Atribución de uso granular para pipelines de dbt con etiquetas de consulta
Etiqueta, realiza un seguimiento y optimiza cada modelo de dbt —desde la atribución de costos y la depuración de rendimiento hasta el monitoreo del entorno— con una sola línea de configuración o Genie.
- Etiqueta cada consulta de dbt con el equipo, centro de costos, proyecto y entorno: cero cambios de código en tus modelos SQL
- Consulta system.query.history para ver exactamente qué modelos de dbt cuestan más y dónde se consume el tiempo de cómputo
- Implementa un proyecto de referencia completo con Declarative Automation Bundles: un pipeline de dbt, un panel de análisis de Query Tag y un trabajo programado, todo desde un único repositorio de GitHub
Su proyecto dbt ejecuta 80 modelos cada noche. La factura del warehouse se duplicó el trimestre pasado. El rendimiento de los modelos varía mucho y los efectos de las optimizaciones más recientes no están claros. Finanzas pregunta qué equipo es el responsable. Abre el historial de consultas y ve... 80 filas idénticas etiquetadas como 'Databricks Dbt'. Buena suerte.
Con Query Tags (ahora en vista previa pública), los equipos de datos ahora pueden beneficiarse de etiquetas autoinyectadas listas para usar, como dbt_model_name, que enriquecen cada ejecución. También puede adjuntar sus propias etiquetas personalizadas (equipo, centro de costos, entorno, lo que sea) a cada consulta que genere su pipeline.
Las etiquetas se registran en system.query.history, lo que hace que la atribución de costos, la depuración del rendimiento y el monitoreo de la carga de trabajo estén a solo una consulta SQL de distancia (todos los detalles en la documentación).
Este blog recorre un proyecto dbt completo y de código abierto que demuestra Query Tags de extremo a extremo: desde la configuración hasta los paneles de atribución de costos. Todo lo que se describe aquí está disponible como un repositorio de GitHub que puede clonar e implementar en su propio espacio de trabajo, o simplemente preguntarle a Genie.
Cómo se integra dbt-databricks con Query Tags
El adaptador dbt-databricks (versión 1.11+) admite Query Tags de forma nativa. Hay tres niveles en los que se pueden aplicar las etiquetas, cada uno de los cuales se basa en el anterior:
Etiquetas autoinyectadas
Además de sus etiquetas personalizadas, dbt-databricks inyecta automáticamente metadatos sobre la ejecución de cada modelo:
Etiqueta | Valor de ejemplo | Descripción |
@@dbt_model_name | fct_daily_usage_by_sku | El modelo dbt que se está ejecutando |
@@dbt_materialized | table | Estrategia de materialización (table, view, incremental, metric_view) |
@@dbt_core_version | 1.11.6 | Versión de dbt-core |
@@dbt_databricks_version | 1.12.0a1 | Versión del adaptador dbt-databricks |
Estas autoetiquetas significan que obtiene visibilidad por modelo con cero configuración: el adaptador lo hace por usted.
Etiquetas a nivel de perfil
El enfoque más sencillo: agregue un campo query_tags a un destino específico en su perfil de dbt. Cada consulta en el proyecto hereda estas etiquetas automáticamente.
Por ejemplo, esta única línea etiqueta cada consulta con cuatro dimensiones: quién es el propietario (team), a dónde va el costo (cost_center), a qué pipeline pertenece (project_name) y en qué entorno se ejecuta (env).
Etiquetas a nivel de modelo
Para una atribución más detallada, puede proporcionar etiquetas en modelos específicos en dbt_project.yml o en la configuración del modelo en su definición sql.
Las etiquetas a nivel de modelo se fusionan con las etiquetas a nivel de perfil. Si ambos definen la misma clave, el valor a nivel de modelo tiene prioridad.
Dónde aparecen las etiquetas: system.query.history
Después de ejecutar dbt run, cada instrucción SQL aparece en system.query.history con la columna query_tags poblada como un MAP. Puede consultarla utilizando la sintaxis estándar de acceso a mapas:
Esto devuelve cada consulta etiquetada de los últimos 7 días, con las etiquetas personalizadas y autoinyectadas extraídas en columnas individuales, listas para la agregación.
También puede encontrar las Query Tags de la consulta que ejecutó en la UI de Query History o en la UI de SQL Warehouse Monitoring.

En la parte inferior derecha del Query Profile, verá las Query Tags que definió, lo que le proporcionará toda la información necesaria de un vistazo.

Atribución de costos con Query Tags
Query Tags permite determinar una atribución de uso detallada directamente a través de consultas SQL, lo que elimina la necesidad de realizar análisis de registros manuales o dividir los recursos del warehouse.
¿Qué modelos dbt consumen la mayor cantidad de recursos del warehouse?
Puede responder a esto de dos maneras: pregúntele a Genie en lenguaje sencillo para una exploración ad-hoc o escriba el SQL usted mismo para obtener un resultado repetible y listo para un panel de control. Ambos leen de los mismos datos de system.query.history .
Opción 1: Genie

Genie escribe y ejecuta la consulta equivalente, y usted puede seguir profundizando con preguntas de seguimiento sin tener que tocar nada de SQL.
Opción 2: SQL
Cualquier camino devuelve el mismo resultado. En nuestro proyecto de referencia, las cuatro tablas mart (materializadas como table) dominan el tiempo de cómputo, mientras que las vistas de staging y las vistas métricas son casi instantáneas. Esto le indica de inmediato dónde debe centrarse el esfuerzo de optimización.

Creación de un panel de control de automonitoreo
Nuestro proyecto de referencia incluye un panel de control de AI/BI que consulta system.query.history filtrado por las propias etiquetas de consulta del proyecto. El resultado: el pipeline que analiza los datos de facturación también realiza un seguimiento de sus propios costos, usando sus propias Query Tags.
El panel de control incluye:
- KPIs: Consultas etiquetadas totales, segundos de cómputo totales, modelos dbt distintos
- Actividad diaria: Recuento de consultas y tiempo de cómputo por día, desglosados por entorno
- Desglose de modelos: Tiempo de cómputo por modelo, coloreado por tipo de materialización
- Distribución de materialización: Gráfico de sectores que muestra cómo se distribuye el cómputo entre table, view y metric_view
- Tabla de detalles de consultas: Cada consulta etiquetada con modelo, duración, entorno y ejecutor
En nuestro proyecto de referencia, los cuatro modelos de mart representaron el 92% del tiempo de cómputo; sin Query Tags, esa información habría sido invisible.
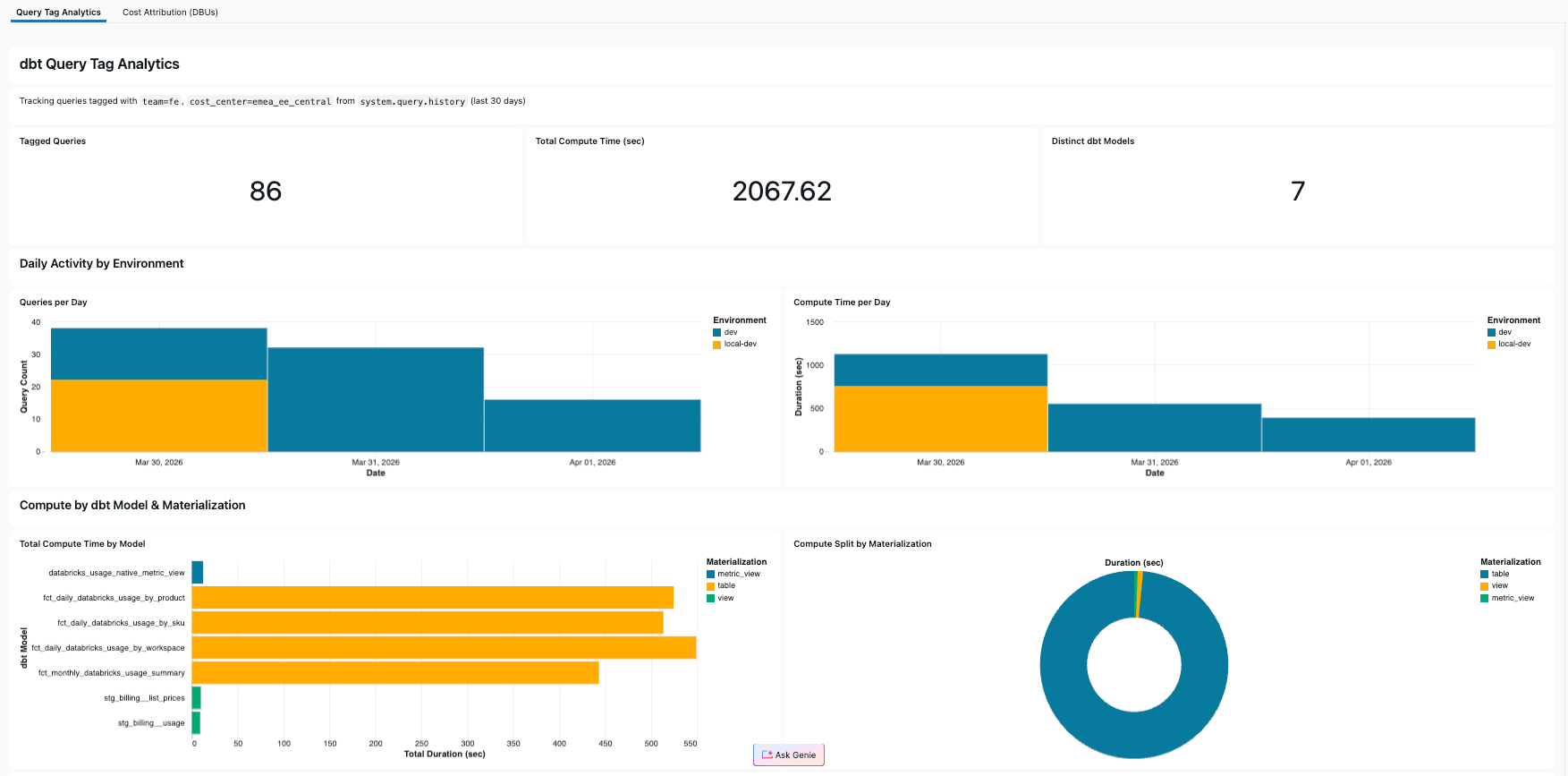
Crear este panel usted mismo lleva solo unos minutos con Genie Code: pídale el tiempo de cómputo por modelo de dbt de system.query.history filtrado por sus etiquetas de consulta, y este escribirá el SQL y generará los elementos visuales. Si prefiere ir directamente al resultado final, el panel también se incluye en el proyecto de referencia y se implementa con un solo databricks bundle deploy junto con el trabajo de dbt (consulte el repositorio de GitHub para obtener la guía detallada).
Etiquetado de vistas de métricas
Las vistas de métricas de Databricks (disponibles con dbt-databricks 1.12+) son un nuevo tipo de materialización que define semántica empresarial reutilizable en forma de dimensiones y medidas directamente en Unity Catalog (consulte la documentación completa). Pueden llevar Query Tags al igual que cualquier otro modelo, utilizando el parámetro de configuración query_tags:
Tenga en cuenta la diferencia: query_tags se adjuntan a las consultas SQL que crean o actualizan la vista de métricas (registradas en system.query.history), mientras que databricks_tags son etiquetas de Unity Catalog en el propio objeto (para gobernanza y descubrimiento). Lo primero es para el seguimiento a nivel de consulta, mientras que lo segundo es a nivel de objeto de Unity Catalog para la descubribilidad general de los datos.
Prácticas recomendadas para etiquetar proyectos de dbt
En este artículo, abordamos el proceso holístico para crear una práctica sólida de FinOps donde las Query Tags son fundamentales para la atribución de costos. Esto es lo que aprendimos al crear el proyecto de referencia y al hablar con usuarios avanzados de dbt:
- Utilice una jerarquía de etiquetas coherente. Defina etiquetas para toda la organización a nivel de perfil (team, cost_center, project_name, env) y reserve las etiquetas a nivel de modelo para casos excepcionales. Esto mantiene las etiquetas predecibles y evita la dispersión de la configuración por modelo.
- Etiquete siempre el entorno. Utilice diferentes valores de env para el desarrollo local (local-dev) y los trabajos implementados (dev, staging, prod). Esto le permite separar las consultas de desarrollo ad-hoc de las ejecuciones de producción programadas en sus análisis. En nuestro proyecto de referencia, el perfil local establece "env": "local-dev" mientras que el perfil implementado establece "env": "dev".
- Utilice `project_name` para distinguir pipelines. Cuando varios proyectos de dbt comparten un almacén, project_name le permite atribuir costos por pipeline sin tener que dividir los almacenes. En combinación con el @@dbt_model_name inyectado automáticamente, obtiene una trazabilidad completa: proyecto → modelo → materialización.
- No abuse de las etiquetas. Las etiquetas inyectadas automáticamente ya cubren el nombre del modelo, el tipo de materialización y las versiones del adaptador. Rara vez necesitará duplicar esta información en etiquetas personalizadas. Centre las etiquetas personalizadas en el contexto empresarial que dbt no puede inferir: propiedad del equipo, centro de costos e identidad del proyecto.
- Etiquete las vistas de métricas explícitamente. Dado que las vistas de métricas son una materialización más reciente, resulta útil etiquetarlas con una clave de característica (por ejemplo, "feature": "metric_view") para poder filtrar fácilmente las consultas de creación de vistas de métricas en su análisis de costos.
Pruébelo usted mismo
El proyecto de referencia completo está disponible en GitHub: github.com/databricks-solutions/dbt-query-tags
Para comenzar:
- Clone el repositorio
- Cree un entorno virtual de Python 3.12 e instale las dependencias: pip install dbt-databricks>=1.12.0a1
- Actualice profiles.yml con el host de su espacio de trabajo, la ruta HTTP del SQL warehouse, el catálogo y las etiquetas de consulta personalizadas
- Ejecute dbt deps && dbt run --profiles-dir . para ejecutar el pipeline
- Consulte system.query.history para ver sus etiquetas en acción
- Actualice dbt_profiles/profiles.yml y databricks.yml para apuntar a la configuración correcta.
- Realice la implementación con databricks bundle deploy para ejecuciones programadas y el panel de análisis
Sustituya los valores por los de su propio equipo y centro de costos. El patrón funciona para cualquier proyecto de dbt en Databricks.
¡Clone el repositorio hoy mismo! Solo se necesita una línea en su perfil para desbloquear la visibilidad de la atribución de uso a nivel de modelo en todo su almacén.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.