Ingesta de la Vía Láctea: a escala de petabytes con Zerobus Ingest
Un análisis profundo de la arquitectura que permite alcanzar 12 GB/s por tabla, y sus posibilidades ilimitadas
por Aleksandar Tomić, Victoria Bukta, Nikola Obradović, Danilo Najkov, Branko Grbić y Milos Milovanovic
- Databricks Zerobus Ingest es una API de streaming serverless que permite a los equipos implementar de forma instantánea pipelines de datos a escala de petabytes sin una gestión manual de la infraestructura.
- La arquitectura de Zerobus se basa en el particionamiento dinámico para escalar automáticamente los recursos de computación, gestionando de manera eficiente volúmenes de datos impredecibles sin necesidad de optimizaciones complejas.
- Este framework sin configuración previa procesa fácilmente cargas de trabajo masivas, demostrando la capacidad de sostener un rendimiento de más de 12 GB/s en una sola tabla durante benchmarks de 24 horas.
Los datos de telemetría están en todas partes. Sensores de IoT en las plantas de fabricación. Sistemas de satélites que escanean la atmósfera. Los vehículos autónomos registran miles de eventos por segundo. Cada uno de estos sistemas tiene el mismo problema subyacente: un flujo continuo y de gran volumen de observaciones de series temporales que debe almacenarse en algún lugar donde se pueda consultar. Debe ser rápido, confiable y sin necesidad de que un equipo de ingeniería pase semanas optimizando y manteniendo la infraestructura típica de las cargas de trabajo basadas en Kafka.
Ese es el problema que Zerobus Ingest está diseñado para resolver. Zerobus es el servicio de ingesta de streaming serverless y totalmente administrado de Databricks. Es una API basada en push que acepta datos de cualquier productor y los escribe directamente en tablas Delta, gobernadas por Unity Catalog.
- Sin infraestructura que aprovisionar.
- Sin pipelines de conectores que mantener.
- Sin particiones ni toma de decisiones por parte del broker.
En su lugar, creas una tabla y envías los datos. Llegan a tu lakehouse, listos para ser consultados en segundos. Ya no necesitas ejecutar Kafka como una canalización cuando tu destino es el lakehouse.
Utilizamos el conjunto de datos NEOWISE de la NASA, que representa 200 mil millones de puntos de datos a lo largo de 11 años, para realizar una prueba de rendimiento de Zerobus Ingest, ingiriendo 1 petabyte en menos de 24 horas, con cero preconfiguración y una latencia estable.
Al ingerir 1 PB en 24 horas, demostramos la capacidad de Zerobus para mantener un rendimiento continuo de 12 GB/s en una sola tabla. 🚀
Ahora a escala de petabytes: streaming de la Vía Láctea (12 GB/s/tabla)
Para obtener más información sobre cómo ejecutar la prueba de rendimiento tú mismo, lee este blog complementario en la Comunidad de Databricks.
Este artículo analiza tres de las decisiones de diseño que hicieron esto posible.
- Diseñar un sistema que se escala automáticamente mediante particionamiento dinámico.
- Crear nuestro propio decodificador protobuf zero-copy propio.
- Implementar un write-ahead log optimizado para la latencia antes de que los datos se publiquen en el lakehouse.
Nuestras decisiones de diseño clave
Nuestra aspiración era crear un sistema de streaming que pudiera soportar la escala de petabytes y escalarse automáticamente para manejar patrones de ingesta fluctuantes.
Las arquitecturas de streaming tradicionales requieren que decidas cuántos brokers y particiones necesita una carga de trabajo determinada. Esto requiere conocer la carga máxima y las limitaciones de ingesta de los consumidores, así como realizar previsiones y comprender el pipeline de extremo a extremo.
Volviendo a los principios fundamentales, diseñamos y construimos un sistema que se escala para manejar cargas de trabajo de tamaño de petabytes para los productores de datos de forma «mágicamente».
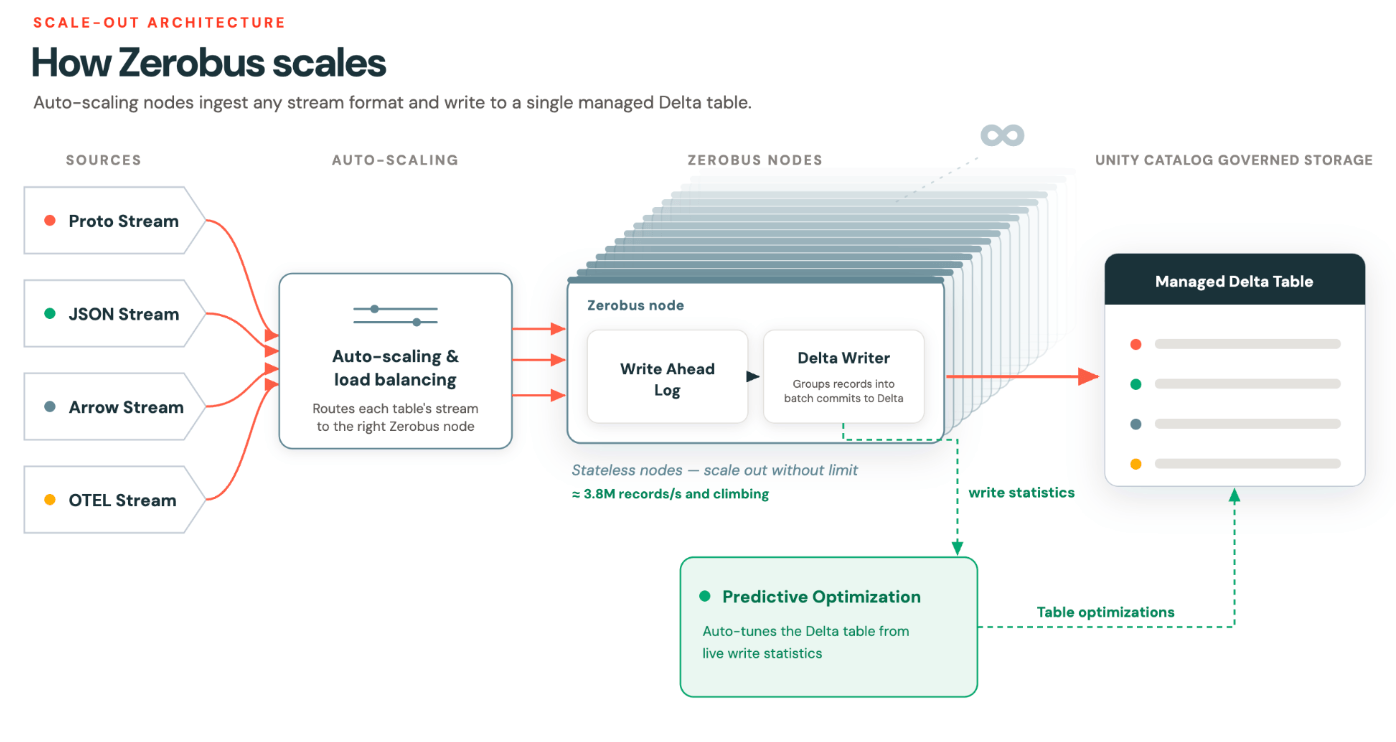
Escalado automático logrado mediante particionamiento dinámico
El problema que intentábamos resolver era cómo lograr un escalado automático eficiente para conseguir un escalado elástico «sin límites».
Nuestra tesis era que, al alejarnos del particionamiento estático y avanzar hacia la unidad lógica de una conexión/flujo (stream), podríamos desbloquear un verdadero escalado automático y un reequilibrio, manteniendo al mismo tiempo las garantías de orden, que son importantes para las cargas de trabajo de consumo.
El problema de las particiones estáticas
En las arquitecturas de bus de mensajes, las particiones son la unidad tanto de paralelismo como de ordenamiento. Este acoplamiento crea una limitación que puede resultar problemática una vez que tienes consumidores que dependen de ella.
El ordenamiento suele ser una garantía por partición, no por productor. El número de particiones y la distribución de los datos entre ellas afectan a la capacidad del consumidor para mantener el ritmo de la ingesta. Esto significa:
- Si el número de particiones cambia, la función de enrutamiento que asigna los mensajes de un productor a una partición ahora puede enviarlos a una partición diferente. El consumidor ahora tiene que conciliar esto.
- En la práctica, la mayoría de los equipos tratan la topología de particiones como inmutable. Realizas el aprovisionamiento para la carga máxima y mantienes esa infraestructura para siempre. Puedes agregar particiones, pero por lo general no puedes reducirlas de forma segura.
- La solución alternativa estándar es una clave de enrutamiento de partición derivada de un campo del mensaje. Esto ayuda con la consistencia del ordenamiento, pero sigue sin resolver el problema de la reducción de escala.
Trasladamos la garantía de ordenamiento a la conexión del flujo (stream)
En los sistemas tradicionales, el ordenamiento es una garantía a nivel de partición. En Zerobus Ingest, el ordenamiento es una garantía a nivel de conexión de flujo (stream).
Cuando un productor abre un flujo (stream) con Zerobus (una conexión a nuestro servidor), registra una identidad lógica con el servicio. Durante la vida útil de esa conexión, sus datos llegan en orden, independientemente de qué pod de «partición» los procese.
«Tu flujo está ordenado», no «tu partición está ordenada». Ese es el contrato.
Enrutamiento activo (hot routing) y verdadero escalado automático
Internamente, Zerobus Ingest distribuye los flujos a través de un grupo de pods. El enrutamiento se basa en heurísticas: si un pod está muy cargado (running hot), los nuevos flujos entrantes se enrutan a un pod diferente. El productor no se entera. Su garantía de ordenamiento no se ve afectada.
El ordenamiento vive a nivel de flujo, lo que significa que se pueden agregar pods cuando la demanda aumenta y eliminarlos cuando la demanda disminuye. Los flujos existentes se drenan de forma controlada y los nuevos flujos dejan de enrutarse allí. El grupo de pods se reduce, manteniendo la eficiencia en el uso de cómputo.
Este es un verdadero escalado automático. La unidad de granularidad es la conexión del flujo, no la asignación de particiones.
Nuestro diseño de particionamiento dinámico permite a Zerobus escalarse automáticamente a un rendimiento de más de 12 GB por segundo para una tabla, manteniendo al mismo tiempo la eficiencia de costos.
Manejo de datos de alto rendimiento con cero copias (zero-copy)
El objetivo principal de Zerobus es permitir una transferencia eficiente, fila por fila, de flujos de datos de cualquier volumen. Para lograr esto, necesitábamos evitar por completo cualquier copia y asignación de memoria innecesarias, desde los formatos de entrada que los clientes envían a Zerobus hasta los formatos internos que garantizan la durabilidad y los formatos abiertos de Delta.
Actualmente, Zerobus admite los siguientes formatos de mensaje.
Entre las muchas optimizaciones que realizamos, ilustraremos el enfoque zero-copy a través de ZeroParser, nuestro decodificador de protobuf personalizado.
Los decodificadores de protobuf estándar te obligan a elegir entre velocidad y flexibilidad. Los decodificadores de protobuf suelen basarse en la generación de código en tiempo de compilación (codegen) o en la reflexión en tiempo de ejecución (reflection).
- La generación de código es rápida, pero requiere descriptores en tiempo de compilación. Zerobus recibe descriptores de forma dinámica en tiempo de ejecución, a partir de esquemas de usuario arbitrarios. Codegen no es una opción.
- La reflexión en tiempo de ejecución resuelve el problema de la flexibilidad, pero crea uno de rendimiento. Los decodificadores dinámicos de protobuf son lentos y requieren la construcción de un gráfico de objetos en memoria en tiempo de ejecución, lo que genera muchas asignaciones de memoria pequeñas.
Ninguno de los dos enfoques era aceptable. Necesitábamos soporte de descriptores dinámicos con el perfil de rendimiento de codegen.
El resultado fue que creamos zeroparser: superando esta brecha mediante el uso de un análisis de una sola pasada (single-pass parsing) con cero asignaciones de memoria, lo que le permite mantener rendimientos de ~1 GB/s de análisis de protobuf por núcleo de CPU incluso con descriptores dinámicos y esquemas complejos.
Zeroparser permite el análisis directo del formato de transmisión (wire format) sin la deconstrucción de los objetos entrantes, lo que evita la copia y asignación de memoria. Con este enfoque, Zerobus puede lograr un mejor rendimiento que las soluciones de análisis de protobuf basadas en generación de código existentes, al tiempo que mantiene la total flexibilidad de proporcionar descriptores de protobuf de forma dinámica.
El sistema de tiempos de vida (lifetimes) de Rust fue fundamental para el diseño de Zeroparser: garantiza la seguridad en tiempo de compilación durante el análisis del protocolo, al tiempo que mantiene los bytes de transmisión sin procesar bajo la propiedad exclusiva de la red, eliminando copias de datos innecesarias.
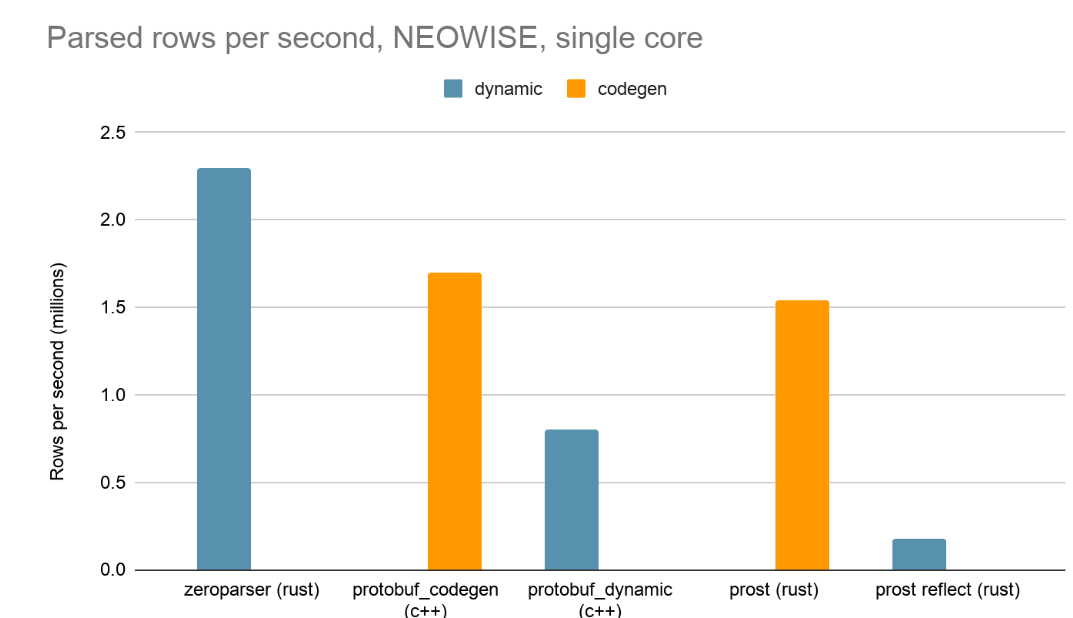
Los resultados muestran que Zeroparser, a pesar de estar en el grupo dinámico, superó a dos implementaciones basadas en codegen estándar de la industria.
Zeroparser es de código abierto como parte del SDK de Zerobus disponible aquí.
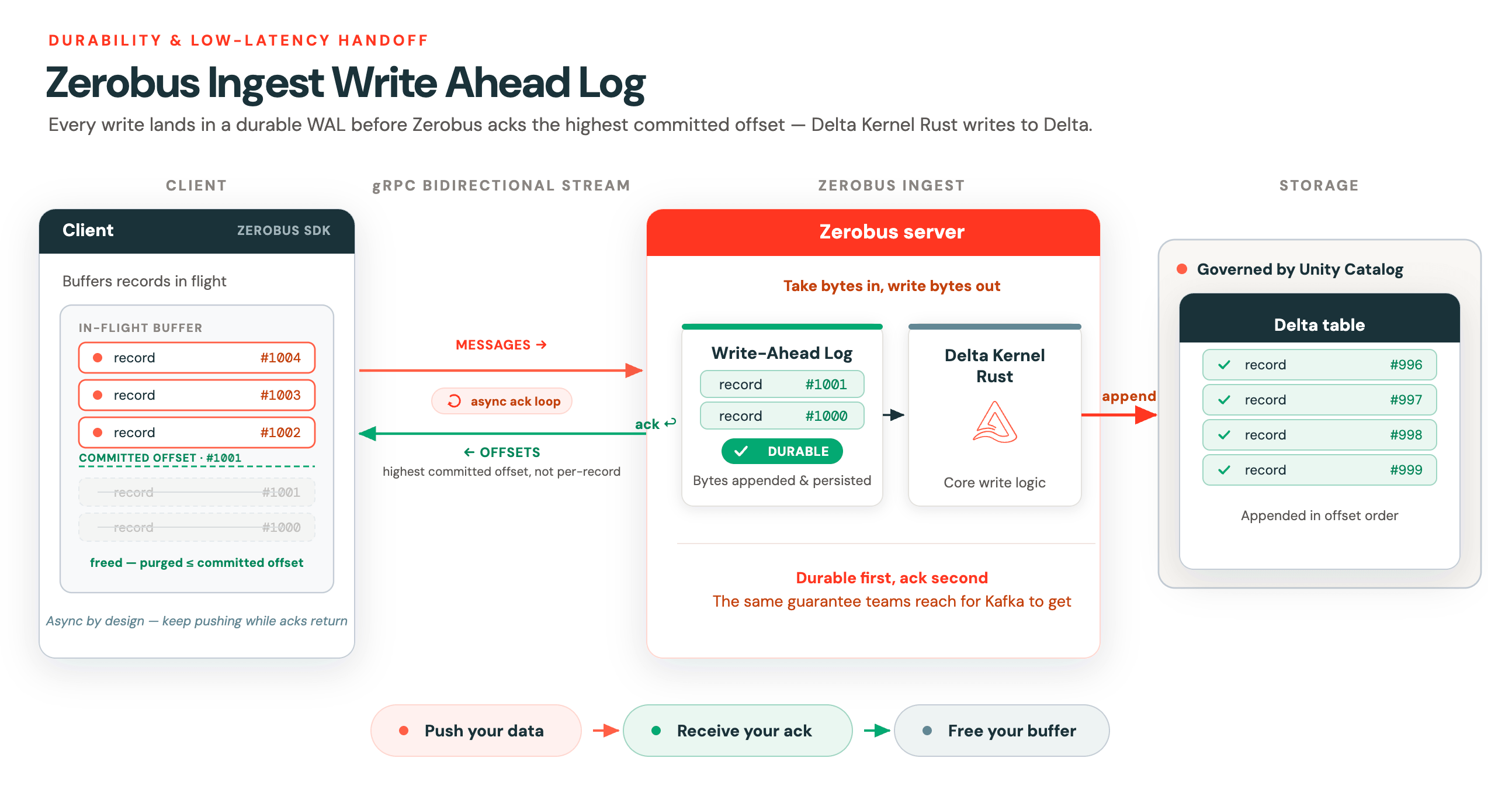
Write Ahead Log
El streaming no se trata solo de poder manejar cargas de trabajo de alto rendimiento. Para ser un verdadero servicio de streaming, también debe admitir la transferencia de mensajes lo más rápido posible. Esta baja latencia en la transferencia de datos es lo que realmente distingue a las cargas de trabajo de streaming de las de procesamiento por lotes (batch).
Para admitir esta transferencia de baja latencia con una garantía de durabilidad, Zerobus implementa un registro de escritura anticipada (WAL) optimizado para la latencia. Una vez que los mensajes son duraderos, Zerobus envía una confirmación (acknowledgement) de vuelta al cliente. En lugar de confirmar cada registro individualmente, el servidor devuelve el offset confirmado más alto en el stream. El resultado es este bucle de confirmación asíncrono (async ack loop). Luego, se utiliza Delta Kernel Rust para la lógica central de escritura en Delta.
Este diseño asíncrono es clave para los clientes que almacenan datos en tránsito (data in flight) en un búfer. Zerobus utiliza streaming bidireccional gRPC, donde cada stream de Zerobus tiene dos líneas de comunicación:
- Una para enviar mensajes
- La otra para recibir confirmaciones de offsets.
Una vez que el cliente recibe ese offset, puede depurar de forma segura todo hasta ese punto de su búfer local en tránsito. Todo esto lo manejan los SDK de Zerobus por ti.
El WAL es lo que mantiene a los clientes ligeros. Envía tus datos, recibe tu confirmación (ack), libera tu búfer. Esa transferencia de baja latencia y alta durabilidad siempre ha sido la razón por la que los equipos recurren a Kafka. Zerobus te ofrece la misma garantía.
Prueba: Ingesta de la Vía Láctea
La clave para realizar pruebas de rendimiento (benchmarking) de un sistema radica en comprender cómo se usaría en un entorno de producción y luego emular ese comportamiento y uso. Es por eso que, para poner a prueba Zerobus Ingest, decidimos elegir el conjunto de datos NEOWISE de la NASA y utilizamos Locust para emular patrones de concentración (fan-in) del mundo real.
¿Por qué Locust? El problema de la concentración (Fan-In)
Zerobus Ingest está diseñado para agregar streams de muchos productores independientes en una sola tabla de destino. Su rendimiento escala con la cantidad de streams abiertos concurrentes. Esto significa que no se puede poner a prueba de manera justa desde una sola máquina o un clúster pequeño. Un único host potente saturaría su propio ancho de banda o CPU antes de ejercer una presión significativa sobre nuestro servicio, lo que resultaría en una prueba de rendimiento del productor, no de Zerobus.
Para simular un patrón de concentración (fan-in) del mundo real, utilizamos Locust para coordinar la apertura de streams separados por pods para realizar pruebas de presión de la ingesta a escala.
El escalado automático de Zerobus responde entonces al recuento de streams y al rendimiento para gestionar la tasa de ingesta.
Configuración de la prueba
Nuestra prueba de rendimiento se implementó en Kubernetes con un maestro de Locust y una flota de trabajadores de Locust, cada uno ejecutándose como un pod independiente. Parámetros clave:
Cada worker recibe una lista única de archivos Parquet para ingestar. Un worker transmite su fragmento y no repite filas.
Los resultados
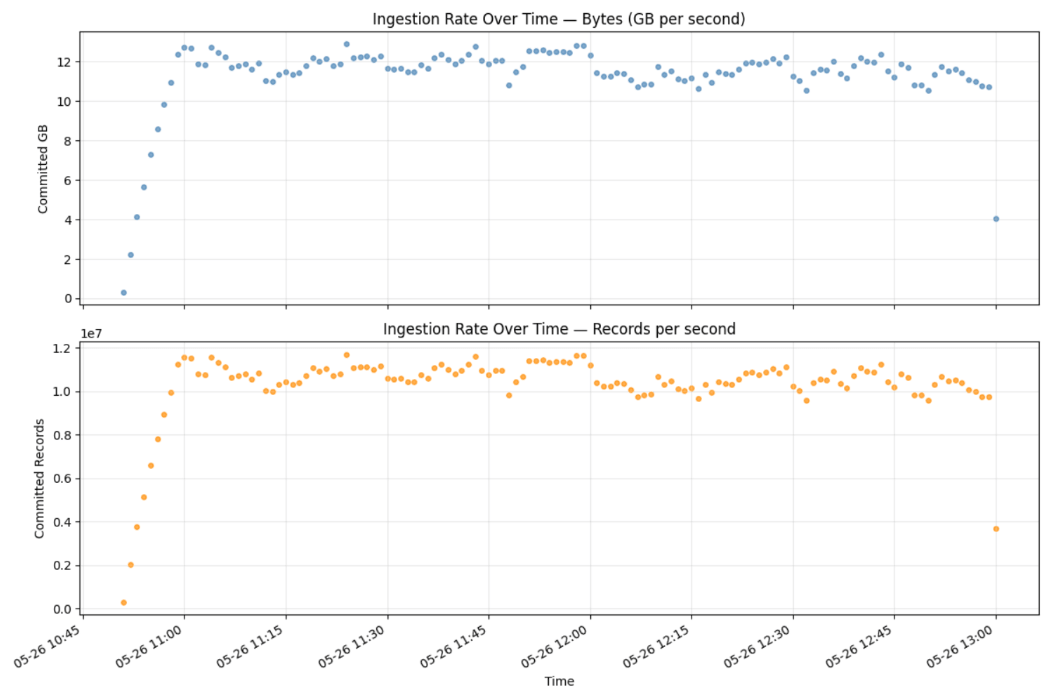
Los resultados de nuestras pruebas demostraron la capacidad de Zerobus Ingest para mantener 12 GB/s en una sola tabla durante un período de 24 horas a partir de 2.048 workers concurrentes en una sola tabla. Durante este período, Zerobus ingestó más de un billón de registros.
La agregación en intervalos de 5 segundos sobre la columna client_ts_ms ofrece una vista precisa y confirmada por el servidor de las filas confirmadas y los bytes recibidos:
Esta consulta se ejecuta en la tabla activa de Unity Catalog. Los números reflejan las filas que se confirmaron por completo en el almacenamiento de Delta.
¿Quieres ejecutarlo tú mismo?
El entorno de pruebas (benchmark) completo con la preparación del conjunto de datos, el código del productor y las instrucciones para ejecutarlo en tu propio endpoint de Zerobus. Consúltalo aquí.
Próximos pasos
Zerobus Ingest ya está disponible de forma general (GA) en Databricks y listo para todas tus cargas de trabajo de producción.
Nuestras métricas de rendimiento de 12 GB/s para una tabla son lo que obtienes de forma predeterminada con Zerobus Ingest. Puedes aumentar las cuotas poniéndote en contacto con tu equipo de cuenta.
En nuestra hoja de ruta:
- Soporte para la API Kafka Producer
- Soporte para la API de MQTT
- Columna de rescate
- Columna de metadatos del sistema
- Soporte para Avro
¡Cuéntanos qué te gustaría ver en el futuro de Zerobus! ¿Cuál crees que es la próxima frontera del streaming? Envíanos tus comentarios en nuestro blog complementario de la comunidad de Databricks.
Si estás listo para comenzar con Zerobus Ingest, consulta nuestra documentación técnica, el SDK de Zerobus Ingest o echa un vistazo al repositorio de GitHub con el benchmark de Neowise.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.