¿Qué son los Hash Buckets?
Una técnica de ingeniería de características que mapea variables categóricas de alta cardinalidad en vectores de tamaño fijo utilizando funciones hash para un uso eficiente de la memoria ML
- Aplica funciones hash (como MurmurHash3) para convertir características categóricas en contenedores de tamaño fijo, evitando la explosión de memoria de la codificación one-hot para variables de alta cardinalidad.
- Acepta colisiones hash donde varios valores se asignan al mismo contenedor, sacrificando precisión a cambio de una memoria significativa y eficiencia computacional en streaming y aprendizaje a gran escala.
- Se utiliza comúnmente en filtrado de spam, sistemas de recomendación y predicción de CTR, donde los espacios de características pueden tener millones de valores únicos que hacen inviable la codificación tradicional.
En informática, una tabla hash [hash map] es una estructura de datos que proporciona acceso prácticamente directo a objetos basados en una clave [una cadena única o un entero]. Una tabla hash utiliza una función hash para calcular un índice en una matriz de cubos (buckets) o ranuras, a partir de las cuales se puede encontrar el valor deseado. Estas son las características principales de la clave que se utiliza:
- La clave utilizada puede ser tu número de seguro social, número de teléfono, número de cuenta, etc.
- Debe tener claves únicas.
- Cada clave está asociada o asignada a un valor.
La guía de IA agéntica para la empresa

Los cubos hash se utilizan para asignar los elementos de datos con fines de clasificación o consulta. El objetivo de este trabajo es debilitar las listas vinculadas para que se pueda acceder a la búsqueda de un elemento específico en un plazo más corto. 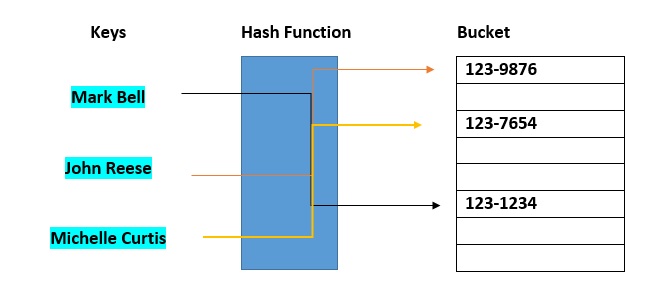 Una tabla hash que usa cubos es en realidad una combinación de una matriz y una lista enlazada. Cada elemento de la matriz [la tabla hash] es un encabezado para una lista enlazada. Todos los elementos que hagan hash en la misma ubicación se almacenarán en la lista. La función hash asigna cada registro al primer espacio dentro de uno de los cubos. En caso de que el espacio esté ocupado, entonces los espacios de los cubos se buscarán secuencialmente hasta que se encuentre un espacio abierto. En caso de que un cubo esté completamente lleno, el registro se almacenará en un cubo de desbordamiento de capacidad infinita al final de la tabla. Todos los cubos comparten el mismo cubo de desbordamiento. Sin embargo, una buena implementación utilizará una función hash que distribuya los registros de manera uniforme entre los cubos para que la menor cantidad posible de registros entren en el cubo de desbordamiento.
Una tabla hash que usa cubos es en realidad una combinación de una matriz y una lista enlazada. Cada elemento de la matriz [la tabla hash] es un encabezado para una lista enlazada. Todos los elementos que hagan hash en la misma ubicación se almacenarán en la lista. La función hash asigna cada registro al primer espacio dentro de uno de los cubos. En caso de que el espacio esté ocupado, entonces los espacios de los cubos se buscarán secuencialmente hasta que se encuentre un espacio abierto. En caso de que un cubo esté completamente lleno, el registro se almacenará en un cubo de desbordamiento de capacidad infinita al final de la tabla. Todos los cubos comparten el mismo cubo de desbordamiento. Sin embargo, una buena implementación utilizará una función hash que distribuya los registros de manera uniforme entre los cubos para que la menor cantidad posible de registros entren en el cubo de desbordamiento.
Recursos adicionales
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.