Avance de Apache Iceberg en Databricks: Iceberg v3 GA, Compartición Abierta y Gobernanza Unificada
El catálogo más completo y abierto para Apache Iceberg
por Jason Reid, Ryan Blue, Daniel Weeks y Michelle Leon
*Unity Catalog es ahora el catálogo Apache Iceberg más completo, interoperable y listo para producción, con Managed Iceberg, Iceberg v3 y Foreign Iceberg pasando a GA.
*Cinco capacidades lo distinguen: APIs abiertas, federación de catálogos, control de acceso entre motores, uso compartido seguro sin copias y optimización impulsada por IA.
*Mirando hacia el futuro, Iceberg v4 y Delta 5.0 convergerán en una estructura de metadatos unificada, poniendo fin al compromiso entre la interoperabilidad y el rendimiento listo para producción.
La siguiente fase del lakehouse abierto estará definida por el catálogo. Los formatos de tabla abiertos permitieron que muchos motores funcionaran con los mismos datos, pero el catálogo determina si esos datos pueden ser gobernados, optimizados y compartidos de manera consistente entre sistemas. A medida que más cargas de trabajo, incluidas las aplicaciones de IA y las agentes, dependen del acceso gobernado a los datos en muchos sistemas, las empresas necesitan un catálogo Iceberg que pueda proporcionar interoperabilidad, un gran rendimiento y una gobernanza lista para la empresa.
Es por eso que hoy, anunciamos el conjunto más completo de capacidades de Iceberg disponibles en cualquier catálogo de lakehouse. En este blog, analizaremos las nuevas mejoras para el soporte de Iceberg en Unity Catalog y desglosaremos 5 cosas que hacen de Unity Catalog el catálogo Iceberg más interoperable del mercado actual.
Novedades: Capacidades de Iceberg de un vistazo
Hemos lanzado un amplio conjunto de capacidades de Iceberg en Databricks y Unity Catalog a Disponibilidad General y Vista Previa para garantizar que cada motor, cada catálogo y cada equipo puedan trabajar juntos sin problemas.
- Iceberg Administrado (GA): Cree, lea, escriba, optimice, gobierne y comparta tablas Iceberg directamente en Unity Catalog, con Optimización Predictiva y Clustering Líquido eliminando el trabajo manual requerido para mantener el rendimiento de las tablas.
- Iceberg v3 (GA): Soporte nativo para vectores de eliminación, seguimiento de filas y el nuevo tipo VARIANT en tablas administradas, externas y habilitadas para UniForm.
- Iceberg Externo (GA) & Venta de Credenciales para Iceberg Externo (GA): Registre, gobierne y consulte de forma segura tablas Iceberg administradas en catálogos externos.
- Compartir Externamente con clientes Iceberg (GA): Comparta datos en vivo con cualquier cliente compatible con REST de Iceberg utilizando el protocolo abierto DeltaSharing.
- Compartir Externamente tablas Iceberg Externas (Vista Previa Pública): Comparta tablas Iceberg administradas fuera de Databricks de forma nativa en Databricks y en todo el ecosistema de Delta Sharing.
- Vistas materializadas compatibles con Iceberg (Vista Previa Pública con Acceso Controlado): Cree vistas materializadas de alto rendimiento en Databricks y expóngalas a downstream como tablas Iceberg nativas.
- Control de Acceso Basado en Atributos (ABAC) entre motores (Beta): Aplique políticas de gobernanza de grano fino para motores Iceberg externos a través de las APIs de escaneo del Catálogo REST de Iceberg.
- Nuevos conectores de federación de catálogos (Vista Previa): Ampliando el soporte de federación de catálogos de Unity Catalog más allá de AWS Glue, Snowflake Horizon, Hive Metastore, y Salesforce Data Cloudpara incluir Google Cloud Lakehousey Palantir, haciendo de Unity Catalog su único panel de control.
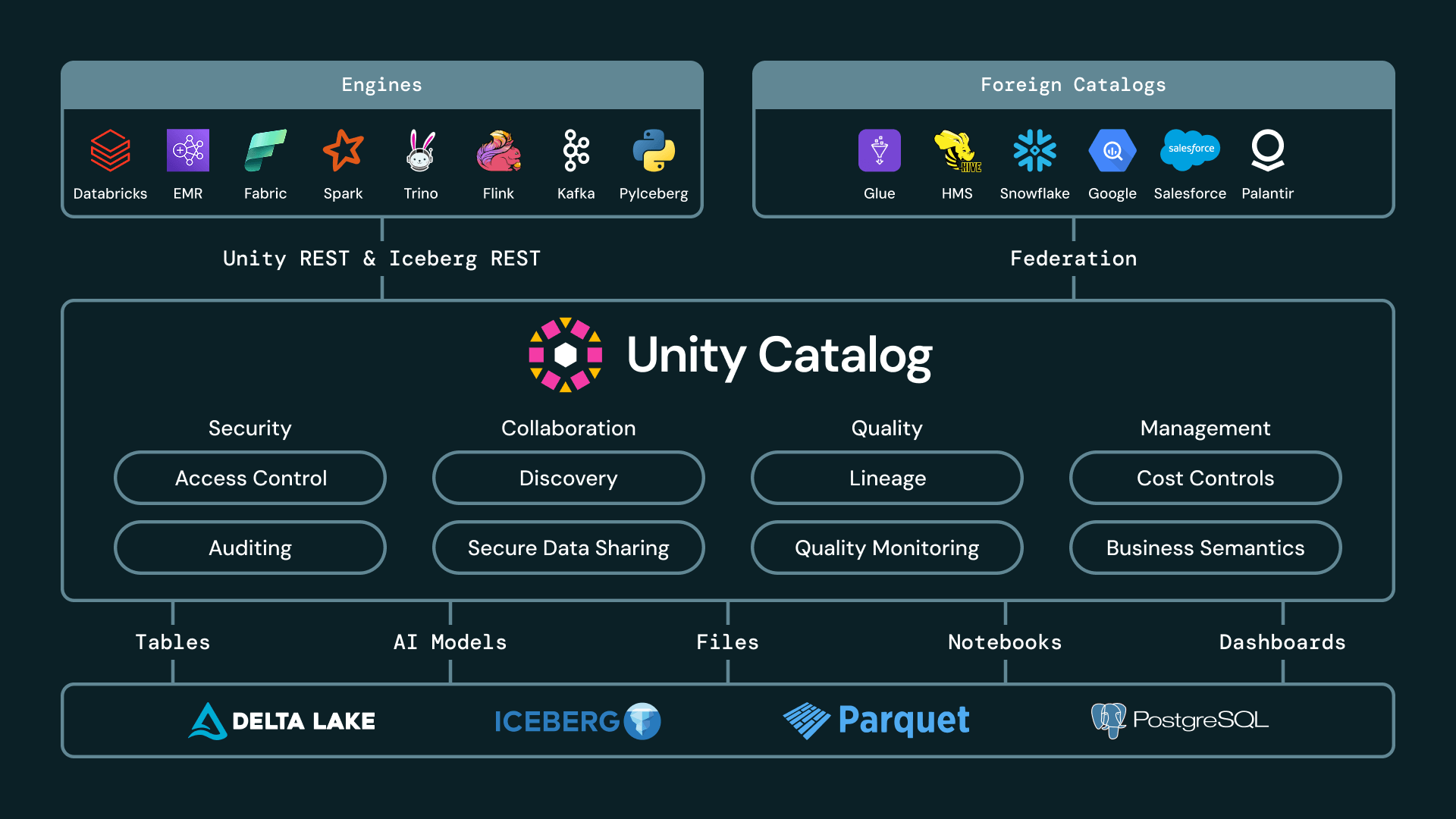
Cinco cosas que hacen de Unity Catalog el catálogo Iceberg más interoperable
Para ofrecer un lakehouse completamente abierto, un catálogo Iceberg debe ir más allá del seguimiento básico de metadatos. Debe brindarle flexibilidad absoluta en diversos motores, proveedores y modelos de gobernanza. Creemos que la evaluación de un catálogo Iceberg abierto se reduce a qué tan bien aborda cinco requisitos operativos fundamentales: proporcionar APIs abiertas, federar a través de entornos externos, aplicar gobernanza entre motores, habilitar el intercambio seguro y abierto, y la innovación continua en rendimiento y formato.
Unity Catalog es el único catálogo que cumple con los cinco requisitos.

1. APIs abiertas y venta de credenciales
Los clientes deben poder usar el motor que mejor se adapte a la carga de trabajo, ya sea Spark, Trino, Flink, Snowflake, DuckDB, pandas o cualquier otro cliente compatible con Iceberg, sin copiar datos ni otorgar permisos de almacenamiento amplios a cada motor.
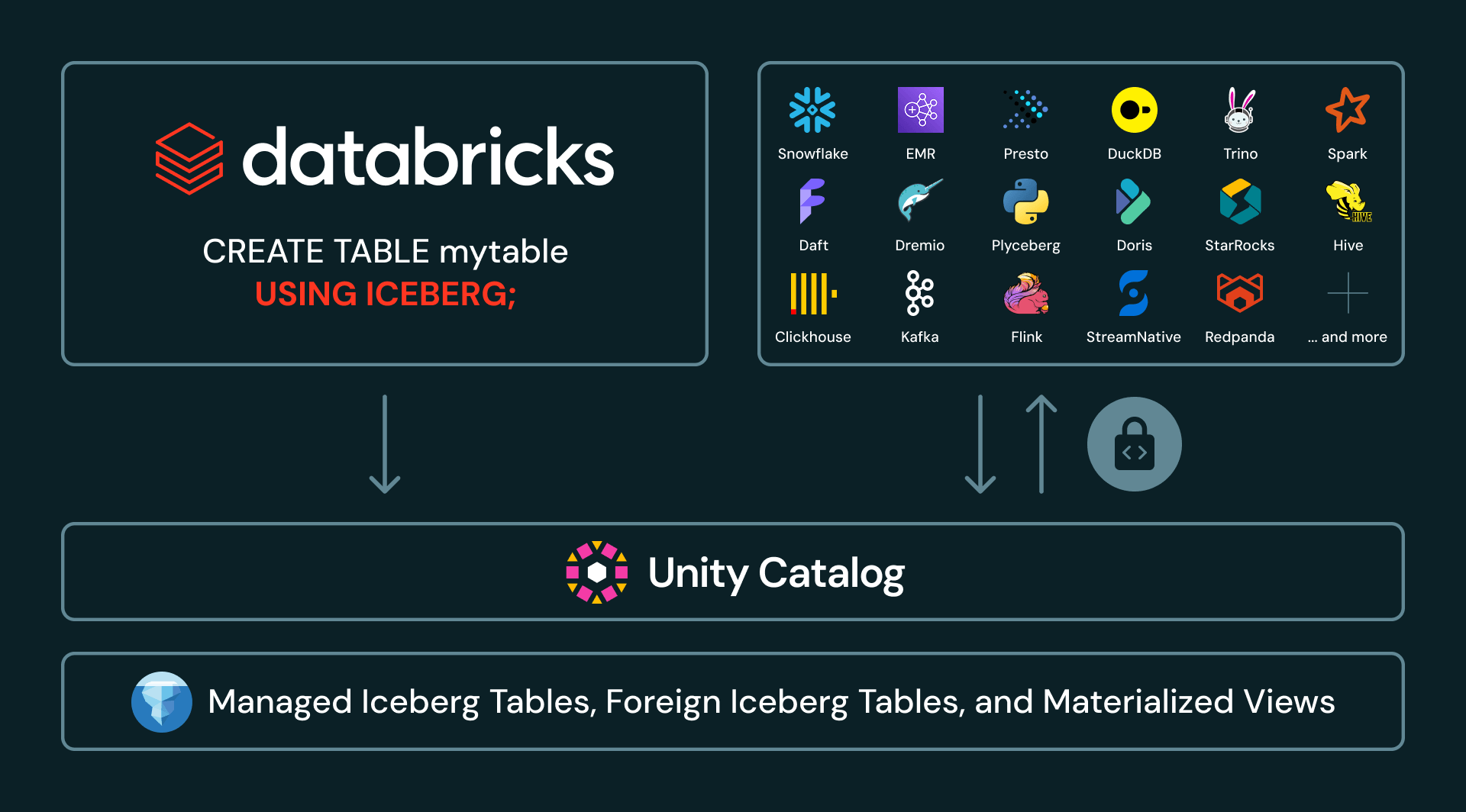
Con Iceberg Administrado ahora disponible de forma general en Databricks, los clientes pueden crear, leer y escribir tablas Iceberg en Unity Catalog desde cualquier motor utilizando las APIs del Catálogo REST de Iceberg de UC.
Las APIs del Catálogo REST de Iceberg de UC ahora también se extienden más allá de las tablas Iceberg administradas. UC también vende credenciales para tablas Iceberg federadas, proporcionando acceso seguro a través de APIs abiertas incluso a tablas administradas en catálogos externos. Y, actualmente en Vista Previa Pública con Acceso Controlado, los clientes pueden crear vistas materializadas en Databricks y exponerlas como tablas Iceberg a consumidores downstream. Con una disponibilidad más amplia en las próximas semanas, los clientes podrán crear vistas materializadas compatibles con Iceberg directamente con CREATE MATERIALIZED VIEW my_mv USING ICEBERG.
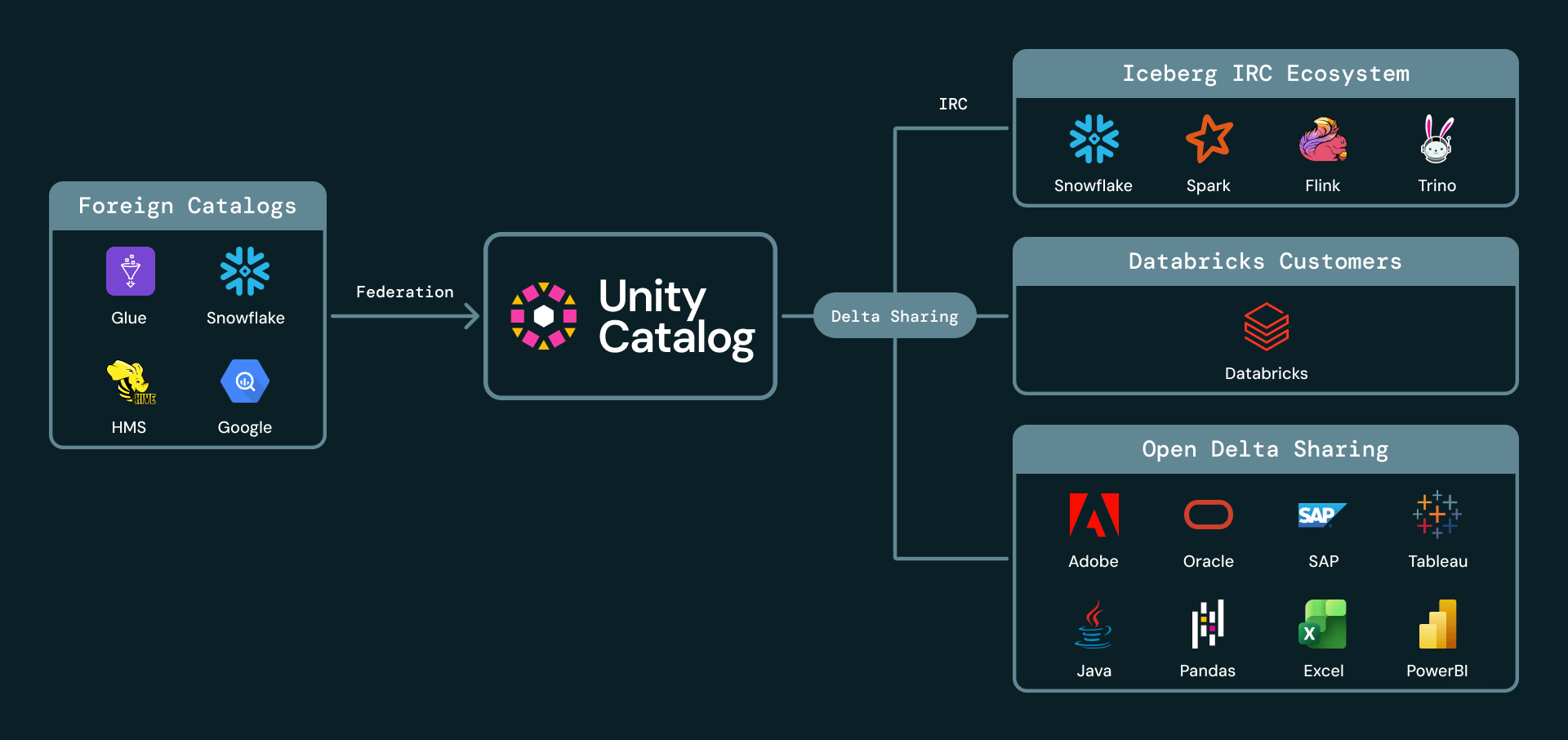
2. Federación de catálogos: todo su patrimonio Iceberg en una sola vista
Muchas grandes empresas tienen varios catálogos en su lakehouse. Por ejemplo, pueden tener datos distribuidos en Unity Catalog, AWS Glue, Snowflake Horizon y Hive Metastore. Con Iceberg Externo ahora disponible de forma general, Unity Catalog puede gobernar tablas Iceberg administradas en otros catálogos. Los clientes pueden descubrir, asegurar, consultar y compartir tablas Iceberg externas a través de Databricks mientras dejan los datos y el catálogo de origen en su lugar.
Unity Catalog ahora admite un conjunto amplio y creciente de integraciones de catálogos Iceberg, que incluyen AWS Glue, Google Cloud Lakehouse Runtime Catalog, Snowflake Horizon, Palantir, Salesforce y Workday. Estas integraciones permiten a las empresas tratar Unity Catalog como el único panel de control para su patrimonio Iceberg, incluso cuando los datos se producen o administran en otro lugar.
3. Control de Acceso Basado en Atributos (ABAC) entre motores
Históricamente, los controles a nivel de fila y columna se aplicaban dentro de un solo motor. En el lakehouse abierto, la misma tabla puede ser accedida por muchos motores. Esto introdujo un problema difícil: la gobernanza debe funcionar dondequiera que se pueda acceder a los datos.
Con los controles de acceso basados en atributos (ABAC) entre motores ahora en versión Beta, Unity Catalog extiende el control de acceso basado en atributos a los clientes de Iceberg que utilizan las API de escaneo del catálogo REST de Iceberg.
Cómo funciona: Los administradores definen políticas una vez en UC, incluidas máscaras de columnas, filtros de filas y políticas basadas en etiquetas. Cuando un motor externo de Iceberg solicita acceso, UC evalúa las políticas aplicables durante la planificación del escaneo en el servidor. Luego, UC devuelve un plan de escaneo filtrado para que el motor solo lea los datos autorizados al procesar la consulta.
Esto aporta una gobernanza granular a los motores externos de Iceberg que utilizan estándares abiertos. Cualquier motor, como Apache Spark o DuckDB, que implemente el cliente de planificación de escaneo del catálogo REST de Iceberg (añadido en la versión 1.11 de Iceberg) puede acceder a los datos con ABAC aplicado. Los clientes pueden utilizar el mejor motor para cada carga de trabajo mientras mantienen un modelo de gobernanza único en todo el lakehouse.
Unity Catalog y Iceberg administrado nos brindan lo mejor de ambos mundos: rendimiento nativo para nuestras canalizaciones de IA y ML, e interoperabilidad abierta para todos los consumidores posteriores. Una ruta de escritura, cero duplicación y una capa de gobernanza que todos los motores respetan, incluidos los productos impulsados por IA que estamos creando para la Nube de Datos de Rippling.—Tae Lee, Ingeniero Principal, Plataforma de Datos en Rippling
4. Compartición segura sin copias para colaboraciones externas y entre dominios
La compartición entre dominios a menudo obliga a los proveedores de datos a tomar malas decisiones: copiar datos a otra plataforma, crear complejos mecanismos de autenticación externa o exigir que cada destinatario utilice el mismo ecosistema de proveedores. Databricks fue pionero en la compartición segura de datos abiertos con Delta Sharing, el protocolo de código abierto más adoptado para la compartición de Datos e IA, compatible tanto con la compartición de Databricks a Databricks como de Databricks a abierto.
Nos complace anunciar que Iceberg es ahora un ciudadano de primera clase en Databricks Delta Sharing, tanto como formato de origen como de destino. Con la compartición con clientes de Iceberg ahora disponible de forma general, los clientes de Databricks pueden compartir datos en vivo externamente con cualquier destinatario que admita la API del Catálogo REST de Iceberg. Los destinatarios pueden consultar datos compartidos desde clientes compatibles con Iceberg como Snowflake, Trino, Flink y Spark, sin necesidad de ingesta manual ni copias. Los proveedores continúan gestionando el acceso, la auditoría y la gobernanza a través de Unity Catalog.
También anunciamos la Vista Previa Pública de la compartición de tablas Iceberg externas. Los clientes pueden compartir tablas Iceberg que se administran o catalogan fuera de Databricks, pero que están registradas y gobernadas en Unity Catalog. Esto significa que UC puede servir como capa de compartición para tablas Iceberg administradas y externas, manteniendo los datos en su lugar y la gobernanza centralizada.
5. Innovación en rendimiento y formato: tablas abiertas más rápidas sin ajuste manual
La interoperabilidad abierta solo funciona si las tablas mantienen un buen rendimiento a escala de producción. Unity Catalog es el único catálogo que utiliza IA para optimizar sus tablas y lograr consultas más rápidas y una menor sobrecarga operativa. Predictive Optimization determina qué tablas necesitan mantenimiento, qué optimizaciones ejecutar y con qué frecuencia, y adapta la disposición de los datos de su tabla en función de los patrones de carga de trabajo. Esto reduce el trabajo operativo necesario para mantener las tablas Iceberg rápidas y eficientes en costos a medida que cambian los usos, y estas optimizaciones benefician a todos los motores; por ejemplo, las técnicas de optimización de la disposición de datos mejoran la omisión de datos para consultas que se ejecutan fuera de Databricks, como en Apache Spark. Estamos innovando constantemente en la experiencia del cliente, y somos el único catálogo que puede seleccionar de forma inteligente las claves de clúster para un rendimiento óptimo o actualizar automáticamente las tablas abiertas con las últimas innovaciones basadas en patrones de acceso previos.
Databricks también está avanzando en el propio estándar Iceberg. Con Iceberg v3 ahora disponible de forma general en Databricks, los clientes obtienen soporte para vectores de eliminación, seguimiento de filas y VARIANT en tablas Iceberg administradas, tablas Iceberg externas y tablas administradas con UniForm habilitado. Estas capacidades cierran brechas importantes entre el rendimiento y la interoperabilidad: los vectores de eliminación aceleran las actualizaciones, fusiones y eliminaciones; el seguimiento de filas admite un procesamiento incremental más eficiente; y VARIANT proporciona una representación estándar para datos semiestructurados. Estas características también funcionan sin problemas tanto en tablas Delta como Iceberg, lo que permite la interoperabilidad sin reescribir datos.
Estas inversiones apuntan al mismo objetivo: tablas abiertas que no obligan a los clientes a elegir entre la interoperabilidad del ecosistema y las capacidades de rendimiento necesarias para las cargas de trabajo de producción.
Unity Catalog nos proporciona un único lugar para gobernar datos en todos los equipos y sistemas, mientras que Iceberg administrado ofrece el rendimiento que necesitamos a nuestra escala.—Kayvon Raphael, Jefe de Ingeniería de Datos, Magnite
En conjunto, estas cinco capacidades hacen de Unity Catalog el mejor catálogo para Apache Iceberg. UC brinda a los clientes acceso abierto a tablas Iceberg, una vista unificada entre catálogos, gobernanza granular entre motores, compartición segura entre dominios y optimización automática para cargas de trabajo de producción.
La próxima frontera: Iceberg v4
Con Iceberg v4, estamos repensando la estructura de metadatos central desde cero para mejorar el rendimiento, la escalabilidad y la interoperabilidad. Nuestro objetivo es elevar continuamente el listón de rendimiento e innovación de funciones, y hacerlo de manera que acerque Iceberg y Delta Lake. Por eso también proponemos que la próxima versión de Delta, Delta 5.0, adopte la estructura de árbol de metadatos adaptativa.
El resultado es simple: todas las tablas administradas se optimizan automáticamente en Unity Catalog, se gobiernan a través de API abiertas y están disponibles para cualquier motor. Mientras que otras plataformas le obligan a elegir entre interoperabilidad y rendimiento y capacidades avanzadas. Con Unity Catalog, obtiene ambas cosas.
Más información en Data + AI Summit
Únase a nosotros en Data + AI Summit para obtener más información sobre Apache Iceberg, Unity Catalog, compartición abierta, federación y la próxima fase de unificación de formatos de Delta e Iceberg.
- Coevolución de Formatos: Cómo Iceberg v4 y Delta 5.0 Comparten Metadatos Unificados Profundice en el árbol de metadatos adaptativo de Iceberg v4 y cómo Delta 5.0 adopta la misma estructura de metadatos de contenido, lo que permite un mejor rendimiento e interoperabilidad en un ecosistema unificado.
- Su Guía de Formatos de Tabla Abiertos: Delta, Iceberg, Mejores Prácticas y Próximos Pasos Conozca las novedades de Delta Lake y Apache Iceberg, incluidas las mejores prácticas para trabajar entre formatos hoy y un vistazo temprano a nuestra próxima hoja de ruta para servir mejor a las cargas de trabajo de IA/ML.
- El Viaje de Interoperabilidad de Magnite en un Petabyte de Datos Iceberg Escuche cómo Magnite centralizó el acceso con Unity Catalog mientras mejoraba el rendimiento en motores como Apache Spark, DuckDB y Snowflake.
- Cómo Acceder de Forma Segura a los Datos con Lakehouse Federation en AWS Glue, Snowflake, BigQuery y Fabric Vea cómo Unity Catalog puede actuar como el catálogo de catálogos para gobernar, asegurar y consultar datos en sistemas externos sin copiar datos.
- Interoperabilidad de Apache Iceberg: Soporte Abierto de Primera Clase en Databricks Delta Sharing
Vea el soporte de primera clase para Iceberg en Delta Sharing, incluido cómo Foot Locker utiliza la compartición abierta de Databricks para la interoperabilidad de Iceberg multiplataforma.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.