Observabilidad para cualquier agente, en cualquier lugar: Trazabilidad lista para producción con OpenTelemetry y Unity Catalog en Databricks
Los rastreos de OpenTelemetry en Unity Catalog crean un ciclo de mejora continua para los agentes de IA a través de análisis, evaluaciones y monitoreo.
por Firas Farah, Bruno Faria y Anoop Sunke
- El problema: Los agentes de IA generan volúmenes masivos de datos de rastreo, pero las herramientas de observabilidad tradicionales hacen que esos datos sean caros de retener, difíciles de gobernar y complicados de usar en flujos de trabajo de evaluación y análisis.
- La solución: Databricks ahora admite la escritura de rastreos de OpenTelemetry (OTel) directamente en tablas de Unity Catalog a través de una ruta de ingesta totalmente administrada y sin servidor.
- El beneficio: Al aterrizar los rastreos directamente en el Lakehouse, los equipos obtienen datos de observabilidad gobernados y listos para el análisis con retención a largo plazo, flujos de trabajo de evaluación y monitoreo unificados, y sin infraestructura OTel que operar.
- El resultado: Los rastreos de producción se vuelven inmediatamente utilizables para análisis y evaluación, lo que permite ciclos de iteración más rápidos entre el uso en el mundo real, la evaluación del modelo y la mejora continua.
Por qué el rastreo de IA rompe la observabilidad tradicional
A medida que las aplicaciones de IA pasan a producción, los rastreos se convierten en una de las formas más claras de entender cómo se comportan realmente los agentes, capturando indicaciones, llamadas a herramientas, respuestas, latencia y rutas de ejecución. Sin un rastreo sólido, es difícil entender por qué los agentes se comportan como lo hacen, lo que hace que la depuración, la evaluación y la gobernanza sean mucho más difíciles.
Los rastreos de IA se vuelven rápidamente valiosos para análisis, evaluación y flujos de trabajo de monitoreo más allá de los casos de uso tradicionales de depuración y observabilidad. Los equipos quieren conservarlos por más tiempo, analizarlos con SQL, unirlos con datos de negocios y modelos, y reutilizarlos para evaluación y monitoreo. Cuando los rastreos viven solo dentro de sistemas de observabilidad, esa flexibilidad es limitada, la gobernanza se fragmenta y mover datos a flujos de trabajo de análisis a menudo requiere canalizaciones y duplicaciones adicionales, especialmente cuando se trata de datos de indicaciones confidenciales.
Ingesta de rastreos OTel
Databricks ahora admite la escritura de rastreos OTel directamente en Unity Catalog utilizando el formato OpenTelemetry (OTel). En la práctica, esto significa que los rastreos se pueden ingerir en tiempo real y almacenar en tablas Delta, donde se benefician de la misma escalabilidad, gobernanza y herramientas que el resto de sus datos.
Esto cambia la forma en que los equipos pueden usar los datos de rastreo:
- Ingesta en tiempo real con retención práctica: Los rastreos se pueden escribir a medida que se generan con alto rendimiento y retener a largo plazo sin la presión de costos típicamente asociada con las plataformas de observabilidad.
- Analizar y gobernar usando el Lakehouse: Una vez que los rastreos están en tablas, puede tratarlos como cualquier otro conjunto de datos: consultarlos con SQL, crear paneles, ejecutar canalizaciones ETL, usar herramientas como Genie y aplicar controles de gobernanza como el enmascaramiento de PII.
- Usar la pila completa de evaluación de MLflow: MLflow facilita la búsqueda, el filtrado y el análisis detallado de sus rastreos para depuración. Persistir rastreos en Unity Catalog elimina las restricciones típicas de experimentos (como límites de rastreo), lo que facilita la ejecución de evaluaciones sin conexión a gran escala, el monitoreo de sistemas de producción y la mejora continua de la calidad a medida que crecen las cargas de trabajo.
SaaS vs. Lakehouse
Entonces, ¿por qué no depender completamente de una herramienta de observabilidad SaaS?
- Economía de retención: Los agentes generan cargas útiles de texto masivas. Almacenar estos datos en Delta Lake en almacenamiento de objetos suele ser significativamente más rentable que los modelos de retención basados en SaaS.
- El punto muerto de PII: Enviar indicaciones sin procesar a plataformas de terceros puede crear fricción en InfoSec. Mantener los rastreos dentro de Unity Catalog ayuda a mantener la soberanía de los datos y simplifica la gobernanza.
- Análisis, no solo telemetría: Si bien las herramientas SaaS son sólidas para métricas operativas como la latencia, el Lakehouse proporciona un motor de análisis. Puede unir rastreos con datos de negocios, como ingresos y conversiones, para comprender el impacto real y ir más allá de la salud del sistema. Además, el Lakehouse le permite aplicar IA directamente a sus rastreos y crear marcos de evaluación para mejorar continuamente la calidad del sistema.
Arquitectura: Ingesta de OpenTelemetry sin servidor
Databricks admite la ingesta de rastreos, registros y métricas de OpenTelemetry (OTel) directamente en tablas de Unity Catalog, utilizando el estándar OTel para separar la instrumentación del almacenamiento.
Databricks elimina la complejidad operativa de las canalizaciones de telemetría tradicionales de varios saltos al proporcionar una capa de ingesta administrada, impulsada de forma transparente por Zerobus Ingest. Zerobus Ingest actúa como un motor de ingesta completamente administrado y sin servidor que admite de forma nativa protocolos OpenTelemetry estándar (OTLP) a través de gRPC para colectores de código abierto, mientras que sus capacidades de API REST permiten una integración perfecta con marcos de aplicaciones como MLflow. Las aplicaciones pueden exportar fácilmente spans, registros y métricas directamente a tablas de Unity Catalog, donde los datos se almacenan en formato Delta. Con una arquitectura de "único destino", Zerobus Ingest simplifica la observabilidad al transmitir datos directamente al lakehouse. Los colectores compatibles con OLTP existentes pueden apuntar directamente a este punto final a través de gRPC, omitiendo por completo los buses de mensajes intermedios como Kafka. Zerobus Ingest actúa como su canalización de telemetría de alto rendimiento, manejando la ingesta y la durabilidad con cero sobrecarga de infraestructura. Cualquier cliente compatible con OTel puede exportar rastreos a este punto final, incluidos los marcos de agentes de IA populares en muchos lenguajes de programación.
A partir de ahí, los rastreos, registros y métricas se convierten en datos de primera clase en el Lakehouse, impulsando análisis SQL ad hoc, paneles, análisis descendentes y flujos de trabajo de evaluación y monitoreo de MLflow. La unificación de su telemetría crea un ciclo de mejora continua donde el comportamiento de producción alimenta la evaluación y el análisis, lo que a su vez impulsa una iteración más rápida y un mejor rendimiento del agente.
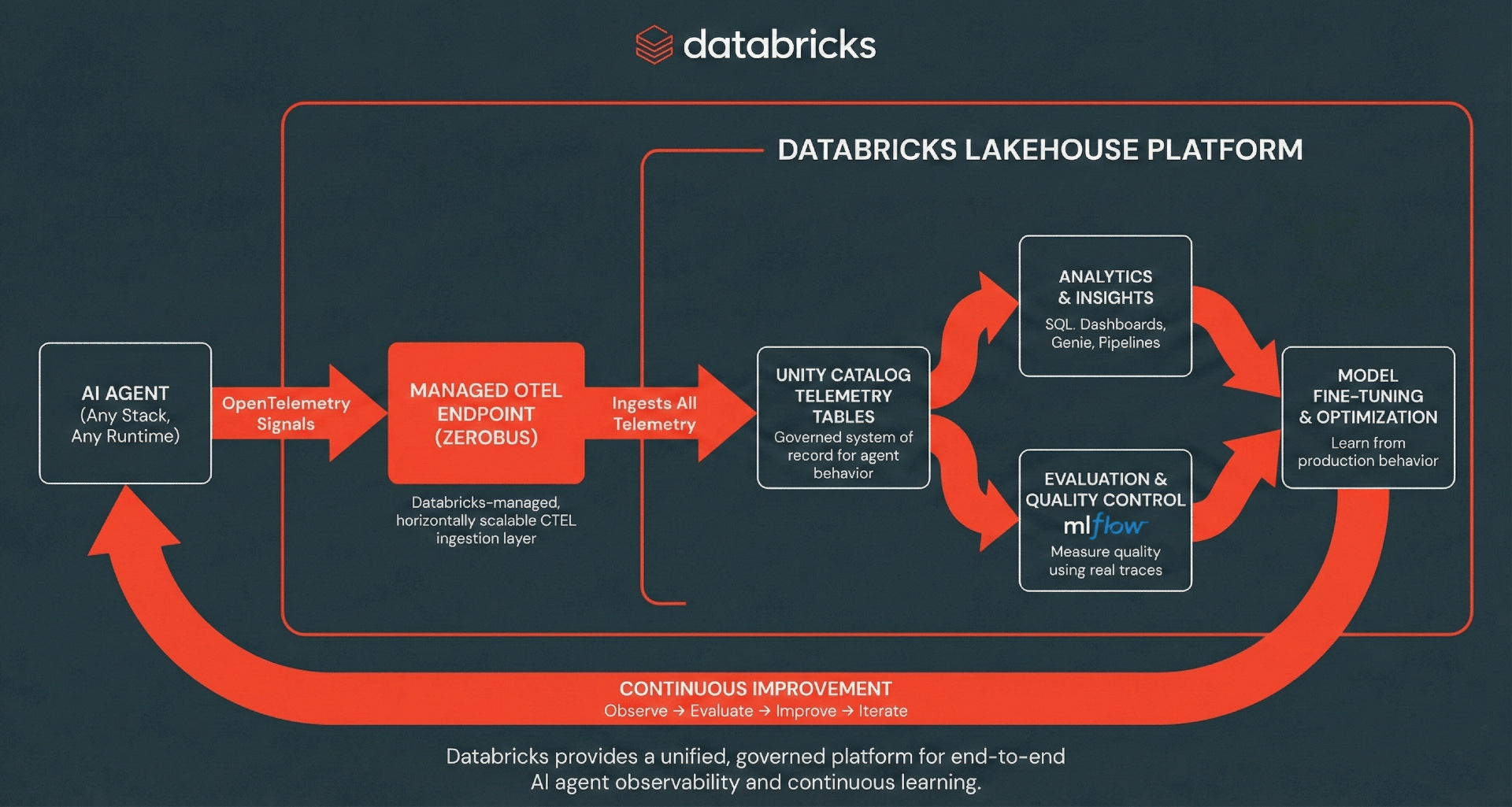
Tutorial: Conectando rastreos al Lakehouse
Agente de ejemplo: Asistente de gerente de soporte
Para esta publicación de blog, crearemos un asistente simple de gerente de soporte que podemos usar para demostrar el rastreo de extremo a extremo. El agente se puede implementar fuera de Databricks, como lo hemos hecho aquí, lo que resalta que la ingesta de rastreos está desacoplada de dónde se ejecuta el agente.
Construimos un agente LangGraph impulsado por un modelo Claude Sonnet 4.6 alojado en Databricks para razonamiento y generación de respuestas. El agente llama a un Genie Space como herramienta, que puede implementar aquí.
Cuando un usuario hace una pregunta basada en datos, el agente invoca Genie a través de la API de herramientas MCP. Genie traduce la solicitud a SQL, la ejecuta contra el conjunto de datos de soporte y devuelve el resultado. Luego, el agente resume los hallazgos y proporciona información procesable para un gerente de soporte.

Configuración del rastreo OTel con UC
Antes de instrumentar el agente, primero configuramos las tablas en UC que almacenarán los rastreos de OpenTelemetry. En este ejemplo, usamos MLflow para crear las tablas subyacentes de OpenTelemetry en Unity Catalog y vincularlas a un experimento de MLflow para que los rastreos se puedan buscar, analizar y anotar desde la interfaz de usuario. Comience por identificar (o crear) un almacén SQL y un experimento de MLflow, luego use la biblioteca Python de MLflow para aprovisionar las tablas de Unity Catalog y asociar el esquema con el experimento. Para obtener los pasos completos, siga la documentación aquí.
Esta configuración crea tablas de Unity Catalog para spans, logs y métricas de OpenTelemetry. Los datos subyacentes se almacenan en formatos de tabla compatibles con OpenTelemetry, y el servicio MLflow crea automáticamente vistas de Databricks SQL junto con ellas que transforman los datos de OpenTelemetry en un formato amigable para MLflow para facilitar la consulta y el análisis. Estos incluyen:
<table_prefix>_otel_spans: datos detallados de ejecución a nivel de span para cada solicitud<table_prefix>_otel_logs: datos de registro/evento estructurados capturados durante la ejecución<table_prefix>_otel_metrics: telemetría numérica capturada durante la ejecución<table_prefix>_otel_annotations: datos de rastreo específicos de MLflow que no son una señal OTel estándar, incluidos metadatos, etiquetas, evaluaciones/comentarios, expectativas y enlaces de ejecución<table_prefix>_trace_unified: una vista consolidada que ensambla datos de rastreo en un solo registro por rastreo, incluidos datos de span sin procesar y metadatos de rastreo<table_prefix>_trace_metadata: Etiquetas, metadatos y evaluaciones de MLflow agrupados por ID de traza; más eficiente que la vista unificada cuando solo necesitas metadatos de trazas de MLflow
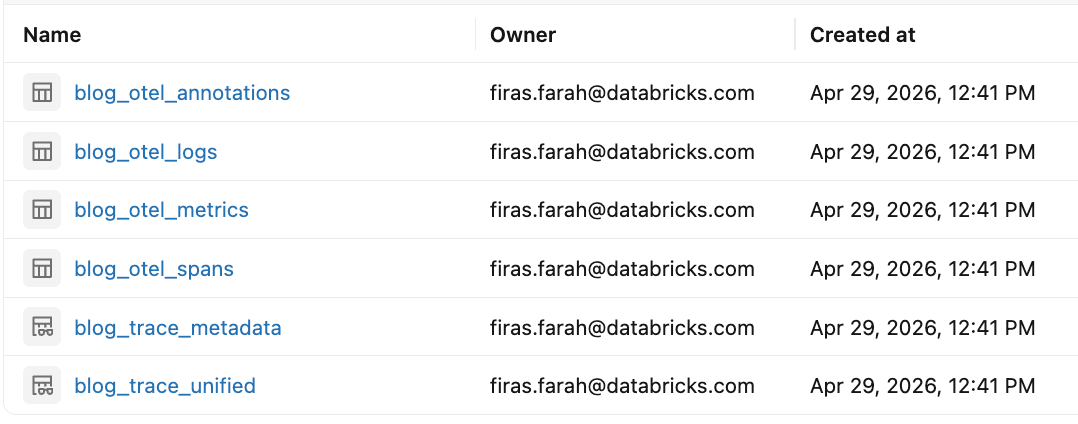
Después de configurar el experimento, la instrumentación del agente sigue siendo la misma. Cualquier biblioteca de instrumentación compatible con OTel puede exportar trazas al endpoint configurado. Puedes realizar un rastreo automático y/o manual como se describe aquí. En nuestro ejemplo, confiamos en mlflow.langchain.autolog() para capturar la ejecución detallada de LangGraph (llamadas a modelos y llamadas a herramientas). También envolvemos el punto de entrada con @MLflow.trace para establecer un span raíz a nivel de solicitud, lo que permite que cada invocación se observe como una ejecución completa de principio a fin.
Inspeccionando una traza de ejemplo
Ahora que el agente está instrumentado y las trazas fluyen hacia Unity Catalog, veamos una ejecución real.
Para este ejemplo, le preguntamos al Asistente de Gerente de Soporte:
"¿A qué ingeniero de soporte debería proponer para un ascenso?"
El agente evaluó la solicitud, llamó al espacio Genie varias veces para recopilar datos de apoyo y devolvió una recomendación basada en métricas de rendimiento.

Si bien la respuesta parece sencilla, la traza revela la ruta de ejecución subyacente que la produjo. En el experimento de MLflow, podemos ver cada una de las llamadas a herramientas, así como la lógica de razonamiento de nuestro modelo claude sonnet. Podemos ver que llamó a la herramienta del espacio Genie tres veces antes de armar una respuesta final.
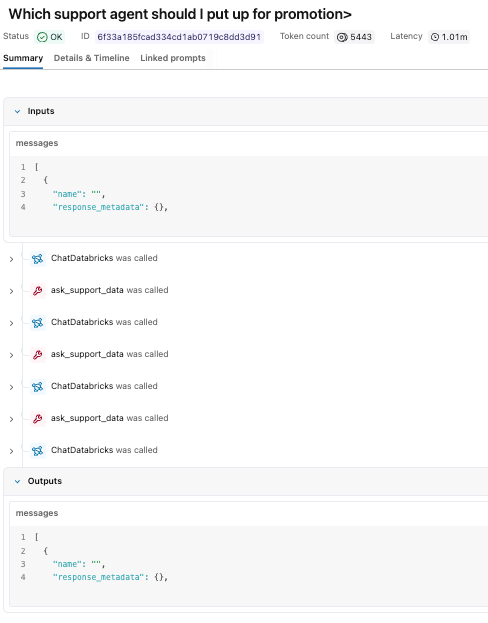
Podemos hacer clic en cada uno de los pasos individuales para estudiar las entradas y salidas.
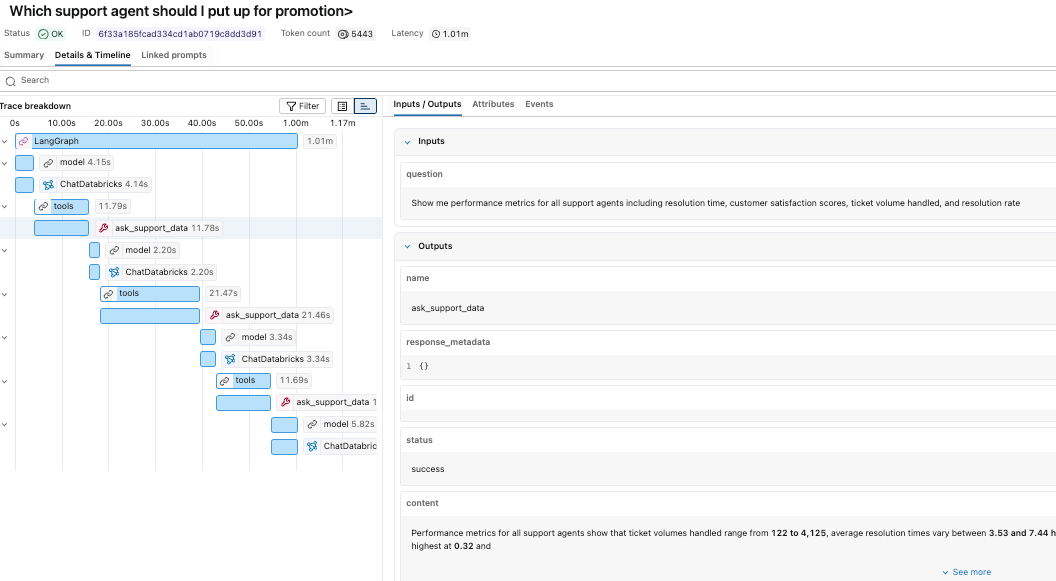
Dado que las trazas se almacenan como tablas Delta, se pueden consultar como cualquier otro conjunto de datos. Podemos comenzar con la vista mlflow_experiment_trace_unified, donde encontraremos un registro que incluye la solicitud, la respuesta, los metadatos de la traza y una matriz de los spans.
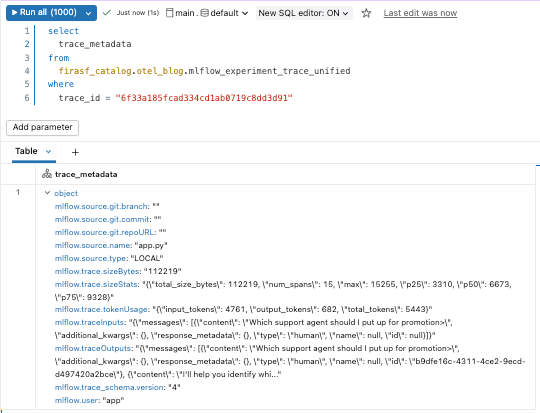
Más allá de la depuración: análisis de datos de trazas
Ahora que las trazas se almacenan en Unity Catalog, están disponibles inmediatamente para análisis de lotes y de transmisión.
Gobernanza en Unity Catalog
Sin embargo, los prompts y las respuestas a menudo contienen información confidencial, por lo que tratar los datos de trazas como datos gobernados es fundamental. Al almacenarlos en Unity Catalog, las trazas heredan controles de acceso detallados, desde permisos de catálogo y esquema hasta enmascaramiento de columnas y filtrado a nivel de fila, lo que permite análisis seguros y listos para producción sin limitar la flexibilidad.
Una vez establecido el acceso, los equipos pueden ejecutar de forma segura análisis ad hoc consultando las tablas y vistas subyacentes con SQL, como hicimos anteriormente. También podemos crear pipelines ETL, además de dashboards y espacios Genie, para obtener información empresarial procesable.
Dashboards
La interfaz de usuario de Experimentos de MLflow ahora incluye dashboards de observabilidad nativos para trazas en Unity Catalog, que incluyen vistas de volumen de trazas, errores, latencia, uso de tokens y costos. Para la mayoría de los equipos, eso es suficiente para monitorear la salud del agente día a día.
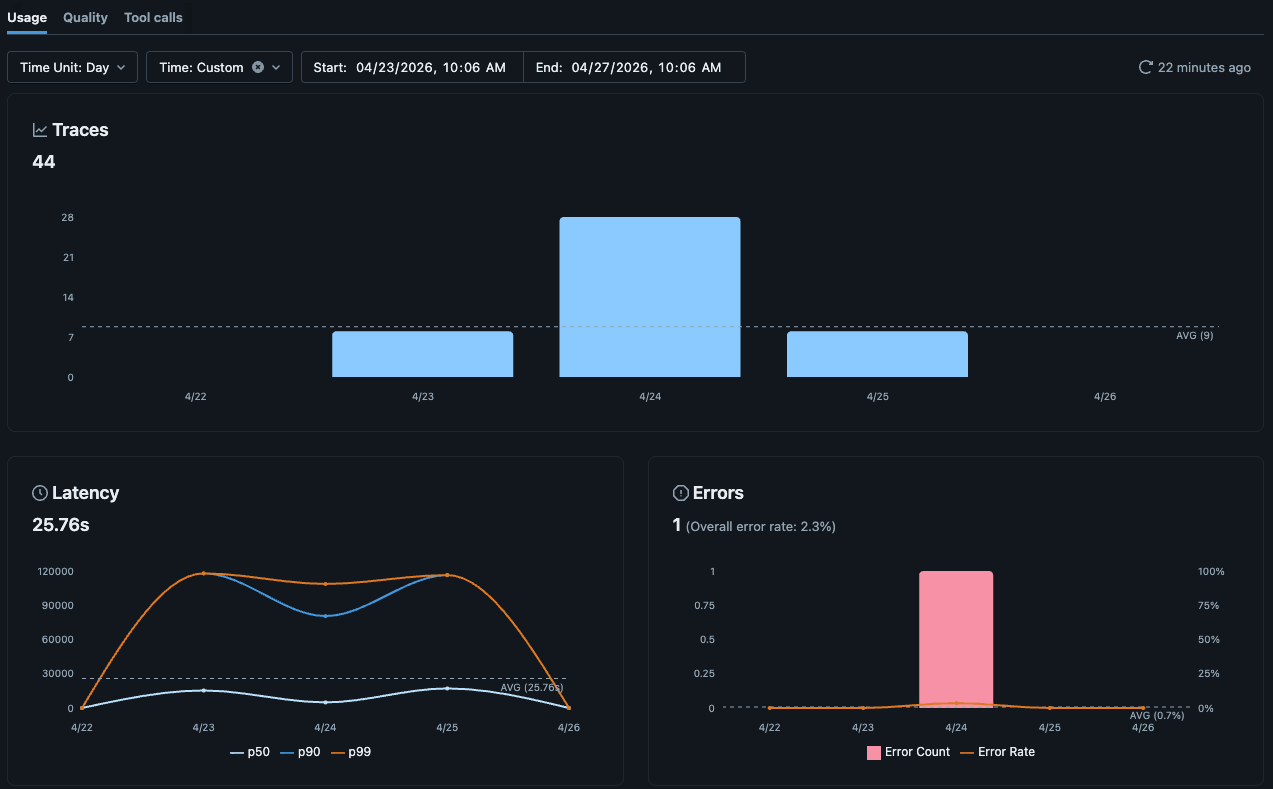
Cuando necesites una vista que vaya más allá de las visualizaciones nativas, las tablas de trazas siguen siendo simplemente tablas Delta en Unity Catalog. Puedes crear un Dashboard personalizado de IA/BI sobre ellas y escribir SQL estándar (con ayuda de IA) para modelar lo que sea importante para tu equipo.
Para mostrar lo que los dashboards personalizados pueden agregar a las vistas nativas, creamos un Centro de Operaciones de IA sobre nuestras tablas de trazas. A continuación, se mencionan un par de capacidades que vale la pena destacar.
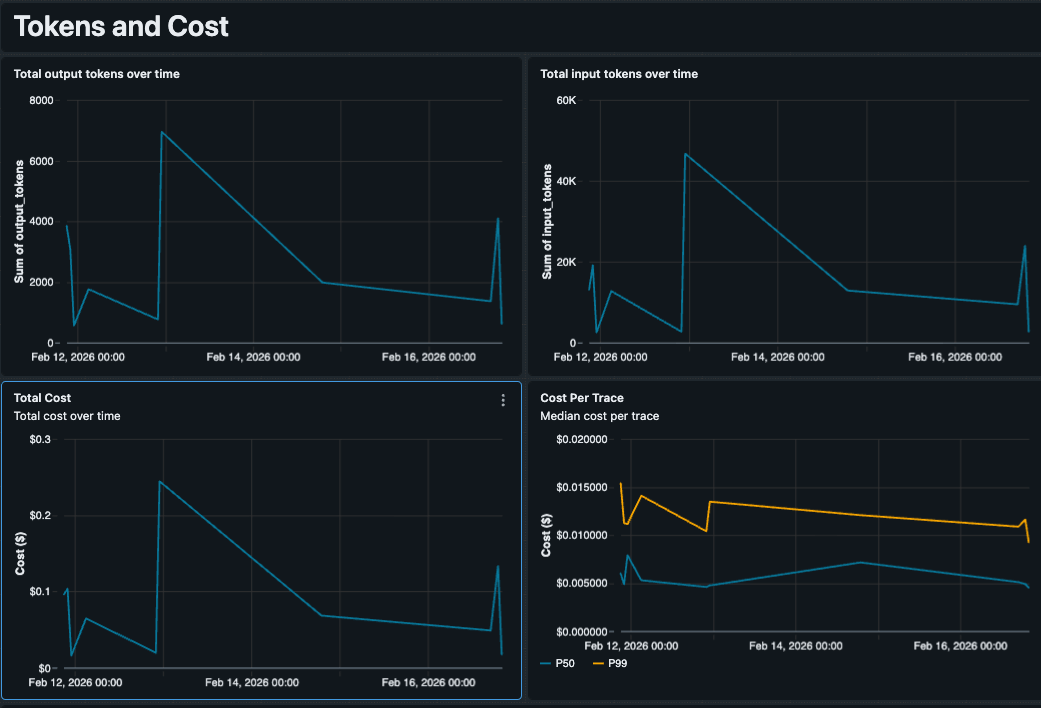
Análisis de costos personalizado con precios de contrato
Las métricas de costos nativas se basan en precios de lista estándar, lo que puede ser impreciso para equipos que han negociado tarifas o ejecutan modelos ajustados con precios diferentes. Como controlamos el SQL, incrustamos nuestra lógica de precios directamente en la consulta. El dashboard rastrea el uso de tokens por tipo de modelo (por ejemplo, GPT 5.5 vs. Claude 4.6 Sonnet) y aplica nuestras tarifas de contrato para producir un Costo Estimado por Traza que refleja lo que realmente pagamos. Esto facilita la detección de valores atípicos costosos, como una sola consulta compleja que cuesta $0.50 debido a un bucle de recuperación.
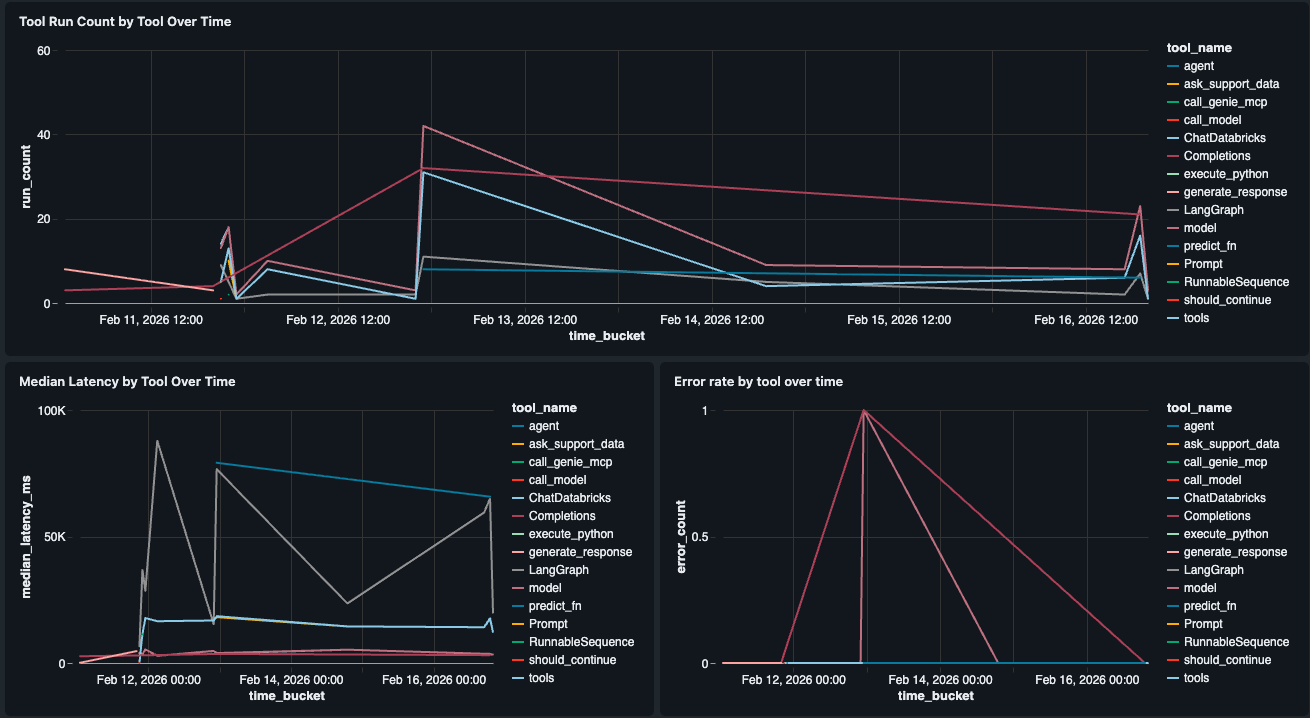
Rendimiento a nivel de componente
Las vistas de latencia nativas muestran P50/P99 a nivel de traza. Para profundizar y ver qué herramienta es lenta, creamos un widget de Rendimiento de Herramientas que desglosa la latencia (P50, P99) y las tasas de error por herramienta individual en el agente (por ejemplo, retrieve_docs vs. generate_response). Esto nos dice si el LLM, una llamada a la herramienta Genie u otro paso es el cuello de botella, para que podamos identificar exactamente dónde se está degradando la experiencia del usuario.
Espacios Genie
Tanto los stakeholders empresariales como los técnicos a menudo quieren explorar el comportamiento del agente sin escribir SQL. Al exponer las tablas de trazas a través de Genie, los equipos pueden habilitar el análisis en lenguaje natural sobre sus datos de telemetría, lo que permite a los usuarios hacer preguntas directamente sobre el rendimiento, el uso de herramientas, la latencia y el comportamiento del modelo. En nuestro ejemplo, esto podría incluir preguntas como:
- ¿Qué tipos de solicitudes requieren escalamiento?
- ¿Están aumentando las reintentos de herramientas?
- ¿Qué consultas desencadenan las rutas de ejecución más complejas?
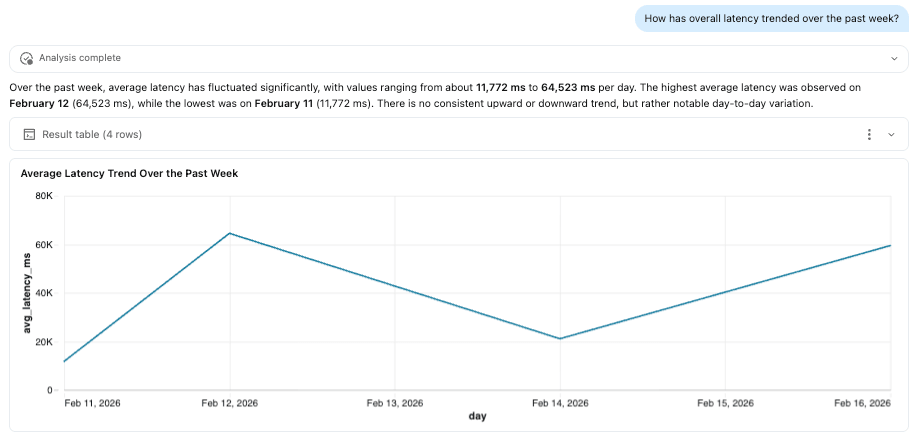
Pipelines ETL
Dado que las trazas se almacenan como tablas Delta, pueden alimentar pipelines ETL posteriores al igual que cualquier otro conjunto de datos. Al habilitar Change Data Feed (CDF), los equipos pueden procesar datos de trazas de forma incremental, ya sea en lotes o en streaming, sin tener que escanear tablas completas repetidamente.
Esto hace posible operacionalizar la observabilidad. Por ejemplo, un pipeline podría monitorear patrones de trazas y activar alertas cuando la latencia supere los umbrales definidos, los fallos de herramientas aumenten o el uso de tokens se desvíe de las líneas base esperadas. Estas señales pueden alimentar dashboards, sistemas de notificación o flujos de trabajo de remediación automatizada.
Es importante destacar que esto complementa las protecciones en tiempo real como AI Guardrails. Mientras que los guardrails aplican políticas en el momento de la solicitud, los pipelines ETL crean un bucle de retroalimentación, ayudando a los equipos a analizar tendencias, refinar políticas y mejorar continuamente el rendimiento del agente.
Cerrando el círculo: de las trazas de producción a la evaluación
Una vez que las trazas están disponibles, pueden potenciar la pila completa de evaluación de MLflow, lo que permite a los equipos medir, mejorar y mantener la calidad de sus aplicaciones GenAI durante todo el ciclo de vida. La evaluación y el monitoreo se basan directamente en el rastreo, lo que permite que la misma telemetría capturada durante el desarrollo, las pruebas y la producción se puntúe utilizando jueces LLM y métricas personalizadas.
Evaluar durante el desarrollo
MLflow nos permite ejecutar evaluaciones contra un conjunto de datos de evaluación, aplicando jueces integrados o personalizados para puntuar la calidad de la respuesta. Un enfoque eficaz es iniciar este conjunto de datos a partir de trazas reales. Dado que estos prompts se originan en interacciones reales de los usuarios, representan mejor los escenarios que tu agente debe manejar en comparación con casos de prueba puramente sintéticos.
A continuación, creamos un conjunto de datos de evaluación a partir de trazas capturadas recientemente. MLflow utiliza un almacén SQL para buscar y materializar registros del conjunto de datos, así que asegúrate de configurar el ID del almacén en tu entorno.
Con el conjunto de datos listo, podemos definir los jueces que calificarán nuestra aplicación. MLflow proporciona un conjunto de jueces integrados y también nos permite definir directrices personalizadas adaptadas al comportamiento esperado de nuestro agente.
Y ahora podemos ver los resultados en el experimento de MLflow.
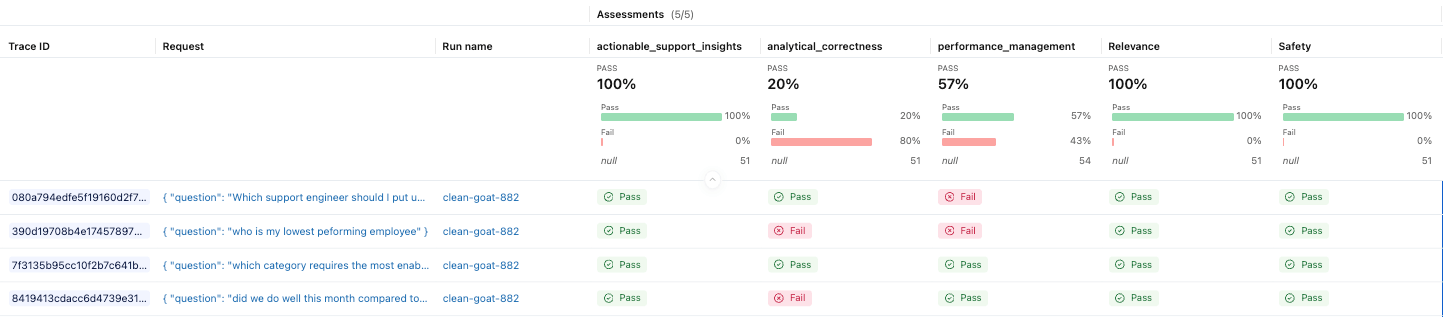
Supervisión en producción
Las evaluaciones de desarrollo nos ayudan a validar el comportamiento antes del lanzamiento, pero la supervisión en producción nos muestra cómo funciona la aplicación con usuarios reales. MLflow puede evaluar automáticamente rastreos en vivo utilizando los mismos jueces, lo que nos ayuda a detectar rápidamente regresiones, desviaciones y patrones de fallos emergentes. Esto convierte la evaluación de una tarea puntual en una práctica continua a medida que la aplicación evoluciona.
Clientes que ejecutan observabilidad de IA en Databricks
Experian
La transición al rastreo de MLflow para nuestro asistente virtual Eva y el sistema de correo electrónico automatizado Latte ha sido fluida. Con los rastreos en Unity Catalog, nuestro equipo de ciencia de datos ejecuta cientos de miles de rastreos a través de tablas Delta gobernadas y evalúa la calidad del agente a escala, todo sin salir de Databricks. A medida que incorporamos más flujos de trabajo de evaluación serios, tener rastreo y evaluaciones en una plataforma gobernada significa que no mantenemos herramientas separadas para cada etapa del ciclo de vida del agente.—James Lin, Director de Innovación de IA/ML, Experian
Superhuman (Grammarly)
Estamos estandarizando el rastreo de MLflow como la capa de observabilidad para todos nuestros agentes de IA en Superhuman. Preferimos la integración más amplia de la plataforma en lugar de construir y mantener una solución personalizada o puntual; esa carga de mantenimiento fue un verdadero punto de dolor para nuestros equipos. Con los rastreos de MLflow en Unity Catalog, podemos escalar a cientos de miles de rastreos por día, y nuestros investigadores pueden auto-servirse y explorar el comportamiento del agente directamente en la interfaz de usuario de MLflow sin soporte de ingeniería. Tener rastreo, evaluación y supervisión en una plataforma gobernada es exactamente lo que necesitábamos para llevar nuestros agentes a producción con confianza.—Martin Jewell, Lead MLE AI Infrastructure, Superhuman
SmartSheet
Elegimos Databricks como nuestra plataforma para GenAI, y MLflow es cómo nuestro equipo construye y evalúa agentes de IA. Durante una co-creación de tres días con Databricks, implementamos dos agentes de producción utilizando rastreo de MLflow, evaluaciones, jueces personalizados y etiquetado, y con los rastreos almacenados en Unity Catalog, podemos ejecutar decenas de miles de evaluaciones e iterar en la calidad con confianza a medida que escalamos.—Kapil Ashar, VP de Ingeniería, Smartsheet
The Standard
The Standard ayuda a nuestros clientes a lograr el bienestar financiero y la tranquilidad. Los datos y la IA son clave para ofrecer esa experiencia a escala. Al integrar la funcionalidad de los agentes de IA, como la extracción de información clave de los documentos de suscripción entrantes y los envíos de reclamaciones, en funciones empresariales importantes, podemos ofrecer un servicio excepcional a nuestros clientes y socios. Con el rastreo y la supervisión en producción, nuestros equipos pueden comprender rápidamente cómo se comportan los sistemas y realizar actualizaciones fiables. Al gobernar los rastreos en Unity Catalog junto con el resto de nuestros datos en la Plataforma de Inteligencia de Datos de Databricks, podemos consultar, supervisar e iterar de forma segura, sin añadir complejidad innecesaria.—Porter Orr, AVP de IA y Automatización, The Standard
Preguntas frecuentes (FAQ)
P: ¿Puedo usar esto para agentes que se ejecutan fuera de Databricks?
R: Sí, el agente puede ejecutarse en cualquier lugar. De hecho, el ejemplo del agente de soporte que se utilizó para este blog se implementa localmente.
P: ¿Cuáles son los límites de rendimiento y almacenamiento de esta solución?
R: El límite de rendimiento de ingesta comienza en 200 QPS. No hay límite de almacenamiento. Los límites anteriores de rastreos por experimento ya no son aplicables. Si necesita límites de rendimiento más altos, póngase en contacto con su equipo de cuentas de Databricks.
P: ¿Qué puedo hacer para garantizar que mis consultas de búsqueda, la experiencia del experimento de MLflow y los análisis posteriores sigan siendo eficientes?
R: Con la última actualización del producto, las tablas se agrupan automáticamente de forma líquida para mantener los datos organizados de forma óptima. Sin embargo, para volúmenes de rastreo más grandes, debería crear una vista materializada sobre las vistas derivadas y actualizarla incrementalmente para mantener el rendimiento de las consultas.
P: ¿Cómo maneja esto la PII encontrada en los prompts de los usuarios?
R: Esta función no aplica ningún manejo especial a la PII. Sin embargo, los datos se almacenan en Unity Catalog, donde puede aprovechar las capacidades de gobernanza, como controles de acceso detallados, enmascaramiento de columnas y filtrado de filas, para gestionar y restringir el acceso posterior.
Comenzar
Para empezar, siga la documentación.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.