Orientação prescritiva para implementar um modelo de cofre de dados na Plataforma Databricks Lakehouse
por Soham Bhatt, Tanveer Shaikh e Glenn Wiebe
Existem muitos modelos de dados diferentes que você pode usar ao projetar um sistema analítico, como modelos de domínio específicos das indústrias, metodologias Kimball, Inmon e Data Vault. Dependendo de seus requisitos exclusivos, você pode usar essas diferentes técnicas de modelagem ao projetar um lakehouse. Todos eles têm seus pontos fortes, e cada um pode se adequar bem a diferentes casos de uso.
Em última análise, um modelo de dados nada mais é do que um construto que define diferentes tabelas com relacionamentos um-para-um, um-para-muitos e muitos-para-muitos definidos. As plataformas de dados devem fornecer as melhores práticas para a fisicalização do modelo de dados, a fim de facilitar a recuperação de informações e obter um melhor desempenho.
Em um artigo anterior, abordamos Cinco passos simples para implementar um esquema em estrela no Databricks com o Delta Lake. Neste artigo, nosso objetivo é explicar o que é um Data Vault, como implementá-lo na camada Bronze/Silver/ouro e como obter o melhor desempenho do Data Vault com a Databricks Lakehouse Platform.
Modelagem Data Vault, definida
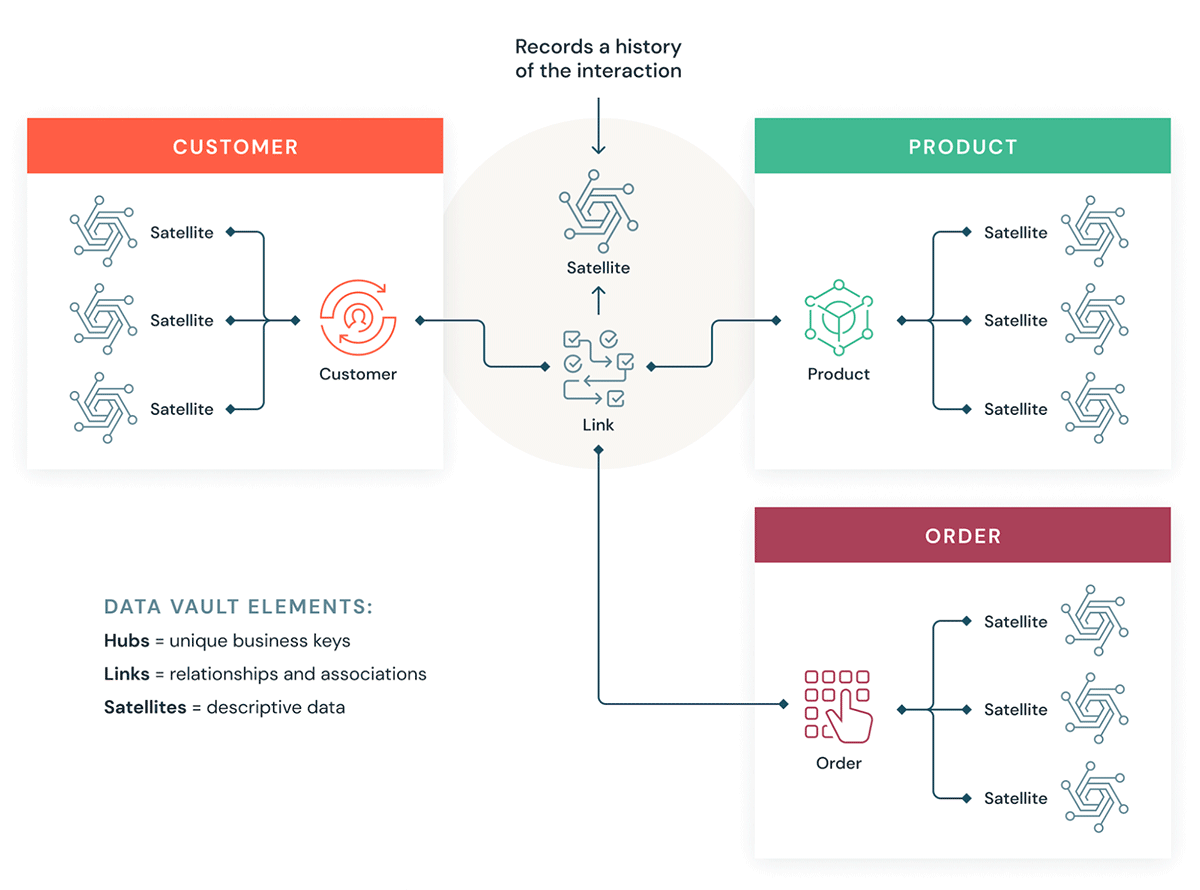
O objetivo da modelagem Data Vault é adaptar-se aos requisitos de negócios em rápida mudança e dar suporte ao desenvolvimento mais rápido e ágil de data warehouses por design. Um Data Vault é adequado à metodologia lakehouse, pois o modelo de dados é facilmente extensível e granular com seu design de hub, link e satellite, de modo que as alterações de design e ETL são facilmente implementadas.
Vamos entender alguns blocos de construção de um Data Vault. Em geral, um modelo de Data Vault tem três tipos de entidades:
- Hubs — Um Hub representa uma entidade de negócio principal, como clientes, produtos, pedidos, etc. Os analistas usarão as keys naturais/de negócio para obter informações sobre um Hub. A key primária das tabelas de Hub geralmente é derivada de uma combinação do ID do conceito de negócio, da data de carregamento e de outra informação de metadados.
- Links: os links representam relacionamentos entre hubs. Ele tem apenas as chaves de junção. É como uma tabela de fatos sem fatos no modelo dimensional. Sem atributos - apenas chaves de junção.
- Satélites — As tabelas satélite têm os atributos das entidades no Hub ou nos Links. Elas têm informações descritivas sobre as entidades de negócios principais. Elas são semelhantes a uma versão normalizada de uma tabela de Dimensão. Por exemplo, um hub de clientes pode ter muitas tabelas satélite, como atributos geográficos do cliente, score de crédito do cliente, níveis de fidelidade do cliente, etc.
Uma das maiores vantagens de usar a metodologia Data Vault é que os Jobs de ETL existentes precisam de significativamente menos refatoração quando o modelo de dados muda. O Data Vault é um estilo de modelagem "otimizado para escrita" e é compatível com abordagens de desenvolvimento ágil, sendo ideal para data lakes e para a abordagem lakehouse.
Como o Data Vault se encaixa em um Lakehouse
Vamos ver como alguns de nossos clientes estão usando a Modelagem Data Vault em uma arquitetura Databricks Lakehouse:
Considerações para implementar um Modelo Data Vault no Databricks Lakehouse
- A modelagem Data Vault recomenda o uso de um hash de chaves de negócios como chaves primárias. O Databricks oferece suporte a funções hash, md5 e SHA prontas para uso para dar suporte a chaves de negócios.
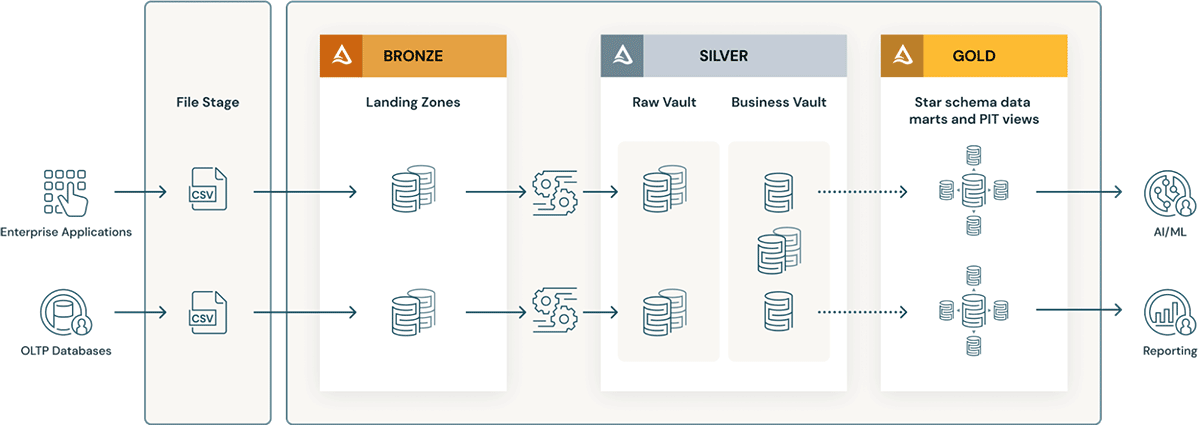
- As camadas do Data Vault têm o conceito de uma landing zone (e, às vezes, uma staging zone). Ambas as camadas físicas se encaixam naturalmente na camada Bronze do data lakehouse. Se os dados da landing zone chegarem em formatos como Avro, CSV, Parquet, XML e JSON, eles serão convertidos em tabelas no formato Delta na staging zone, para que o ETL subsequente possa ter um alto desempenho.
- O Raw Vault é criado a partir da zona de landing ou de preparo. Os dados são modelados como tabelas Hub, Link e Satélite no Raw Data Vault. Regras de ETL "de negócios" adicionais normalmente não são aplicadas ao carregar o Vault de dados brutos.
- Todas as regras de negócio de ETL, regras de qualidade de dados e regras de limpeza e conformidade são aplicadas entre o Raw e o Business Vault. As tabelas do Business Vault podem ser organizadas por domínios de dados, que servem como um "repository central" empresarial de dados padronizados e limpos. Os gestores de dados e SMEs são responsáveis pela governança, pela qualidade dos dados e pelas regras de negócio em suas áreas do Business Vault.
- Tabelas de auxílio à query, como tabelas Point-in-Time (PIT) e Bridge, são criadas para a camada de apresentação sobre o business vault. As tabelas PIT melhorarão o desempenho da query, pois alguns satellites e hubs são pré-unidos e fornecem algumas condições WHERE com filtragem "point in time". As tabelas Bridge pré-unem hubs ou entidades para fornecer views achatadas do tipo "tabela dimensional" para entidades. Delta Live Tables são exatamente como Visualizações Materializadas e podem ser usadas para criar tabelas Point-in-Time, bem como tabelas Bridge na camada ouro/Apresentação sobre o Business Data Vault.
- À medida que os processos de negócios mudam e se adaptam, o modelo Data Vault pode ser facilmente estendido sem refatoração massiva, como os modelos dimensionais. Hubs adicionais (áreas de assunto) podem ser facilmente adicionados a Links (tabelas de join pura) e satellites adicionais (por exemplo, segmentações de clientes) podem ser adicionados a um Hub (cliente) com alterações mínimas.
- Além disso, carregar um data warehouse de modelo dimensional na camada ouro torna-se mais fácil pelos seguintes motivos:
- Os hubs facilitam o gerenciamento de chaves (chaves naturais dos hubs podem ser convertidas em chaves substitutas por meio de Identity columns).
- Os satélites facilitam o carregamento de dimensões porque contêm todos os atributos.
- Os Links tornam o carregamento de tabelas de fatos bastante simples, porque contêm todos os relacionamentos.
Dicas para obter o melhor desempenho de um Modelo Data Vault no Databricks Lakehouse
- Use tabelas no formato Delta para as tabelas do Raw Vault, do Business Vault e da camada Gold.
- Certifique-se de usar índices OPTIMIZE e Z-order em todas as chaves de junção de Hubs, Links e Satellites.
- Não particione excessivamente as tabelas, especialmente as tabelas satellites menores. Use o Bloom filter indexing em colunas de data, colunas de flag atual e colunas de predicado que normalmente são filtradas para garantir o melhor desempenho, especialmente se você precisar criar índices adicionais além da Z-order.
- O Delta Live Tables (Visualizações Materializadas) facilita muito a criação e o gerenciamento de tabelas PIT.
- Reduza o
optimize.maxFileSizepara um número menor, como 32-64 MB, em vez do default de 1 GB. Ao criar arquivos menores, você pode se beneficiar do file pruning e minimizar a E/S recuperando os dados que precisa join. - O modelo Data Vault tem comparativamente mais joins, então use a versão mais recente do DBR, que garante que o Adaptive Query Execution esteja ativado por padrão para que a melhor estratégia de join seja usada automaticamente. Use dicas de junção somente se necessário. (para ajuste de desempenho avançado).
Saiba mais sobre modelagem Data Vault na Data Vault Alliance.
Comece a construir seu Data Vault no Lakehouse
Experimente a Databricks gratuitamente por 14 dias
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.