Los tipos de nodos flexibles ya están disponibles para el público en general
Mejora la confiabilidad del lanzamiento de clústeres y reduce los costos de cómputo con la conmutación por error automática de instancias
por Kelsey Ge, Andrew Bagshaw, Tianyi Zhang, Vedaant Shah, Rishan Girish y Hugh March
- Proteja las cargas de trabajo contra los errores de capacidad: cuando su tipo de VM preferido no está disponible, Databricks recurre automáticamente a alternativas compatibles para que los clústeres puedan lanzarse de todos modos.
- Obtenga flexibilidad al estilo de flota en todas las nubes: los tipos de nodo flexibles ofrecen un respaldo automático de tipo de instancia para Azure, GCP y AWS. Disfrute de una activación más sencilla con "un solo clic" en todo el espacio de trabajo, con una visibilidad clara de los recursos adquiridos y un orden de respaldo opcionalmente configurable.
- Reduzca el gasto sin sacrificar la confiabilidad: priorice las instancias Spot con descuento cuando estén disponibles y recurra a las alternativas solo cuando sea necesario para mantener el éxito del lanzamiento.
Garantizar una capacidad de cómputo específica puede ser un desafío, especialmente durante los períodos de alto tráfico (y alta presión). Los ingenieros de datos y los administradores de plataformas conocen muy bien la frustración de los errores por capacidad insuficiente, o de "agotamiento de existencias", que se producen cuando falla el lanzamiento de un clúster porque un proveedor de la nube no puede satisfacer una solicitud de un tipo de instancia específico.
Ya sea:
AWS_INSUFFICIENT_INSTANCE_CAPACITY_FAILURECLOUD_PROVIDER_RESOURCE_STOCKOUTen Azure, oGCP_INSUFFICIENT_CAPACITY,
Estos errores interrumpen las cargas de trabajo críticas, especialmente durante los períodos críticos para el negocio, cuando el tiempo de actividad es más importante.
¿Qué son los tipos de nodos flexibles?
Tradicionalmente, los clústeres de Databricks requerían que cada nodo fuera del tipo de instancia exacto especificado en su configuración. Si ese tipo específico no estuviera disponible, el lanzamiento del clúster fallaría.
Los tipos de nodo flexibles eliminan esta restricción. Cuando un tipo de instancia preferido no está disponible, Databricks recurre automáticamente a una alternativa compatible que comparte la misma forma de computación. En otras palabras, el clúster se lanza con éxito utilizando una combinación de tipos de instancia similares en lugar de fallar por completo.
Para los equipos que necesitan un control más estricto, también pueden definir una lista de respaldo personalizada a través de la API, que incluya qué tipos de instancia probar y en qué orden.
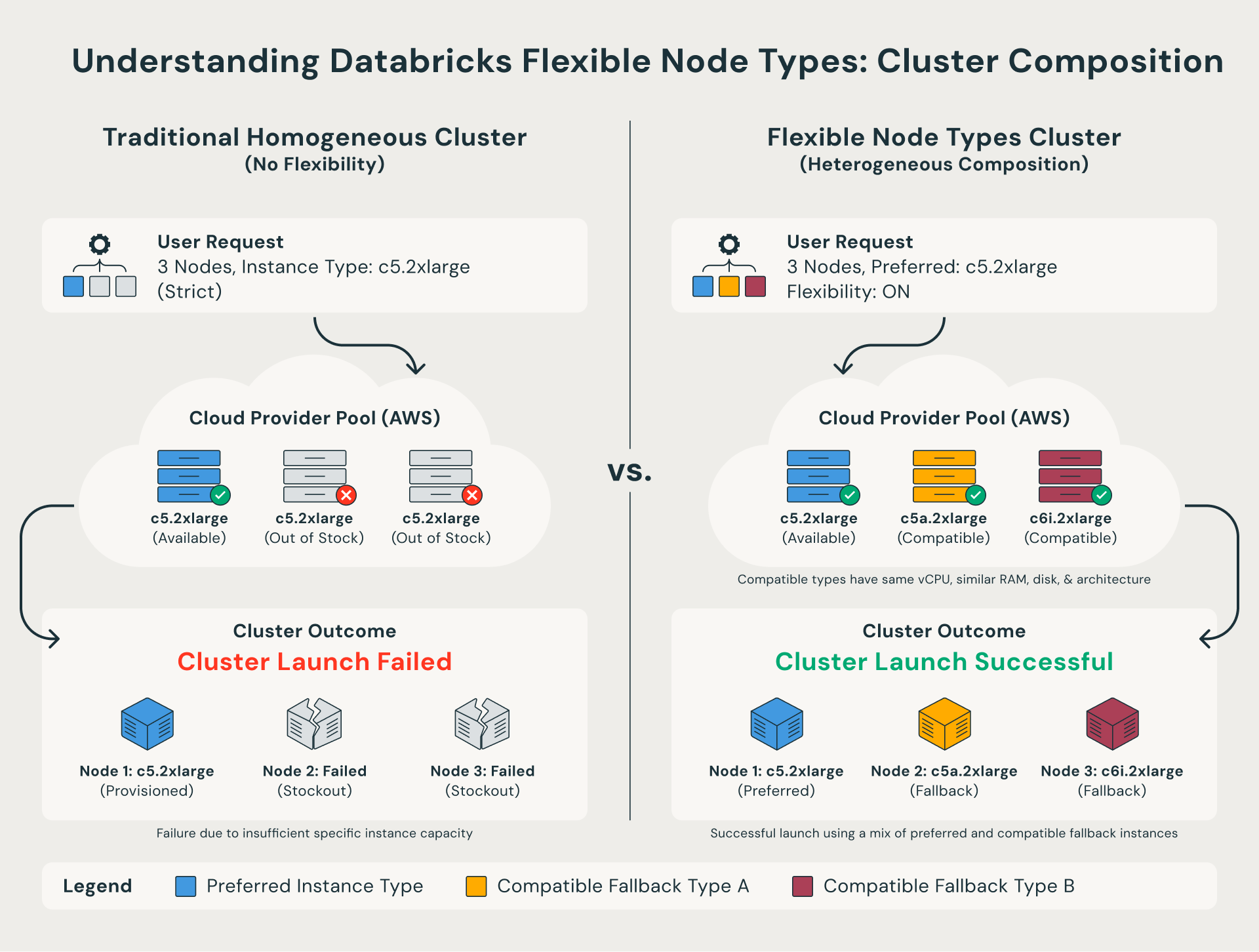
Beneficios clave
Menos inicios de clúster fallidos durante los picos de demanda
Los tipos de nodo flexibles reducen tanto la frecuencia como la gravedad de las fallas relacionadas con la capacidad. Cuando un proveedor de la nube no puede satisfacer el tipo de instancia preferido, Databricks recurre automáticamente a alternativas compatibles, lo que permite que los clústeres se lancen en lugar de generar un error.
Uso optimizado de instancias Spot
Para los clústeres configurados con Spot con respaldo, los tipos de nodos flexibles intentan adquirir capacidad de Spot en toda la lista de respaldo antes de volver a las instancias bajo demanda. Esto aumenta la porción del clúster que se ejecuta en Spot, lo que ayuda a reducir los costos de computación sin dejar de priorizar los lanzamientos exitosos.
Visibilidad clara y control preciso
Los equipos pueden inspeccionar exactamente qué tipos de nodo se adquieren utilizando la tabla de sistema node_timeline. Además, se puede definir un orden de respaldo personalizado a través de la API, lo que permite un control preciso sobre el costo y el comportamiento del rendimiento.
Inicio rápido
Los administradores del área de trabajo pueden habilitar fácilmente la característica en la configuración de administrador (Documentación: AWS, Azure, GCP). A partir de ahí, la característica se aplica inmediatamente a todos los nuevos lanzamientos de clústeres. Los clústeres de larga duración adoptarán la característica en su próximo reinicio, y los futuros clústeres de trabajos creados para trabajos existentes utilizarán automáticamente la característica.
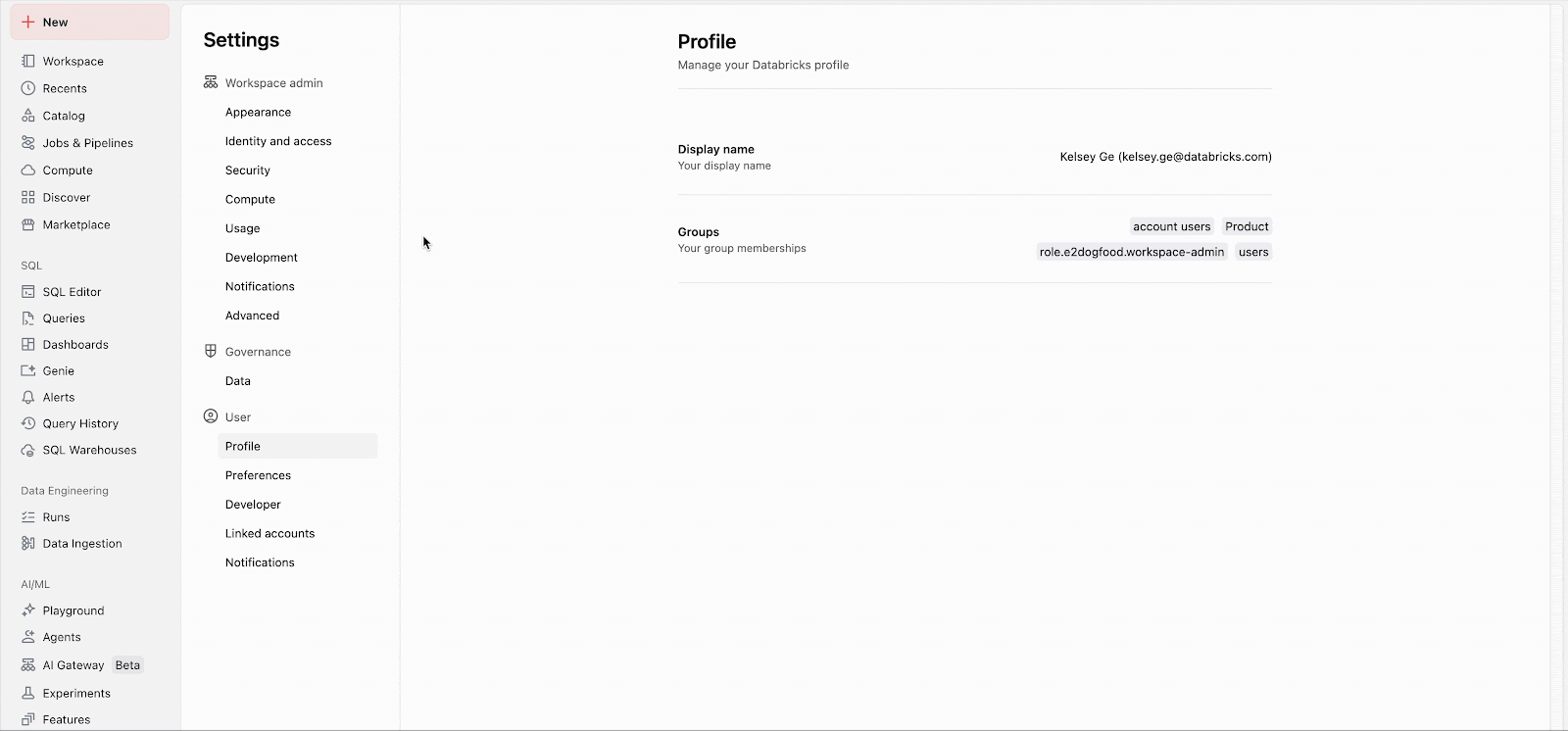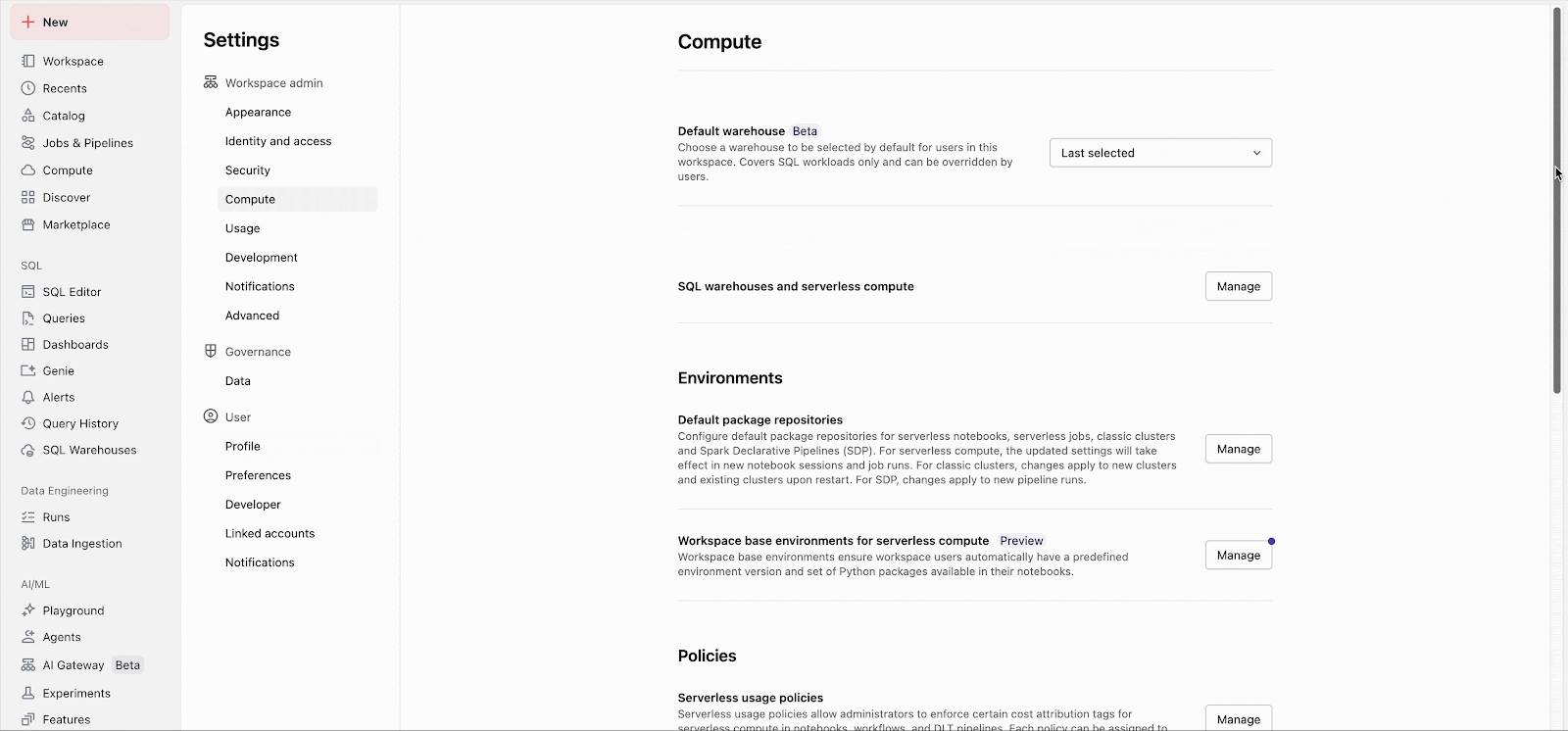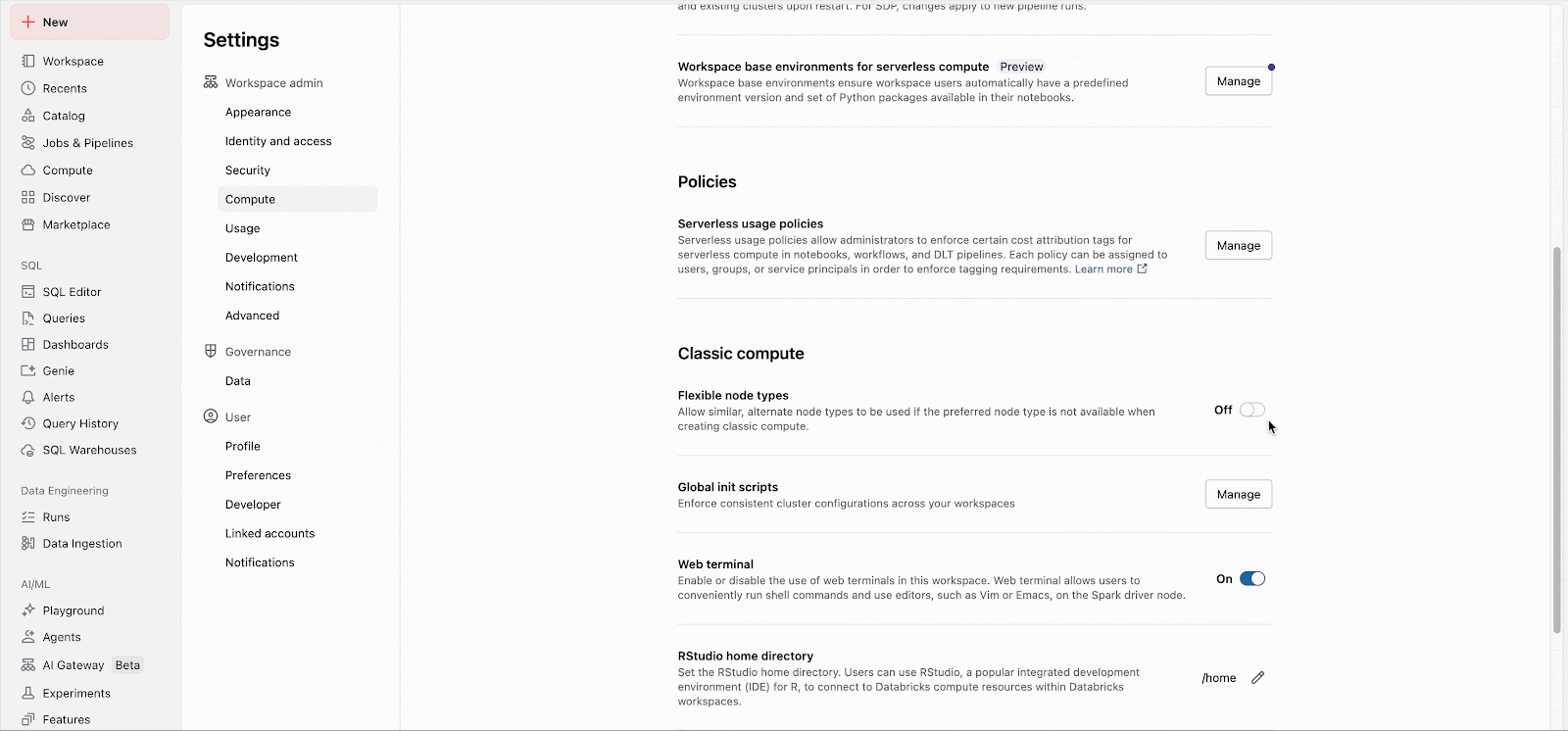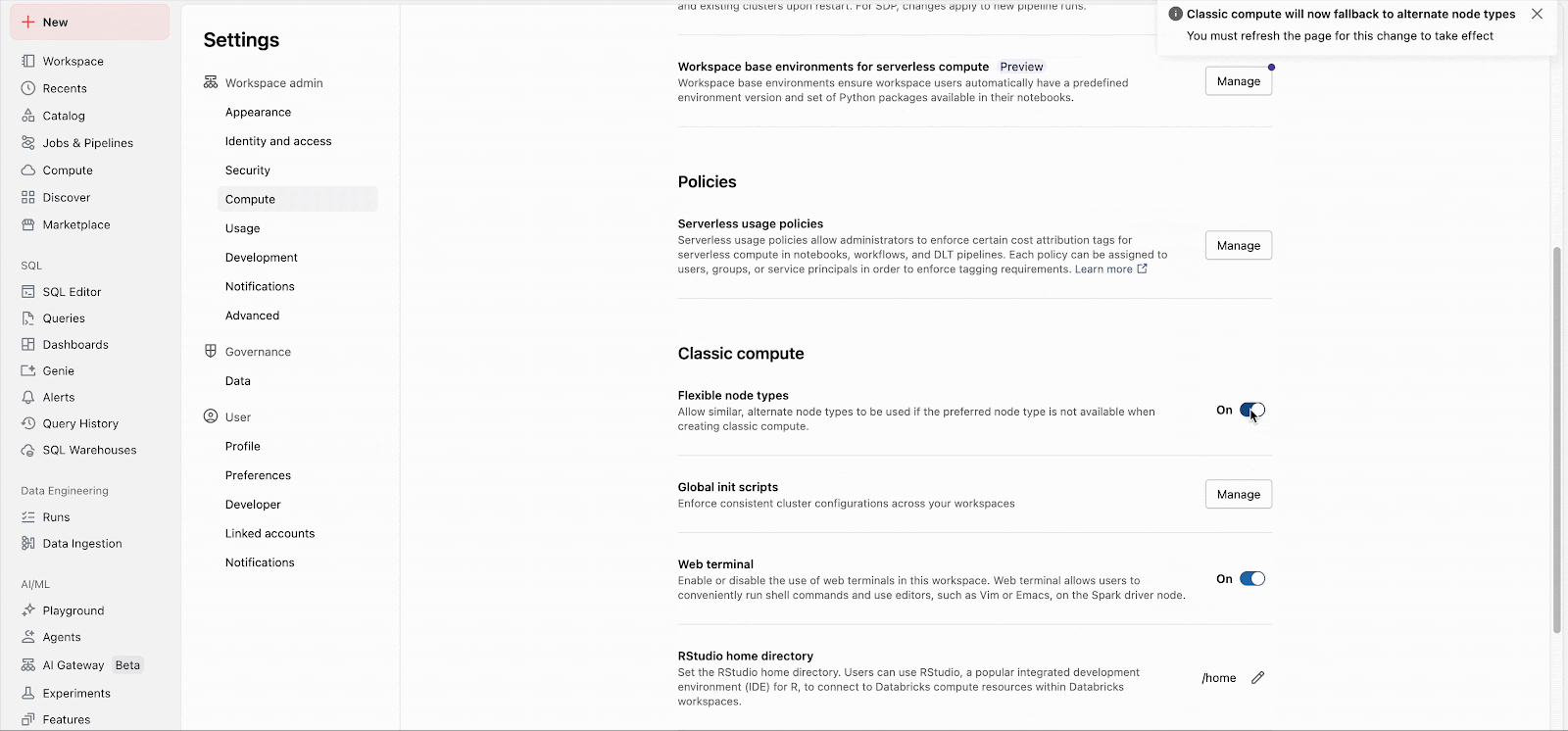
Las listas de respaldo personalizadas se pueden configurar a través de la API, independientemente de la configuración del área de trabajo.
Detalles adicionales
Consulte la documentación para obtener más detalles sobre la configuración de tipos de nodo flexibles con grupos de instancias, facturación, cuotas de tipo de nodo y habilitación/deshabilitación selectiva (Documentación: AWS, Azure, GCP).
Los tipos de nodos flexibles están diseñados para que tu plataforma de datos sea más resiliente y rentable. Los administradores pueden habilitar esta función con un solo clic hoy mismo en la configuración de administrador del espacio de trabajo siguiendo las instrucciones de la documentación.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.