Cómo la arquitectura lakehouse se mantiene resiliente a las fallas en la nube
por Jasraj Dange y Hans Norheim
- Las cargas de trabajo de los agentes están remodelando los requisitos de confiabilidad en la nube. Los agentes crean bases de datos 4 veces más rápido que los humanos, exigen infraestructura sin servidor y autoescalable, y tratan las operaciones del plano de control (como iniciar una base de datos) como trabajo crítico del plano de datos. En Lakebase, ahora iniciamos decenas de millones de bases de datos por día.
- La arquitectura de Lakebase está construida para la resiliencia, no parcheada para ella. El cómputo de Postgres sin estado en almacenamiento redundante por zonas significa que las instancias se pueden reemplazar instantáneamente sin hot standbys ni recuperación ante fallos. Estamos separando las operaciones del plano de control de ruta activa en un servicio dedicado, minimizando las dependencias del proveedor de la nube y compartimentando cada región en celdas autónomas.
- Demostramos la confiabilidad a través de pruebas y mediciones, no de promesas. Cada lanzamiento se somete a pruebas de caos con inyección de fallos a nivel de proceso, nodo y zona de disponibilidad, validado contra herramientas de código abierto como SqlLancer. Rastreamos la disponibilidad por base de datos (no promedios de flota) contra un objetivo mensual del 99.99%, con la consecución publicada de forma transparente.
El último año, los agentes han llevado al límite la infraestructura en la nube con nuevos patrones de uso:
- Mayor rendimiento de las operaciones del plano de control: Los agentes crean y gestionan mediante programación bases de datos, almacenamiento, cómputo y otros componentes de infraestructura a un ritmo mucho mayor que los humanos. En Databricks Lakebase, los agentes crean 4 veces más bases de datos que los humanos.
- Más demanda bajo demanda: La infraestructura sin servidor, de escalado automático y de suspensión automática es la nueva norma. Si el agente se duerme, ¿por qué pagar por la infraestructura aprovisionada?
- Agotamiento de la capacidad: La demanda de cómputo, GPUs e infraestructura en la nube está aumentando. La noción de que la nube tiene capacidad “infinita” está mostrando grietas.
Esto es un desafío tanto para los constructores de plataformas como para los proveedores de nube. Los planos de control están experimentando aumentos significativos en el volumen de solicitudes para crear, gestionar y escalar la infraestructura, lo que pone a prueba la fiabilidad. La asignación de nueva capacidad en la nube no siempre tendrá éxito. Al mismo tiempo, las cargas de trabajo de los agentes exigen fiabilidad a nivel del plano de datos para las operaciones críticas del plano de control como parte de sus flujos operativos. En los últimos meses, hemos visto cómo los agentes impulsaban un aumento exponencial en el inicio de bases de datos, y ahora estamos iniciando decenas de millones de bases de datos cada día.
La consiguiente avalancha de fallos e incidentes en los servicios en la nube nos ha enseñado lecciones que informan nuestra hoja de ruta de fiabilidad, y queremos compartir cómo estamos haciendo que la arquitectura y el diseño de Lakebase sean más resistentes a los fallos de la nube. Algunos elementos ya están en producción, otros están en proceso.
Arquitectura de alta disponibilidad
En la base se encuentra nuestra arquitectura de cómputo y almacenamiento separados, donde la Alta Disponibilidad (HA) es un principio de diseño fundamental del sistema y no un complemento.
Cómputo Postgres sin estado
A diferencia de muchas configuraciones de servicios de bases de datos Postgres en la nube que son monolíticas y tienen cómputo con estado, Postgres en la arquitectura Lakebase no tiene estado. Todos los datos duraderos residen en un servicio de almacenamiento remoto, por lo que el proceso de cómputo no mantiene ningún estado duradero en el disco local. Si Postgres o el hardware en el que se ejecuta falla, puede ser reemplazado instantáneamente sin replicar datos a un standby en caliente ni ejecutar la recuperación de fallos habitual de Postgres. Un standby en caliente en una configuración monolítica requiere una copia completa de los datos (no es gratis), mientras que la recuperación de fallos debe reproducir el registro de escritura anticipada (WAL) desde el último punto de control, lo que escala con la tasa de escritura en el momento del fallo y puede llevar decenas de minutos, dependiendo de la configuración. Dado que el contenido de la base de datos se almacena en nuestro servicio de almacenamiento resistente a zonas, una instancia de cómputo Postgres única en Lakebase tiene una disponibilidad significativamente mejorada en comparación con una instancia de cómputo Postgres con estado única, sin el coste de una instancia de cómputo adicional en standby en caliente.
Para las bases de datos que requieren los niveles más altos de disponibilidad, puede configurar alta disponibilidad. Esto aprovisiona cómputos dedicados en múltiples zonas de disponibilidad para su base de datos, asegurando que su base de datos permanezca disponible incluso si el proveedor de nube se queda sin capacidad durante (o como resultado de) el evento de fallo. Estos cómputos pueden utilizarse adicionalmente para escalar las lecturas.
Almacenamiento redundante por zonas para todos
Las configuraciones monolíticas de Postgres suelen estar respaldadas por dispositivos de bloque locales que rara vez son redundantes por zonas. Esto requiere replicación física y costosas réplicas de standby en caliente en múltiples zonas de disponibilidad. En Lakebase y Neon, todas las bases de datos, independientemente del nivel y la configuración, están respaldadas por almacenamiento distribuido, redundante por zonas y de alta disponibilidad. Los datos se almacenan en almacenamiento de objetos altamente duradero y redundante por zonas, y el rendimiento se acelera mediante cachés NVMe SSD en múltiples zonas de disponibilidad sin coste adicional para usted.
El plano de control es el nuevo plano de datos
En la arquitectura de servicio de bases de datos en la nube monolítica, el plano de datos es la parte crítica del servicio. Está diseñado para una disponibilidad del 99,99 % o superior y una estabilidad estática. El plano de control solo importa para las operaciones de gestión. Con las cargas de trabajo de agentes y bajo demanda, la parte del plano de control que inicia las bases de datos es efectivamente el plano de datos. Esto ha cambiado nuestra forma de pensar sobre nuestra arquitectura. Actualmente, nuestro plano de control maneja todo, desde el inicio de bases de datos hasta la facturación. Lo primero es claramente más crítico. Hemos tenido interrupciones en las que las operaciones de mantenimiento en segundo plano consumían recursos de los inicios de bases de datos bajo demanda, lo cual claramente no está bien.
Actualmente estamos trabajando arduamente para separar las partes críticas del plano de control en un servicio de controlador de plano de datos que maneje solo las operaciones de ruta activa (inicio/suspensión). Este servicio tiene menos lógica de negocio, un conjunto estricto y mínimo de dependencias externas (ver la siguiente sección), y está diseñado desde cero pensando en la resiliencia, la degradación elegante y la defensa en profundidad.
Para ilustrar lo central que es el plano de control para el tráfico de bases de datos, podemos analizar la vida útil de las sesiones de cómputo (el tiempo desde la reanudación automática debido a una conexión entrante hasta la suspensión por inactividad). En Neon, el 90 % de las sesiones de cómputo para bases de datos con suspensión automática duran menos de 10 minutos.
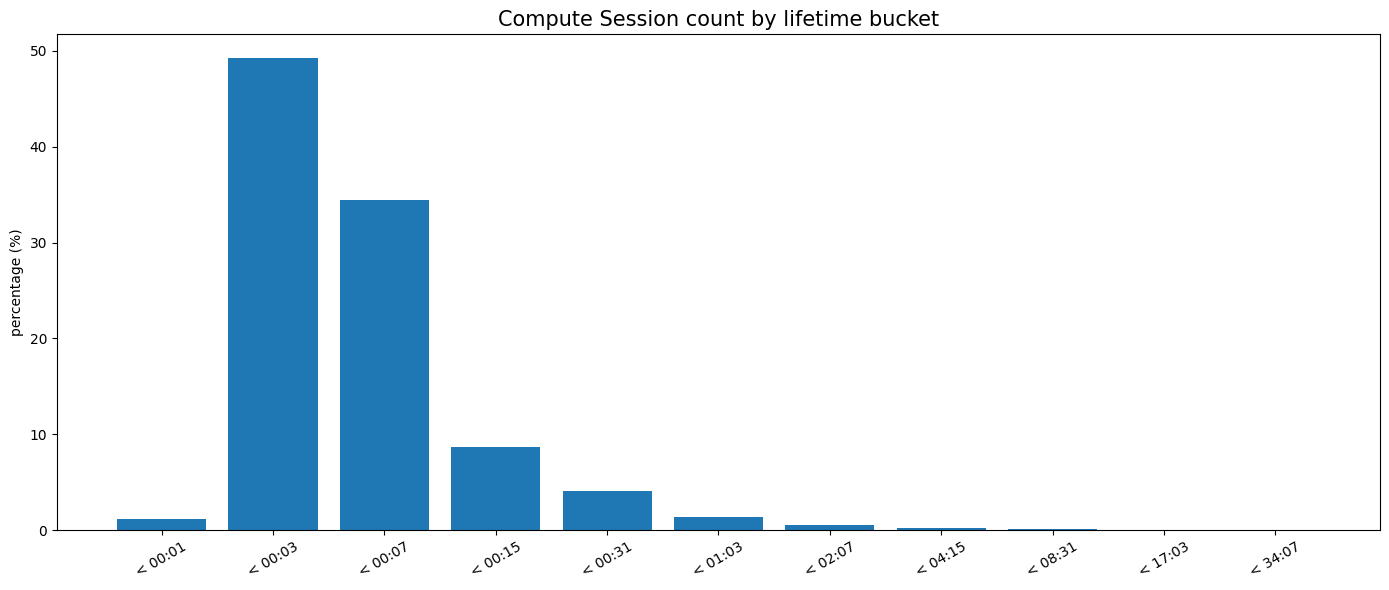
Considere cuidadosamente las dependencias de la ruta crítica, incluidos los planos de control del proveedor de nube
Servir cargas de trabajo de agentes significa que la creación y reanudación de bases de datos debe ser altamente fiable. La fiabilidad está fuertemente correlacionada con la cadena de dependencias y la cantidad de maquinaria involucrada en el flujo. En una configuración tradicional con Postgres en VMs de proveedores de nube, esto va mucho más allá del plano de datos:
- Plano de control de cómputo del proveedor de nube para aprovisionar VMs
- Capacidad de VM disponible (donde el proveedor de nube controla la política de quién la obtiene)
- Plano de control de almacenamiento de bloques del proveedor de nube para aprovisionar almacenamiento local
- Plano de control de red del proveedor de nube para asignar IPs, configurar firewalls y rutas de red a la nueva VM
- Si se utiliza Kubernetes (K8s), una dependencia adicional de los servicios del sistema K8s.
En Lakebase, adoptamos un enfoque diferente que reduce drásticamente la cantidad de maquinaria del plano de control involucrada en los flujos críticos de bases de datos:
- Asignamos un grupo de instancias grandes (a menudo bare metal) del proveedor de nube. Mantenemos buffers para soportar interrupciones de aprovisionamiento del proveedor de nube.
- Hemos creado nuestra propia capa de virtualización de escalado vertical automático que programa múltiples instancias de Postgres en esas instancias en la nube.
- No dependemos de dispositivos de almacenamiento de bloques en la nube, sino que almacenamos los datos en nuestro propio almacenamiento redundante por zonas, que en última instancia está respaldado en almacenes de objetos como S3 o Azure Blob storage.
Muchos otros servicios en Databricks experimentan los mismos desafíos de fiabilidad. Aquí es donde Lakebase se beneficia de ser parte de Databricks: Databricks tiene los medios y está invirtiendo fuertemente en la construcción de una plataforma común para aumentar la fiabilidad de todos los productos en las tres principales nubes.
Compartimentar y contener el radio de explosión
En lugar de ejecutar una única implementación regional monolítica, Lakebase compone una región a partir de una o más celdas con forma idéntica. Una celda es una porción completa y autocontenida de la pila de Neon y Lakebase: Kubernetes, plano de control, cómputo y almacenamiento.
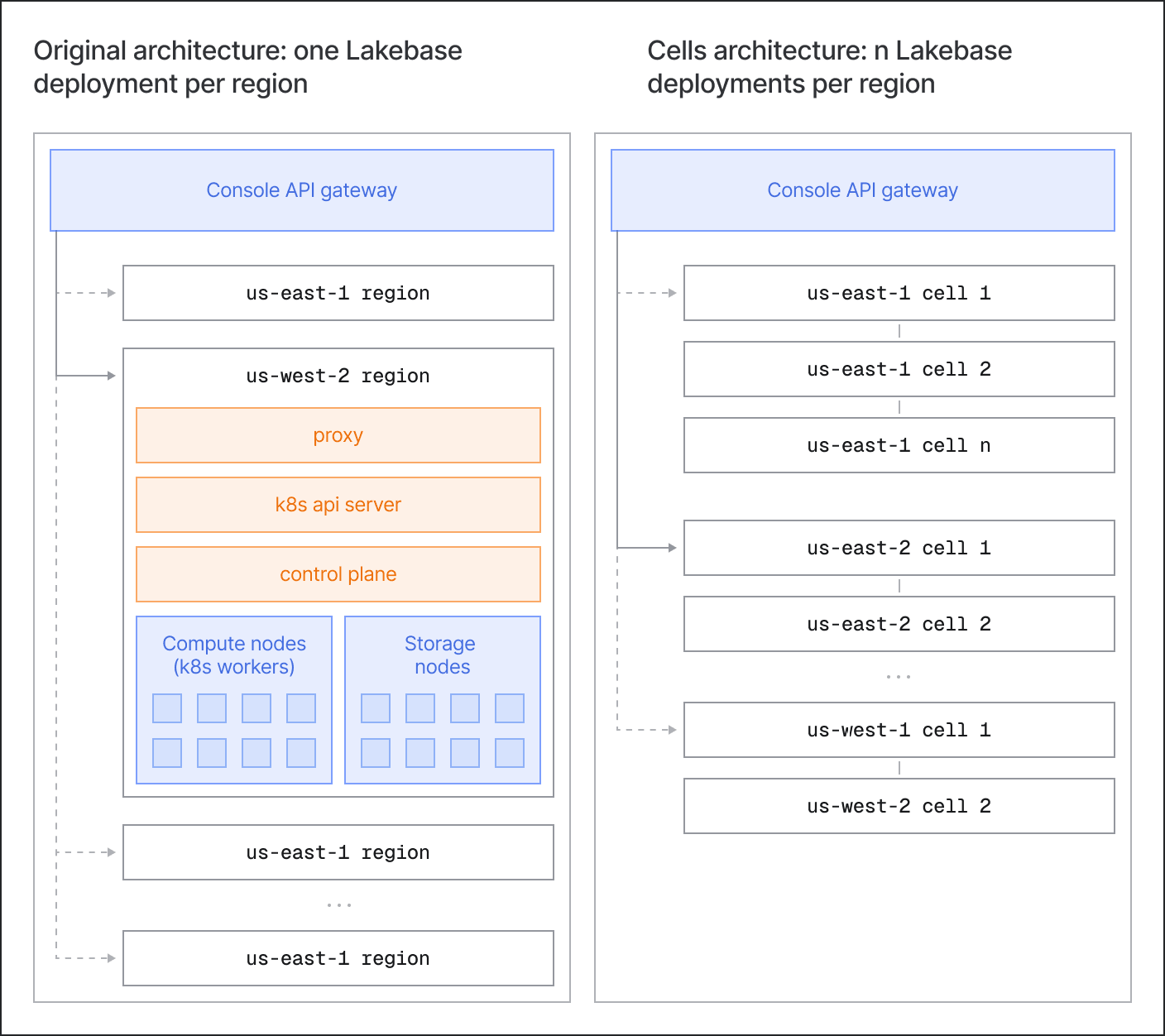
Esto ayuda de dos maneras:
- Escalabilidad: Para hacer crecer una región, añadimos otra celda. Cuando una celda existente se acerca a los límites de escalabilidad de Kubernetes y del plano de control, la creación de nuevos proyectos se dirige a una celda recién aprovisionada. Las celdas se inician rápidamente a medida que crece la demanda.
- Contención del radio de explosión: Incluso con pruebas exhaustivas y protecciones integradas, las cosas todavía salen mal en producción: problemas en el plano de control/servicios del sistema de Kubernetes, regresiones de código o configuración, situaciones de DoS, etc. El límite de la celda aísla las fallas y evita que la situación se propague, dejando que las otras celdas de la región sirvan tráfico normalmente.
En conjunto, esto permite que nuestra plataforma escale una región elásticamente mientras limita el radio de explosión de cualquier falla individual. Durante un incidente el 8 de mayo de 2026, cuando AWS experimentó problemas con una Zona de Disponibilidad en us-east-1, una de las celdas tuvo problemas para hacer failover a nodos saludables. El impacto se limitó a esa celda. Las otras siete celdas de la región hicieron failover correctamente, por lo que el incidente afectó solo a ~13% de las bases de datos de la región. En este caso, la arquitectura basada en celdas redujo el impacto en aproximadamente un orden de magnitud.
Simulación e inyección de fallos
La arquitectura y los principios de redundancia no valen mucho a menos que funcionen en la práctica. Se puede pensar en todos los modos de falla posibles, pero la Ley de Murphy está muy viva, y los sistemas complejos siempre encuentran una manera de sorprenderte. Cada lanzamiento de Lakebase pasa por inyección de fallos y pruebas de caos antes de ir a producción. Desplegamos el lanzamiento en un clúster real, lo ejecutamos con una combinación de cargas de trabajo OLTP y OLAP, agentizadas y no agentizadas, a concurrencia de nivel de estrés, y luego comenzamos a romper cosas debajo. Matamos procesos, derribamos nodos, inyectamos fallos de red, borramos contenidos de disco y reiniciamos componentes en bucles, todo mientras la carga de trabajo sigue en ejecución. Usamos failpoints liberalmente en nuestro código para inyectar errores difíciles de reproducir, como un fallo en el peor momento posible. Esto es impulsado por un framework interno de inyección de fallos que puede apuntar a un solo proceso o coordinar fallos a nivel de clúster en toda una celda.
Nuestro umbral de aprobación es más estricto que "la prueba no arrojó error". Utilizamos herramientas de código abierto como SqlLancer y SqlSmith, junto con herramientas internas similares, para verificar el comportamiento correcto de Postgres. Mientras se ejecuta la inyección de fallos, validamos la consistencia interna de los datos, que ninguna transacci�ón confirmada se pierda y que cada componente se recupere a un estado consistente por sí solo.
Ahora estamos llevando esto un nivel más allá, del caos a nivel de componente a simulaciones de caída de AZ completas. En un clúster real con cargas de trabajo en ejecución, desconectamos programáticamente la red de una zona de disponibilidad del resto del clúster y observamos cómo reacciona el sistema: qué tan rápido se transfieren los datos a réplicas supervivientes, qué tan rápido fallan los cómputos a AZ saludables, cómo la capa de proxy redirige las conexiones y cuánto tiempo una base de datos individual experimenta una interrupción. Nuestro objetivo es que ninguna carga de trabajo esté inactiva por más de 30 segundos.
Medir, medir, medir
Lord Kelvin dijo: “Si no puedes medirlo, no es ciencia”. Encarnamos lo mismo y hacemos una ciencia de la medición de la disponibilidad y la fiabilidad. El estado visible para el usuario que ves en https://neonstatus.com/ es una vista de alto nivel. Internamente, medimos Indicadores de Nivel de Servicio (SLI) y establecemos objetivos (SLO) para todos los componentes del sistema y operaciones importantes, especialmente las que ven los usuarios. Por ejemplo, medimos:
- Disponibilidad de la base de datos: Qué porcentaje del tiempo está disponible cada base de datos individual. No solo medimos la disponibilidad agregada de la flota, porque a un cliente individual no le importa si la flota tuvo una gran disponibilidad si su base de datos estuvo inactiva.
- Tiempo de inicio de la base de datos: Qué tan rápido una base de datos suspendida se vuelve disponible cuando te conectas, o qué tan rápido se inicia una base de datos completamente nueva.
- Cambio/failover de base de datos: Frecuencia y latencia. Tan infrecuente como sea posible, y tan rápido como sea posible cuando ocurra.
- Almacenamiento: Disponibilidad y latencia de lecturas de página y escrituras duraderas de Postgres al almacenamiento. Estos nos dicen si tu carga de trabajo obtiene lo que necesita.
- APIs del Plano de Control: Tasas de éxito y latencia de operaciones importantes como el branching.
Nuestro objetivo es que cada base de datos supere el 99.99% de disponibilidad cada mes. Medimos qué tan cerca estamos de ese objetivo con la consecución: Qué porcentaje de las bases de datos de la flota cumplieron el objetivo. A continuación se muestra la consecución de la disponibilidad de Neon hasta ahora en 2026 para bases de datos activas mensualmente.
Mes | Bases de datos cumplieron 99.95% | Bases de datos cumplieron 99.99% |
2026-01 | 99.96% | 99.85% |
2026-02 | 99.95% | 99.84% |
2026-03 | 99.96% | 99.81% |
2026-04 | 99.93% | 99.75% |
La fiabilidad y disponibilidad de primer nivel son de suma importancia en los sistemas operativos. Estamos trabajando arduamente para construir tu confianza en nuestro servicio de base de datos.
El Equipo
El trabajo de fiabilidad anterior está siendo impulsado por personas que han dedicado sus carreras a construir y operar bases de datos relacionales. Algunos de ellos:
- Jasraj Dange - Líder de ingeniería en Lakebase, anteriormente lideró trabajos en Azure SQL Database Performance, Scalability y en hacer de Azure SQL Database una plataforma robusta para Aplicaciones.
- Hans Norheim - Enfocado en la disponibilidad y fiabilidad de Lakebase, pasó 13 años en Microsoft trabajando en SQL Server y Azure SQL Database, incluida la tecnología de hot patching que permite actualizar SQL Server sin tiempo de inactividad, y la orquestación de actualizaciones que mantiene a Azure SQL Database con su SLA de tiempo de actividad del 99.995%.
- Stas Kelvich - Ahora trabajando en Lakebase después de cofundar Neon. Antes de Neon, trabajó en internos de Postgres en Postgres Professional durante cinco años, incluida la replicación multi-maestro tolerante a fallos con commit de quorum, aislamiento de instantáneas entre nodos utilizando relojes débilmente sincronizados, y mejoras en el commit de dos fases y la replicación lógica.
- John Spray - Liderando Lakebase Storage. Anteriormente lideró almacenamiento y cómputo, impulsando mejoras clave para la escala como el sharding. Antes de eso, trabajó en almacenamiento y sistemas distribuidos en Redpanda, Red Hat (Ceph) e Intel.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.