Avançando o Lakehouse com o Apache Iceberg v3 no Databricks
O Databricks é compatível com o Apache Iceberg v3, oferecendo aos clientes uma camada de dados unificada, de alto desempenho e interoperável
por Ryan Blue, Daniel Weeks, Jason Reid, Fred Liu e Aniruth Narayanan
• A Databricks oferece suporte ao Apache Iceberg v3, para que os clientes possam executar cargas de trabalho interoperáveis e governadas em uma única cópia de dados
• Com o Iceberg v3, vetores de exclusão, linhagem em nível de linha e o tipo de dados Variant agora estão disponíveis em todas as tabelas gerenciadas
• Com esses recursos, a Databricks leva a Data Intelligence Platform para todos os formatos para o melhor desempenho
O Databricks oferece suporte ao Apache Iceberg v3 na Plataforma de Intelig�ência de Dados, oferecendo aos clientes uma camada de dados unificada e aberta com o melhor desempenho da categoria, interoperabilidade e governança.
Com este lançamento, os clientes do Databricks que executam workloads do Iceberg agora podem aproveitar os recursos da v3, incluindo vetores de exclusão, linhagem em nível de linha e o tipo de dados Variant. Esses recursos permitem que as equipes façam a execução de workloads modernos de forma eficiente e consistente em todas as plataformas. Esses recursos também funcionam perfeitamente em tabelas Delta e Iceberg, permitindo a interoperabilidade sem reescrever os dados.

Este lançamento reforça o compromisso da Databricks com os padrões abertos e ajuda os clientes a construir sobre a base de lakehouse do Delta Lake, Apache Iceberg, Apache Parquet e Apache Spark, tudo com governança total e flexibilidade.
Neste blog, exploraremos:
- Uma camada de dados unificada com o Iceberg v3
- Workloads eficientes do Iceberg v3 no Databricks
- Impulsionando os formatos de tabela abertos
Uma camada de dados unificada com o Iceberg v3
O Delta Lake e o Apache Iceberg tornaram-se a base do lakehouse moderno, cada um com recursos robustos para confiabilidade, governança e gestão de dados escalável. Ambos usam arquivos de metadados para rastrear arquivos de dados Parquet e exclusões em nível de linha. No entanto, pequenas diferenças entre os formatos nesses arquivos de dados e de exclusão geralmente forçavam as organizações a escolher um formato e seus recursos, geralmente com base em quais plataformas de dados elas usavam. Essa escolha era muitas vezes irreversível, já que reescrever petabytes de dados é impraticável.
O Iceberg v3 preenche essa lacuna. Ele introduz recursos que se alinham estreitamente com o Delta e o ecossistema aberto mais amplo, como Parquet e Spark, permitindo que as equipes usem uma única cópia dos dados com comportamento e desempenho consistentes em todos os formatos.
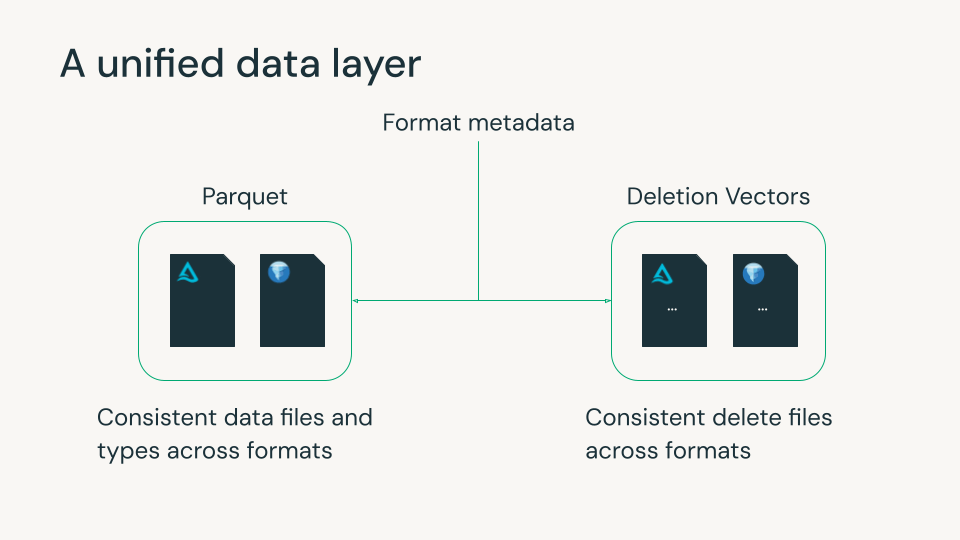
A Databricks há muito tempo acredita que o futuro do lakehouse é a opcionalidade sem fragmentação. Nossas contribuições para o Iceberg v3 refletem esse compromisso: ajudar a unificar os comportamentos essenciais da tabela para que os clientes possam usar os engines e as ferramentas que preferirem, enquanto governam tudo de forma consistente com o Unity Catalog.
Workloads eficientes do Iceberg v3 no Databricks
Com o Iceberg v3, o Databricks traz recursos da Data Intelligence Platform para todas as tabelas gerenciadas do Unity Catalog.
Vetores de exclusão para atualizações mais rápidas
Os vetores de exclusão permitem excluir ou atualizar linhas sem reescrever os arquivos Parquet. Em vez disso, as exclusões são armazenadas como arquivos separados e merge durante as leituras. A maioria dos workloads de engenharia de dados modifica apenas algumas linhas por vez, tornando este um recurso essencial para gravações eficientes.

Agora você pode aproveitar a melhor relação preço-desempenho de ETL do Databricks para a execução de workloads do Iceberg usando vetores de exclusão. Em comparação com as instruções MERGE regulares, os vetores de exclusão podem acelerar as atualizações em até 10x. Os engines do Iceberg podem ler e gravar em tabelas gerenciadas do Iceberg usando as APIs REST do Catálogo do Iceberg do Unity Catalog. Conforme observa a Geodis:
“Agora que os Vetores de Exclusão chegaram ao Iceberg, podemos centralizar nosso patrimônio de dados do Iceberg no Unity Catalog, aproveitando o engine de nossa escolha e mantendo o melhor desempenho da categoria.” —Delio Amato, Arquiteto-Chefe e Diretor de Dados, Geodis
Linhagem de linha para concorrência em nível de linha
A linhagem de linha fornece a cada linha um ID exclusivo, facilitando o rastreamento de alterações ao longo do tempo. A linhagem de linha é necessária para todas as tabelas Iceberg v3.
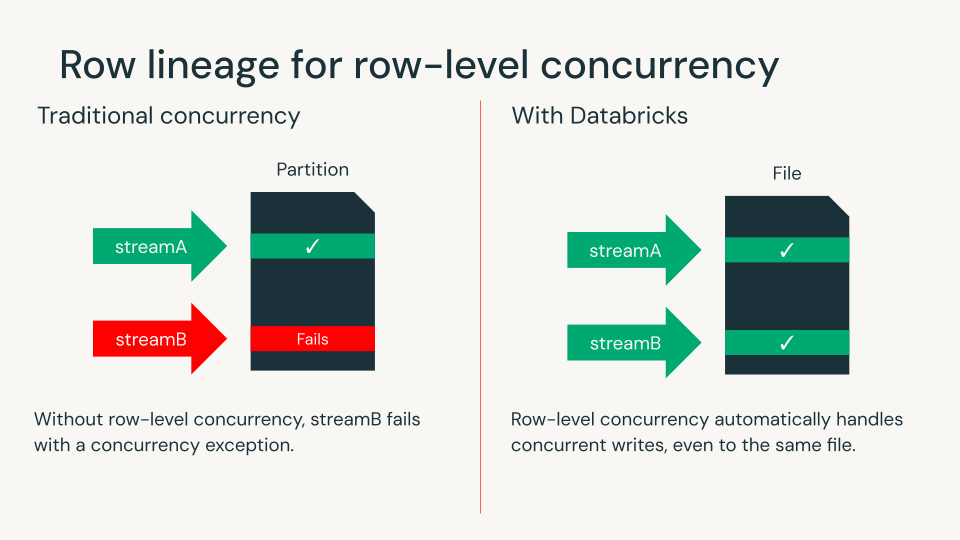
Com vetores de exclusão e linhagem de linha, os clientes do Databricks agora podem usar a concorrência em nível de linha para detectar conflitos de gravação no nível da linha. Isso elimina a necessidade de projetar disposições de dados complexas ou coordenar workloads para garantir a concorrência. O Databricks continua sendo o único engine de lakehouse que traz esse recurso para formatos de tabela abertos.
Tipo de dados variante para ingestão flexível
Os dados modernos raramente se encaixam perfeitamente em linhas e colunas. Logs, eventos e dados de aplicativos geralmente chegam no formato JSON. O tipo de dados Variant armazena dados semiestruturados diretamente, oferecendo excelente desempenho sem a necessidade de esquemas complexos ou pipelines frágeis.

Usando o tipo de dados Variant no Databricks, você pode inserir dados brutos diretamente nas tabelas do seu lakehouse usando funções de ingestão. Essas funções oferecem suporte ao carregamento de dados JSON, CSV e XML. O Variant oferece suporte a shredding, que extrai campos comuns em blocos separados para fornecer um desempenho semelhante ao colunar. Isso acelera as query para pipeline de BI de baixa latência, dashboards e alertas.
O Variant funciona tanto no Delta quanto no Iceberg. Equipes que usam engines diferentes podem query a mesma tabela, incluindo as colunas Variant, sem duplicação de dados:
“Já se foram os dias dos dados escalares simples, especialmente para casos de uso que exigem logs de segurança e de aplicativos. O Unity Catalog e o Iceberg v3 liberam o poder dos dados semiestruturados por meio do Variant. Isso permite a interoperabilidade e a coleta de logs econômica em escala de petabytes.” —Russell Leighton, Arquiteto-Chefe, Panther
Impulsionando os formatos de tabela abertos
O Iceberg v3 marca um passo importante para a unificação dos formatos de tabela abertos em toda a camada de dados. A próxima fronteira é melhorar a forma como os formatos gerenciam e sincronizam metadados em escala. Esforços da comunidade, como a árvore de metadados adaptável introduzida pela primeira vez na Iceberg Summit, podem reduzir a sobrecarga de metadados e acelerar as operações de tabela em escala.
À medida que essas ideias amadurecem, elas aproximam as comunidades Delta e Iceberg, com objetivos compartilhados em torno de commits mais rápidos, gerenciamento eficiente de metadados e operações escaláveis de várias tabelas. O Databricks continua a contribuir para essa evolução, permitindo que os clientes obtenham o melhor desempenho e interoperabilidade sem serem restringidos por diferenças no nível do formato.
Experimente o Iceberg v3 hoje com o Databricks
Esses recursos do Iceberg v3 já estão disponíveis no Databricks, fornecendo aos clientes a implementação do padrão mais preparada para o futuro, com o respaldo da governança do Unity Catalog. Com o Iceberg v3, os clientes do Databricks podem aproveitar os melhores recursos das tabelas Delta e Iceberg. Criar uma tabela gerenciada do Unity Catalog com o Iceberg v3 é fácil:
Começar com Unity Catalog e Iceberg v3 e join-se a nós nos próximos eventos do Open Lakehouse + AI para saber mais sobre nosso trabalho em todo o ecossistema aberto.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.