Primeros pasos con la personalización mediante la puntuación de propensión
por Tian Tan, Sam Steiny y Bryan Smith

Los consumidores esperan cada vez más una interacción personalizada. Ya sea un correo electrónico que promociona productos para complementar una compra reciente, un banner en línea que anuncia una oferta en productos de una categoría que se consulta con frecuencia, o contenido alineado con sus intereses, los consumidores tienen cada vez más opciones para decidir dónde gastar su dinero y prefieren hacerlo en establecimientos que reconozcan sus necesidades y preferencias personales.
Una encuesta reciente de McKinsey destaca que casi tres cuartas partes de los consumidores esperan interacciones personalizadas como parte de su experiencia de compra. La investigación incluida en esta encuesta resalta que las empresas que lo hacen bien pueden generar un 40% más de ingresos a través de interacciones personalizadas, lo que convierte a la personalización en un diferenciador clave para las principales empresas de retail.
Aun así, a muchos minoristas les cuesta implementar la personalización. Una encuesta reciente de Forrester revela que solo el 30% de los consumidores de US y el 26% de los de UK consideran que los minoristas hacen un buen trabajo al crear experiencias relevantes para ellos. En otra encuesta independiente de 3radical, solo el 18% de los encuestados afirmó con seguridad recibir recomendaciones personalizadas, mientras que el 52% expresó su frustración por recibir ofertas y comunicaciones irrelevantes. Dado que los consumidores tienen cada vez más facilidad para cambiar de marca y de tienda, acertar con la personalización se ha convertido en una prioridad para un número creciente de empresas.
La personalización es un camino
Para una organización que se inicia en la personalización, la idea de ofrecer interacciones personalizadas uno a uno puede parecer abrumadora. ¿Cómo superamos los procesos aislados, la gestión deficiente de los datos y las preocupaciones sobre la privacidad para recopilar la información necesaria para este enfoque? ¿Cómo diseñamos contenidos y mensajes que se sientan realmente personalizados con recursos de marketing limitados? ¿Cómo nos aseguramos de que el contenido que creamos se dirija de manera efectiva a personas con necesidades y preferencias en constante evolución?
Aunque gran parte de la literatura sobre personalización destaca enfoques de vanguardia que sobresalen por su novedad (pero no siempre por su efectividad), la realidad es que la personalización es un camino. En las primeras fases, se hace hincapié en aprovechar los datos propios (first-party data), donde la privacidad y la confianza del cliente se mantienen con mayor facilidad. Se aplican técnicas predictivas bastante estándar para implementar capacidades ya probadas. A medida que se demuestra el valor y la organización se familiariza no solo con estas nuevas técnicas, sino también con las diversas formas de integrarlas en sus prácticas, se empiezan a emplear enfoques más sofisticados.
La puntuación de propensión suele ser el primer paso hacia la personalización
Uno de los primeros pasos en el camino de la personalización suele ser el análisis de los datos de ventas para obtener información sobre las preferencias individuales de los clientes. En un proceso conocido como puntuación de propensión (propensity scoring), las empresas pueden estimar la receptividad potencial de los clientes a una oferta o a contenido relacionado con un subconjunto de productos. Con estas puntuaciones, los profesionales de marketing pueden determinar cuál de los muchos mensajes disponibles debe presentarse a un cliente específico. Del mismo modo, estas puntuaciones se pueden utilizar para identificar segmentos de clientes que sean más o menos receptivos a una forma particular de interacción.
El punto de partida para la mayoría de los ejercicios de puntuación de propensión es el cálculo de atributos numéricos (características o features) a partir de interacciones pasadas. Estas características pueden incluir aspectos como la frecuencia de compra de un cliente, el porcentaje de gasto asociado a una categoría de producto específica, los días transcurridos desde la última compra y muchas otras métricas derivadas de los datos históricos. A continuación, se examina el período histórico inmediatamente posterior al período a partir del cual se calcularon estas características para identificar comportamientos de interés, como la compra de un producto dentro de una categoría específica o el canje de un cupón. Si se observa el comportamiento, se asocia una etiqueta de 1 a las características. Si no se observa, se asigna una etiqueta de 0.
Utilizando las características como predictores de las etiquetas, los científicos de datos pueden entrenar un modelo para estimar la probabilidad de que ocurra el comportamiento de interés. Al aplicar este modelo entrenado a las características calculadas para el período más reciente, los profesionales de marketing pueden estimar la probabilidad de que un cliente realice este comportamiento en el futuro cercano.
Con numerosas ofertas, promociones, mensajes y otros contenidos a nuestra disposición, se entrenan y aplican múltiples modelos (cada uno de los cuales predice un comportamiento diferente) a este mismo conjunto de características. Se compila un perfil por cliente que consta de puntuaciones para cada uno de los comportamientos de interés y luego se publica en los sistemas descendentes (downstream) para que el equipo de marketing lo utilice en la orquestación de diversas campañas.
Databricks ofrece capacidades críticas para la puntuación de propensión
Aunque la puntuación de propensión suena sencilla, no está exenta de desafíos. En nuestras conversaciones con minoristas que implementan la puntuación de propensión, a menudo nos encontramos con las mismas tres preguntas:
- ¿Cómo mantenemos los cientos y, a veces, miles de características que utilizamos para entrenar nuestros modelos de propensión?
- ¿Cómo entrenamos rápidamente modelos alineados con las nuevas campañas que el equipo de marketing desea poner en marcha?
- ¿Cómo volvemos a implementar rápidamente en el pipeline de puntuación los modelos reentrenados a medida que cambian los patrones de los clientes?
En Databricks, nuestro enfoque es empoderar a nuestros clientes a través de una plataforma de analítica diseñada teniendo en cuenta las necesidades integrales de la empresa. Con ese fin, hemos incorporado a nuestra plataforma funciones como Feature Store, AutoML y MLflow, que pueden emplearse para abordar estos desafíos como parte de un proceso sólido de puntuación de propensión.
Feature Store
El Feature Store de Databricks es un repositorio centralizado que permite la persistencia, el descubrimiento y el uso compartido de características en diversos ejercicios de entrenamiento de modelos. A medida que se capturan las características, se registran el linaje y otros metadatos para que los científicos de datos que deseen reutilizar características creadas por otros puedan hacerlo con confianza y facilidad. Los modelos de seguridad estándar garantizan que solo los usuarios y procesos autorizados puedan emplear estas características, de modo que los procesos de ciencia de datos se gestionen de acuerdo con las políticas de acceso a datos de la organización.
AutoML
Databricks AutoML le permite generar modelos rápidamente aprovechando las mejores prácticas de la industria. Como solución de tipo "caja de cristal" (glass box), AutoML genera primero una colección de notebooks que representan diferentes variaciones de modelos alineadas con su escenario. Mientras entrena de forma iterativa los diferentes modelos para determinar cuál funciona mejor con su conjunto de datos, le permite acceder a los notebooks asociados a cada uno de ellos. Para muchos equipos de ciencia de datos, estos notebooks se convierten en un punto de partida editable para seguir explorando variaciones de modelos, lo que en última instancia les permite llegar a un modelo entrenado que confían que cumplirá con sus objetivos.
MLflow
MLflow es un repositorio de modelos de machine learning de código abierto, gestionado dentro de la plataforma de Databricks. Este repositorio permite al equipo de ciencia de datos realizar un seguimiento y analizar las diversas iteraciones de modelos generadas tanto por AutoML como por ciclos de entrenamiento personalizados. Sus capacidades de gestión de flujos de trabajo permiten a las organizaciones trasladar rápidamente los modelos entrenados desde el desarrollo a la producción, de modo que estos puedan tener un impacto más inmediato en las operaciones.
Cuando se utiliza en combinación con el Feature Store de Databricks, los modelos guardados con MLflow conservan el conocimiento de las características utilizadas durante el entrenamiento. Cuando se recuperan los modelos para la inferencia, esta misma información permite al modelo recuperar las características relevantes del Feature Store, lo que simplifica enormemente el flujo de trabajo de puntuación y permite una implementación rápida.
Creación de un flujo de trabajo de puntuación de propensión
Al utilizar estas funciones en combinación, vemos que muchas organizaciones implementan la puntuación de propensión como parte de un flujo de trabajo de tres partes. En la primera parte, los ingenieros de datos trabajan con los científicos de datos para definir las características relevantes para el ejercicio de puntuación de propensión y guardarlas en el Feature Store. A continuación, se definen procesos de ingeniería de características diarios o incluso en tiempo real para calcular valores de características actualizados a medida que llegan nuevas entradas de datos.
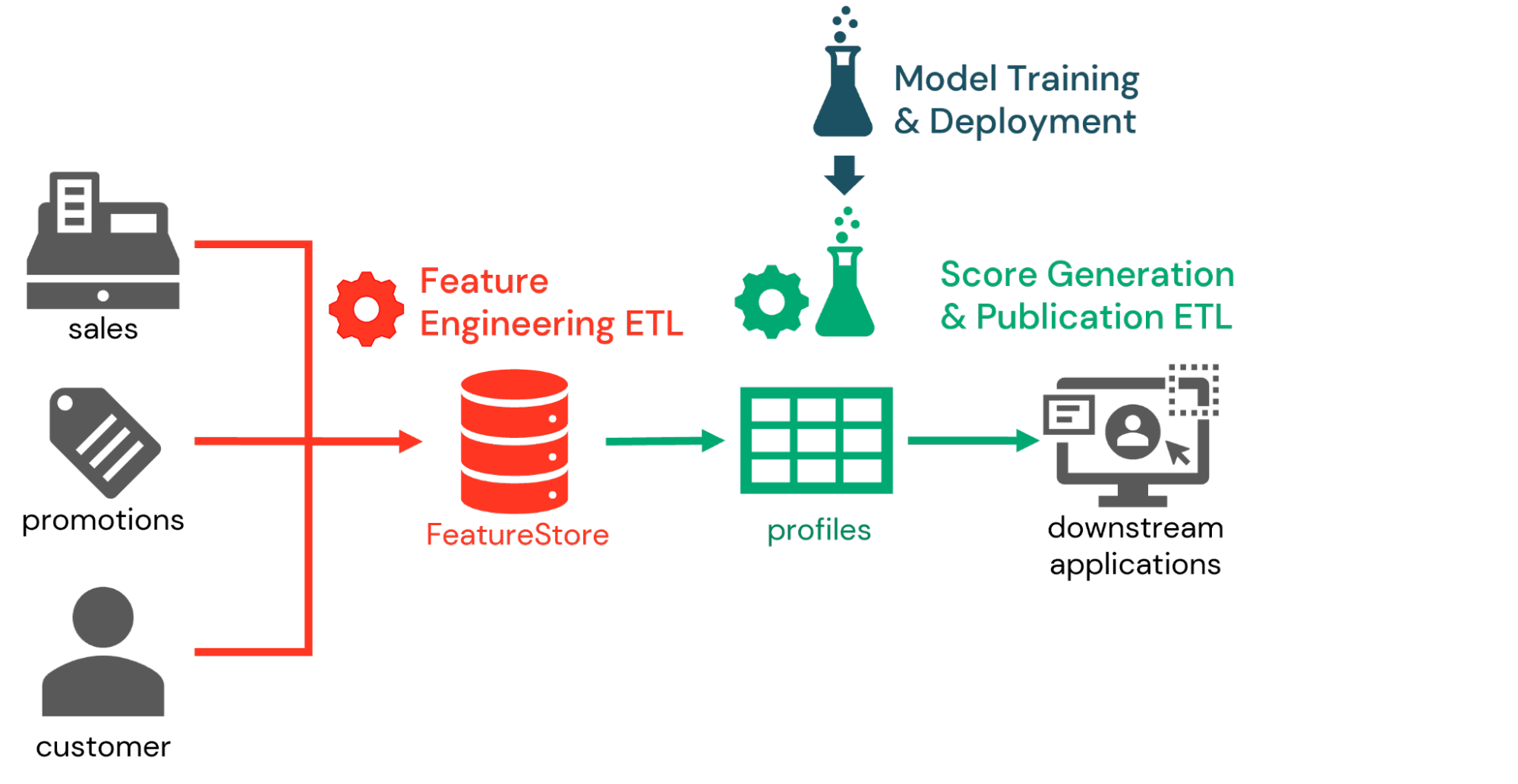
A continuación, como parte del flujo de trabajo de inferencia, los identificadores de los clientes se presentan a los modelos previamente entrenados para generar puntuaciones de propensión basadas en las últimas características disponibles. La información de Feature Store capturada con el modelo permite a los ingenieros de datos recuperar estas características y generar las puntuaciones deseadas con relativa facilidad. Estas puntuaciones pueden persistirse para su análisis dentro de la plataforma Databricks, pero lo más habitual es que se publiquen en sistemas de marketing descendentes.
Por último, en el flujo de trabajo de entrenamiento de modelos, los científicos de datos reentrenan periódicamente los modelos de puntuación de propensión para capturar los cambios en el comportamiento de los clientes. A medida que estos modelos se persisten en MLflow, se emplean procesos de gestión de cambios para evaluar los modelos y promover a producción aquellos que cumplan con los criterios de la organización. En la siguiente iteración del flujo de trabajo de inferencia, se recupera la última versión de producción de cada modelo para generar las puntuaciones de los clientes.
Para demostrar cómo funcionan juntas estas capacidades, hemos creado un flujo de trabajo de extremo a extremo para la puntuación de propensión basado en un conjunto de datos disponible públicamente. Este flujo de trabajo demuestra las tres partes del flujo de trabajo descrito anteriormente y muestra cómo emplear las características clave de Databricks para crear una canalización de puntuación de propensión eficaz.
Descargue los recursos aquí y utilícelos como punto de partida para crear su propia base de personalización con la plataforma Databricks.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.