Cómo transformar flujos de trabajo de activación de documentos con Genie y Agent Bricks
Convierta documentos en valiosas perspectivas de negocio con Databricks
por Elena Tesser
-Los flujos de trabajo manuales de extracción de documentos en industrias como medios, comunicaciones y juegos ralentizan a los equipos, filtran ingresos y aumentan el riesgo de cumplimiento.
-Las empresas pueden unir AI/BI Genie, Agent Bricks y Unity Catalog para establecer un flujo de trabajo riguroso de múltiples agentes que puede convertir documentos clave en marketing, legal, finanzas, RR. HH. y más en datos gobernados, buscables y accionables.
-Al pasar de la extracción a la orquestación de múltiples agentes y la escritura de sistemas, las organizaciones pueden fluir sin problemas desde el procesamiento, la lectura hasta la activación de sus documentos.
Existe una brecha de inteligencia documental en las empresas actuales
Las organizaciones funcionan con montañas de documentos, desde contratos, acuerdos de empleo, acuerdos de talento y NDA, hasta órdenes de inserción publicitaria y acuerdos maestros de servicio y más. Cada documento contiene información valiosa sobre ingresos potenciales, riesgos y obligaciones, sin embargo, la forma en que la mayoría de las organizaciones trabajan con ellos no ha cambiado mucho en décadas.
Sin embargo, hoy en día, incluso cuando las organizaciones integran cada vez más la IA para ayudarles a avanzar más rápido, muchos equipos todavía dependen de humanos para leer PDFs, copiar campos en hojas de cálculo y volver a introducir datos en sistemas ERP, CRM y de planificación. Todo esto crea un riesgo significativo; los flujos de trabajo de procesamiento manual generan retrasos y pérdidas de ingresos potenciales debido a errores humanos, mientras que la falta de gobernanza significa que los equipos no pueden auditar de manera confiable sus informes.
Las herramientas puntuales y las arquitecturas heredadas se están quedando cortas
Los líderes entienden que la automatización con IA puede ayudarles a superar estos desafíos. Sin embargo, muchos son reacios a integrar completamente la IA en sus flujos de trabajo, ya que las inversiones tempranas como motores OCR, sistemas de gestión del ciclo de vida de contratos y soluciones puntuales específicas de dominio a menudo han cumplido poco. Incluso cuando las organizaciones experimentan con GenAI, muchos equipos de finanzas, legales y operaciones todavía informan poco valor realizado de las inversiones en IA. El problema, sin embargo, no es la automatización con IA en sí, sino las bases de datos fragmentadas e incompletas sobre las que se asientan estas herramientas tempranas.
Sin una base de datos unificada y bien gobernada, carecen de contexto industrial y organizacional, están aisladas de los sistemas empresariales clave y solo están diseñadas para leer, no para activar. Lo que es peor, cuando intentas construir un flujo de trabajo de agente sobre esto, obtienes una experiencia desarticulada, inconsistente e imposible de escalar.
Adoptar un enfoque de plataforma para la activación de documentos
El momento decisivo para la inteligencia documental llega cuando una empresa evoluciona de gestionar flujos de trabajo con soluciones de herramientas puntuales a construirlos sobre una base de datos unificada y gobernada. Este cambio abre la puerta a una experiencia multiagente verdaderamente unificada y escalable que permite a usuarios técnicos y no técnicos consultar sus datos empresariales estructurados y no estructurados, y luego tomar medidas apropiadas sobre esos datos.
Tres capacidades principales de Databricks hacen esto posible:
- AI/BI Genie: una experiencia de BI nativa de IA que permite a los usuarios de negocios hacer preguntas en lenguaje natural sobre tablas Delta gobernadas, sin escribir SQL.
- Agent Bricks: bloques de construcción reutilizables para agentes de producción de alta calidad, que incluyen extracción de información, asistentes de conocimiento y orquestación, que se construyen y optimizan sobre sus datos en lugar de ser prototipos únicos.
- Unity Catalog: gobernanza unificada, linaje y control de acceso granular sobre datos, agentes de IA e incluso servidores MCP, desde el documento fuente hasta la respuesta del agente y la retroalimentación del sistema.
El flujo de trabajo de activación de documentos multiagente
Sobre esta base, implementamos un flujo de trabajo de activación de documentos por fases que los equipos técnicos y no técnicos pueden adoptar y replicar paso a paso.
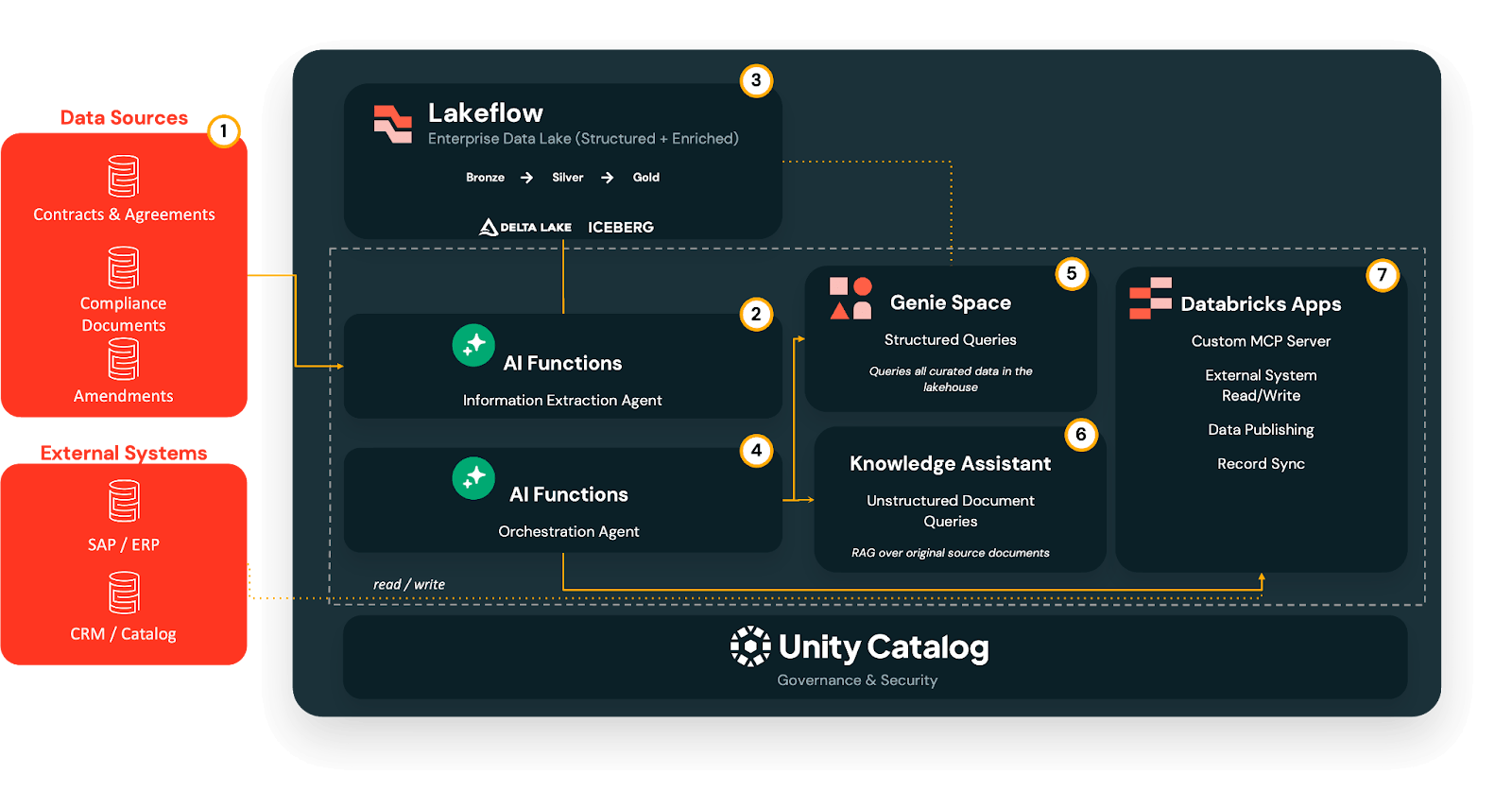
Fase 1 - Extraer: De PDFs a tablas Delta gobernadas
En la Fase 1, el Agente de Extracción de Información utiliza la extracción basada en LLM para convertir documentos no estructurados (PDF, DOC/DOCX, PPT/PPTX, imágenes) en campos estructurados, sin necesidad de crear canalizaciones OCR personalizadas o analizadores únicos.
Los resultados sin procesar llegan a una canalización de medallón Lakeflow:
- Bronce: campos extraídos sin procesar tal cual.
- Plata: valores limpios y estandarizados, con IDs canónicos resueltos y códigos normalizados.
- Oro: tablas listas para el negocio, optimizadas para consultas y análisis.
Esta extracción se ejecuta en el momento de la ingesta, no en el momento de la consulta, por lo que todo lo posterior se basa en una base de datos consistente y gobernada.
Fase 2: Consultar - Análisis de autoservicio con Genie
Una vez que los términos clave se estructuran en tablas Delta, AI/BI Genie proporciona a los usuarios de negocios una interfaz de autoservicio para hacer preguntas en inglés claro.
Apunte Genie a las tablas de la capa Gold y los usuarios podrán hacer preguntas como "¿Qué contratos expiran el próximo trimestre en EMEA?" o "¿Qué acuerdos de editor tienen tramos de participación en los ingresos que se activan por encima de un umbral de gasto determinado?". Genie luego traduce estas consultas a SQL, aplica los permisos de Unity Catalog y devuelve resultados tabulares o visuales, eliminando el cuello de botella del analista y manteniendo el acceso a los datos gobernado.
Fase 3: Comprender - Respuestas a nivel de cláusula con Knowledge Assistant
Algunas preguntas no se pueden responder solo con agregados. Los equipos legales, de derechos y de cumplimiento a menudo necesitan saber exactamente qué dice una cláusula específica.
Aquí, un Knowledge Assistant, un agente conversacional basado en RAG, se ejecuta directamente sobre los documentos fuente originales almacenados en los Volúmenes de Unity Catalog.
Puede responder preguntas como "¿Cuáles son las restricciones de sublicencia en el acuerdo de Warner?" o "¿Tenemos derechos SVOD para el Show X en Francia en 2027, y son exclusivos?". El asistente devuelve fragmentos a nivel de cláusula con citas a los PDFs originales, manteniendo una trazabilidad completa.
Fase 4: Orquestar — una única puerta de entrada con un supervisor multiagente
A medida que agregas más agentes, no quieres que los usuarios decidan qué herramienta abrir para cada pregunta.
El Multi-Agent Supervisor actúa como un único punto de entrada conversacional que analiza cada consulta y la dirige al especialista adecuado:
- Preguntas estructuradas → Genie Spaces
- Preguntas a nivel de cláusula → Knowledge Assistant
- Acciones del sistema → Conectores basados en MCP y flujos posteriores
Los usuarios simplemente hacen su pregunta y el supervisor selecciona el camino correcto, combinando contexto no estructurado y estructurado cuando es necesario.
Fase 5: Actuar — de la información a las actualizaciones del sistema con MCP
Finalmente, los servidores MCP convierten la comprensión de documentos en acción al envolver API de sistemas externos (ERP, HRIS, CRM, plataformas publicitarias, sistemas de derechos, Slack) como herramientas que el supervisor puede llamar.
Esto le permite tomar el mejor curso de acción basado en los datos extraídos y el contexto organizacional. Los ejemplos incluyen::
- Insertar datos de derechos validados en SAP y sincronizarlos con un catálogo de títulos o CRM.
- Actualizar derechos y paquetes en sistemas de facturación y atención al cliente basándose en los términos extraídos.
- Desencadenar flujos de trabajo en herramientas de gestión de proyectos o de tickets cuando se detectan plazos regulatorios u obligaciones de compensación.
Por último, dado que todo esto está gobernado por Unity Catalog, cada campo sigue siendo rastreable hasta el documento del que proviene, con linaje y pistas de auditoría a través de agentes y retroalimentación del sistema.
Casos de uso específicos de la industria en medios, agencias, ad tech y telecomunicaciones
Este flujo de trabajo de activación de documentos se puede aplicar en una amplia gama de industrias y casos de uso. Sin embargo, puede ser especialmente impactante para industrias como Telecomunicaciones y Medios y Entretenimiento, donde los clientes se basan en grandes cantidades de datos estructurados y no estructurados en rápida evolución dentro de sus documentos. Sin importar la necesidad comercial o el perfil, existe una aplicación para convertir documentos relevantes en información limpia y gobernada y la siguiente acción apropiada.
- Editores de medios y estudios
- Rastrear contratos de derechos y licencias, responder preguntas como "¿Tenemos derechos de transmisión para el Título X en Alemania hasta 2027?" y marcar proactivamente los contratos que expiran en los próximos 90 días.
- Extraer términos de participación en los ingresos y distribución en tablas estructuradas y canalizar números validados en sistemas ERP y de planificación.

- Agencias de medios
- Extraiga listas de tarifas, umbrales de AVB y desencadenantes de facturación de los contratos de compra de medios, y concilielos automáticamente con la entrega y el gasto.
- Estructure los briefs de clientes y los informes de investigación en datos reutilizables para sistemas de planificación y análisis de campañas.
- Plataformas de Ad Tech
- Active las regulaciones de privacidad y los documentos de políticas de publicidad para responder a “¿Qué regulaciones activas requieren mecanismos de exclusión voluntaria para la orientación conductual?” y aplique controles en los motores de consentimiento y políticas.
- Rastree los términos de licencias de datos y API para evitar el entrenamiento o la activación de modelos no conformes.
- Proveedores de telecomunicaciones
- Gestione los acuerdos de servicio y mayoristas, los términos de los acuerdos de roaming e interconexión, y los arrendamientos de torres, con una visibilidad clara de los SLA, los escaladores y las ventanas de renovación.
- Goberne los derechos y paquetes de los clientes de extremo a extremo, sincronizando los derechos validados con los sistemas de facturación, CRM y soporte.
En todos estos escenarios, los clientes ven mejoras como un cierre de mes más rápido, ingresos recuperados, reducción de fugas y menor riesgo operativo, todo ello reduciendo el esfuerzo manual para los equipos de finanzas, legal, operaciones y marketing.
Próximos pasos
Si sus equipos todavía dependen de flujos de trabajo manuales de documentos y herramientas desconectadas, ahora es el momento de modernizar la inteligencia de documentos en una plataforma de datos e IA gobernada.
- Explore Databricks para medios y entretenimiento y telecomunicaciones para ver cómo los contratos, las políticas y los acuerdos encajan en su estrategia de datos más amplia.
- Hable con su equipo de cuentas de Databricks sobre una prueba de valor de activación de documentos enfocada, comenzando con un caso de uso de alto impacto y una sola línea de negocio.
- Profundice en historias de clientes como SEGA, First American, y Vale para ver cómo las organizaciones ya están convirtiendo documentos no estructurados en datos gobernados y accionables a escala.
Al unificar la extracción, consulta, RAG, orquestación y escritura de sistemas en Databricks, puede ir más allá de simplemente “leer documentos” para activarlos, desbloqueando así nuevos ingresos, reduciendo el riesgo y liberando a sus equipos para que se concentren en trabajos de mayor valor.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.