Construindo Produtos de Dados Geoespaciais
por Milos Colic
Este blog está desatualizado. Consulte este blog sobre Spatial SQL para obter abordagens atualizadas sobre como armazenar e processar dados geoespaciais na sua Databricks Lakehouse.
Dados geoespaciais impulsionam a inovação há séculos, por meio do uso de mapas, cartografia e, mais recentemente, conteúdo digital. Por exemplo, o mapa mais antigo encontrado foi gravado em um pedaço de presa de mamute e data de aproximadamente 25.000 a.C.. Isso torna os dados geoespaciais uma das fontes de dados mais antigas usadas pela sociedade para tomar decisões. Um exemplo mais recente, considerado o nascimento da análise espacial, é o de Charles Picquet em 1832, que usou dados geoespaciais para analisar surtos de cólera em Paris. Algumas décadas depois, John Snow, em 1854, seguiu a mesma abordagem para surtos de cólera em Londres. Esses dois indivíduos usaram dados geoespaciais para resolver um dos problemas mais difíceis de seus tempos e, efetivamente, salvaram inúmeras vidas. Avançando rapidamente para o século XX, o conceito de Sistemas de Informação Geográfica (GIS) foi introduzido pela primeira vez em 1967 em Ottawa, Canadá, pelo Departamento de Silvicultura e Desenvolvimento Rural.
Hoje, estamos no meio da revolução da indústria de computação em nuvem - escala de supercomputação disponível para qualquer organização, virtualmente escalável infinitamente tanto para armazenamento quanto para computação. Conceitos como data mesh e data marketplace estão emergindo na comunidade de dados para abordar questões como federação de plataforma e interoperabilidade. Como podemos adotar esses conceitos para dados geoespaciais, análise espacial e sistemas GIS? Adotando o conceito de produtos de dados e abordando o design de dados geoespaciais como um produto.
Neste blog, forneceremos um ponto de vista sobre como projetar produtos de dados geoespaciais escaláveis, modernos e robustos. Discutiremos como a Databricks Lakehouse Platform pode ser usada para desbloquear todo o potencial de produtos geoespaciais, que são um dos ativos mais valiosos para resolver os problemas mais difíceis de hoje e do futuro.
O que é um produto de dados? E como projetar um?
A definição mais ampla e concisa de "produto de dados" foi cunhada por DJ Patil (o primeiro Cientista Chefe de Dados dos EUA) em Data Jujitsu: The Art of Turning Data into Product: "um produto que facilita um objetivo final por meio do uso de dados". A complexidade desta definição (como admitido pelo próprio Patil) é necessária para encapsular a amplitude de produtos possíveis, para incluir dashboards, relatórios, planilhas Excel e até mesmo extratos CSV compartilhados por e-mail. Você pode notar que os exemplos fornecidos se deterioram rapidamente em qualidade, robustez e governança.
Quais são os conceitos que diferenciam um produto bem-sucedido de um malsucedido? É a embalagem? É o conteúdo? É a qualidade do conteúdo? Ou é apenas a adoção do produto no mercado? A Forbes define os 10 itens essenciais de um produto bem-sucedido. Uma boa estrutura para resumir isso é através da pirâmide de valor.
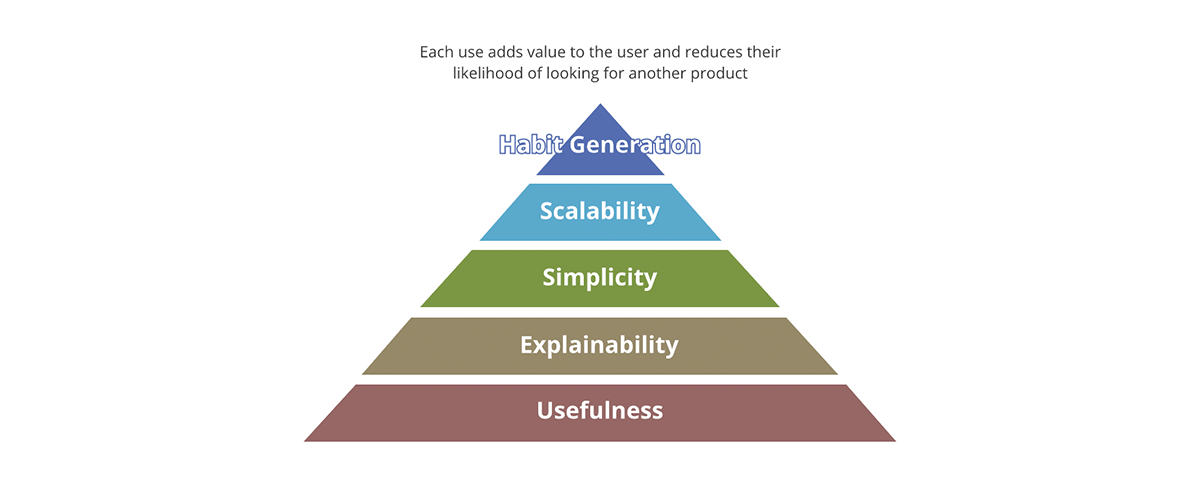
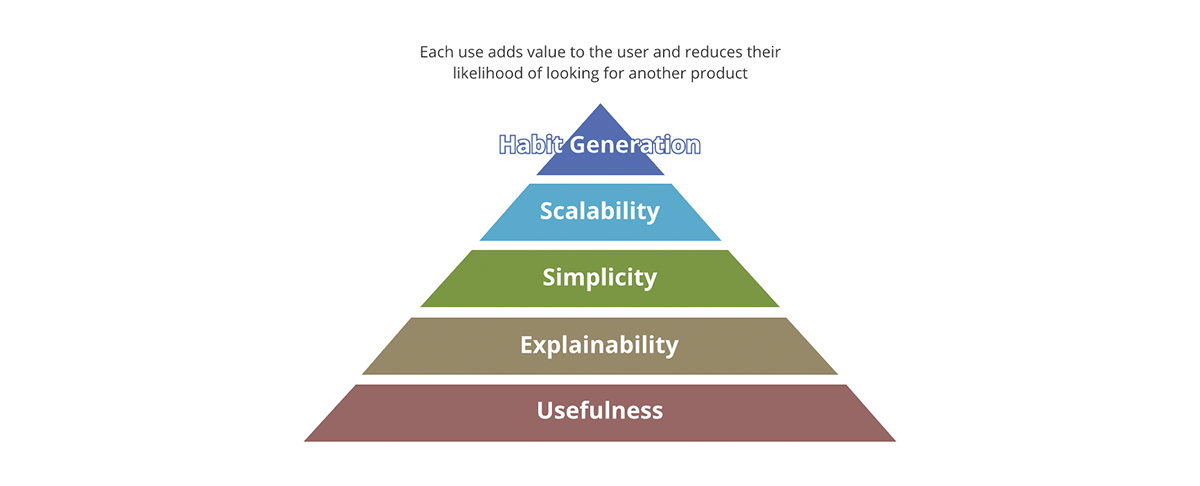{kind=link}
A pirâmide de valor prioriza cada aspecto do produto. Nem toda pergunta de valor que fazemos sobre o produto tem o mesmo peso. Se o resultado não for útil, nenhum dos outros aspectos importa - o resultado não é realmente um produto, mas se torna mais um poluente de dados para o conjunto de resultados úteis. Da mesma forma, a escalabilidade só importa depois que a simplicidade e a explicabilidade são abordadas.
Como a pirâmide de valor se relaciona com os produtos de dados? Cada saída de dados, para ser um produto de dados:
- Deve ter utilidade clara. A quantidade de dados que a sociedade está gerando é rivalizada apenas pela quantidade de poluentes de dados que estamos gerando. São saídas sem valor e uso claros, muito menos uma estratégia sobre o que fazer com elas.
- Deve ser explicável. Com o surgimento de IA/ML, a explicabilidade tornou-se ainda mais importante para a tomada de decisões orientada por dados. Os dados são tão bons quanto os metadados que os descrevem. Pense nisso em termos de alimentos - o sabor importa, mas um fator mais importante é o valor nutricional dos ingredientes.
- Deve ser simples. Um exemplo de mau uso do produto é usar um garfo para comer cereal em vez de uma colher. Além disso, a simplicidade é essencial, mas não suficiente; além da simplicidade, os produtos devem ser intuitivos. Sempre que possível, tanto os usos pretendidos quanto os não pretendidos dos dados devem ser óbvios.
- Deve ser escalável. Os dados são um dos poucos recursos que crescem com o uso. Quanto mais dados você processa, mais dados você tem. Se tanto as entradas quanto as saídas do sistema forem ilimitadas e em constante crescimento, o sistema deve ser escalável em poder de computação, capacidade de armazenamento e poder expressivo de computação. Plataformas de dados em nuvem como a Databricks estão em uma posição única para responder a todos os três aspectos.
- Deve gerar hábitos. No domínio de dados, não estamos preocupados com a retenção de clientes como é o caso de produtos de varejo. No entanto, o valor da geração de hábitos é óbvio se aplicado às melhores práticas. Os sistemas e as saídas de dados devem exibir as melhores práticas e promovê-las - deve ser mais fácil usar os dados e o sistema da maneira pretendida do que o contrário.
Os dados geoespaciais devem aderir a todos os aspectos mencionados anteriormente, assim como qualquer produto de dados. Além dessa tarefa árdua, os dados geoespaciais têm algumas necessidades específicas.
Padrões de dados geoespaciais
Padrões de dados geoespaciais são usados para garantir que os dados geográficos sejam coletados, organizados e compartilhados de maneira consistente e confiável. Esses padrões podem incluir diretrizes para coisas como formato de dados, sistemas de coordenadas, projeções de mapas e metadados. A adesão a padrões facilita o compartilhamento de dados entre diferentes organizações, permitindo maior colaboração e acesso mais amplo a informações geográficas.
A Geospatial Commission (Governo do Reino Unido) definiu o UK Geospatial Data Standards Register como um repositório central para padrões de dados a serem aplicados no caso de dados geoespaciais. Além disso, a missão deste registro é:
- "Garantir que os dados geoespaciais do Reino Unido sejam mais consistentes, coerentes e utilizáveis em uma gama mais ampla de sistemas." - Esses conceitos são um chamado para a importância da explicabilidade, utilidade e geração de hábitos (possivelmente outros aspectos da pirâmide de valor).
- "Capacitar a comunidade geoespacial do Reino Unido a se engajar mais com os padrões e órgãos normativos relevantes." - A geração de hábitos dentro da comunidade é tão importante quanto o design robusto e crítico do padrão. Se não forem adotados, os padrões são inúteis.
- "Promover a compreensão e o uso de padrões de dados geoespaciais em outros setores do governo." - A pirâmide de valor se aplica aos padrões também - conceitos como facilidade de adesão (utilidade/simplicidade), propósito do padrão (explicabilidade/utilidade), adoção (geração de hábitos) são críticos para a geração de valor de um padrão.
Uma ferramenta crítica para alcançar a missão de padrões de dados são os princípios de dados FAIR:
- Findable (Encontrável) - O primeiro passo para (re)utilizar dados é encontrá-los. Metadados e dados devem ser fáceis de encontrar tanto para humanos quanto para computadores. Metadados legíveis por máquina são essenciais para a descoberta automática de conjuntos de dados e serviços.
- Accessible (Acessível) - Uma vez que o usuário encontra os dados necessários, ele(a)/eles precisam saber como eles podem ser acessados, possivelmente incluindo autenticação e autorização.
- Interoperável - Os dados geralmente precisam ser integrados com outros dados. Além disso, os dados precisam interoperar com aplicativos ou fluxos de trabalho para análise, armazenamento e processamento.
- Reutilizável - O objetivo final do FAIR é otimizar a reutilização dos dados. Para atingir isso, metadados e dados devem ser bem descritos para que possam ser replicados e/ou combinados em diferentes cenários.
Compartilhamos a crença de que os princípios FAIR são cruciais para o design de produtos de dados escaláveis nos quais podemos confiar. Para ser justo, FAIR é baseado no bom senso, então por que é fundamental para nossas considerações? "O que vejo em FAIR não é novo em si, mas o que ele faz bem é articular, de forma acessível, a necessidade de uma abordagem holística para a melhoria dos dados. Essa facilidade de comunicação é o motivo pelo qual FAIR está sendo cada vez mais usado como um guarda-chuva para a melhoria dos dados - e não apenas na comunidade geoespacial." - A FAIR wind sets our course for data improvement.
Para apoiar ainda mais essa abordagem, o Federal Geographic Data Committee desenvolveu o National Spatial Data Infrastructure (NSDI) Strategic Plan que abrange os anos de 2021-2024 e foi aprovado em novembro de 2020. Os objetivos do NSDI são, em essência, os princípios FAIR e transmitem a mesma mensagem de projetar sistemas que promovam a economia circular de dados - produtos de dados que fluem entre organizações seguindo padrões comuns e, em cada etapa da cadeia de suprimentos de dados, desbloqueiam novo valor e novas oportunidades. O fato de esses princípios estarem permeando diferentes jurisdições e serem adotados por diferentes reguladores é uma prova da robustez e solidez da abordagem.

{kind=link}
Os conceitos FAIR se integram muito bem ao design de produtos de dados. Na verdade, FAIR atravessa toda a pirâmide de valor do produto e forma um ciclo de valor. Ao adotar tanto a pirâmide de valor quanto os princípios FAIR, projetamos produtos de dados com uma perspectiva interna e externa. Isso promove a reutilização de dados em vez do acúmulo de dados.
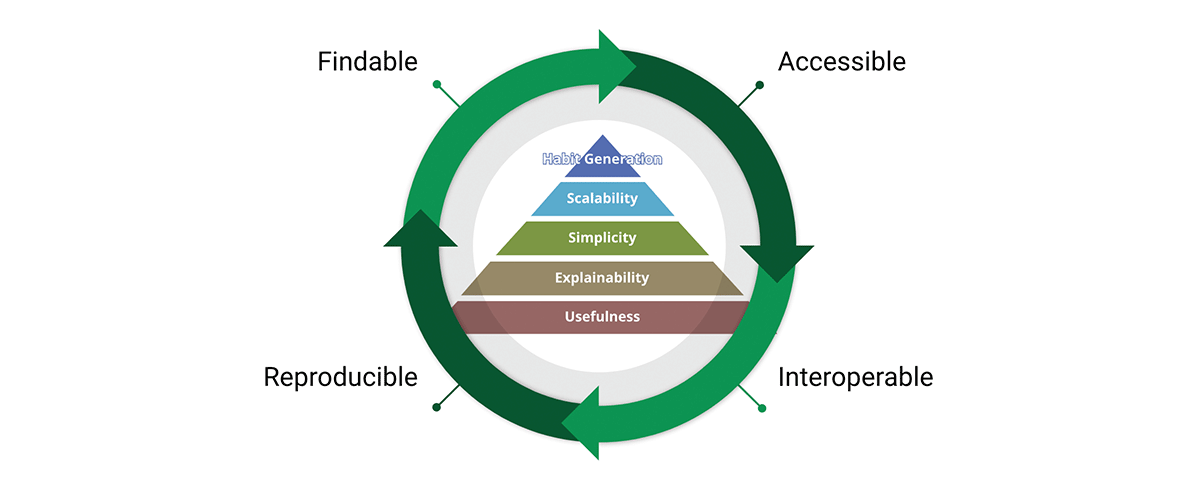
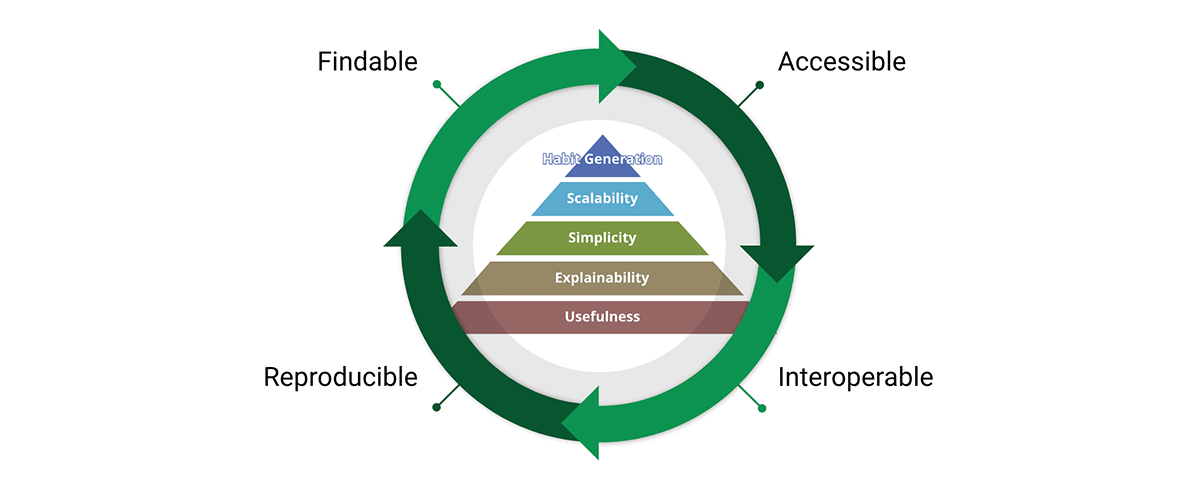{kind=link}
Por que os princípios FAIR são importantes para dados geoespaciais e produtos de dados geoespaciais? FAIR é transcendente aos dados geoespaciais, é na verdade transcendente aos dados, é um sistema simples, porém coerente, de princípios orientadores para um bom design - e esse bom design pode ser aplicado a qualquer coisa, incluindo dados geoespaciais e sistemas geoespaciais.
Sistemas de índice de grade
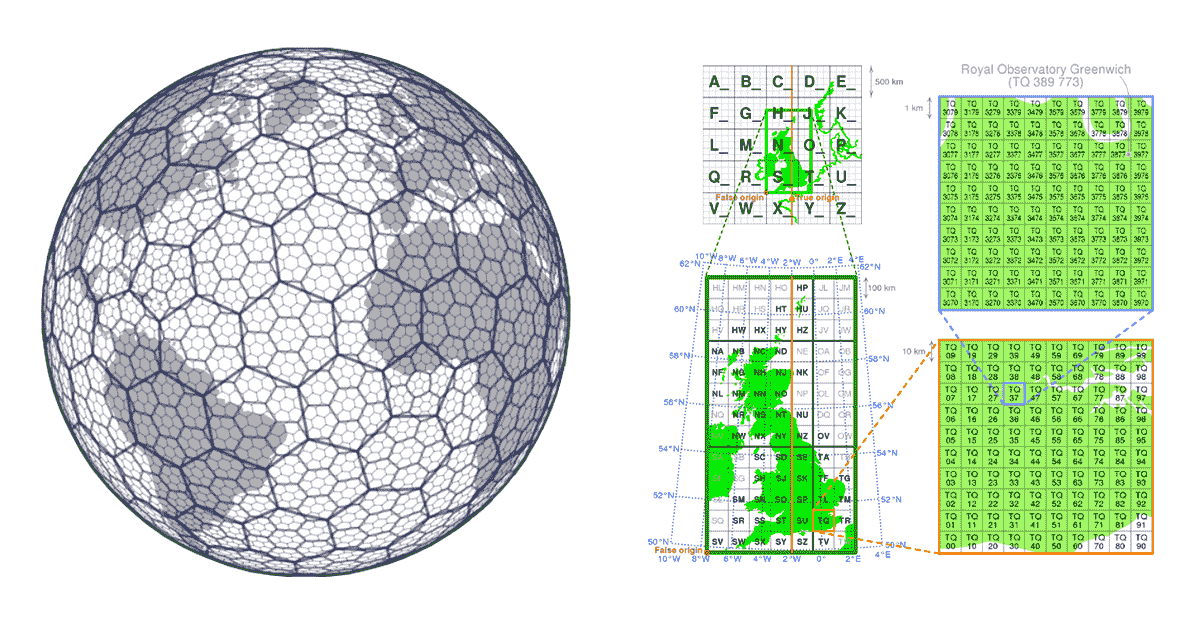
Em soluções GIS tradicionais, o desempenho de operações espaciais é geralmente alcançado pela construção de estruturas de árvore (KD trees, ball trees, Quad trees, etc.). O problema com abordagens de árvore é que elas eventualmente quebram o princípio de escalabilidade - quando os dados são muito grandes para serem processados a fim de construir a árvore e o cálculo necessário para construir a árvore é muito longo e frustra o propósito. Isso também afeta negativamente a acessibilidade dos dados; se não conseguirmos construir a árvore, não conseguiremos acessar todos os dados e, na prática, não conseguiremos reproduzir os resultados. Neste caso, os sistemas de índice de grade fornecem uma solução.
Sistemas de índice de grade são construídos desde o início com os aspectos de escalabilidade dos dados geoespaciais em mente. Em vez de construir árvores, eles definem uma série de grades que cobrem a área de interesse. No caso do H3 (pioneiro da Uber), a grade cobre a área da Terra; no caso de sistemas de índice de grade locais (por exemplo, British National Grid), eles podem cobrir apenas a área específica de interesse. Essas grades são compostas por células que possuem identificadores únicos. Existe uma relação matemática entre a localização e a célula na grade. Isso torna os sistemas de índice de grade muito escaláveis e paralelos em sua natureza.
{kind=link}
Outro aspecto importante dos sistemas de índice de grade é que eles são de código aberto, permitindo que os valores de índice sejam universalmente aproveitados por produtores e consumidores de dados. Os dados podem ser enriquecidos com as informações do índice de grade em qualquer etapa de sua jornada pela cadeia de suprimentos de dados. Isso torna os sistemas de índice de grade um exemplo de padrões de dados impulsionados pela comunidade. Padrões de dados impulsionados pela comunidade, por natureza, não exigem aplicação, o que adere totalmente ao aspecto de geração de hábitos da pirâmide de valor e aborda significativamente os princípios de interoperabilidade e acessibilidade do FAIR.
{kind=link}
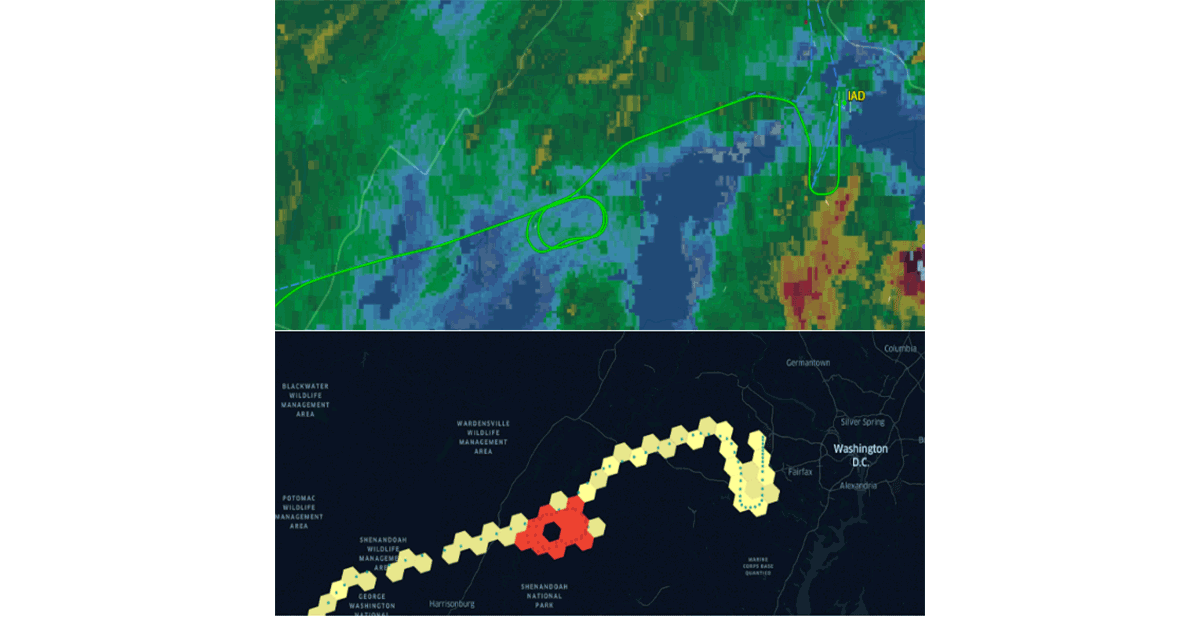
A Databricks anunciou recentemente suporte nativo para o sistema de índice de grade H3 seguindo a mesma proposta de valor. Adotar padrões comuns da indústria impulsionados pela comunidade é a única maneira de impulsionar adequadamente a geração de hábitos e a interoperabilidade. Para fortalecer essa declaração, organizações como CARTO, ESRI e Google têm promovido o uso de sistemas de índice de grade para design de sistemas GIS escaláveis. Além disso, o projeto Databricks Labs Mosaic suporta o British National Grid como o sistema de índice de grade padrão amplamente utilizado no governo do Reino Unido. Os sistemas de índice de grade são fundamentais para a escalabilidade do processamento de dados geoespaciais e para o projeto adequado de soluções para problemas complexos (por exemplo, figura 5 - padrões de espera de voo usando H3).
Diversidade de dados geoespaciais
Padrões de dados geoespaciais dedicam um esforço considerável à padronização de formatos de dados, e o formato, para esse assunto, é uma das considerações mais importantes quando se trata de interoperabilidade e reprodutibilidade. Além disso, se a leitura dos seus dados é complexa - como podemos falar em simplicidade? Infelizmente, os formatos de dados geoespaciais são tipicamente complexos, pois os dados podem ser produzidos em vários formatos, incluindo formatos de código aberto e proprietários. Considerando apenas dados vetoriais, podemos esperar que os dados cheguem em WKT, WKB, GeoJSON, web CSV, CSV, Shape File, GeoPackage e muitos outros. Por outro lado, se considerarmos dados raster, podemos esperar que os dados cheguem em qualquer número de formatos, como GeoTiff, netCDF, GRIB ou GeoDatabase; para uma lista abrangente de formatos, consulte este blog.
O domínio de dados geoespaciais é muito diversificado e cresceu organicamente ao longo dos anos em torno dos casos de uso que abordava. A unificação de um ecossistema tão diverso é um desafio imenso. Um esforço recente do Open Geospatial Consortium (OGC) para padronizar para Apache Parquet e sua especificação de esquema geoespacial GeoParquet é um passo na direção certa. A simplicidade é um dos aspectos chave no design de um bom produto escalável e robusto - a unificação leva à simplicidade e aborda uma das principais fontes de atrito no ecossistema - a ingestão de dados. A padronização para GeoParquet traz muito valor que aborda todos os aspectos dos dados FAIR e da pirâmide de valor.
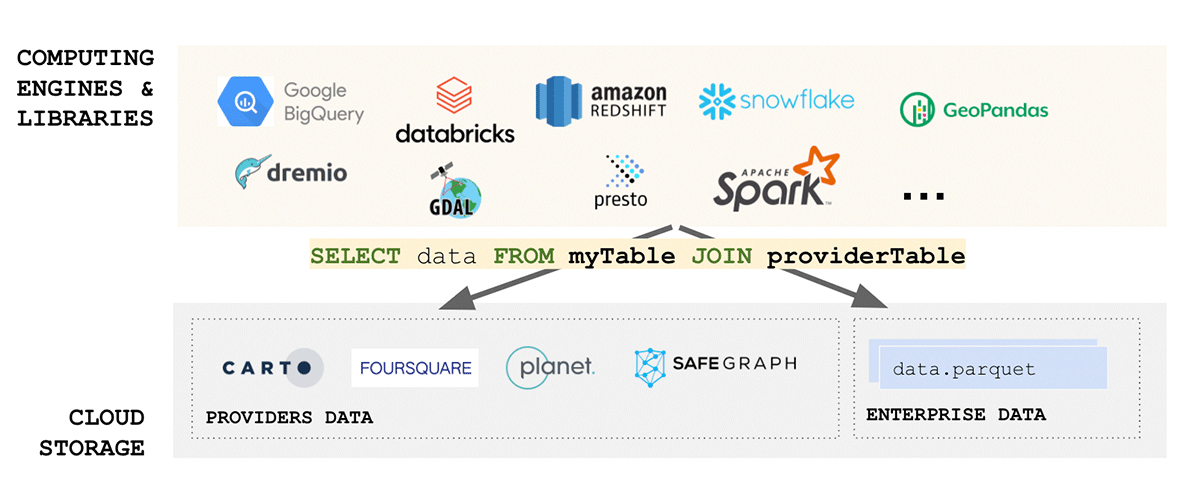
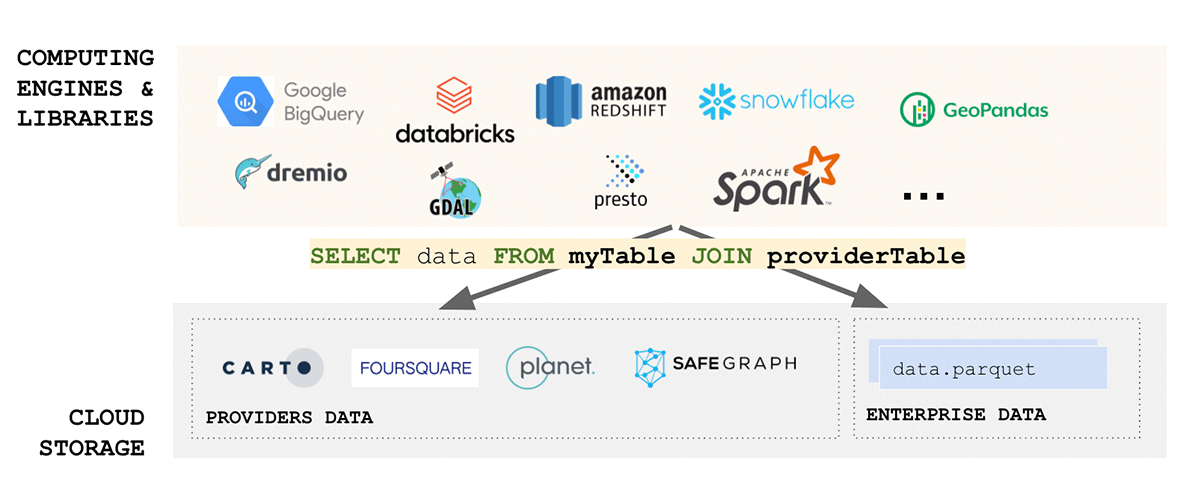{kind=link}
Por que introduzir outro formato em um ecossistema já complexo? GeoParquet não é um novo formato - é uma especificação de esquema para o formato Apache Parquet, que já é amplamente adotado e utilizado pela indústria e pela comunidade. O Parquet como formato base suporta colunas binárias e permite o armazenamento de carga útil de dados arbitrária, ao mesmo tempo que o formato suporta colunas de dados estruturadas que podem armazenar metadados juntamente com a carga útil de dados. Isso o torna uma escolha que promove a interoperabilidade e a reprodutibilidade. Finalmente, o Delta Lake é um formato construído sobre o parquet e traz propriedades ACID para a mesa. As propriedades ACID de um formato são cruciais para a reprodutibilidade e para resultados confiáveis. Além disso, o Delta é o formato usado pela solução escalável de compartilhamento de dados Delta Sharing. O Delta Sharing permite o compartilhamento de dados em escala empresarial entre qualquer nuvem pública usando Databricks (opções DIY para nuvem privada estão disponíveis usando blocos de construção de código aberto). O Delta Sharing abstrai completamente a necessidade de APIs REST personalizadas para expor dados a terceiros. Qualquer ativo de dados armazenado em Delta (usando o esquema GeoParquet) torna-se automaticamente um produto de dados que pode ser exposto a partes externas de forma controlada e governada. O Delta Sharing foi construído do zero com melhores práticas de segurança em mente.
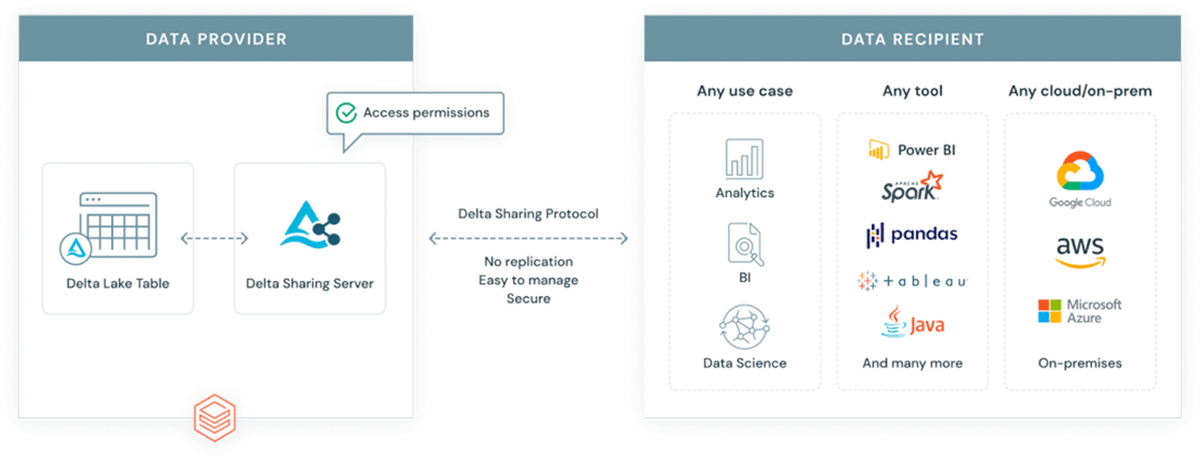
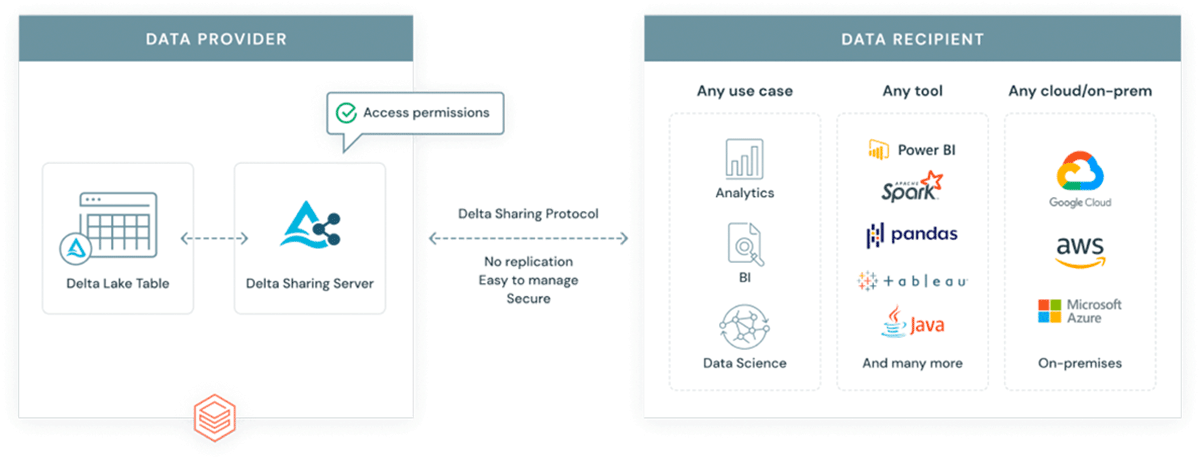{kind=link}
Economia circular de dados
Emprestando conceitos do domínio da sustentabilidade, podemos definir uma economia circular de dados como um sistema em que os dados são coletados, compartilhados e usados de forma a maximizar seu valor, minimizando desperdícios e impactos negativos, como tempo de computação desnecessário, insights não confiáveis ou ações tendenciosas baseadas em poluentes de dados. A reutilização é o conceito chave nessa consideração, como podemos minimizar o "reinventar a roda". Existem inúmeros ativos de dados por aí que representam a mesma área, os mesmos conceitos com apenas pequenas alterações para melhor se adequar a um caso de uso específico. Isso se deve a otimizações reais ou ao fato de ter sido mais fácil criar uma nova cópia dos ativos do que reutilizar os existentes? Ou foi muito difícil encontrar os ativos de dados existentes, ou talvez tenha sido muito complexo definir padrões de acesso a dados.
A duplicação de ativos de dados tem muitos aspectos negativos tanto nas considerações FAIR quanto nas considerações da pirâmide de valor dos dados - ter muitos ativos de dados semelhantes (mas diferentes) e dispersos que representam a mesma área e os mesmos conceitos pode deteriorar as considerações de simplicidade do domínio de dados - torna-se difícil identificar o ativo de dados em que realmente podemos confiar. Também pode ter implicações muito negativas em relação à geração de hábitos, muitas comunidades de nicho surgirão que se padronizarão ignorando as melhores práticas do ecossistema mais amplo, ou pior ainda, não se padronizarão.
Em uma economia circular de dados, os dados são tratados como um recurso valioso que pode ser usado para criar novos produtos e serviços, bem como melhorar os existentes. Essa abordagem incentiva a reutilização e a reciclagem de dados, em vez de tratá-los como uma commodity descartável. Mais uma vez, estamos usando a analogia da sustentabilidade em sentido literal - argumentamos que essa é a maneira correta de abordar o problema. Poluentes de dados são um desafio real para as organizações, tanto interna quanto externamente. Um artigo do The Guardian afirma que menos de 1% dos dados coletados são realmente analisados. Há muita duplicação de dados, a maioria dos dados é de difícil acesso e derivar valor real é muito complicado. A economia circular de dados promove melhores práticas e reutilização de ativos de dados existentes, permitindo uma interpretação e insights mais consistentes em todo o ecossistema de dados.
{kind=link}
A interoperabilidade é um componente chave dos princípios de dados FAIR, e da interoperabilidade surge a questão da circularidade. Como podemos projetar um ecossistema que maximize a utilização e a reutilização de dados? Mais uma vez, FAIR, juntamente com a pirâmide de valor, tem as respostas. A encontrabilidade dos dados é fundamental para a reutilização dos dados e para a solução da poluição de dados. Com ativos de dados que podem ser descobertos facilmente, podemos evitar a recriação dos mesmos ativos de dados em vários lugares com apenas pequenas alterações, em vez disso, obtemos um ecossistema de dados coerente com dados que podem ser facilmente combinados e reutilizados. A Databricks anunciou recentemente o Databricks Marketplace. A ideia por trás do marketplace está alinhada com a definição original de produto de dados de DJ Patel. O marketplace suportará o compartilhamento de conjuntos de dados, notebooks, dashboards e modelos de machine learning. O bloco de construção crítico para tal marketplace é o conceito de Delta Sharing - o canal escalável, flexível e robusto para compartilhar quaisquer dados - incluindo dados geoespaciais.
Projetar produtos de dados escaláveis que viverão no Marketplace é crucial. Para maximizar o valor agregado de cada produto de dados, deve-se considerar fortemente os princípios FAIR e a pirâmide de valor do produto. Sem esses princípios orientadores, apenas aumentaremos os problemas que já estão presentes nos sistemas atuais. Cada produto de dados deve resolver um problema único e resolvê-lo de maneira simples, reprodutível e robusta.
Você pode ler mais sobre como a Databricks Lakehouse Platform pode ajudá-lo a acelerar o tempo de valor de seus produtos de dados no eBook - Uma Nova Abordagem para Compartilhamento de Dados.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.