Administração do Databricks Workspace – Melhores Práticas para Administradores de Conta, Workspace e Metastore
Uma história de três administradores
Este blog faz parte da nossa série Admin Essentials, onde discutimos tópicos relevantes para administradores do Databricks. Outros blogs incluem nossas Melhores Práticas de Gerenciamento de Workspace, Estratégias de DR com Terraform e muitos outros! Fique de olho em mais conteúdo em breve. Em blogs anteriores focados em administração, discutimos como estabelecer e manter uma organização de workspace forte por meio de design inicial e automação de aspectos como DR, CI/CD e verificações de integridade do sistema. Um aspecto igualmente importante da administração é como você se organiza dentro de seus workspaces, especialmente quando se trata dos muitos tipos diferentes de personas de administrador que podem existir dentro de um Lakehouse. Neste blog, falaremos sobre as considerações administrativas de gerenciamento de um workspace, como:
- Configurar políticas e diretrizes para preparar o onboarding de novos usuários e casos de uso para o futuro
- Governar o uso de recursos
- Garantir o acesso permitido aos dados
- Otimizar o uso de computação para aproveitar ao máximo seu investimento
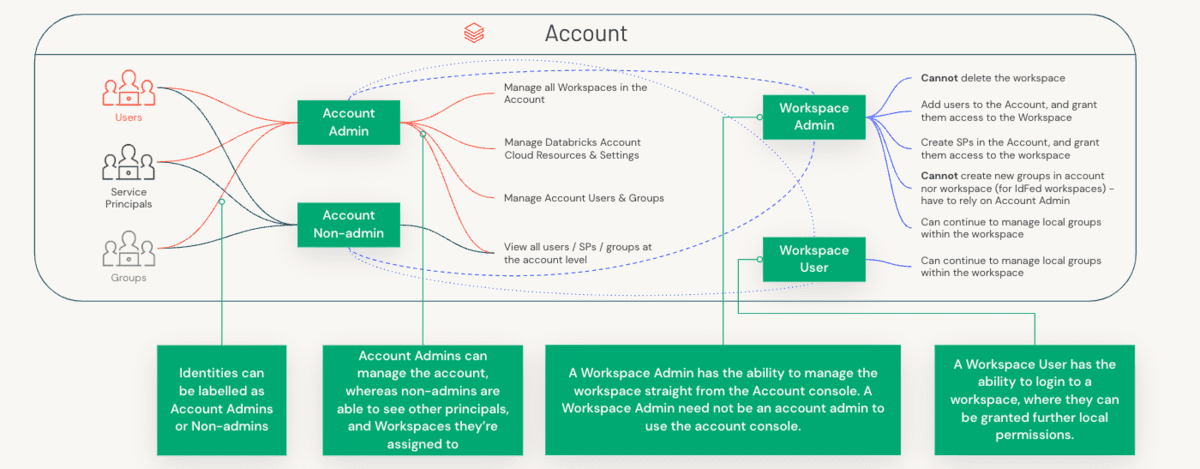
Para entender a delimitação de funções, primeiro precisamos entender a distinção entre um Administrador de Conta e um Administrador de Workspace, e os componentes específicos que cada uma dessas funções gerencia.
Administradores de Conta vs. Administradores de Workspace vs. Administradores de Metastore
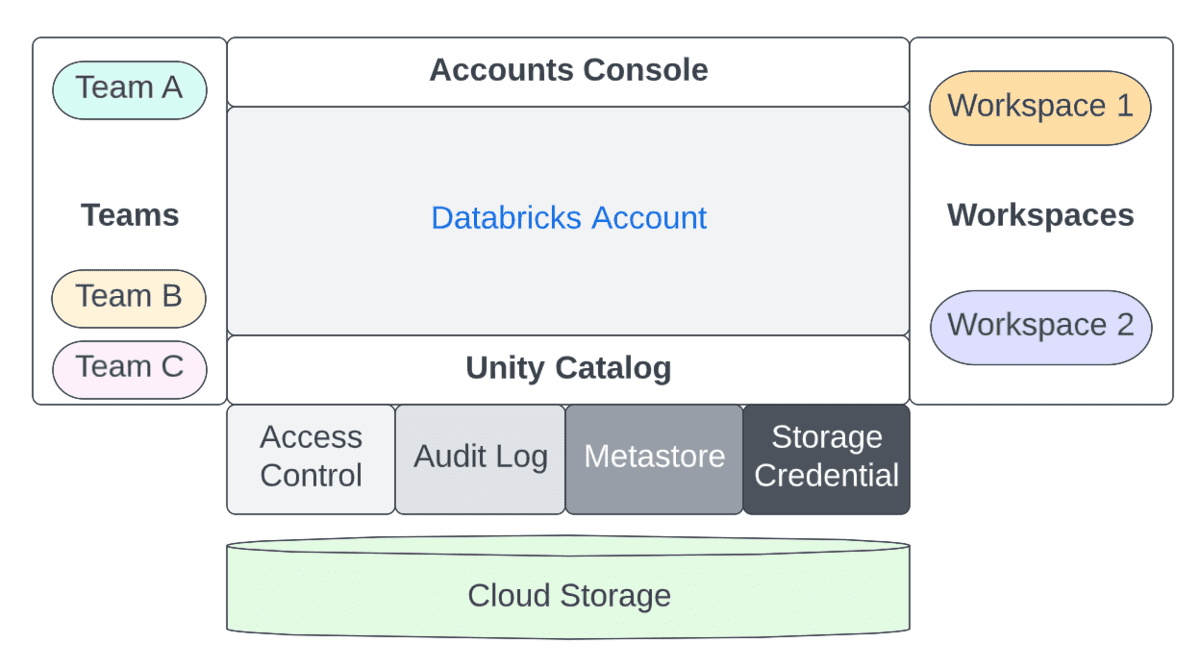
As preocupações administrativas são divididas entre contas (um construto de alto nível que geralmente é mapeado 1:1 com sua organização) e workspaces (um nível de isolamento mais granular que pode ser mapeado de várias maneiras, por exemplo, por LOB). Vamos dar uma olhada na separação de tarefas entre essas três funções.
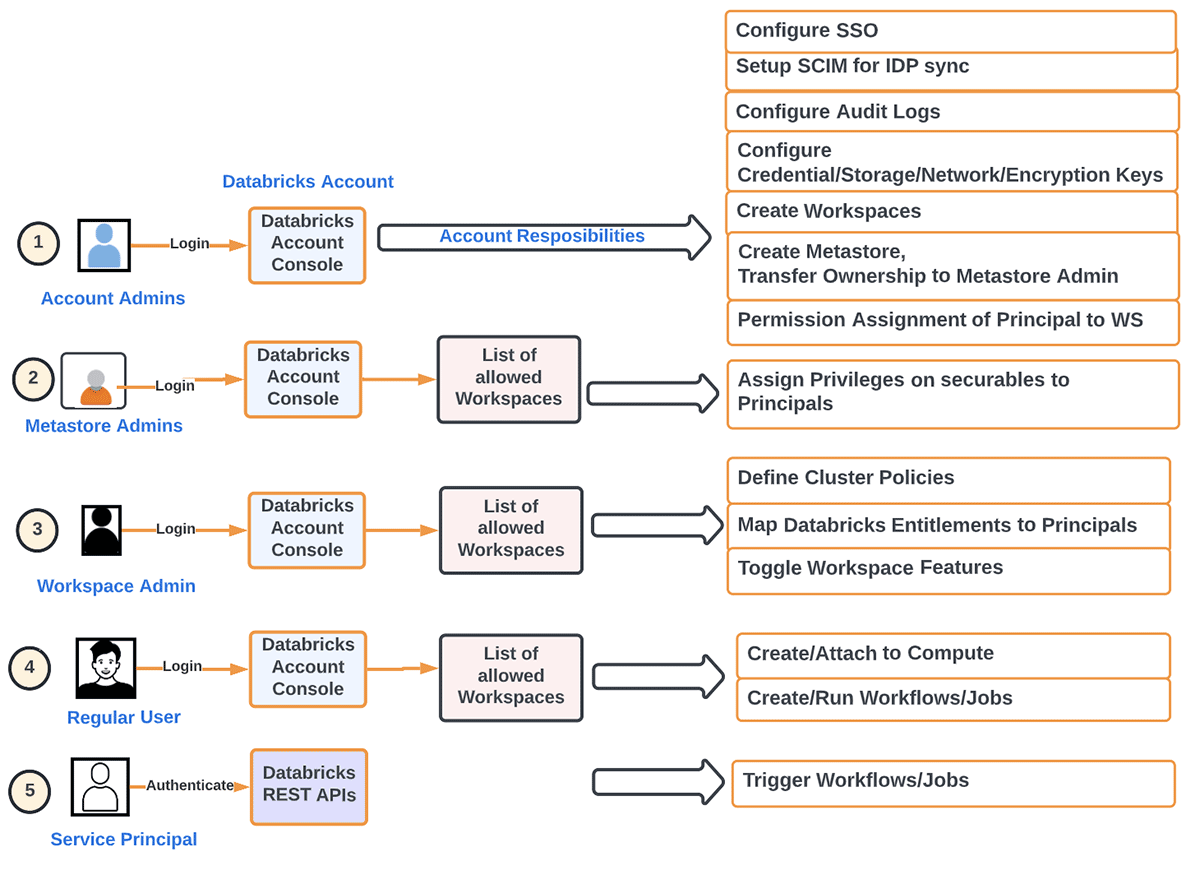
Para afirmar isso de outra forma, podemos detalhar as principais responsabilidades de um Administrador de Conta da seguinte forma:
- Provisionamento de Principais (Grupos/Usuários/Serviço) e SSO no nível da conta. Federação de Identidade refere-se à atribuição de Identidades de Nível de Conta acesso a workspaces diretamente da conta.
- Configuração de Metastores
- Configuração do Log de Auditoria
- Monitoramento de Uso no nível da Conta (DBU, Faturamento)
- Criação de workspaces de acordo com o método de organização desejado
- Gerenciamento de outros objetos de nível de workspace (armazenamento, credenciais, rede, etc.)
- Automação de cargas de trabalho de desenvolvimento usando IaaC para remover o elemento humano em cargas de trabalho de produção
- Ativação/desativação de recursos no nível da Conta, como cargas de trabalho serverless, Delta sharing
Por outro lado, as principais preocupações de um Administrador de Workspace são:
- Atribuição de Funções apropriadas (Usuário/Admin) no nível do workspace para Principais
- Atribuição de Entitlements (ACLs) apropriados no nível do workspace para Principais
- Opcionalmente, configuração de SSO no nível do workspace
- Definição de Políticas de Cluster para conceder aos Principais permissão para
- Definir recursos de computação (Clusters/Warehouses/Pools)
- Definir Orquestração (Jobs/Pipelines/Workflows)
- Ativação/desativação de recursos no nível do Workspace
- Atribuição de permissões a Principais
- Acesso a Dados (ao usar metastore hive interno/externo)
- Gerenciar o acesso de Principais a recursos de computação
- Gerenciamento de URLs externas para recursos como Repos (incluindo lista de permissões)
- Controle de segurança e proteção de dados
- Desativar/restringir DBFS para evitar exposição acidental de dados entre equipes
- Impedir o download de dados de resultados (de notebooks/DBSQL) para evitar exfiltração de dados
- Ativar Controle de Acesso (Objetos do Workspace, Clusters, Pools, Jobs, Tabelas, etc.)
- Definição de entrega de logs no nível do cluster (ou seja, configuração de armazenamento para logs de cluster, idealmente através de Políticas de Cluster)
Para resumir as diferenças entre o administrador de conta e o administrador de workspace, a tabela abaixo captura a separação entre essas duas personas para algumas dimensões-chave:
| Admin de Conta | Admin de Metastore | Admin de Workspace | |
|---|---|---|---|
| Gerenciamento de Workspace | - Criar, Atualizar, Excluir workspaces - Pode adicionar outros administradores |
Não Aplicável | - Gerencia apenas ativos dentro de um workspace |
| Gerenciamento de Usuários | - Criar usuários, grupos e principais de serviço ou usar SCIM para sincronizar dados de IDPs. - Conceder permissão a Principais para Workspaces com a API de Atribuição de Permissão |
Não Aplicável | - Recomendamos o uso do UC para governança central de todos os seus ativos de dados (securables). A Federação de Identidade estará Ativada para qualquer workspace vinculado a um Metastore do Unity Catalog (UC). - Para workspaces habilitados em Federação de Identidade, configure SCIM no Nível da Conta para todos os Principais e pare o SCIM no Nível do Workspace. - Para Workspaces sem UC, você pode usar SCIM no nível do workspace (mas esses usuários também serão promovidos a identidades de nível de conta). - Grupos criados no nível do workspace serão considerados grupos "locais" do nível do workspace e não terão acesso ao Unity Catalog |
| Acesso e Gerenciamento de Dados | - Criar Metastore(s) - Vincular Workspace(s) ao Metastore - Transferir a propriedade do metastore para o Admin/grupo de Metastore |
Com Unity Catalog: - Gerenciar privilégios em todos os securables (catálogo, esquema, tabelas, views) do metastore - CONCEDER (Delegar) Acesso a Catálogo, Esquema (Banco de Dados), Tabela, View, Localizações Externas e Credenciais de Armazenamento para Gerentes/Proprietários de Dados |
- Hoje, com metastores Hive, os clientes usam uma variedade de construtos para proteger o acesso a dados, como Perfis de Instância na AWS, Principais de Serviço no Azure, ACLs de Tabela, Passagem de Credenciais, entre outros. - Com o Unity Catalog, isso é definido no nível da conta e GRANTS ANSI serão usados para ACL todos os securables |
| Gerenciamento de Clusters | Não Aplicável | Não Aplicável | - Criar clusters para várias personas/tamanhos para personas de DE/ML/SQL para cargas de trabalho S/M/L - Remover a permissão allow-cluster-create do grupo users padrão. - Criar Políticas de Cluster, conceder acesso a políticas para grupos apropriados - Dar permissão Can_Use para grupos para SQL Warehouses |
| Gerenciamento de Workflows | Não Aplicável | Não Aplicável | - Garantir que existam políticas de cluster de job/DLT/uso geral e que os grupos tenham acesso a elas - Pré-criar clusters de propósito de aplicativo que os usuários podem reiniciar |
| Gerenciamento de Orçamento | - Configurar orçamentos por workspace/sku/tags de cluster - Monitorar Uso por tags no Console de Contas (roadmap) - Tabela de sistema de uso faturável para consultar via DBSQL (roadmap) |
Não Aplicável | Não Aplicável |
| Otimizar / Ajustar | Não aplicável | Não aplicável | - Maximizar computação; Usar DBR mais recente; Usar Photon - Trabalhar em conjunto com as equipes de Linha de Negócios/Centro de Excelência para seguir as melhores práticas e otimizações para aproveitar ao máximo o investimento em infraestrutura |
Dimensionando um workspace para atender às necessidades de computação de pico
O número máximo de nós de cluster (indiretamente o maior job ou o número máximo de jobs concorrentes) é determinado pelo número máximo de IPs disponíveis na VPC e, portanto, dimensionar a VPC corretamente é uma consideração importante de design. Cada nó consome 2 IPs (no Azure, AWS). Aqui estão os detalhes relevantes para a nuvem de sua escolha: AWS, Azure, GCP. Usaremos um exemplo do Databricks na AWS para ilustrar isso. Use este para mapear CIDR para IP. O intervalo CIDR da VPC permitido para um workspace E2 é /25 - /16. Pelo menos 2 sub-redes privadas em 2 zonas de disponibilidade diferentes devem ser configuradas. As máscaras de sub-rede devem estar entre /16-/17. As VPCs são unidades de isolamento lógico e, desde que 2 VPCs não precisem se comunicar, ou seja, fazer peering uma com a outra, elas podem ter o mesmo intervalo. No entanto, se precisarem, é preciso ter cuidado para evitar sobreposição de IP. Vamos pegar um exemplo de uma VPC com intervalo CIDR /16:
| VPC CIDR /16 | Máx. # de IPs para esta VPC: 65.536 | Clusters de nó único/múltiplos nós são iniciados em uma sub-rede |
| 2 AZs | Se cada AZ for /17: => 32.768 * 2 = 65.536 IPs, nenhuma outra sub-rede é possível | 32.768 IPs => máximo de 16.384 nós em cada sub-rede |
| Se cada AZ for /23: => 512 * 2 = 1.024 IPs. 65.536 - 1.024 = 64.512 IPs restantes | 512 IPs => máximo de 256 nós em cada sub-rede | |
| 4 AZs | Se cada AZ for /18: 16.384 * 4 = 65.536 IPs, nenhuma outra sub-rede é possível | 16.384 IPs => máximo de 8192 nós em cada sub-rede |
Equilibrando controle e agilidade para administradores de workspace
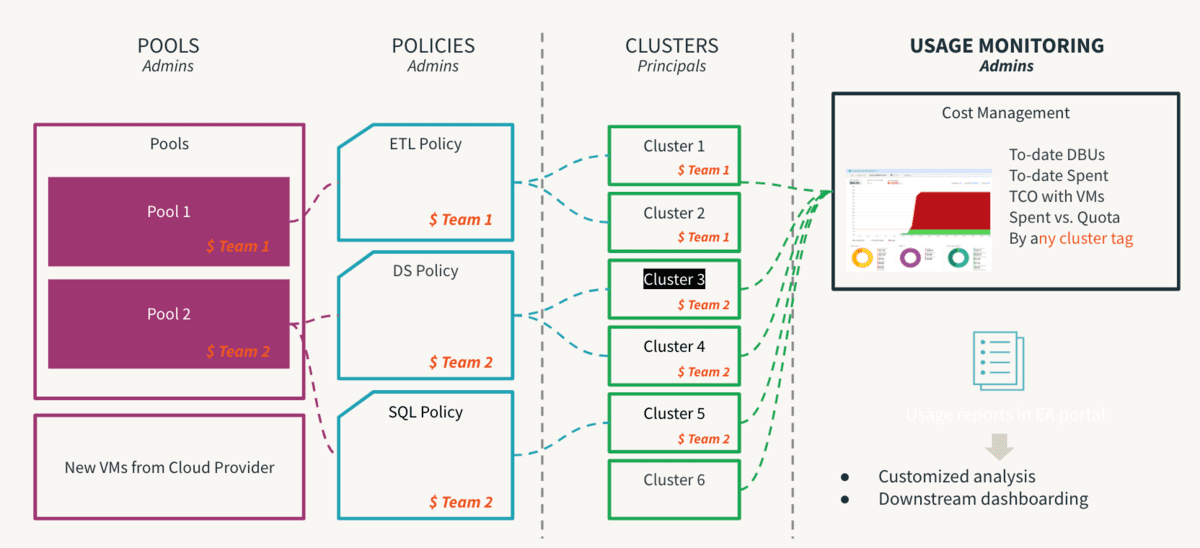
Computação é o componente mais caro de qualquer investimento em infraestrutura de nuvem. A democratização de dados leva à inovação e facilitar o autoatendimento é o primeiro passo para habilitar uma cultura orientada a dados. No entanto, em um ambiente multilocatário, um usuário inexperiente ou um erro humano inadvertido pode levar a custos descontrolados ou exposição não intencional. Se os controles forem muito rigorosos, isso criará gargalos de acesso e sufocará a inovação. Portanto, os administradores precisam definir barreiras para permitir o autoatendimento sem os riscos inerentes. Além disso, eles devem ser capazes de monitorar a adesão a esses controles. É aqui que as Políticas de Cluster são úteis, onde as regras são definidas e os direitos mapeados para que o usuário opere dentro dos perímetros permitidos e seu processo de tomada de decisão seja muito simplificado. Deve-se notar que as políticas devem ser apoiadas por processos para serem verdadeiramente eficazes, de modo que exceções pontuais possam ser gerenciadas por processos para evitar caos desnecessário. Uma etapa crítica desse processo é remover o direito de *allow-cluster-create* do grupo padrão de *users* em um workspace, para que os usuários possam utilizar apenas computação governada por Políticas de Cluster. As seguintes são as principais recomendações das Melhores Práticas de Política de Cluster e podem ser resumidas abaixo:
- Use tamanhos de camiseta (T-shirt sizes) para fornecer modelos de cluster padrão
- Por tamanho de carga de trabalho (pequeno, médio, grande)
- Por persona (DE/ ML/ BI)
- Por proficiência (cidadão/ avançado)
- Gerencie a Governança aplicando o uso de
- Tags: atribuição por equipe, usuário, caso de uso
- a nomenclatura deve ser padronizada
- tornar alguns atributos obrigatórios ajuda para relatórios consistentes
- Tags: atribuição por equipe, usuário, caso de uso
- Controle o Consumo limitando
- Taxa de queima de DBU e propósito da política
- Tempo limite de auto-desligamento, tamanho mínimo/máximo de escalonamento
Considerações de computação
Ao contrário da infraestrutura de computação fixa local (on-premise), a nuvem nos oferece elasticidade e flexibilidade para combinar a computação certa com a carga de trabalho e o SLA em consideração. O diagrama abaixo mostra as várias opções. As entradas são parâmetros como tipo de carga de trabalho ou ambiente e a saída é o tipo e tamanho da computação que melhor se adapta.
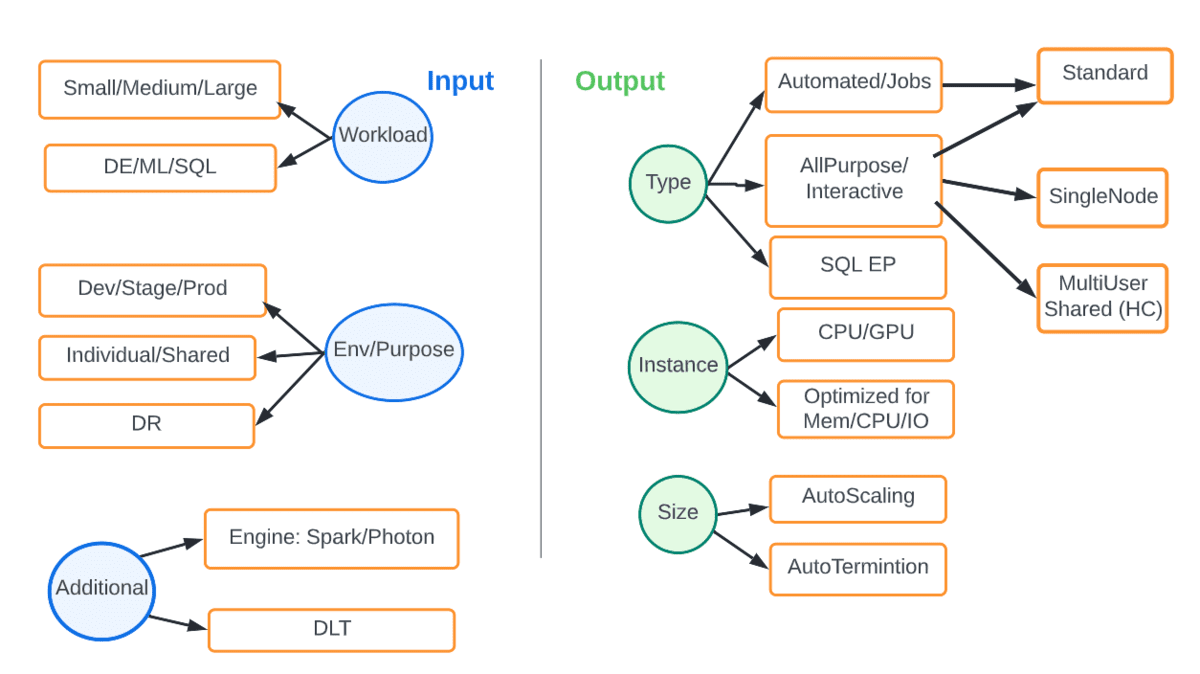
Por exemplo, uma carga de trabalho de DE em produção deve estar sempre em clusters de job automatizados, preferencialmente com o DBR mais recente, com escalonamento automático e usando o motor Photon. A tabela abaixo captura alguns cenários comuns.
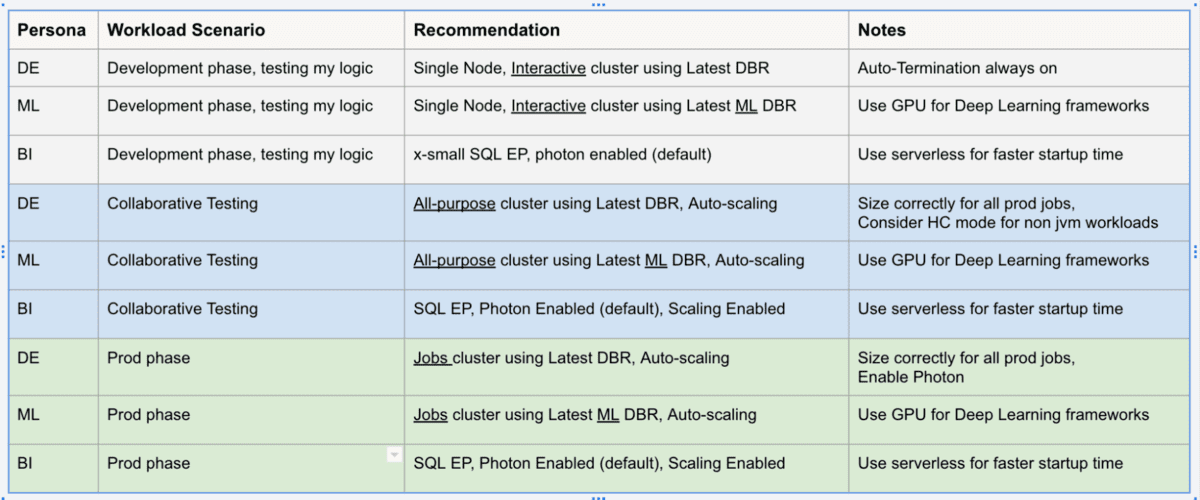
Considerações de fluxo de trabalho
Agora que os requisitos de computação foram formalizados, precisamos analisar
- Como os Workflows serão definidos e acionados
- Como as Tarefas podem reutilizar computa�ção entre si
- Como as dependências de Tarefas serão gerenciadas
- Como as tarefas com falha podem ser retentadas
- Como as atualizações de versão (spark, biblioteca) e patches são aplicados
Estas são considerações de Engenharia de Dados e DevOps que giram em torno do caso de uso e são tipicamente uma preocupação direta de um administrador. Existem algumas tarefas de higiene que podem ser monitoradas, como
- Um workspace tem um limite máximo no número total de jobs configurados. Mas muitos desses jobs podem não ser invocados e precisam ser limpos para abrir espaço para os genuínos. Um administrador pode executar verificações para determinar a lista de descarte válida de jobs inativos.
- Todos os jobs de produção devem ser executados como um principal de serviço e o acesso do usuário a um ambiente de produção deve ser altamente restrito. Revise as permissões de Jobs.
- Jobs podem falhar, então cada job deve ser configurado para alertas de falha e opcionalmente para retentativas. Revise email_notifications, max_retries e outras propriedades aqui
- Cada job deve ser associado a políticas de cluster e marcado adequadamente para atribuição.
DLT: Exemplo de um framework ideal para pipelines confiáveis em escala
Trabalhando com milhares de clientes, grandes e pequenos, em diferentes verticais da indústria, desafios comuns de dados para desenvolvimento e operacionalização se tornaram aparentes, e é por isso que a Databricks criou o Delta Live Tables (DLT). É uma plataforma gerenciada que oferece simplificar o desenvolvimento e a manutenção de cargas de trabalho ETL, permitindo a criação de pipelines declarativos onde você especifica o 'o quê' e não o 'como'. Isso simplifica as tarefas de um engenheiro de dados, levando a menos cenários de suporte para administradores.
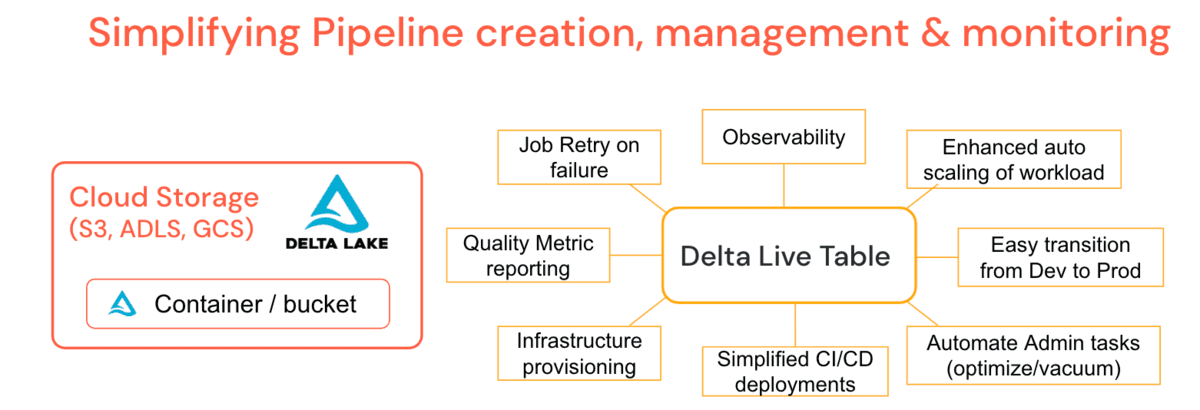
DLT incorpora funcionalidades comuns de administração, como trabalhos periódicos de otimização e vácuo, diretamente na definição do pipeline com um trabalho de manutenção que garante que eles sejam executados sem supervisão adicional. DLT oferece observabilidade profunda em pipelines para operações simplificadas, como linhagem, monitoramento e verificações de qualidade de dados. Por exemplo, se o cluster for encerrado, a plataforma tentará novamente automaticamente (no modo de Produção) em vez de depender do engenheiro de dados para tê-lo provisionado explicitamente. O Auto-Scaling Aprimorado pode lidar com picos súbitos de dados que exigem o aumento do cluster e reduzir a escala de forma graciosa. Em outras palavras, o dimensionamento automático de cluster e a tolerância a falhas de pipeline são um recurso da plataforma. Latências de turntable permitem que você execute pipelines em lote ou streaming e mova pipelines de desenvolvimento para produção com relativa facilidade, gerenciando a configuração em vez do código. Você pode controlar o custo de seus pipelines utilizando Políticas de Cluster específicas de DLT. O DLT também atualiza automaticamente seu mecanismo de runtime, removendo assim a responsabilidade dos Administradores ou Engenheiros de Dados, e permitindo que você se concentre apenas em gerar valor para o negócio.
UC: Exemplo de um framework ideal de Governança de Dados
Unity Catalog (UC) permite que as organizações adotem um modelo de segurança comum para tabelas e arquivos para todos os workspaces sob uma única conta, o que não era possível antes por meio de simples instruções GRANT. Ao conceder e auditar todo o acesso a dados, tabelas ou arquivos, de um cluster DE/DS ou SQL Warehouse, as organizações podem simplificar sua estratégia de auditoria e monitoramento sem depender de primitivas por nuvem. As principais funcionalidades que o UC oferece incluem:
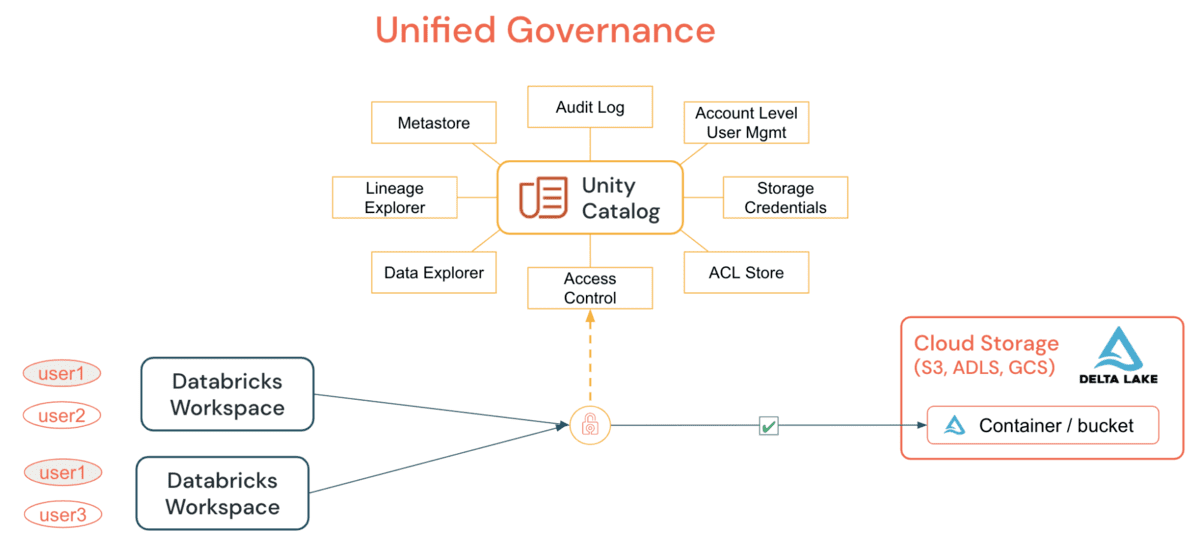
O UC simplifica o trabalho de um administrador (tanto no nível da conta quanto do workspace) centralizando as definições, o monitoramento e a descoberta de dados em todo o metastore, e facilitando o compartilhamento seguro de dados, independentemente do número de workspaces a ele conectados. Utilizando o modelo Definir uma Vez, Proteger em Todos os Lugares, isso tem a vantagem adicional de evitar a exposição acidental de dados no cenário em que os privilégios de um usuário são inadvertidamente mal representados em um workspace, o que pode dar a eles um backdoor para acessar dados que não eram destinados ao seu consumo. Tudo isso pode ser facilmente realizado utilizando Identidades de Nível de Conta e Permissões de Dados. O Registro de Auditoria do UC permite visibilidade total de todas as ações de todos os usuários em todos os níveis em todos os objetos, e se você configurar o registro de auditoria detalhado, cada comando executado, de um notebook ou Databricks SQL, é capturado. O acesso a securables pode ser concedido por um administrador de metastore, o proprietário de um objeto, ou o proprietário do catálogo ou esquema que contém o objeto. Recomenda-se que o administrador de nível de conta delegue a função de metastore nomeando um grupo para ser os administradores do metastore cujo único propósito é conceder os privilégios de acesso corretos.
Recomendações e melhores práticas
- As funções e responsabilidades dos administradores de conta, administradores de metastore e administradores de workspace são bem definidas e complementares. Fluxos de trabalho como automação, solicitações de alteração, escalonamentos, etc., devem fluir para os proprietários apropriados, quer os workspaces sejam configurados por LOB ou gerenciados por um Centro de Excelência central.
- As Identidades de Nível de Conta devem ser habilitadas, pois isso permite o gerenciamento centralizado de principais para todos os workspaces, simplificando assim a administração. Recomendamos a configuração de recursos como SSO, SCIM e Logs de Auditoria no nível da conta. O SSO no nível do workspace ainda é necessário, até que o recurso de Federação de SSO esteja disponível.
- As Políticas de Cluster são uma alavanca poderosa que fornece salvaguardas para autoatendimento eficaz e simplifica muito o papel de um administrador de workspace. Fornecemos algumas políticas de exemplo aqui. O administrador da conta deve fornecer políticas padrão simples com base na persona principal/tamanho, idealmente por meio de automação como Terraform. Os administradores de workspace podem adicionar a essa lista para controles mais granulares. Combinado com um processo adequado, todos os cenários de exceção podem ser acomodados com elegância.
- O rastreamento do consumo contínuo para todos os tipos de carga de trabalho em todos os workspaces é visível para os administradores de conta através do console de contas. Recomendamos configurar a entrega de log de uso faturável para que tudo vá para seu armazenamento central na nuvem para rateio e análise. A API de Orçamento (Em Preview) deve ser configurada no nível da conta, o que permite aos administradores de conta criar limites nos workspaces, SKU e tags de cluster e receber alertas de consumo para que ações oportunas possam ser tomadas para permanecer dentro dos orçamentos alocados. Use uma ferramenta como Overwatch para rastrear o uso em um nível ainda mais granular para ajudar a identificar áreas de melhoria quando se trata de utilização de recursos de computação.
- A plataforma Databricks continua a inovar e simplificar o trabalho das várias personas de dados, abstraindo funcionalidades administrativas comuns na plataforma. Nossa recomendação é usar Delta Live Tables para novos pipelines e Unity Catalog para todo o seu gerenciamento de usuários e controle de acesso a dados.
Por fim, é importante notar que para a maioria dessas práticas recomendadas, e, de fato, para a maioria das coisas que mencionamos neste blog, coordenação e trabalho em equipe são essenciais para o sucesso. Embora seja teoricamente possível que administradores de Conta e de Workspace existam isoladamente, isso não só vai contra os princípios gerais do Lakehouse, mas também torna a vida mais difícil para todos os envolvidos. Talvez a sugestão mais importante a ser retirada deste artigo seja conectar Administradores de Conta/Workspace + Líderes de Projeto/Dados + Usuários dentro de sua própria organização. Mecanismos como canais no Teams/Slack, um alias de e-mail e/ou um encontro semanal têm se mostrado bem-sucedidos. As organizações mais eficazes que vemos aqui na Databricks são aquelas que abraçam a abertura não apenas em sua tecnologia, mas em suas operações. Fique atento para mais blogs focados em administradores em breve, desde recomendações de log e exfiltração até resumos interessantes de nossos recursos de plataforma focados em gerenciamento.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.