Processamento de Dados Geoespaciais em Escala com Databricks
por Nima Razavi e Michael Johns
Este blog está desatualizado. Consulte este blog sobre Spatial SQL para obter abordagens atualizadas sobre como armazenar e processar dados geoespaciais na sua Databricks Lakehouse.
A evolução e a convergência da tecnologia impulsionaram um mercado vibrante para dados geoespaciais precisos e em tempo hábil. Todos os dias, bilhões de dispositivos portáteis e de IoT, juntamente com milhares de plataformas de sensoriamento remoto aéreas e de satélite, geram centenas de exabytes de dados com reconhecimento de localização. Esse boom de big data geoespacial, combinado com os avanços em machine learning, está permitindo que organizações de todos os setores criem novos produtos e capacidades.
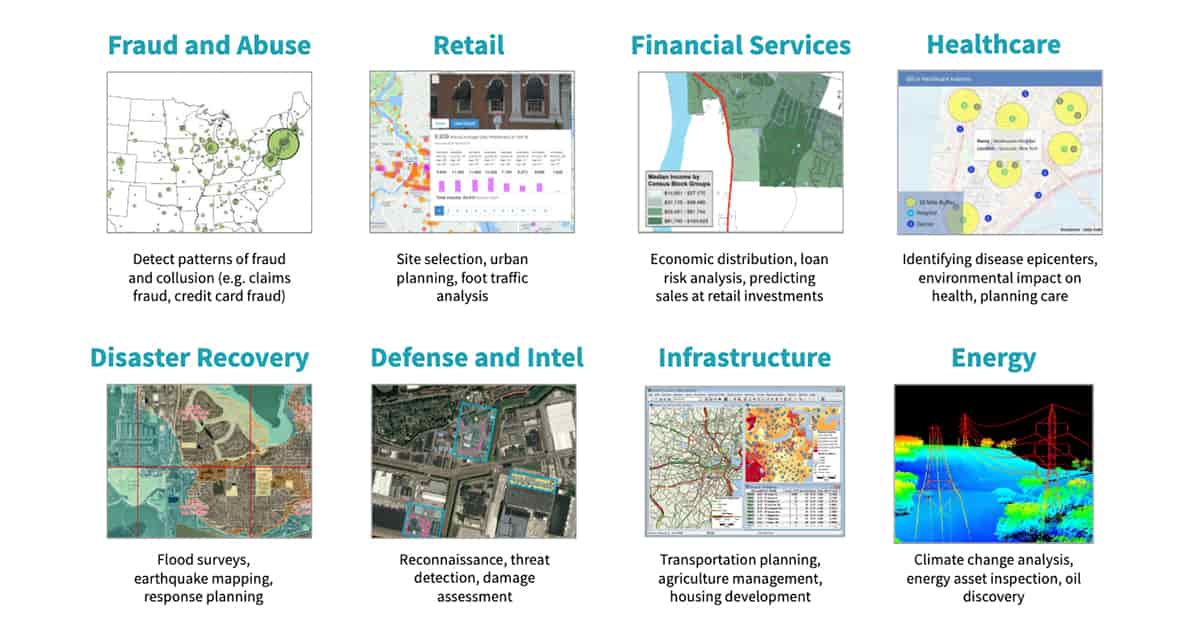
Por exemplo, inúmeras empresas oferecem serviços localizados baseados em drones, como mapeamento e inspeção de locais (consulte Desenvolvimento para a Nuvem Inteligente e a Borda Inteligente). Outra indústria em rápido crescimento para dados geoespaciais são os veículos autônomos. Startups e empresas estabelecidas estão acumulando grandes acervos de geodados altamente contextualizados de sensores de veículos para entregar a próxima inovação em carros autônomos (consulte Databricks impulsiona a ambição da wejo de criar um ecossistema de dados de mobilidade). Varejistas e agências governamentais também buscam aproveitar seus dados geoespaciais. Por exemplo, a análise de fluxo de pessoas (consulte Construindo um Conjunto de Dados de Insights de Fluxo de Pessoas) pode ajudar a determinar o melhor local para abrir uma nova loja ou, no Setor Público, melhorar o planejamento urbano. Apesar de todos esses investimentos em dados geoespaciais, existem vários desafios.
Desafios na Análise Geoespacial em Escala
O primeiro desafio envolve lidar com a escala em aplicações de streaming e batch. A pura proliferação de dados geoespaciais e os SLAs exigidos pelas aplicações sobrecarregam os sistemas tradicionais de armazenamento e processamento. Os dados dos clientes têm transbordado de bancos de dados geoespaciais existentes, escalados verticalmente, para data lakes há muitos anos devido a pressões como volume de dados, velocidade, custo de armazenamento e aplicação rigorosa de schema-on-write. Embora as empresas tenham investido em dados geoespaciais, poucas possuem a arquitetura de tecnologia adequada para preparar esses conjuntos de dados grandes e complexos para análises downstream. Além disso, dado que dados em escala são frequentemente necessários para casos de uso avançados, a maioria das iniciativas impulsionadas por IA está falhando em ir do piloto à produção.
A compatibilidade com vários formatos espaciais representa o segundo desafio. Existem muitos formatos geoespaciais especializados estabelecidos ao longo de muitas décadas, bem como fontes de dados incidentais nas quais informações de localização podem ser coletadas:
- Formatos vetoriais como GeoJSON, KML, Shapefile e WKT
- Formatos raster como ESRI Grid, GeoTIFF, JPEG 2000 e NITF
- Padrões de navegação como os usados por dispositivos AIS e GPS
- Geobancos de dados acessíveis via conexões JDBC / ODBC, como PostgreSQL / PostGIS
- Formatos de sensores remotos de plataformas Hyperspectral, Multispectral, Lidar e Radar
- Padrões web OGC como WCS, WFS, WMS e WMTS
- Logs, fotos, vídeos e mídias sociais com geotag
- Dados não estruturados com referências de localização
Neste post, apresentamos uma visão geral das abordagens gerais para lidar com os dois principais desafios listados acima usando a Plataforma Unificada de Análise de Dados Databricks. Esta é a primeira parte de uma série de posts sobre o trabalho com grandes volumes de dados geoespaciais.
Escalando Cargas de Trabalho Geoespaciais com Databricks
A Databricks oferece uma plataforma unificada de análise de dados para análise de big data e machine learning, utilizada por milhares de clientes em todo o mundo. Ela é alimentada por Apache Spark™, Delta Lake e MLflow, com um amplo ecossistema de integrações de bibliotecas de terceiros e disponíveis. Databricks UDAP oferece segurança, suporte, confiabilidade e desempenho de nível empresarial em escala para cargas de trabalho de produção. Cargas de trabalho geoespaciais são tipicamente complexas e não existe uma única biblioteca que se encaixe em todos os casos de uso. Embora o Apache Spark não ofereça Tipos de Dados geoespaciais nativamente, a comunidade de código aberto, bem como empresas, direcionaram muito esforço para desenvolver bibliotecas espaciais, resultando em um mar de opções para escolher.
Existem geralmente três padrões para escalar operações geoespaciais, como junções espaciais ou vizinhos mais próximos:
- Usando bibliotecas especializadas que estendem o Apache Spark para análise geoespacial. GeoSpark, GeoMesa, GeoTrellis e Rasterframes são algumas dessas bibliotecas usadas por nossos clientes. Essas frameworks frequentemente oferecem múltiplas vinculações de linguagem, têm escalabilidade e desempenho muito melhores do que abordagens não formalizadas, mas também podem apresentar uma curva de aprendizado.
- Empacotando bibliotecas de nó único, como GeoPandas, Geospatial Data Abstraction Library (GDAL) ou Java Topology Service (JTS), em funções definidas pelo usuário (UDFs) ad hoc para processamento de forma distribuída com Spark DataFrames. Esta é a abordagem mais simples para escalar cargas de trabalho existentes sem muita reescrita de código; no entanto, pode introduzir desvantagens de desempenho, pois é mais uma abordagem de "lift-and-shift".
- Indexando os dados com sistemas de grade e aproveitando o índice gerado para realizar operações espaciais é uma abordagem comum para lidar com cargas de trabalho de escala muito grande ou computacionalmente restritas. S2, GeoHex e H3 da Uber são exemplos de tais sistemas de grade. Grids aproximam features geoespaciais, como polígonos ou pontos, com um conjunto fixo de células identificáveis, evitando assim operações geoespaciais caras e oferecendo um comportamento de escalabilidade muito melhor. Os implementadores podem escolher entre grids fixos em uma única precisão, que podem ser um tanto imprecisos, mas mais performáticos, ou grids com múltiplas precisões, que podem ser menos performáticos, mas mitigam a imprecisão.
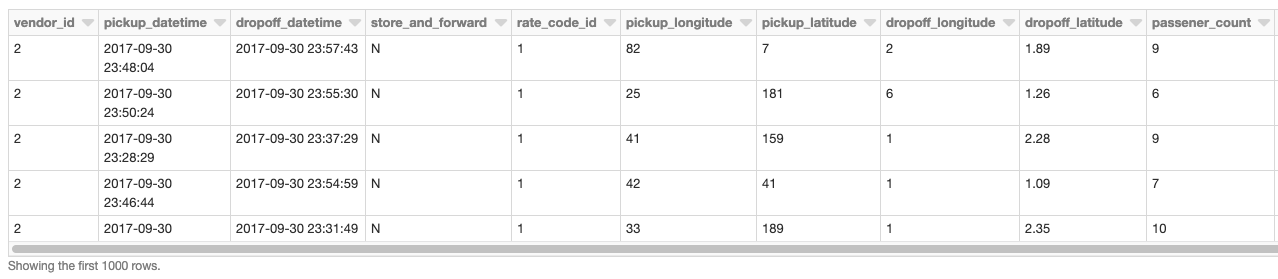
Os exemplos a seguir são geralmente orientados em torno de um conjunto de dados de embarque/desembarque de táxi de Nova York encontrado aqui. Dados de Zona de Táxi de Nova York com geometrias também serão usados como o conjunto de polígonos. Esses dados contêm polígonos para os cinco distritos de Nova York, bem como os bairros. Este notebook irá guiá-lo pelas preparações e limpezas feitas para converter os arquivos CSV iniciais em Tabelas Delta Lake como uma fonte de dados confiável e performática.
Nosso DataFrame base é o conjunto de dados de embarque/desembarque de táxi lido de uma Tabela Delta Lake usando Databricks.
Operações Geoespaciais usando Bibliotecas Geoespaciais para Apache Spark
Nos últimos anos, várias bibliotecas foram desenvolvidas para estender as capacidades do Apache Spark para análise geoespacial. Esses frameworks se encarregam de registrar tipos definidos pelo usuário (UDTs) e funções (UDFs) comumente aplicados de maneira consistente, aliviando o fardo que, de outra forma, recairia sobre usuários e equipes para escrever lógica espacial ad-hoc. Observe que, neste post, usamos várias estruturas espaciais diferentes escolhidas para destacar várias capacidades. Entendemos que existem outros frameworks além dos destacados que você também pode querer usar com Databricks para processar suas cargas de trabalho espaciais.
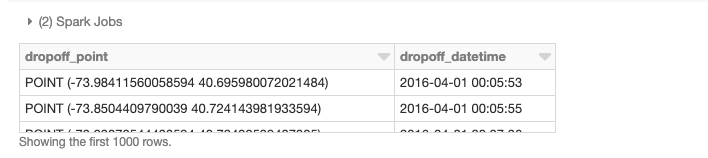
Anteriormente, carregamos nossos dados base em um DataFrame. Agora, precisamos transformar os atributos de latitude/longitude em geometrias de ponto. Para conseguir isso, usaremos UDFs para executar operações em DataFrames de forma distribuída. Consulte os notebooks fornecidos no final do post para obter detalhes sobre como adicionar esses frameworks a um cluster e as chamadas de inicialização para registrar UDFs e UDTs. Para começar, adicionamos o GeoMesa ao nosso cluster, um framework especialmente adepto ao manuseio de dados vetoriais. Para ingestão, estamos aproveitando principalmente sua integração do JTS com o Spark SQL, que nos permite converter e usar facilmente classes de geometria JTS registradas. Usaremos a função st_makePoint que, dada uma latitude e longitude, cria um objeto de geometria Point. Como a função é uma UDF, podemos aplicá-la diretamente às colunas.
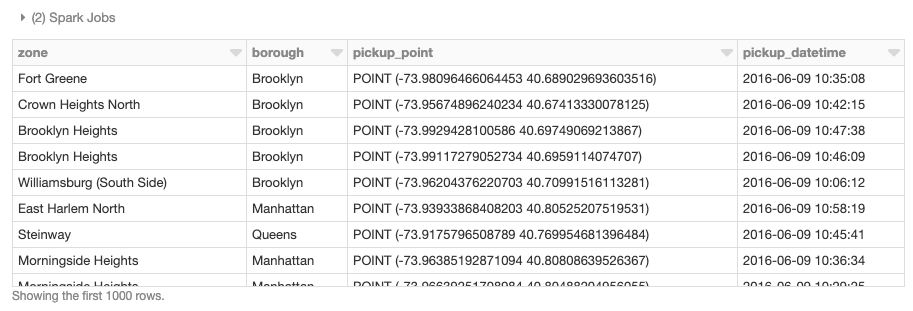
Também podemos realizar junções espaciais distribuídas, neste caso usando a UDF st_contains fornecida pelo GeoMesa para produzir a junção resultante de todos os polígonos contra os pontos de coleta.
Envolvendo Bibliotecas de Nó Único em UDFs
Além de usar frameworks espaciais distribuídos desenvolvidos para fins específicos, bibliotecas existentes de nó único também podem ser envolvidas em UDFs ad-hoc para realizar operações geoespaciais em DataFrames de forma distribuída. Esse padrão está disponível para todos os bindings de linguagem Spark – Scala, Java, Python, R e SQL – e é uma abordagem simples para alavancar cargas de trabalho existentes com alterações mínimas de código. Para demonstrar um exemplo de nó único, vamos carregar dados de distritos de Nova York e definir a UDF find_borough(...) para a operação ponto-em-polígono para atribuir cada local GPS a um distrito usando geopandas. Isso também poderia ter sido realizado com uma UDF vetorizada para um desempenho ainda melhor.
Agora podemos aplicar a UDF para adicionar uma coluna ao nosso Spark DataFrame que atribui um nome de distrito a cada ponto de coleta.
Sistemas de Grade para Indexação Espacial
Operações geoespaciais são inerentemente computacionalmente caras. Ponto-em-polígono, junções espaciais, vizinho mais próximo ou ajuste a rotas envolvem operações complexas. Ao indexar com sistemas de grade, o objetivo é evitar completamente as operações geoespaciais. Essa abordagem leva às implementações mais escaláveis, com a ressalva de operações aproximadas. Aqui está um breve exemplo com H3.
Escalar operações espaciais com H3 é essencialmente um processo de duas etapas. A primeira etapa é calcular um índice H3 para cada feature (pontos, polígonos, …) definida como a UDF geoToH3(...). A segunda etapa é usar esses índices para operações espaciais, como junção espacial (ponto em polígono, k-vizinhos mais próximos, etc.), neste caso definida como a UDF multiPolygonToH3(...).
Agora podemos aplicar essas duas UDFs aos dados de táxi de Nova York, bem como ao conjunto de polígonos de distritos para gerar o índice H3.
Dado um conjunto de pontos lat/lon e um conjunto de geometrias de polígonos, agora é possível realizar a junção espacial usando o campo h3index como condição de junção. Essas atribuições podem ser usadas para agregar o número de pontos que caem dentro de cada polígono, por exemplo. Geralmente, há milhões ou bilhões de pontos que precisam ser correspondidos a milhares ou milhões de polígonos, o que exige uma abordagem escalável. Existem outras técnicas não abordadas neste post que podem ser usadas para indexação em suporte a operações espaciais quando uma aproximação é insuficiente.

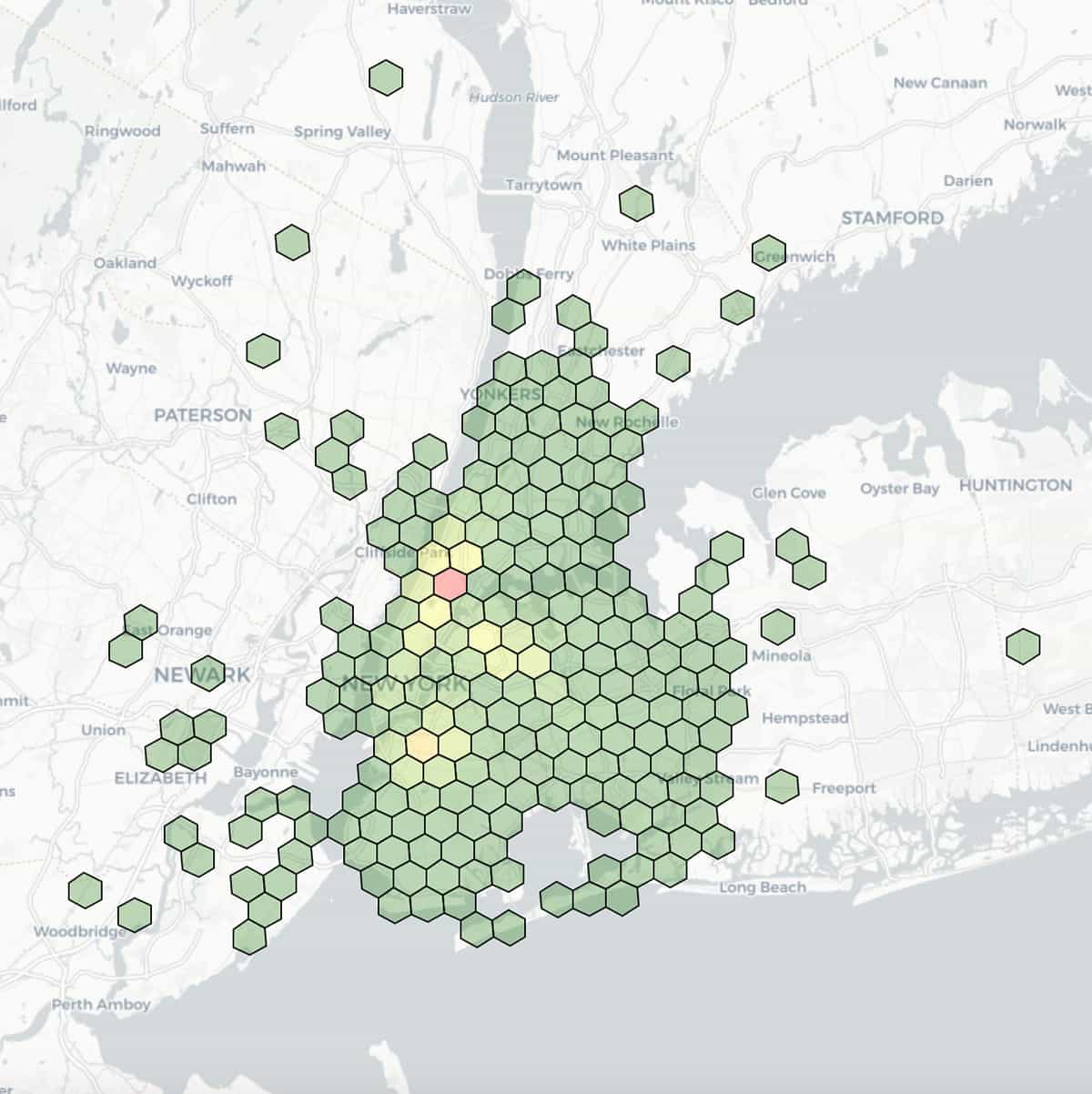
Aqui está uma visualização dos locais de desembarque de táxi, com latitude e longitude agrupadas em uma resolução de 7 (comprimento de aresta de 1,22 km) e coloridas por contagens agregadas dentro de cada agrupamento.
Tratando Formatos Espaciais com Databricks
Dados geoespaciais envolvem pontos de referência, como latitude e longitude, para locais físicos ou extensões na Terra, juntamente com recursos descritos por atributos. Embora existam muitos formatos de arquivo para escolher, selecionamos um punhado de formatos vetoriais e raster representativos para demonstrar a leitura com Databricks.
Dados Vetoriais
Dados vetoriais são uma representação do mundo armazenada em coordenadas x (longitude), y (latitude) em graus, também z (altitude em metros) se a elevação for considerada. Os três tipos básicos de símbolos para dados vetoriais são pontos, linhas e polígonos. Well-known-text (WKT), GeoJSON e Shapefile são alguns formatos populares para armazenar dados vetoriais que destacamos abaixo.
Vamos ler os dados de Zonas de Táxi de Nova York com geometrias armazenadas como WKT. A estrutura de dados que queremos obter de volta é um DataFrame, que nos permitirá padronizar com outras APIs e fontes de dados disponíveis, como as usadas em outras partes do blog. Somos capazes de converter facilmente o conteúdo de texto WKT encontrado no campo the_geom em sua classe JTS Geometry correspondente através da chamada UDF st_geomFromWKT(...).
GeoJSON é usado por muitos pacotes GIS de código aberto para codificar uma variedade de estruturas de dados geográficos, incluindo seus recursos, propriedades e extensões espaciais. Para este exemplo, leremos os Limites dos Bairros de Nova York com a abordagem dependendo do fluxo de trabalho. Como os dados estão em conformidade com JSON, poderíamos usar o leitor JSON integrado do Databricks com .option("multiline","true") para carregar os dados com o esquema aninhado.

A partir daí, poderíamos optar por elevar qualquer um dos campos para colunas de nível superior usando a função explode integrada do Spark. Por exemplo, poderíamos querer trazer geometria, propriedades e tipo e, em seguida, converter a geometria para sua classe JTS correspondente, como foi mostrado com o exemplo WKT.

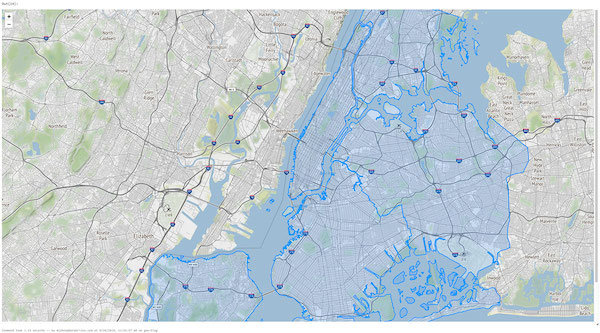
Também podemos visualizar os dados de Zonas de Táxi de Nova York em um notebook usando um DataFrame existente ou renderizando diretamente os dados com uma biblioteca como Folium, uma biblioteca Python para renderizar dados espaciais. O Databricks File System (DBFS) é executado sobre uma camada de armazenamento distribuído que permite que o código funcione com formatos de dados usando padrões familiares de sistema de arquivos. O DBFS tem um FUSE Mount para permitir chamadas de API locais que realizam operações de leitura e escrita de arquivos, o que torna muito fácil carregar dados com APIs não distribuídas para renderização interativa. No comando Python open(...) abaixo, o prefixo "/dbfs/..." habilita o uso do FUSE Mount.
Shapefile é um formato vetorial popular desenvolvido pela ESRI que armazena a localização geométrica e as informações de atributos de feições geográficas. O formato consiste em uma coleção de arquivos com um prefixo de nome de arquivo comum (*.shp, *.shx e *.dbf são obrigatórios) armazenados no mesmo diretório. Uma alternativa ao shapefile é o KML, também usado por nossos clientes, mas não mostrado por brevidade. Para este exemplo, vamos usar os shapefiles de Edifícios de Nova York. Embora existam muitas maneiras de demonstrar a leitura de shapefiles, daremos um exemplo usando GeoSpark. O ShapefileReader integrado é usado para gerar o DataFrame rawSpatialDf.
Ao registrar rawSpatialDf como uma view temporária, podemos facilmente entrar na sintaxe pura do Spark SQL para trabalhar com o DataFrame, incluindo a aplicação de uma UDF para converter o WKT do shapefile em Geometry.
Além disso, podemos usar a visualização integrada do Databricks para análises inline, como a criação de gráficos dos edifícios mais altos de Nova York.

Dados Raster
Dados raster armazenam informações de características em uma matriz de células (ou pixels) organizadas em linhas e colunas (discretas ou contínuas). Imagens de satélite, fotogrametria e mapas digitalizados são todos tipos de dados de Observação da Terra (EO) baseados em raster.
O seguinte exemplo em Python usa RasterFrames, um framework de análise espacial centrado em DataFrame, para ler duas bandas de imagens GeoTIFF Landsat-8 (vermelho e infravermelho próximo) e combiná-las no Índice de Vegetação por Diferença Normalizada. Podemos usar esses dados para avaliar a saúde das plantas ao redor de Nova York. O módulo rf_ipython é usado para manipular o conteúdo do RasterFrame em uma variedade de formas visualmente úteis, como abaixo, onde as colunas de tiles vermelho, NIR e NDVI são renderizadas com rampas de cores, usando o comando displayHTML(...) integrado do Databricks para mostrar os resultados dentro do notebook.
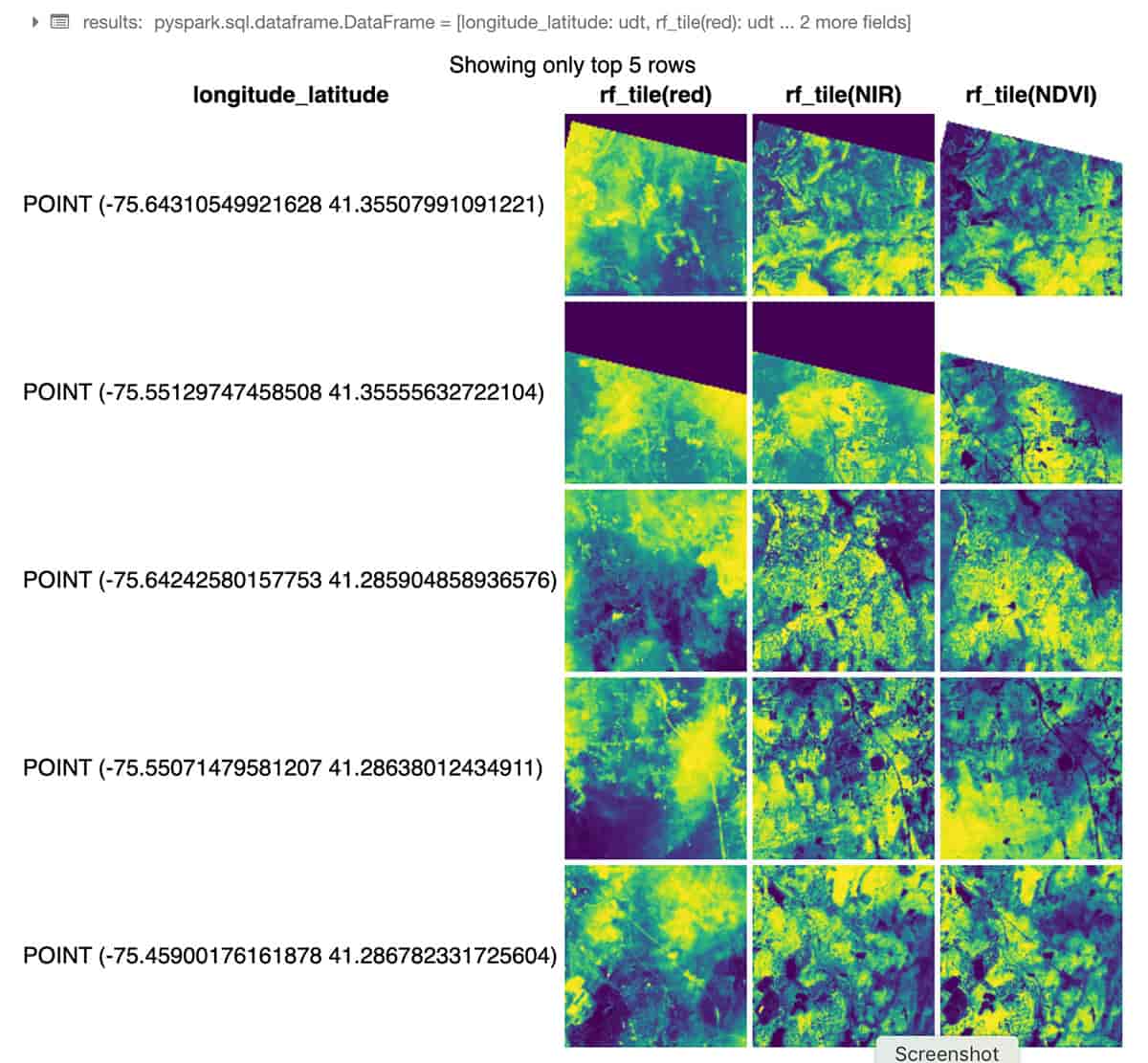
Através de seu Spark DataSource personalizado, RasterFrames pode ler vários formatos raster, incluindo GeoTIFF, JP2000, MRF e HDF, de um array de serviços. Ele também suporta a leitura dos formatos vetoriais GeoJSON e WKT/WKB. O conteúdo do RasterFrame pode ser filtrado, transformado, resumido, reamostrado e rasterizado através de mais de 200 funções raster e vetoriais, como st_reproject(...) e st_centroid(...) usadas no exemplo acima. Ele fornece APIs para Python, SQL e Scala, bem como interoperabilidade com Spark ML.
GeoDatabases
Geo bancos de dados podem ser baseados em arquivos para dados de menor escala ou acessíveis via conexões JDBC / ODBC para dados de escala média. Você pode usar o Databricks para consultar muitos bancos de dados SQL com o JDBC / ODBC Data Source integrado. A conexão com o PostgreSQL é mostrada abaixo, que é comumente usado para cargas de trabalho de menor escala aplicando extensões PostGIS. Esse padrão de conectividade permite que os clientes mantenham o acesso como está aos bancos de dados existentes.
Começando com Análise Geoespacial no Databricks
Empresas e agências governamentais buscam usar dados referenciados espacialmente em conjunto com fontes de dados corporativas para obter insights acionáveis e entregar uma ampla gama de casos de uso inovadores. Neste blog, demonstramos como a Plataforma Unificada de Análise de Dados Databricks pode escalar facilmente cargas de trabalho geoespaciais, permitindo que nossos clientes aproveitem o poder da nuvem para capturar, armazenar e analisar dados de tamanho massivo.
Em um próximo blog, vamos nos aprofundar em tópicos mais avançados para processamento geoespacial em escala com Databricks. Você encontrará detalhes adicionais sobre os formatos espaciais e frameworks destacados revisando o Data Prep Notebook, GeoMesa + H3 Notebook, GeoSpark Notebook, GeoPandas Notebook e Rasterframes Notebook. Além disso, fique atento a uma nova seção em nossa documentação especificamente para tópicos geoespaciais de interesse.
Próximos Passos
- Participe do nosso próximo webinar Análise Geoespacial e IA no Setor Público para ver uma demonstração ao vivo cobrindo vários casos de uso populares
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.