Raciocínio Agente na Prática: Entendendo Dados Estruturados e Não Estruturados
Dados empresariais raramente são úteis isoladamente. Responder a perguntas como "Quais de nossos produtos tiveram vendas em declínio nos últimos três meses e quais problemas potencialmente relacionados são mencionados em avaliações de clientes em vários sites de vendedores?" exige raciocínio em uma mistura de fontes de dados estruturadas e não estruturadas, incluindo data lakes, dados de avaliações e sistemas de gerenciamento de informações de produtos. Neste blog, demonstramos como o Databricks Agent Bricks Supervisor Agent (SA) pode ajudar nessas tarefas complexas e realistas por meio de raciocínio multi-etapas fundamentado em um híbrido de dados estruturados e não estruturados.
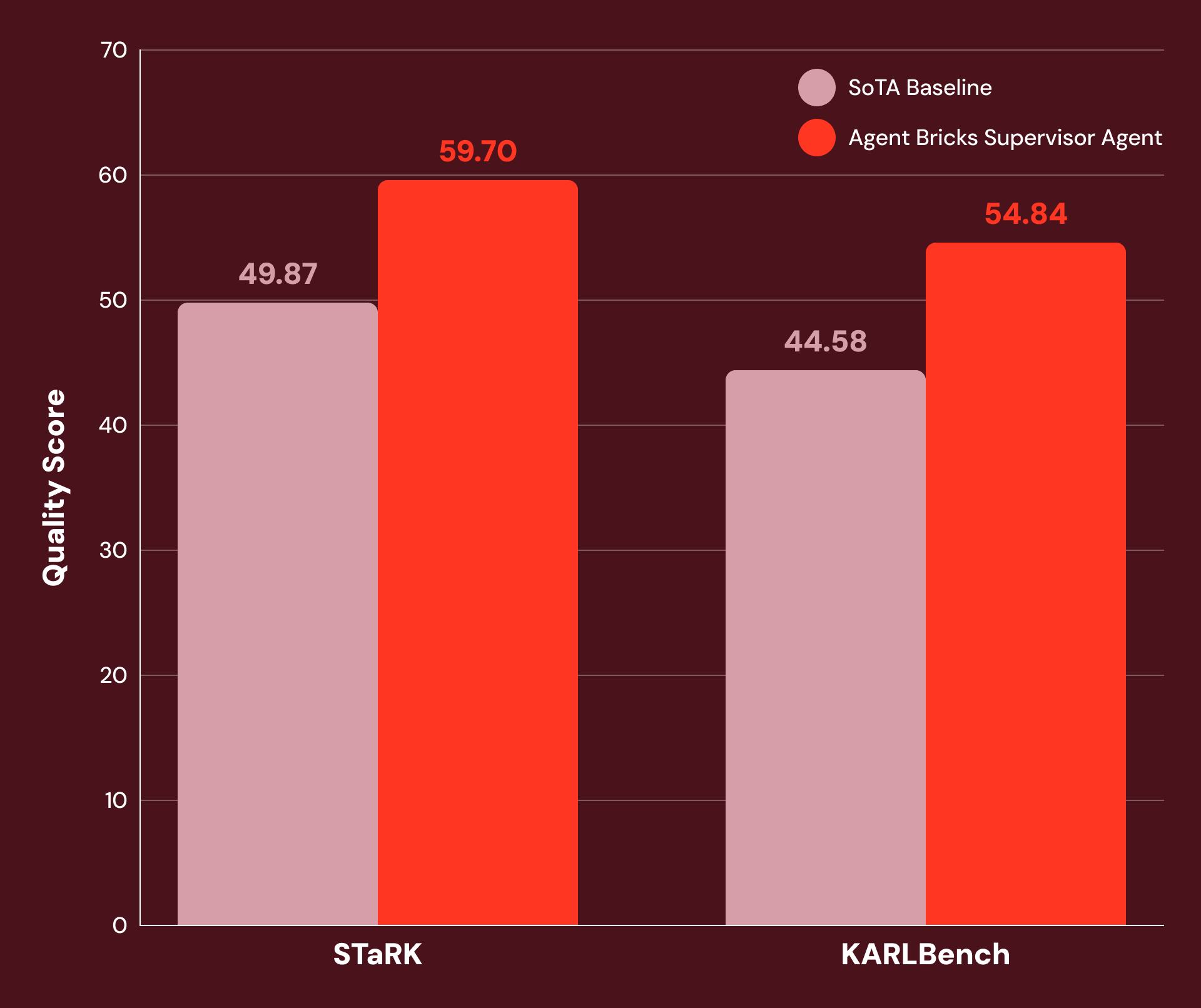
Com instruções ajustadas e configuração cuidadosa de ferramentas, descobrimos que o SA é altamente performático em uma ampla gama de tarefas empresariais intensivas em conhecimento. A Figura 1 mostra que o SA atinge 20% ou mais de melhoria sobre as linhas de base SoTA em:
- STaRK: um conjunto de três tarefas de recuperação semiestruturada publicadas por pesquisadores de Stanford.
- KARLBench: um conjunto de benchmarks para raciocínio fundamentado complexo recentemente publicado pela Databricks.
O Supervisor Agent demonstra ganhos significativos em uma ampla gama de tarefas economicamente valiosas: desde recuperação acadêmica (+21% no STaRK-MAG) até raciocínio biomédico (+38% no STaRK Prime) e análise financeira (+23% no FinanceBench).
Configuração do Agente
O Agent Bricks Supervisor Agent é um construtor de agentes declarativo que orquestra agentes e ferramentas. Ele é construído sobre o aroll — um framework interno de agentes para construir, avaliar e implantar fluxos de trabalho LLM multi-etapas em escala.1 O aroll e o SA foram projetados especificamente para os casos de uso avançados de agentes que nossos clientes encontram frequentemente.
O aroll permite adicionar novas ferramentas e instruções personalizadas por meio de simples alterações de configuração, pode lidar com milhares de conversas simultâneas e execuções paralelas de ferramentas, e incorpora técnicas avançadas de orquestração de agentes e gerenciamento de contexto para refinar consultas e recuperar de respostas parciais. Tudo isso é difícil de alcançar com sistemas SoTA de turno único hoje.
Como o SA é construído sobre essa arquitetura flexível, sua qualidade pode ser continuamente melhorada por meio de simples curadoria do usuário, como ajustar instruções de nível superior ou refinar descrições de agentes, sem a necessidade de escrever nenhum código personalizado.
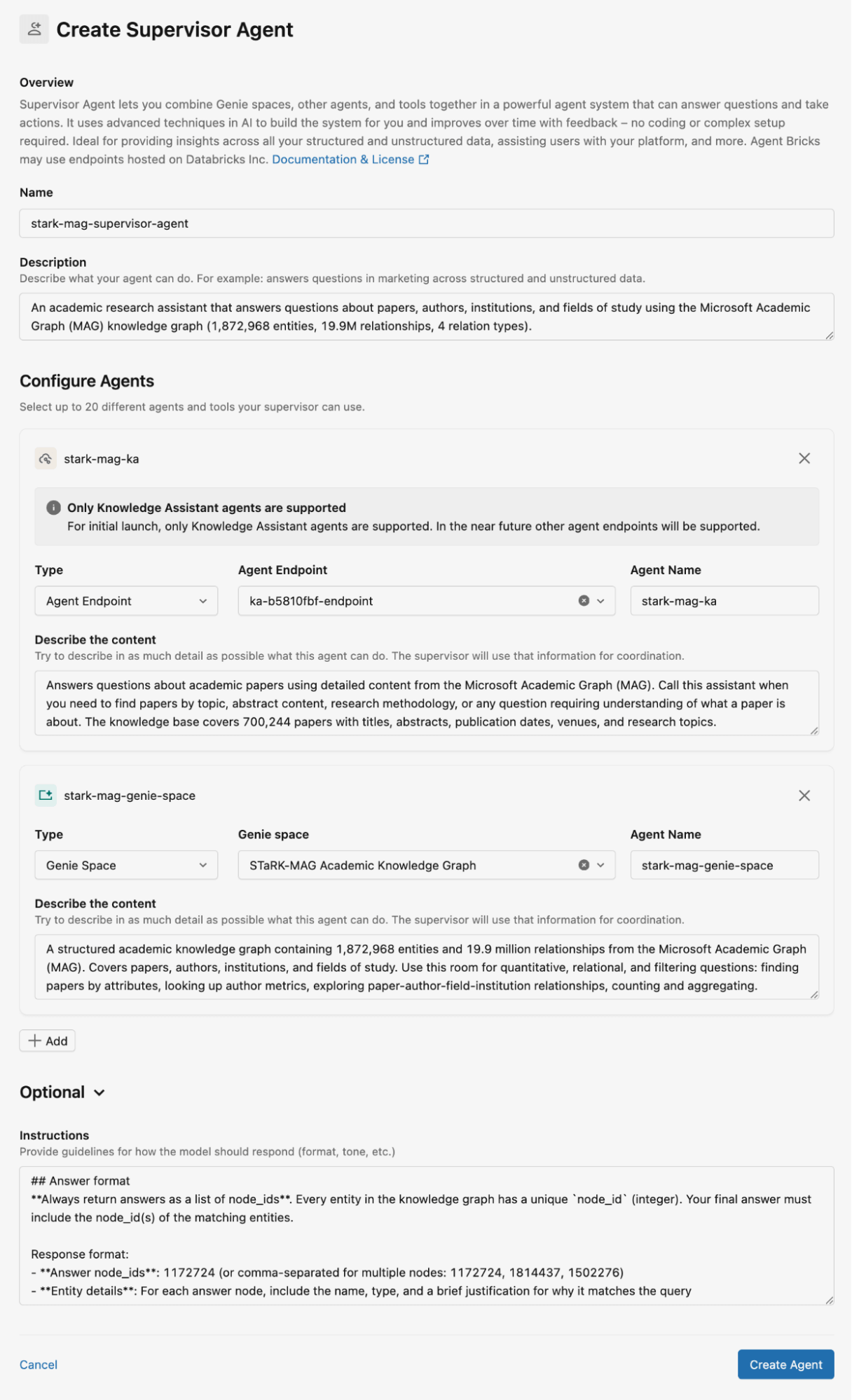
A Figura 2 mostra como configuramos o Supervisor Agent para o dataset STaRK-MAG. Neste blog, usamos Genie spaces para armazenar as bases de conhecimento relacionais e Knowledge Assistants para armazenar documentos não estruturados para recuperação. Fornecemos descrições detalhadas para todos os Knowledge Assistants e Genie spaces, bem como instruções para as respostas do agente.
Raciocínio Híbrido: Estruturado Encontra Não Estruturado
Para avaliar o raciocínio fundamentado com base em um híbrido de dados estruturados e não estruturados, usamos o benchmark STaRK, que inclui três domínios:
- Amazon: atributos de produtos (estruturados) e avaliações (não estruturadas)
- MAG: redes de citação (estruturadas) e artigos acadêmicos (não estruturados)
- Prime: entidades biomédicas (estruturadas) e literatura (não estruturada)
Por exemplo, "Encontre-me um artigo escrito por um coautor com 115 artigos e que seja sobre o átomo de Rydberg" exige que o sistema combine filtragem estruturada ("coautor com 115 artigos") com compreensão não estruturada ("sobre o átomo de Rydberg"). As melhores linhas de base publicadas usam busca por similaridade de vetores com um reranker baseado em LLM — uma abordagem forte de turno único, mas que não consegue decompor consultas entre tipos de dados. Para garantir uma comparação justa, reexecutamos essa linha de base com o modelo fundamental SoTA atual, fornecendo uma linha de base substancialmente mais forte.
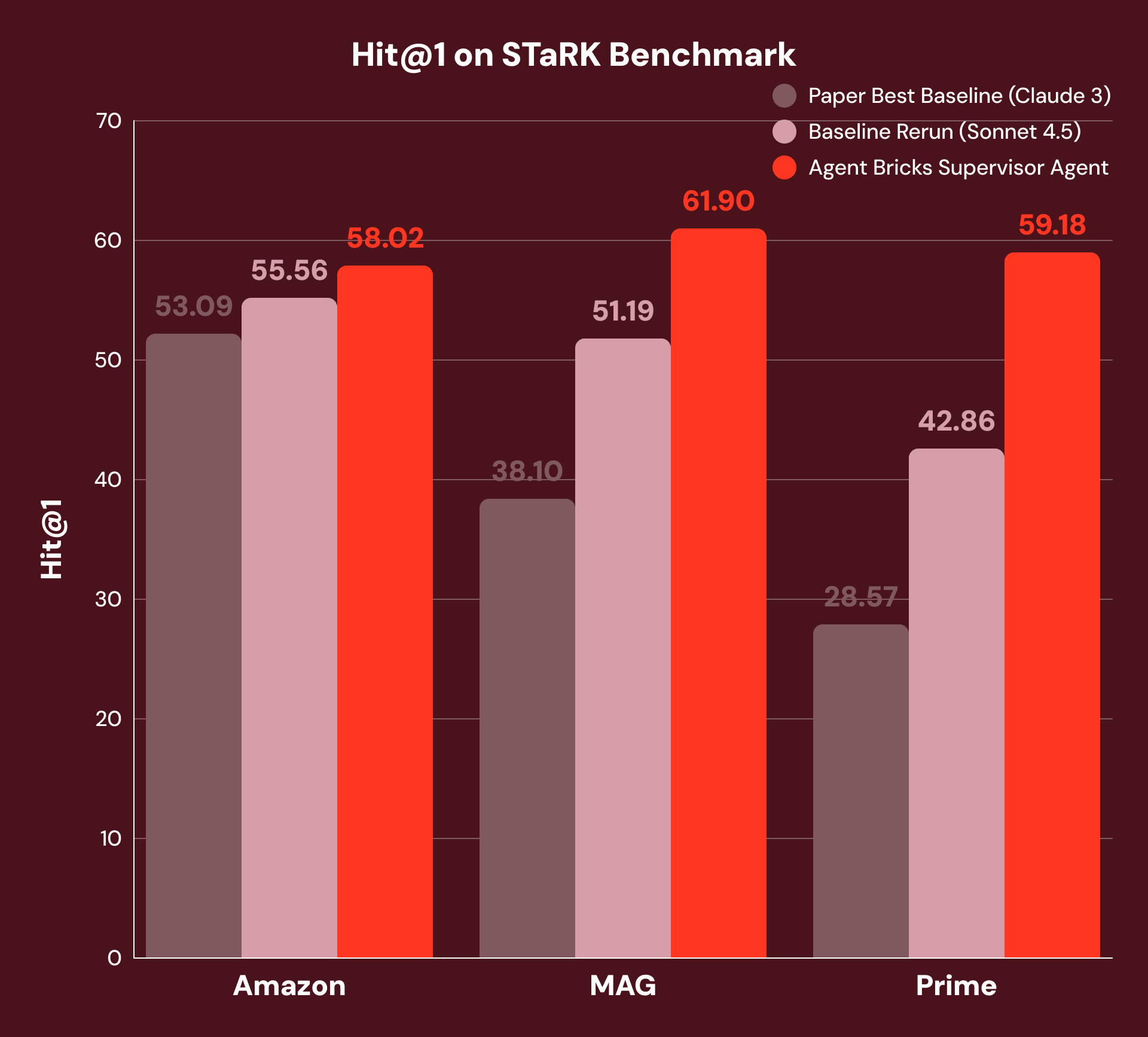
Com nossa abordagem, o SA decompõe cada pergunta, roteia sub-perguntas para a ferramenta apropriada e sintetiza resultados em várias etapas de raciocínio. Como a Figura 3 mostra, isso alcança +4% de Hit@1 na Amazon, +21% no MAG e +38% no Prime sobre as melhores linhas de base originais e nossas linhas de base reexecutadas com o modelo fundamental SoTA atual. Vemos as melhores melhorias no MAG e Prime, onde a resposta requer a integração mais estreita de dados estruturados e não estruturados.
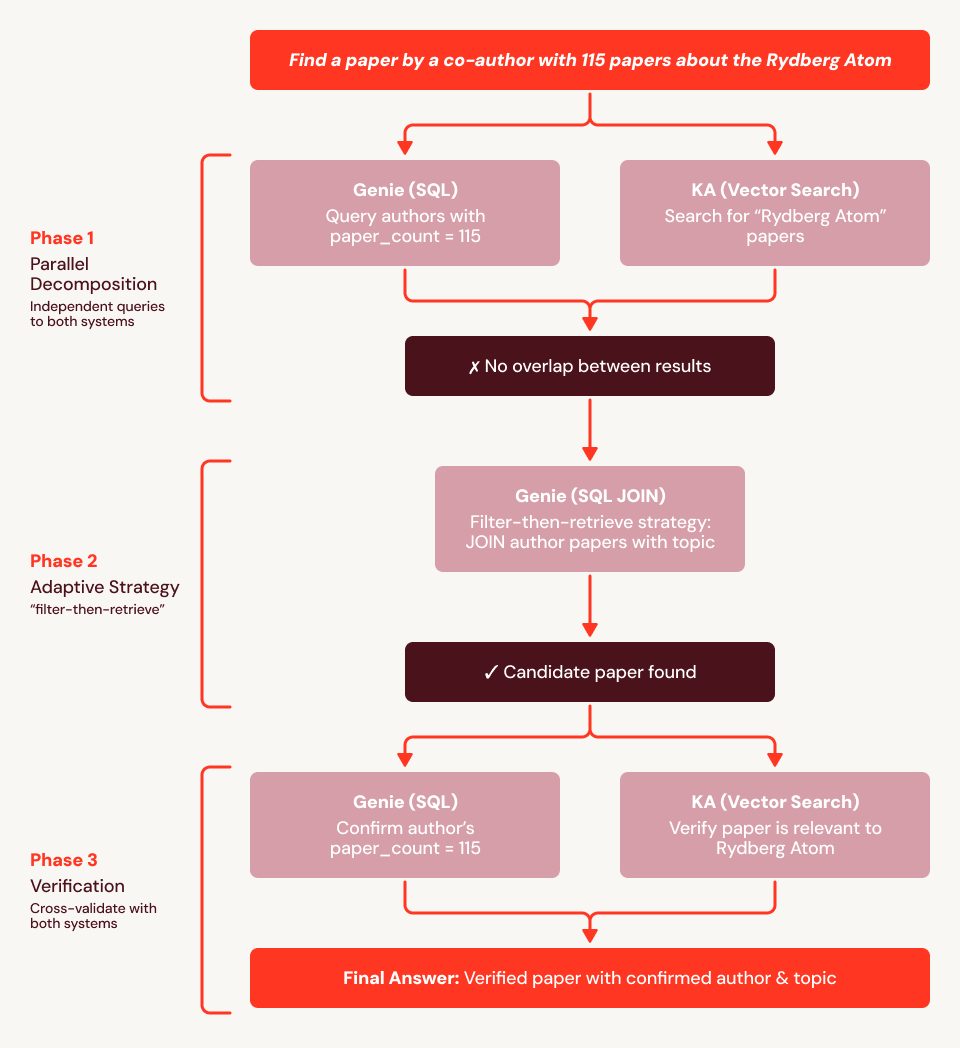
Usando nossa pergunta de exemplo acima ("Encontre-me um artigo escrito por um coautor com 115 artigos e que seja sobre o átomo de Rydberg"), descobrimos que a linha de base falha porque os embeddings não conseguem codificar a restrição estrutural ("coautor tem exatamente 115 artigos"). Na Figura 4, mostramos um rastreamento de execução para o SA: ele primeiro usa o Genie para encontrar todos os 759 autores com 115 artigos e o Knowledge Assistant para recuperar artigos sobre Rydberg, depois cruza os dois conjuntos. Quando não há sobreposição, o SA se adapta: ele emite um JOIN SQL da lista de autores com 115 artigos contra todos os artigos que mencionam "Rydberg" no título ou resumo, apresentando a resposta diretamente dos dados estruturados. Em seguida, ele chama o Knowledge Assistant para verificar a relevância e o Genie para confirmar a contagem de artigos do autor, e retorna com sucesso o artigo correto.
A Vantagem Agente em Tarefas Intensivas em Conhecimento
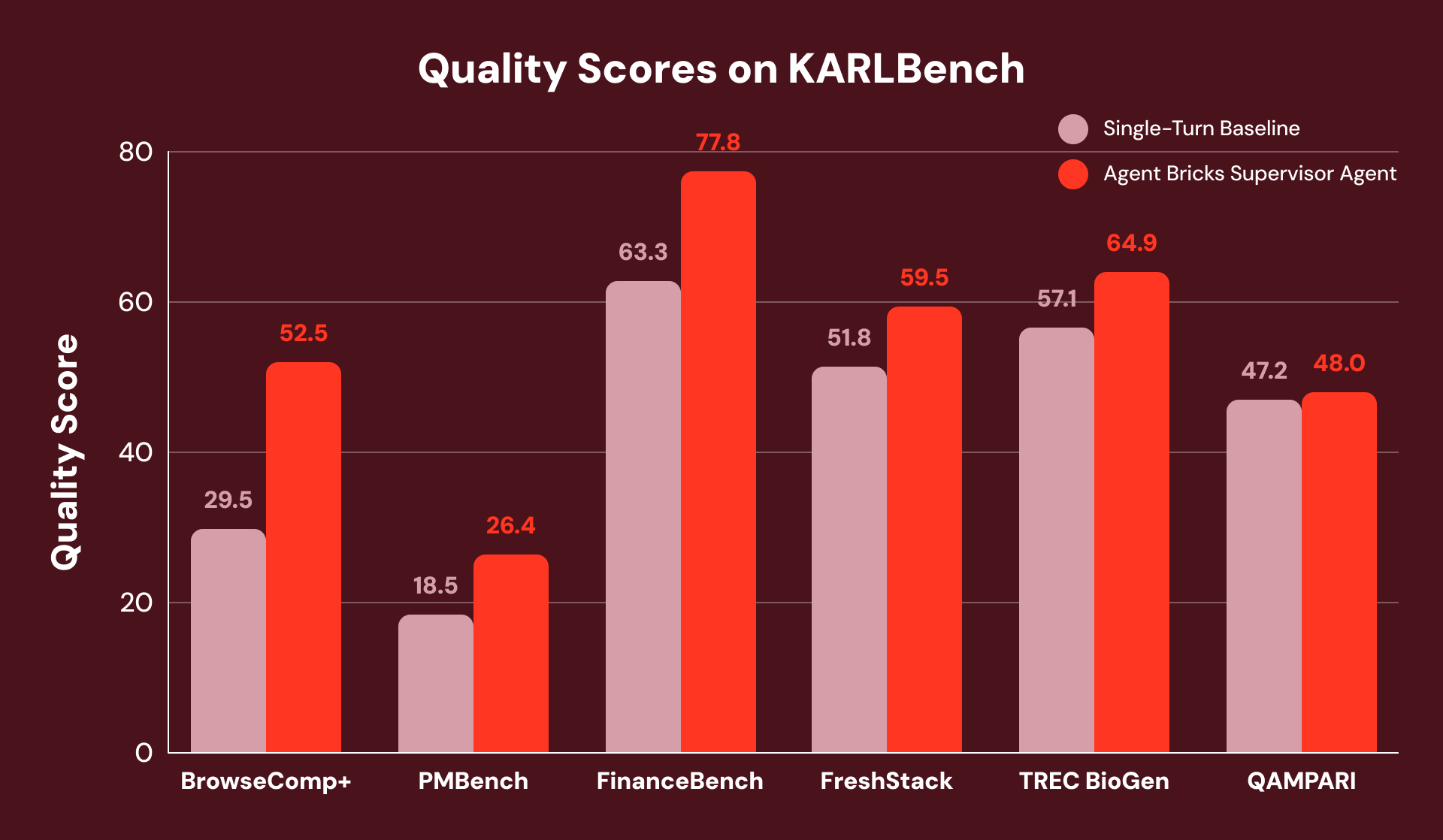
Para comparar o desempenho do Agent Bricks SA com uma linha de base forte de turno único (semelhante à melhor linha de base publicada para STaRK) onde nenhum dado estruturado é necessário, nós os avaliamos usando o KARLBench, um conjunto de benchmarks de raciocínio fundamentado que testa coletivamente diferentes capacidades de recuperação e raciocínio:
- BrowseComp+: busca de entidades por processo de eliminação
- TREC BioGen: síntese de literatura biomédica
- FinanceBench: raciocínio numérico sobre relatórios financeiros
- QAMPARI: recuperação exaustiva de entidades
- FreshStack: solução de problemas técnicos em documentação
- PMBench: compreensão de documentos empresariais internos da Databricks
No geral, o Supervisor Agent alcança ganhos consistentes em todos os seis benchmarks, com as maiores melhorias em tarefas que exigem análise exaustiva ou autocorreção. No FinanceBench, ele se recupera de uma recuperação inicial incompleta detectando lacunas e reformulando consultas, resultando em uma melhoria geral de +23%.
Por exemplo, as perguntas do BrowseComp+ têm de 5 a 10 restrições interligadas, como “Encontre um jogador que deixou um clube russo (2015-2020), naturalizado europeu (2010-2016), altura 1,95-2,06m. Qual foi a sua taxa de sucesso de bloqueio nas Olimpíadas adiadas pela COVID?” A linha de base de turno único emite uma consulta ampla que identifica corretamente o jogador, mas não consegue apresentar documentos com estatísticas granulares e falha na pergunta.
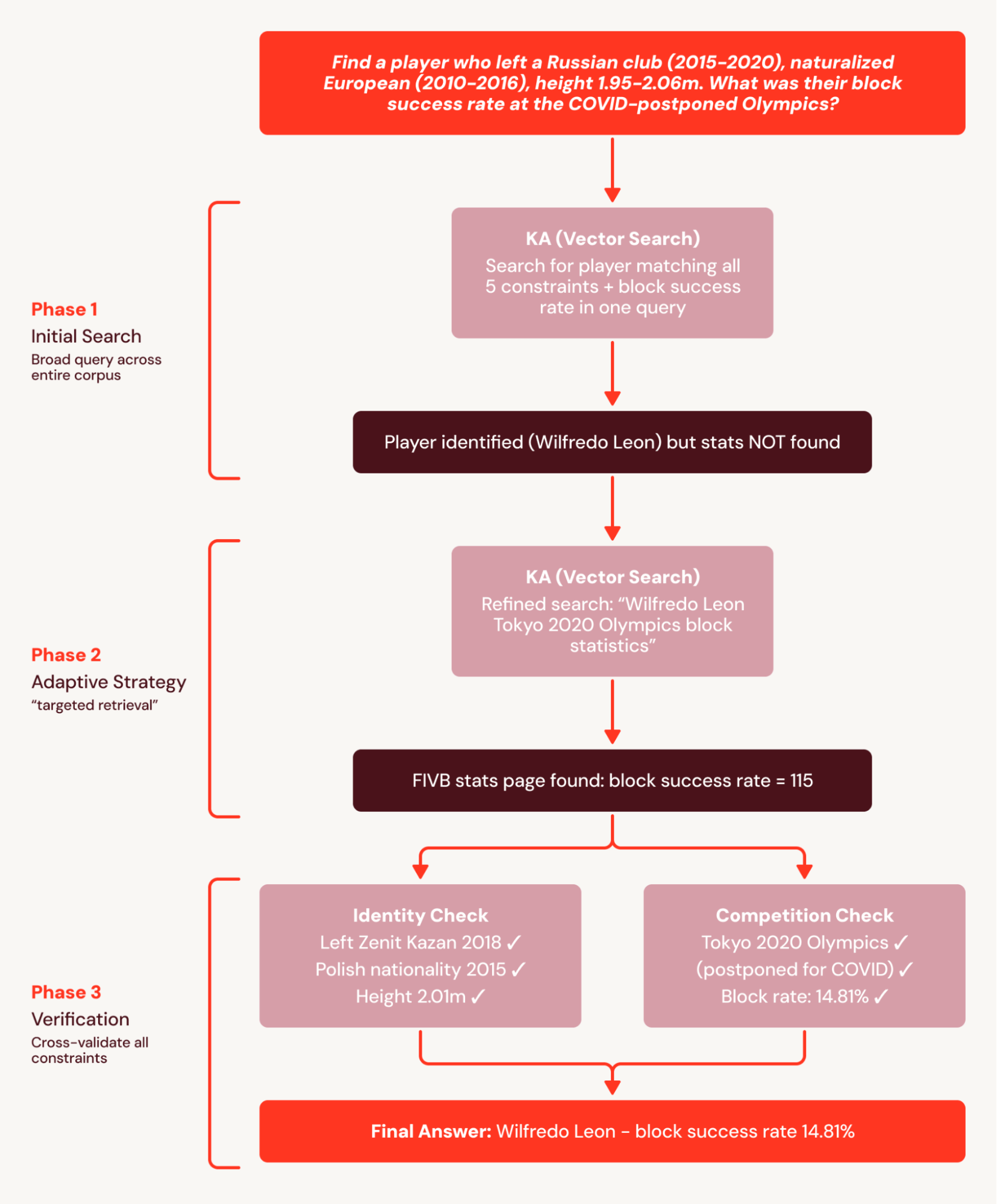
O SA divide essa tarefa em um plano de busca coordenado e decompõe o plano em subconjuntos pesquisáveis. Isso evita a falha da linha de base de turno único, onde as estatísticas não são encontradas porque são recuperadas em uma busca subsequente. Como resultado, o SA alcança uma melhoria relativa de +78%.
Em outro exemplo do PMBench, uma das perguntas é “quais são os tipos de guardrail que os clientes estão usando”, que requer 26 nuggets (veja a definição no relatório KARL) em mais de 10 documentos de conversas de clientes para uma resposta exaustiva. A linha de base de turno único encontra apenas uma menção de cliente porque não consegue pesquisar em todas as categorias de guardrail em uma única pergunta. O SA pesquisa cada categoria de guardrail separadamente (“detecção de PII”, “alucinação”, “toxicidade”, “injeção de prompt”) e, gradualmente, apresenta cada vez mais menções de clientes no processo.
O que aprendemos
Os resultados de nossos experimentos apontam para algumas conclusões importantes:
- Agentes de raciocínio fundamentados podem se beneficiar de uma combinação de recuperação de dados estruturados e não estruturados se tiverem acesso às ferramentas e representações de dados corretas.
- Para cenários de recuperação de alta qualidade, a criação de pipelines RAG personalizados sobre conjuntos de dados heterogêneos deve ser evitada, mesmo que modelos SoTA sejam usados para a fase de reclassificação. O raciocínio em várias etapas, onde, a cada etapa, o agente seleciona a fonte de dados correta e reflete sobre sua utilidade, é crucial para melhorar o desempenho.
- Uma abordagem declarativa para a construção de agentes, como a implementada pelo Databricks Supervisor Agent, oferece um bom equilíbrio entre facilidade de uso e qualidade.
Usamos o Databricks Supervisor Agent para construir agentes para todos os três domínios STaRK e seis conjuntos de dados não estruturados no KARLBench. As únicas coisas que diferem nessas nove tarefas são as instruções e as ferramentas — nenhum código personalizado foi necessário para processar esses diversos conjuntos de dados. Assim, construir um agente de alto desempenho para uma nova tarefa empresarial é, em grande parte, uma questão de escrever instruções precisas e equipá-lo com as ferramentas certas, em vez de construir um novo sistema do zero.
O Agent Bricks Supervisor Agent está disponível para todos os nossos clientes. Você pode começar com o Agent Bricks SA simplesmente criando um agente e conectando-o aos seus agentes, ferramentas e servidores MCP existentes. Explore a documentação para ver como o Supervisor Agent se encaixa em seus fluxos de trabalho de produção.
Autores: Xinglin Zhao, Arnav Singhvi, Mark Rizkallah, Jonathan Li, Jacob Portes, Elise Gonzales, Sabhya Chhabria, Kevin Wang, Yu Gong, Moonsoo Lee, Michael Bendersky e Matei Zaharia.
1Veja nossa publicação recente “KARL: Knowledge Agents via Reinforcement Learning” para mais detalhes sobre como o aroll é usado para geração de dados sintéticos, treinamento RL escalável e inferência online para tarefas de agente.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.