Apache Spark e Hadoop: Trabalhando Juntos
por Ion Stoica
Frequentemente nos perguntam como o Apache Spark se encaixa no ecosistema Hadoop e como é possível executar o Spark em um cluster Hadoop existente. Este blog tem como objetivo responder a essas perguntas.
Primeiramente, o Spark pretende aprimorar, e não substituir, a pilha Hadoop. Desde o primeiro dia, o Spark foi projetado para ler e gravar dados de e para o HDFS, bem como outros sistemas de armazenamento, como o HBase e o S3 da Amazon. Dessa forma, os usuários do Hadoop podem enriquecer suas capacidades de processamento combinando o Spark com o Hadoop MapReduce, o HBase e outros frameworks de big data.
Em segundo lugar, nosso foco constante tem sido tornar o mais fácil possível para que todos os usuários do Hadoop aproveitem os recursos do Spark. Independentemente de você executar o Hadoop 1.x ou o Hadoop 2.0 (YARN), e de ter ou não privilégios administrativos para configurar o cluster Hadoop, existe uma maneira de executar o Spark! Em particular, há três maneiras de implantar o Spark em um cluster Hadoop: standalone, YARN e SIMR.
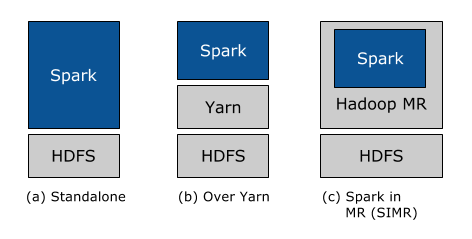
Implantação standalone: com a implantação standalone, é possível alocar recursos estaticamente em todas ou em um subconjunto de máquinas em um cluster Hadoop e executar o Spark lado a lado com o Hadoop MR. O usuário pode então executar jobs arbitrários do Spark em seus dados HDFS. Sua simplicidade a torna a implantação preferida de muitos usuários do Hadoop 1.x.
Hadoop Yarn: implantação: usuários do Hadoop que já implantaram ou planejam implantar o Hadoop Yarn podem simplesmente executar o Spark no YARN sem a necessidade de pré-instalação ou acesso administrativo. Isso permite que os usuários integrem facilmente o Spark em seu stack do Hadoop e aproveitem todo o poder do Spark, bem como de outros componentes executados no Spark.
Spark In MapReduce (SIMR): Para os usuários do Hadoop que ainda não estão executando o YARN, outra opção, além da implantação standalone, é usar o SIMR para iniciar Jobs do Spark dentro do MapReduce. Com o SIMR, os usuários podem começar a experimentar o Spark e usar seu shell poucos minutos após o download! Isso reduz tremendamente a barreira de implantação e permite que praticamente todos explorem o Spark.
Interoperabilidade com outros sistemas
O Spark interopera não apenas com o Hadoop, mas também com outras populares tecnologías de big data.
- Apache Hive: por meio do Shark, o Spark permite que os usuários do Apache Hive executem suas consultas não modificadas com muito mais rapidez. O Hive é uma solução popular de data warehouse executada sobre o Hadoop, enquanto o Shark é um sistema que permite que o framework do Hive seja executado sobre o Spark em vez do Hadoop. Como resultado, o Shark pode acelerar as consultas do Hive em até 100x quando os dados de entrada cabem na memória e em até 10x quando os dados de entrada são armazenados em disco.
- AWS EC2: os usuários podem executar facilmente o Spark (e o Shark) no EC2 da Amazon usando os scripts que vêm com o Spark ou as versões hospedadas do Spark e do Shark no Elastic MapReduce da Amazon.
- Apache Mesos: O Spark é executado no Mesos, um sistema gerenciador de cluster que fornece isolamento eficiente de recursos em aplicações distribuídas, incluindo MPI e Hadoop. O Mesos permite o compartilhamento de granularidade fina, o que permite que um Job do Spark aproveite dinamicamente os recursos ociosos no cluster durante sua execução. Isso leva a melhorias consideráveis de desempenho, especialmente para Jobs do Spark de longa duração.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.