Databricks Workspace Administration – Best Practices for Account, Workspace and Metastore Admins
A tale of three admins
by Anindita Mahapatra, Mohan Mathews and Greg Wood
This blog is part of our Admin Essentials series, where we discuss topics relevant to Databricks administrators. Other blogs include our Workspace Management Best Practices, DR Strategies with Terraform, and many more! Keep an eye out for more content coming soon. In past admin-focused blogs, we have discussed how to establish and maintain a strong workspace organization through upfront design and automation of aspects such as DR, CI/CD, and system health checks. An equally important aspect of administration is how you organize within your workspaces- especially when it comes to the many different types of admin personas that may exist within a Lakehouse. In this blog we will talk about the administrative considerations of managing a workspace, such as how to:
- Set up policies and guardrails to future-proof onboarding of new users and use cases
- Govern usage of resources
- Ensure permissible data access
- Optimize compute usage to make the most of your investment
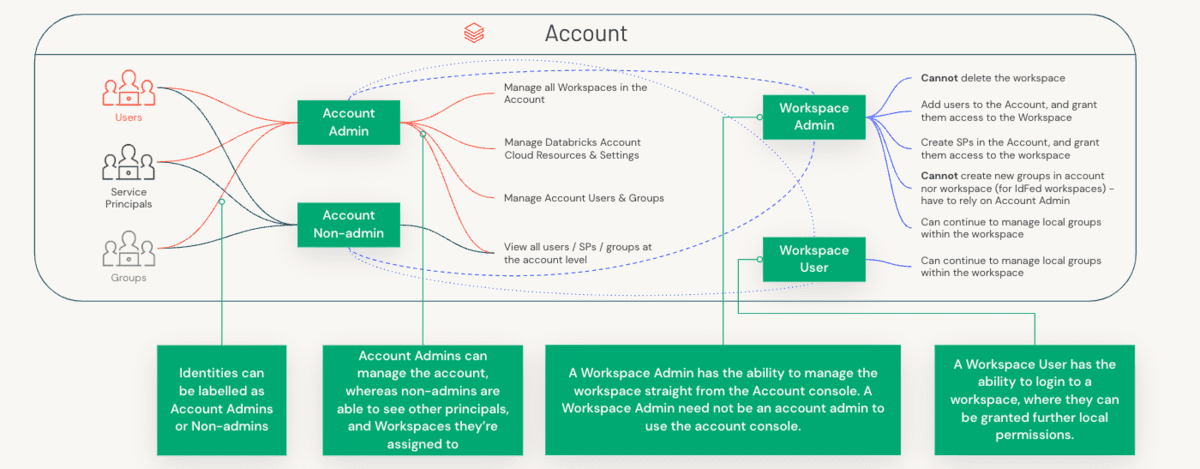
In order to understand the delineation of roles, we first need to understand the distinction between an Account Administrator and a Workspace Administrator, and the specific components that each of these roles manage.
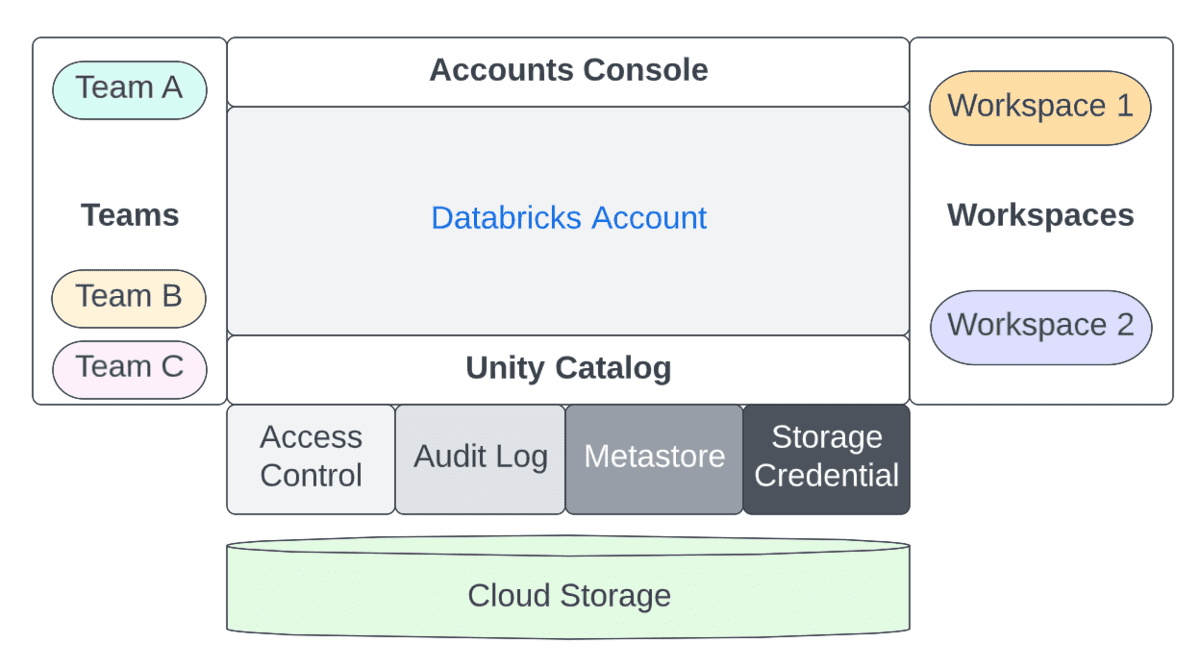
Account Admins Vs Workspace Admins Vs Metastore Admins
Administrative concerns are split across both accounts (a high-level construct that is often mapped 1:1 with your organization) & workspaces (a more granular level of isolation that can be mapped various ways, i.e, by LOB). Let's take a look at the separation of duties between these three roles.
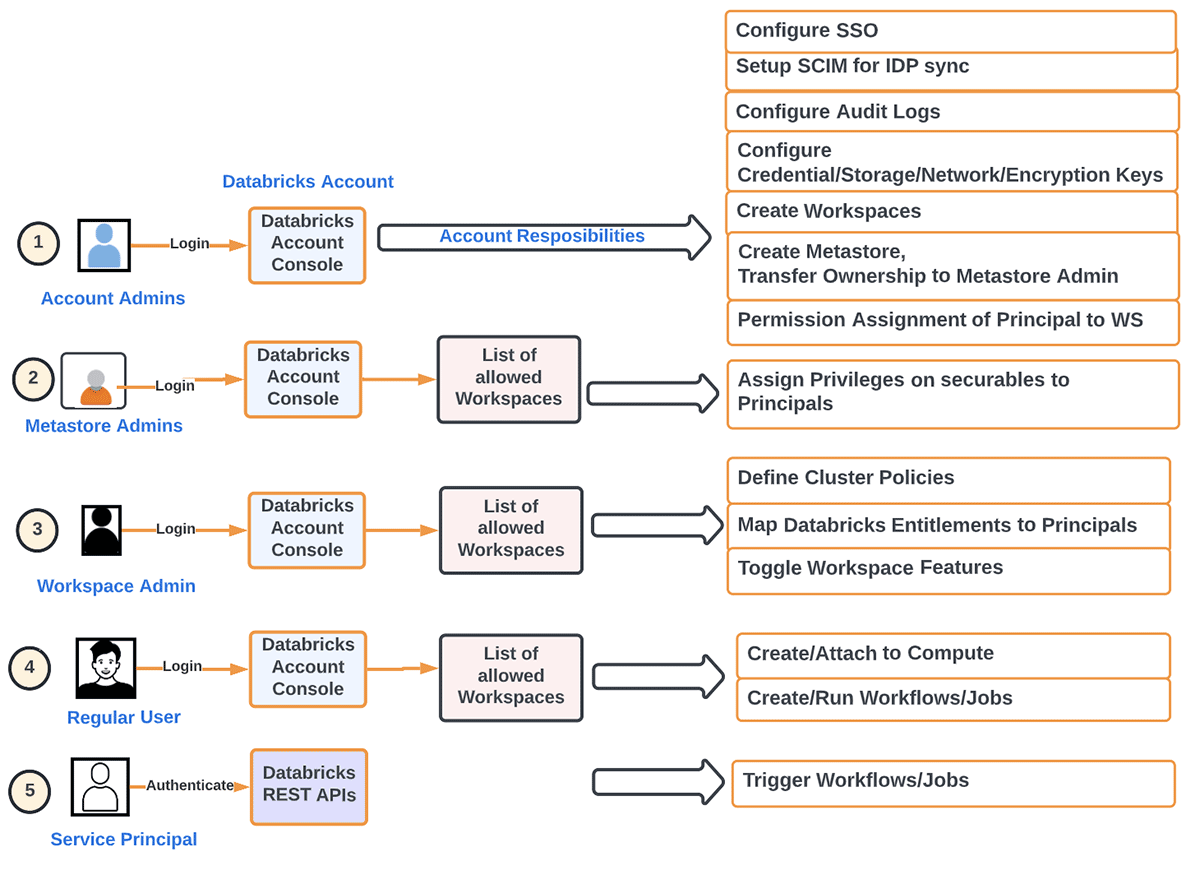
To state this in a different way, we can break down the primary responsibilities of an Account Administrator as the following:
- Provisioning of Principals(Groups/Users/Service) and SSO at the account level. Identity Federation refers to assigning Account Level Identities access to workspaces directly from the account.
- Configuration of Metastores
- Setting up Audit Log
- Monitoring Usage at the Account level (DBU, Billing)
- Creating workspaces according to the desired organization method
- Managing other workspace-level objects (storage, credentials, network, etc.)
- Automating dev workloads using IaaC to remove the human element in prod workloads
- Turning features on/off at Account level such as serverless workloads, Delta sharing
On the other hand, the primary concerns of a Workspace Administrator are:
- Assigning appropriate Roles (User/Admin) at the workspace level to Principals
- Assigning appropriate Entitlements (ACLs) at the workspace level to Principals
- Optionally setting SSO at the workspace level
- Defining Cluster Policies to entitle Principals to enable them to
- Define compute resource (Clusters/Warehouses/Pools)
- Define Orchestration (Jobs/Pipelines/Workflows)
- Turning features on/off at Workspace level
- Assigning entitlements to Principals
- Data Access (when using internal/external hive metastore)
- Manage Principals' access to compute resources
- Managing external URLs for features such as Repos (including allow-listing)
- Controlling security & data protection
- Turn off / restrict DBFS to prevent accidental data exposure across teams
- Prevent downloading result data (from notebooks/DBSQL) to prevent data exfiltration
- Enable Access Control (Workspace Objects, Clusters, Pools, Jobs, Tables etc)
- Defining log delivery at the cluster level (i.e., setting up storage for cluster logs, ideally through Cluster Policies)
To summarize the differences between the account and workspace admin, the table below captures the separation between these two personas for a few key dimensions:
| Account Admin | Metastore Admin | Workspace Admin | |
|---|---|---|---|
| Workspace Management | - Create, Update, Delete workspaces - Can add other admins |
Not Applicable | - Only Manages assets within a workspace |
| User Management | - Create users, groups and service principals or use SCIM to sync data from IDPs. - Entitle Principals to Workspaces with the Permission Assignment API |
Not Applicable | - We recommend use of the UC for central governance of all your data assets(securables). Identity Federation will be On for any workspace linked to a Unity Catalog (UC) Metastore. - For workspaces enabled on Identity Federation, setup SCIM at the Account Level for all Principals and stop SCIM at the Workspace Level. - For non-UC Workspaces, you can SCIM at the workspace level (but these users will also be promoted to account level identities). - Groups created at workspace level will be considered "local" workspace-level groups and will not have access to Unity Catalog |
| Data Access and Management | - Create Metastore(s) - Link Workspace(s) to Metatore - Transfer ownership of metastore to Metastore Admin/group |
With Unity Catalog: -Manage privileges on all the securables (catalog, schema, tables, views) of the metastore - GRANT (Delegate) Access to Catalog, Schema(Database), Table, View, External Locations and Storage Credentials to Data Stewards/Owners |
- Today with Hive-metastore(s), customers use a variety of constructs to protect data access, such as Instance Profiles on AWS, Service Principals in Azure, Table ACLs, Credential Passthrough, among others. -With Unity Catalog, this is defined at the account level and ANSI GRANTS will be used to ACL all securables |
| Cluster Management | Not Applicable | Not Applicable | - Create clusters for various personas/sizes for DE/ML/SQL personas for S/M/L workloads - Remove allow-cluster-create entitlement from default users group. - Create Cluster Policies, grant access to policies to appropriate groups - Give Can_Use entitlement to groups for SQL Warehouses |
| Workflow Management | Not Applicable | Not Applicable | - Ensure job/DLT/all-purpose cluster policies exist and groups have access to them - Pre-create app-purpose clusters that users can restart |
| Budget Management | - Set up budgets per workspace/sku/cluster tags - Monitor Usage by tags in the Accounts Console (roadmap) - Billable usage system table to query via DBSQL (roadmap) |
Not Applicable | Not Applicable |
| Optimize / Tune | Not Applicable | Not Applicable | - Maximize Compute; Use latest DBR; Use Photon - Work alongside Line Of Business/Center Of Excellence teams to follow best practices and optimizations to make the most of the infrastructure investment |
Sizing a workspace to meet peak compute needs
The max number of cluster nodes (indirectly the largest job or the max number of concurrent jobs) is determined by the max number of IPs available in the VPC and hence sizing the VPC correctly is an important design consideration. Each node takes up 2 IPs (in Azure, AWS). Here are the relevant details for the cloud of your choice: AWS, Azure, GCP. We'll use an example from Databricks on AWS to illustrate this. Use this to map CIDR to IP. The VPC CIDR range allowed for an E2 workspace is /25 - /16. At least 2 private subnets in 2 different availability zones must be configured. The subnet masks should be between /16-/17. VPCs are logical isolation units and as long as 2 VPCs do not need to talk, i.e. peer to each other, they can have the same range. However, if they do, then care has to be taken to avoid IP overlap. Let us take an example of a VPC with CIDR rage /16:
| VPC CIDR /16 | Max # IPs for this VPC: 65,536 | Single/multi-node clusters are spun up in a subnet |
| 2 AZs | If each AZ is /17 : => 32,768 * 2 = 65,536 IPs no other subnet is possible | 32,768 IPs => max of 16,384 nodes in each subnet |
| If each AZ is /23 instead: => 512 * 2 = 1,024 IPs 65,536 - 1,024 = 64, 512 IPs left | 512 IPs => max of 256 nodes in each subnet | |
| 4 AZs | If each AZ is /18: 16,384 * 4 = 65,536 IPs no other subnet is possible | 16,384 IPs => max of 8192 nodes in each subnet |
Balancing control & agility for workspace admins
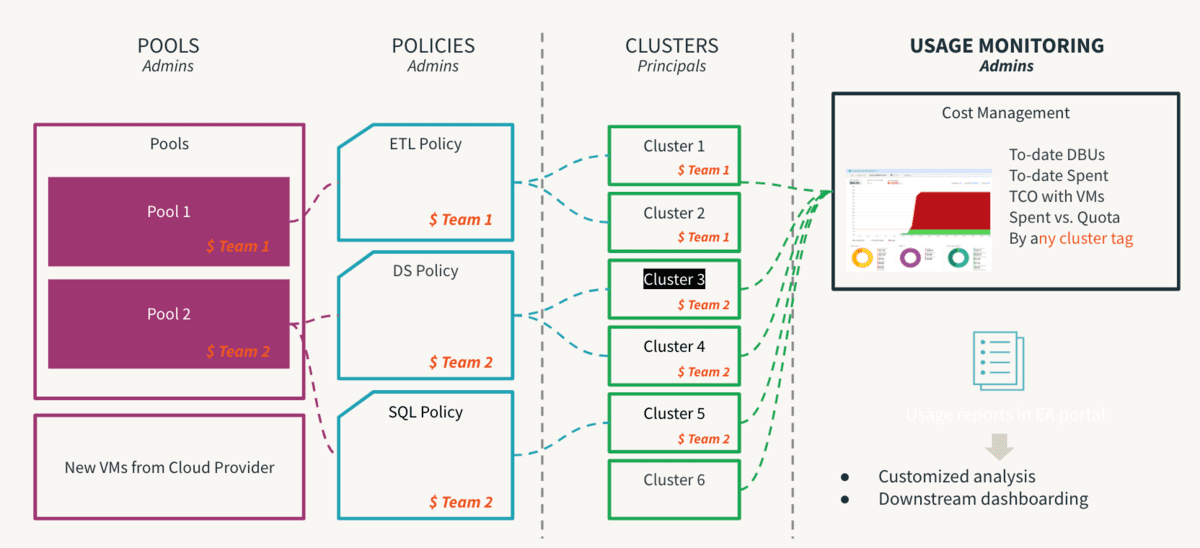
Compute is the most expensive component of any cloud infrastructure investment. Data democratization leads to innovation and facilitating self-service is the first step towards enabling a data driven culture. However, in a multi-tenant environment, an inexperienced user or an inadvertent human error could lead to runaway costs or inadvertent exposure. If controls are too stringent, it will create access bottlenecks and stifle innovation. So, admins need to set guard-rails to allow self-service without the inherent risks. Further, they should be able to monitor the adherence of these controls. This is where Cluster Policies come in handy, where the rules are defined and entitlements mapped so the user operates within permissible perimeters and their decision-making process is greatly simplified. It should be noted that policies should be backed by process to be truly effective so that one off exceptions can be managed by process to avoid unnecessary chaos. One critical step of this process is to remove the allow-cluster-create entitlement from the default users group in a workspace so that users can only utilize compute governed by Cluster Policies. The following are top recommendations of Cluster Policy Best Practices and can be summarized as below:
- Use T-shirt sizes to provide standard cluster templates
- By workload size (small, medium, large)
- By persona (DE/ ML/ BI)
- By proficiency (citizen/ advanced)
- Manage Governance by enforcing use of
- Tags : attribution by team, user, use case
- naming should be standardized
- making some attributes mandatory helps for consistent reporting
- Tags : attribution by team, user, use case
- Control Consumption by limiting
- DBU Burn rate and purpose of policy
- Auto-termination timeout, Scaling min/max size
Compute considerations
Unlike fixed on-prem compute infrastructure, cloud gives us elasticity as well as flexibility to match the right compute to the workload and SLA under consideration. The diagram below shows the various options. The inputs are parameters such as type of workload or environment and the output is the type and size of compute that is a best-fit.
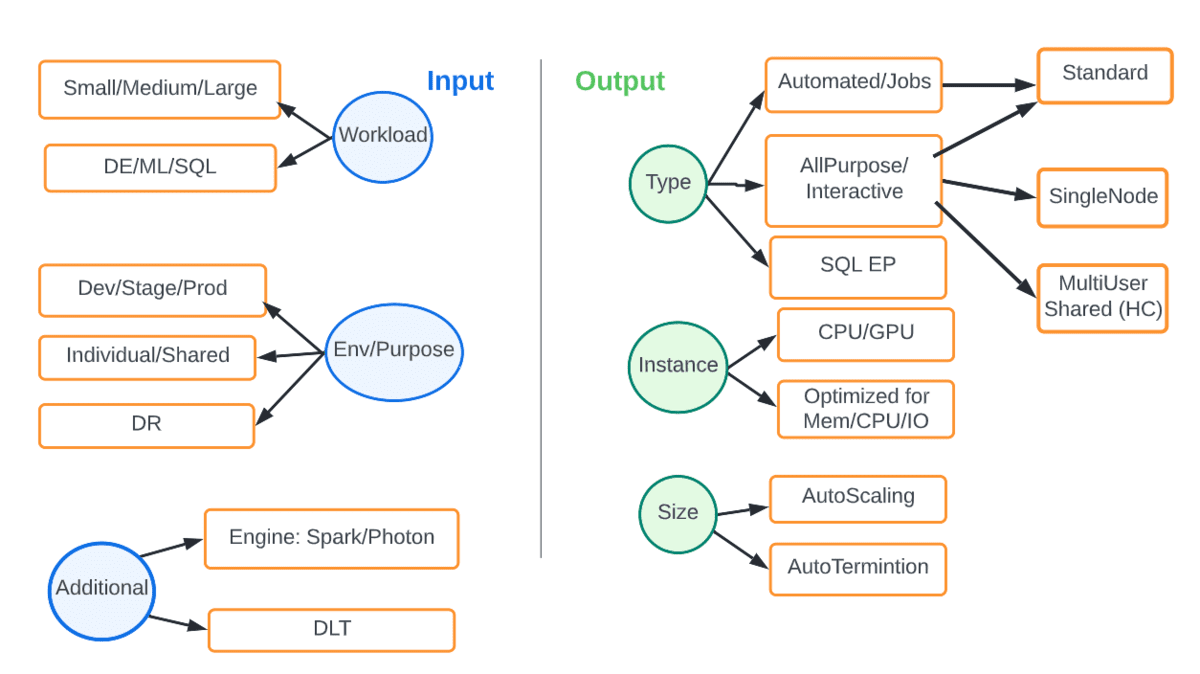
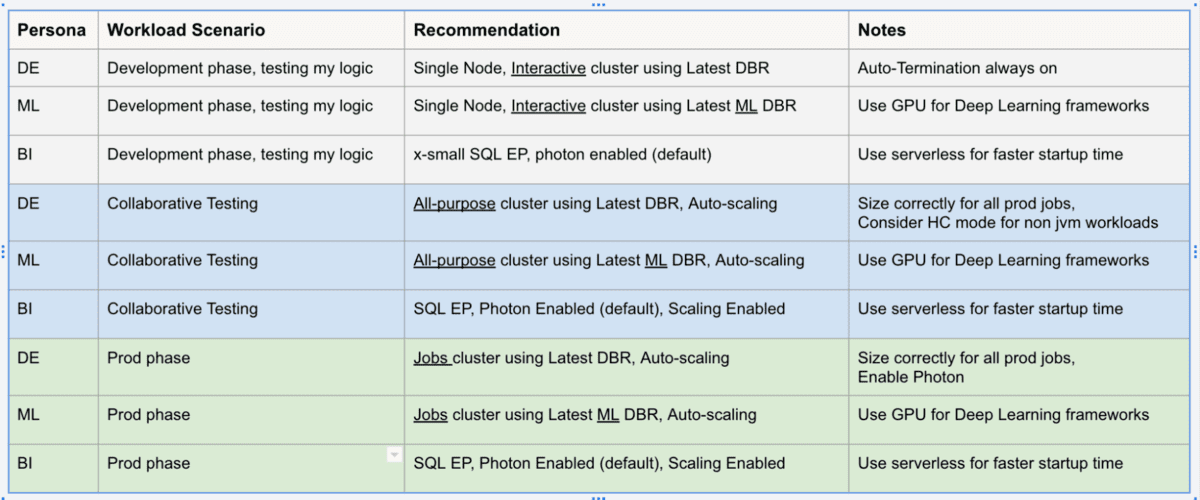
For example, a production DE workload should always be on automated job clusters preferably with the latest DBR, with autoscaling and using the photon engine. The table below captures some common scenarios.
Workflow considerations
Now that the compute requirements have been formalized, we need to look at
- How Workflows will be defined and triggered
- How Tasks can reuse compute amongst themselves
- How Task dependencies will be managed
- How failed tasks can be retried
- How version upgrades (spark, library) and patches are applied
These are Date Engineering and DevOps considerations that are centered around the use case and is typically a direct concern of an administrator. There are some hygiene tasks that can be monitored such as
- A workspace has a max limit on the total number of configured jobs. But a lot of these jobs may not be invoked and need to be cleaned up to make space for genuine ones. An administrator can run checks to determine the valid eviction list of defunct jobs.
- All production jobs should be run as a service principal and user access to a production environment should be highly restricted. Review the Jobs permissions.
- Jobs can fail, so every job should be set for failure alerts and optionally for retries. Review email_notifications, max_retries and other properties here
- Every job should be associated with cluster policies and tagged properly for attribution.
DLT: Example of an ideal framework for reliable pipelines at scale
Working with thousands of clients big and small across different industry verticals, common data challenges for development and operationalization became apparent, which is why Databricks created Delta Live Tables (DLT). It is a managed platform offering to simplify ETL workload development and maintenance by allowing creation of declarative pipelines where you specify the 'what' & not the 'how'. This simplifies the tasks of a data engineer, leading to fewer support scenarios for administrators.
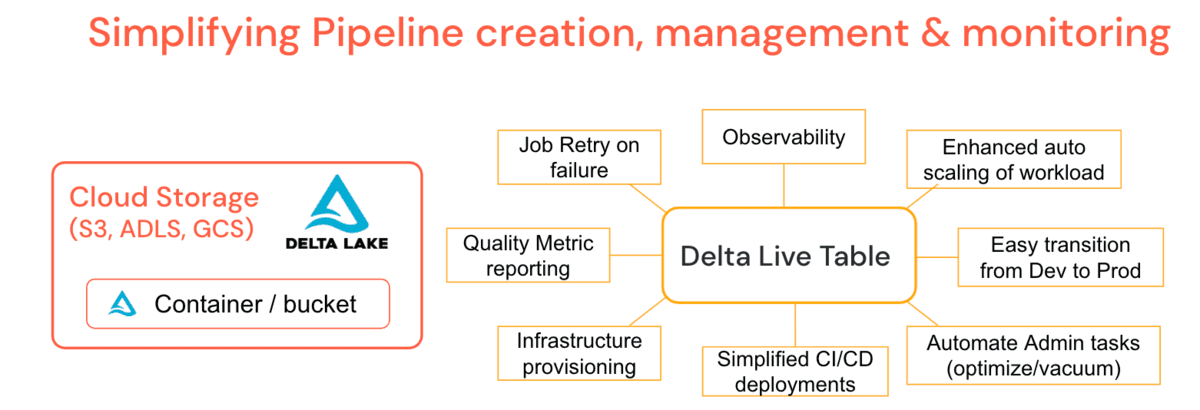
DLT incorporates common admin functionality such as periodic optimize & vacuum jobs right into the pipeline definition with a maintenance job that ensures that they run without additional babysitting. DLT offers deep observability into pipelines for simplified operations such as lineage, monitoring and data quality checks. For example, if the cluster terminates, the platform auto-retries (in Production mode) instead of relying on the data engineer to have provisioned it explicitly. Enhanced Auto-Scaling can handle sudden data bursts that require cluster upsizing and downscale gracefully. In other words, automated cluster scaling & pipeline fault tolerance is a platform feature. Turntable latencies enable you to run pipelines in batch or streaming and move dev pipelines to prod with relative ease by managing configuration instead of code. You can control the cost of your Pipelines by utilizing DLT-specific Cluster Policies. DLT also auto-upgrades your runtime engine, thus removing the responsibility from Admins or Data Engineers, and allowing you to focus only on generating business value.
UC: Example of an ideal Data Governance framework
Unity Catalog (UC) enables organizations to adopt a common security model for tables and files for all workspaces under a single account, which was not possible before through simple GRANT statements. By granting and auditing all access to data, tables/or files, from a DE/DS cluster or SQL Warehouse, organizations can simplify their audit and monitoring strategy without relying on per-cloud primitives. The primary capabilities that UC provides include:
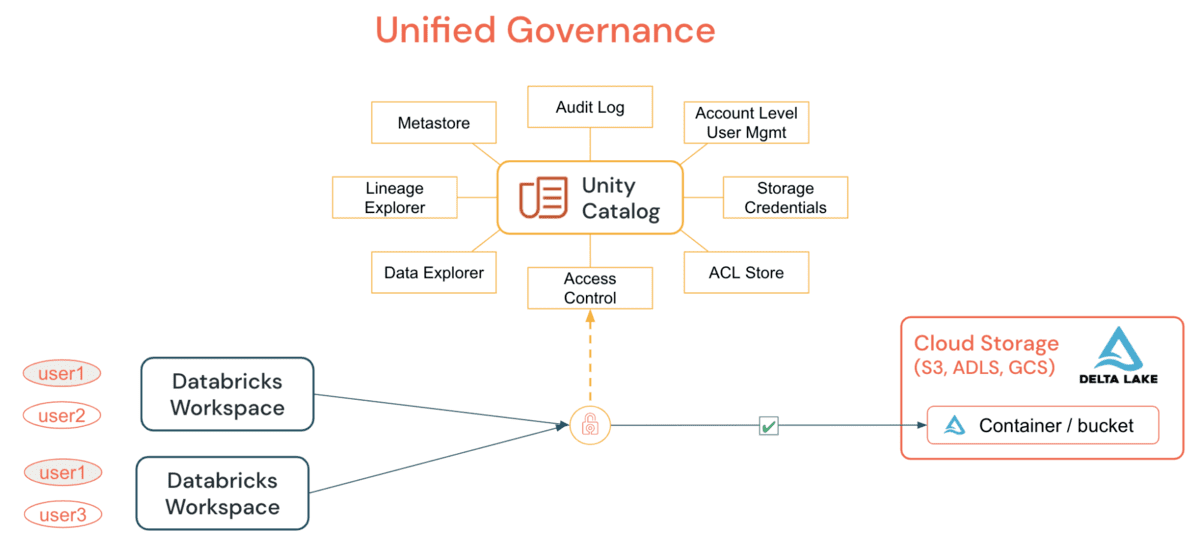
UC simplifies the job of an administrator (both at the account and workspace level) by centralizing the definitions, monitoring and discoverability of data across the metastore, and making it easy to securely share data irrespective of the number of workspaces that are attached to it.. Utilizing the Define Once, Secure Everywhere model, this has the added advantage of avoiding accidental data exposure in the scenario of a user's privileges inadvertently misrepresented in one workspace which may give them a backdoor to get to data that was not intended for their consumption. All of this can be accomplished easily by utilizing Account Level Identities and Data Permissions. UC Audit Logging allows full visibility into all actions by all users at all levels on all objects, and if you configure verbose audit logging, then each command executed, from a notebook or Databricks SQL, is captured. Access to securables can be granted by either a metastore admin, the owner of an object, or the owner of the catalog or schema that contains the object. It is recommended that the account-level admin delegate the metastore role by nominating a group to be the metastore admins whose sole purpose is granting the right access privileges.
Recommendations and best practices
- Roles and responsibilities of Account admins, Metastore admins and Workspace admins are well-defined and complementary. Workflows such as automation, change requests, escalations, etc. should flow to the appropriate owners, whether the workspaces are set up by LOB or managed by a central Center of Excellence.
- Account Level Identities should be enabled as this allows for centralized principal management for all workspaces, thereby simplifying administration. We recommend setting up features like SSO, SCIM and Audit Logs at the account level. Workspace-level SSO is still required, until the SSO Federation feature is available.
- Cluster Policies are a powerful lever that provides guardrails for effective self-service and greatly simplifies the role of a workspace administrator. We provide some sample policies here. The account admin should provide simple default policies based on primary persona/t-shirt size, ideally through automation such as Terraform. Workspace admins can add to that list for more fine-grained controls. Combined with an adequate process, all exception scenarios can be accommodated gracefully.
- Tracking the on-going consumption for all workload types across all workspaces is visible to account admins via the accounts console. We recommend setting up billable usage log delivery so that it all goes to your central cloud storage for chargeback and analysis. Budget API (In Preview) should be configured at the account level, which allows account administrators to create thresholds at the workspaces, SKU, and cluster tags level and receive alerts on consumption so that timely action can be taken to remain within allotted budgets. Use a tool such as Overwatch to track usage at an even more granular level to help identify areas of improvement when it comes to utilization of compute resources.
- The Databricks platform continues to innovate and simplify the job of the various data personas by abstracting common admin functionalities into the platform. Our recommendation is to use Delta Live Tables for new pipelines and Unity Catalog for all your user management and data access control.
Finally, it's important to note that for most of these best practices, and in fact, most of the things we mention in this blog, coordination, and teamwork are tantamount to success. Although it's theoretically possible for Account and Workspace admins to exist in a silo, this not only goes against the general Lakehouse principles but makes life harder for everyone involved. Perhaps the most important suggestion to take away from this article is to connect Account / Workspace Admins + Project / Data Leads + Users within your own organization. Mechanisms such as Teams/Slack channel, an email alias, and/or a weekly meetup have been proven successful. The most effective organizations we see here at Databricks are those that embrace openness not just in their technology, but in their operations. Keep an eye out for more admin-focused blogs coming soon, from logging and exfiltration recommendations to exciting roundups of our platform features focused on management.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.