Apresentando o Variant: um novo padrão aberto para dados semiestruturados no Apache Parquet™, Delta Lake e Apache Iceberg™
- O Variant, o tipo de dados nativo para dados semiestruturados, agora foi ratificado na comunidade Apache Parquet™ com suporte em Delta Lake, Apache Iceberg™ e Apache Spark™
- O shredding, uma técnica para colunarizar campos que ocorrem com frequência em dados Variant, melhora o desempenho de leitura em 8x em comparação com o uso do Variant regular e em 30x em comparação com o uso de string
- O shredding de Variant tem suporte no Databricks com DBR 17.2+ (DBSQL 2025.30+), com funções para ingerir facilmente de fontes JSON, CSV e XML
Dados semiestruturados estão por toda parte em IA, logs de aplicativos e telemetria. Esses dados são úteis, mas a alteração de esquemas dificulta o armazenamento e a consulta. Durante anos, a prática padrão foi armazenar esses dados como strings. As strings eram flexíveis, mas tinham baixo desempenho de consulta, já que o mecanismo precisava analisar e pesquisar em toda a string.
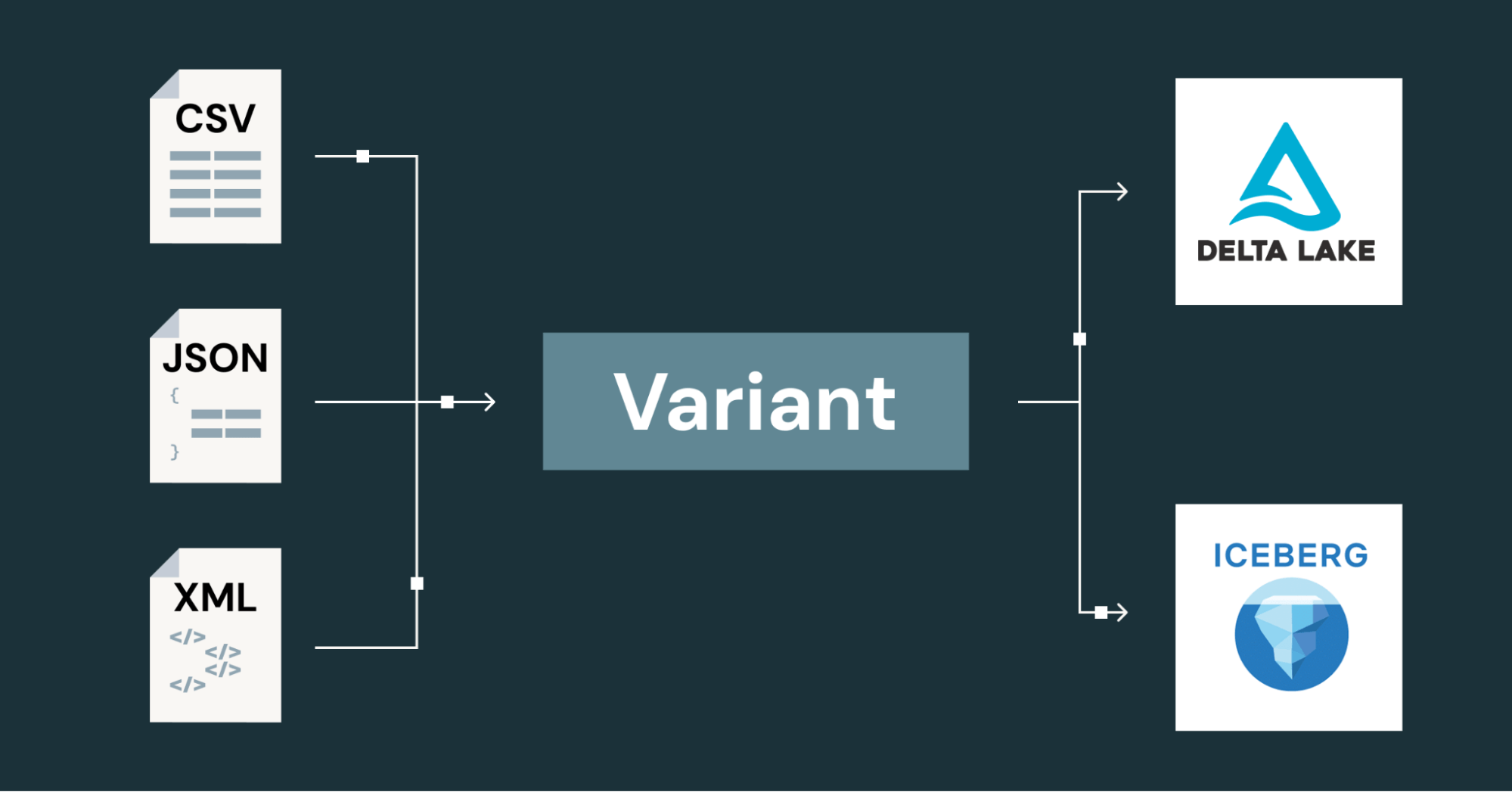
O tipo de dado Variant, agora ratificado no Apache Parquet™, adota uma abordagem diferente. Ele armazena os dados em um formato binário compacto que é flexível e performático para consultas. Essa abordagem não está vinculada a um único mecanismo ou formato: o Variant é o padrão aberto para dados semiestruturados em todo o lakehouse, com suporte em Apache Spark™, Delta Lake e Apache Iceberg™.
Neste post, abordaremos:
- Investindo em padrões abertos do Variant
- Como o Variant e a fragmentação funcionam
- Desempenho rápido em dados semiestruturados
A Databricks está liderando os esforços do Variant em código aberto.
No ano passado, colaboramos com a comunidade de código aberto para apresentar o Variant ao Apache Spark™ e Delta Lake. Esse novo tipo de dados oferece flexibilidade e performance em comparação com o armazenamento de dados semiestruturados como strings (que têm baixa performance) ou structs (que não são flexíveis).
O lançamento do Variant atraiu rapidamente o interesse de outros grandes projetos de código aberto, incluindo o Apache Iceberg™ e o Apache Arrow™. Para unificar o ecossistema, propusemos levar o Variant para todos os mecanismos e formatos, incorporando o tipo diretamente no Parquet e movendo a implementação do Spark para o projeto de código aberto Parquet-java, contribuindo com mais de 9.600 linhas de código. Isso permite que todos os formatos de tabela abertos aproveitem facilmente o tipo de dados Variant.
Agora que o Variant foi aprovado na comunidade Parquet, todo o ecossistema de lakehouse tem um tipo de dado padrão e aberto para dados semiestruturados. O Variant já tem suporte em formatos de tabela abertos: o Delta incluiu suporte ao Variant no último ano e, em maio passado, o Iceberg aprovou a v3, que inclui suporte ao Variant. Consequentemente, os usuários que utilizam Delta ou Iceberg agora podem se beneficiar da flexibilidade e do desempenho do Variant.
Os artefatos da Variante Parquet incluem:
- Especificação de Codificação Binária do Variant
- Especificação do Variant Shredding (uma técnica para armazenar dados Variant com mais eficiência)
- Versão de Lançamento 2.12.0 do Parquet com a implementação Parquet Java 1.16.0
Os protocolos do Delta e do Iceberg para suporte ao Variant são:
Agradecemos a todos os indivíduos e organizações envolvidos por suas contribuições em várias comunidades de código aberto, incluindo Apache Parquet™, Apache Spark™, Apache Iceberg™, Delta Lake e Apache Arrow™.
Como o Variant e a fragmentação funcionam
O Variant usa um formato de codificação binária para fornecer uma interface flexível para o armazenamento de dados. O Variant também tem um esquema de shredding, uma técnica para armazenar o Variant de forma mais eficiente para melhorar o desempenho.
Formato de codificação binária
O tipo de dados Variant aproveita um esquema de codificação binária eficiente para representar dados semiestruturados. Em vez de armazenar os dados como um valor de texto simples (como JSON), os dados Variant codificam os valores e a estrutura em um formato binário que prioriza a navegação eficiente.
Navegar em uma string JSON exige a leitura e o processamento de todo o objeto JSON para encontrar o campo relevante. Com a codificação binária Variant, a estrutura dos dados é codificada usando deslocamentos para outros locais dentro do valor Variant. Com esses deslocamentos, navegar pela estrutura Variant não exige a leitura ou o processamento de todo o valor. Essa navegação baseada em deslocamentos melhora muito o desempenho do processamento de dados semiestruturados.
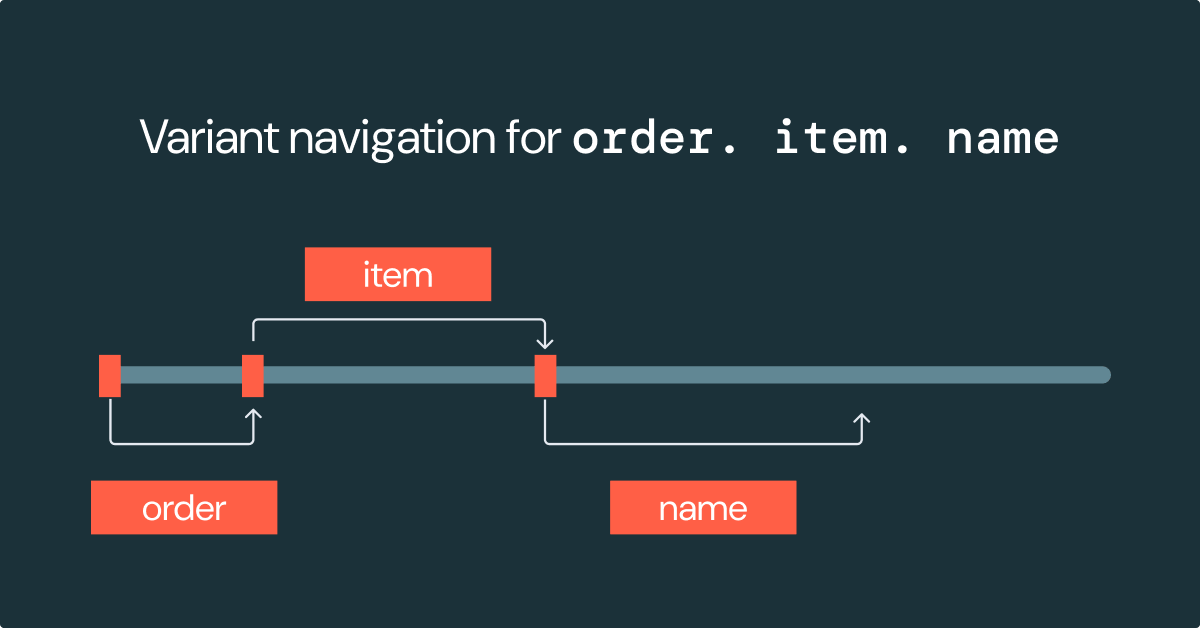
Este exemplo demonstra que navegar até o caminho order.item.name requer examinar apenas algumas partes do valor Variant usando os offsets. Isso reduz a quantidade de dados a serem processados/analisados e leva a um desempenho mais rápido.
Desmembramento
O desmembramento extrai automaticamente campos comuns dos valores Variant. Esses campos são armazenados como chunks separados e tipados na mesma coluna. Sem o shredding, todo o valor do Variant é armazenado como um único "blob binário" no arquivo.
Há várias vantagens de desempenho para o shredding de Variants:
- I/O otimizado: quando os campos são armazenados separadamente, apenas os campos exigidos pela consulta precisam ser buscados. Isso significa que, se a consulta exigir apenas uma pequena fração dos campos do Variant, apenas uma pequena fração do I/O será necessária.
- Salto de dados: quando campos que passaram por shredding são armazenados como partes Parquet separadas, os mecanismos podem usar todas as otimizações do Parquet para um salto eficiente de grupos de linhas e páginas de colunas.
- Compressão: como os campos desmembrados são colunares, os dados podem ser compactados com mais eficiência, reduzindo assim o tamanho do armazenamento.
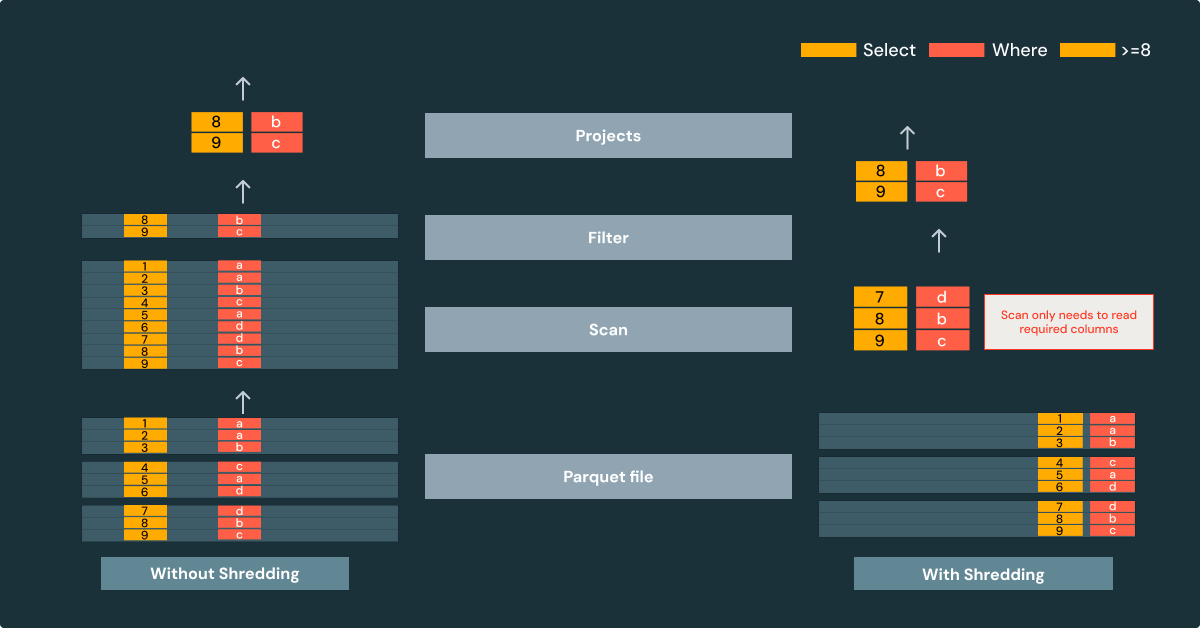
Este exemplo demonstra que, com o shredding, a varredura só precisa ler as colunas exigidas pela consulta. A varredura usa as estatísticas de coluna do Parquet, então os grupos de linhas irrelevantes podem ser completamente ignorados. A leitura de arquivos que passaram por shredding melhora o desempenho, pois evita trabalho desnecessário.
Desempenho rápido em dados semiestruturados
O formato binário do Variant e a técnica de shredding permitem melhorias significativas de desempenho em comparação com o armazenamento de dados semiestruturados como strings JSON. Realizamos benchmarks de desempenho usando dados semiestruturados baseados no TPC-DS para comparar as representações Variant e de string.

Em comparação com o armazenamento de JSON como string, o Variant tem um desempenho de leitura 8x mais rápido. Com o shredding, as gravações do Variant são de 20% a 50% mais lentas, mas as leituras são 30x mais rápidas, demonstrando seu desempenho e eficiência.
Experimente o Variant hoje
Com suporte nativo para Parquet, Delta e Iceberg, o tipo de dados Variant é o tipo de dados aberto e padronizado para dados semiestruturados. Ao eliminar a necessidade de ETLs complexos e análises frágeis, o Variant capacita os usuários a analisar dados de forma rápida, fácil e confiável.
Criar uma tabela com uma coluna Variant é fácil:
Para carregar dados Variant, o Databricks oferece suporte a funções de ingestão do Variant de fontes JSON, XML e CSV:
O shredding do Variant tem suporte no DBR 17.2+ (DBSQL 2025.30+) com suporte em tabelas Delta e Iceberg. Isso melhora o desempenho da consulta sem alterações no código:
Fique ligado em nosso post de acompanhamento sobre o Variant, no qual apresentaremos exemplos práticos e compartilharemos histórias de clientes.
O foco em desempenho, simplicidade e valor é a base do Databricks SQL, onde o melhor data warehouse é um lakehouse. Para saber mais sobre o Databricks SQL, acesse nosso site, leia a documentação ou confira o tour pelo produto. O Databricks SQL é o data warehouse de alto desempenho, baixo custo e sem servidor — experimente gratuitamente hoje mesmo.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.