Agentic reasoning in practice: Making sense of structured and unstructured data
Enterprise data is rarely useful in a silo. Answering questions like, "Which of our products have had declining sales over the past three months, and what potentially related issues are brought up in customer reviews on various seller sites?" requires reasoning across a mix of structured and unstructured data sources, including data lakes, review data, and product information management systems. In this blog, we demonstrate how Databricks Agent Bricks Supervisor Agent (SA) can help with these complex, realistic tasks through multi-step reasoning grounded in a hybrid of structured and unstructured data.
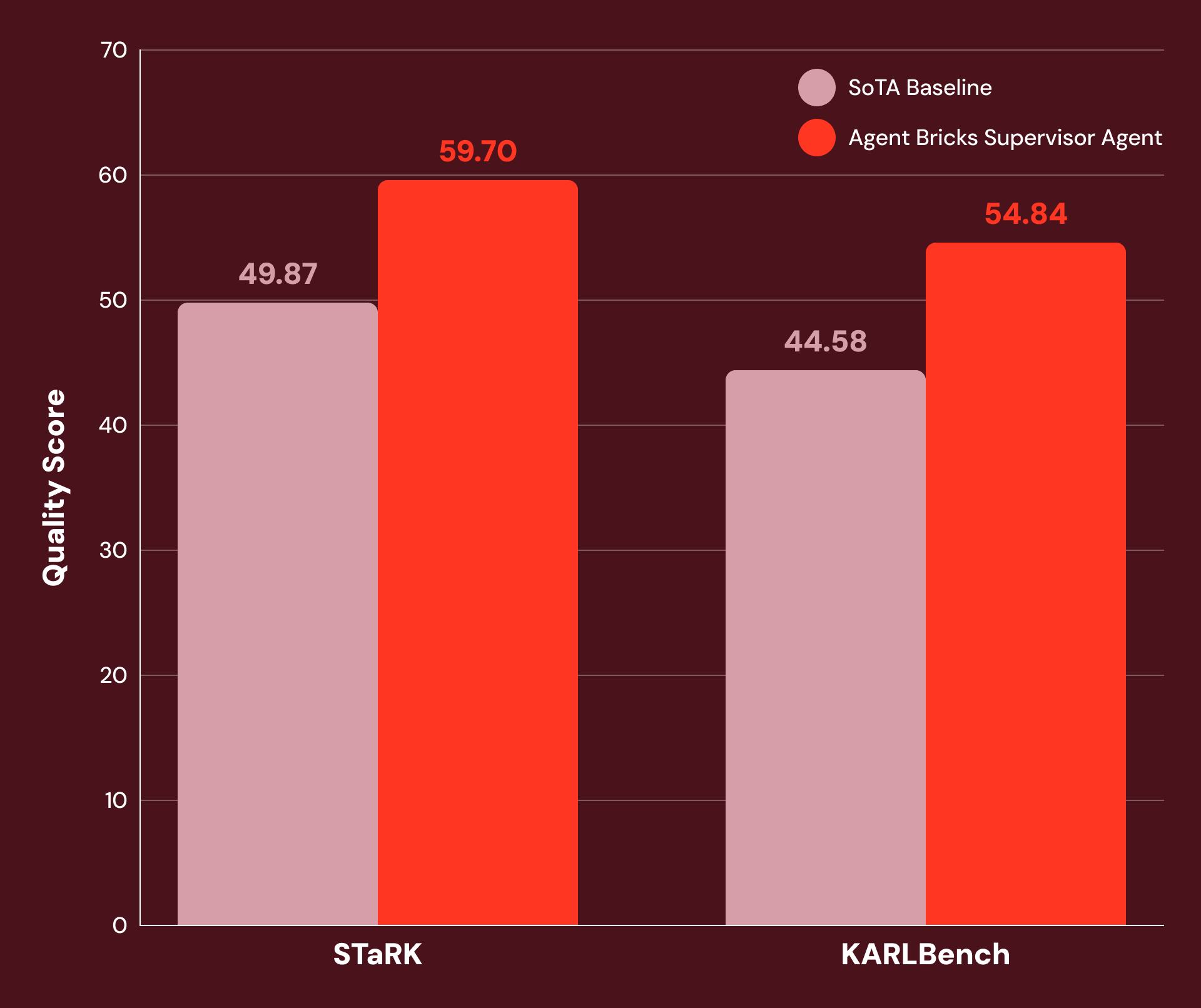
With tuned instructions and careful tool configuration, we find SA to be highly performant on a wide range of knowledge-intensive enterprise tasks. Figure 1 shows that SA achieves 20% or more improvement over SoTA baselines on:
- STaRK: a suite of three semi-structured retrieval tasks published by Stanford researchers.
- KARLBench: a benchmark suite for complex grounded reasoning recently published by Databricks.
Supervisor Agent demonstrates significant gains on a wide range of economically valuable tasks: from academic retrieval (+21% on STaRK-MAG) to biomedical reasoning (+38% on STaRK Prime) and financial analysis (+23% on FinanceBench).
Agent Setup
Agent Bricks Supervisor Agent is a declarative agent builder that orchestrates agents and tools. It is built on aroll — an internal agentic framework for building, evaluating, and deploying multi-step LLM workflows at scale.1 aroll and SA were specifically designed for the advanced agentic use cases our customers frequently encounter.
aroll enables adding new tools and custom instructions through simple configuration changes, can handle thousands of concurrent conversations and parallel tool executions, and incorporates advanced agent orchestration and context management techniques to refine queries and recover from partial answers. All of these are difficult to achieve with SoTA single-turn systems today.
Because SA is built on this flexible architecture, its quality can be continually improved through simple user curation, such as tweaking top-level instructions or refining agent descriptions, without needing to write any custom code.
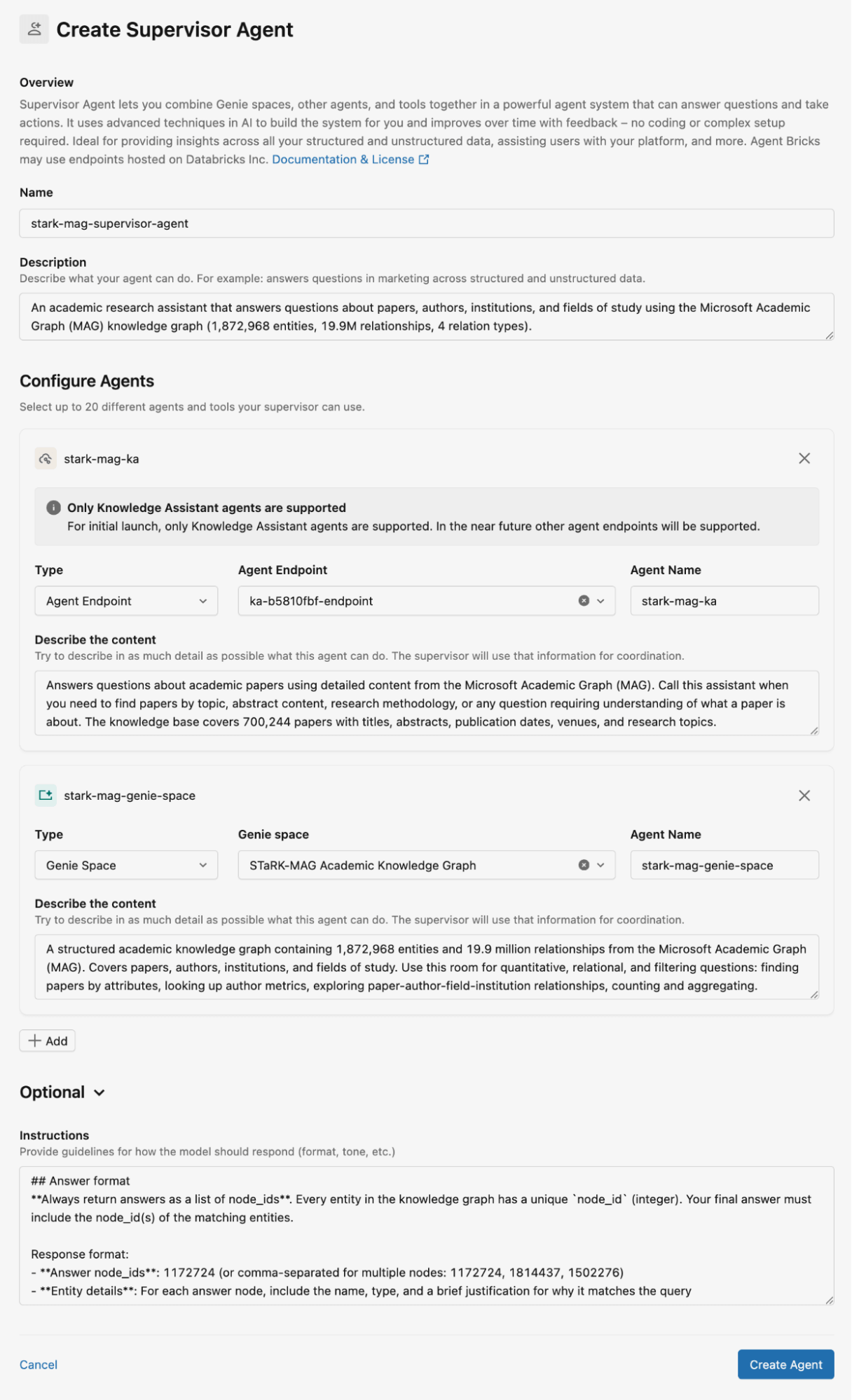
Figure 2 shows how we configured the Supervisor Agent for the STaRK-MAG dataset. In this blog, we use Genie spaces for storing the relational knowledge bases and Knowledge Assistants for storing unstructured documents for retrieval. We provide detailed descriptions for all Knowledge Assistants and Genie spaces, as well as instructions for the agent responses.
Hybrid Reasoning: Structured Meets Unstructured
To evaluate grounded reasoning based on a hybrid of structured and unstructured data, we use the STaRK benchmark, which includes three domains:
- Amazon: product attributes (structured) and reviews (unstructured)
- MAG: citation networks (structured) and academic papers (unstructured)
- Prime: biomedical entities (structured) and literature (unstructured)
For example, “Find me a paper written by a co-author with 115 papers and is about the Rydberg atom” requires the system to combine structured filtering (“co-author with 115 papers”) with unstructured understanding (“about the Rydberg atom”). The best published baselines use vector similarity search with an LLM-based reranker — a strong single-turn approach, but one that cannot decompose queries across data types. To ensure a fair comparison, we reran this baseline with the current SoTA foundational model, providing a substantially stronger baseline.
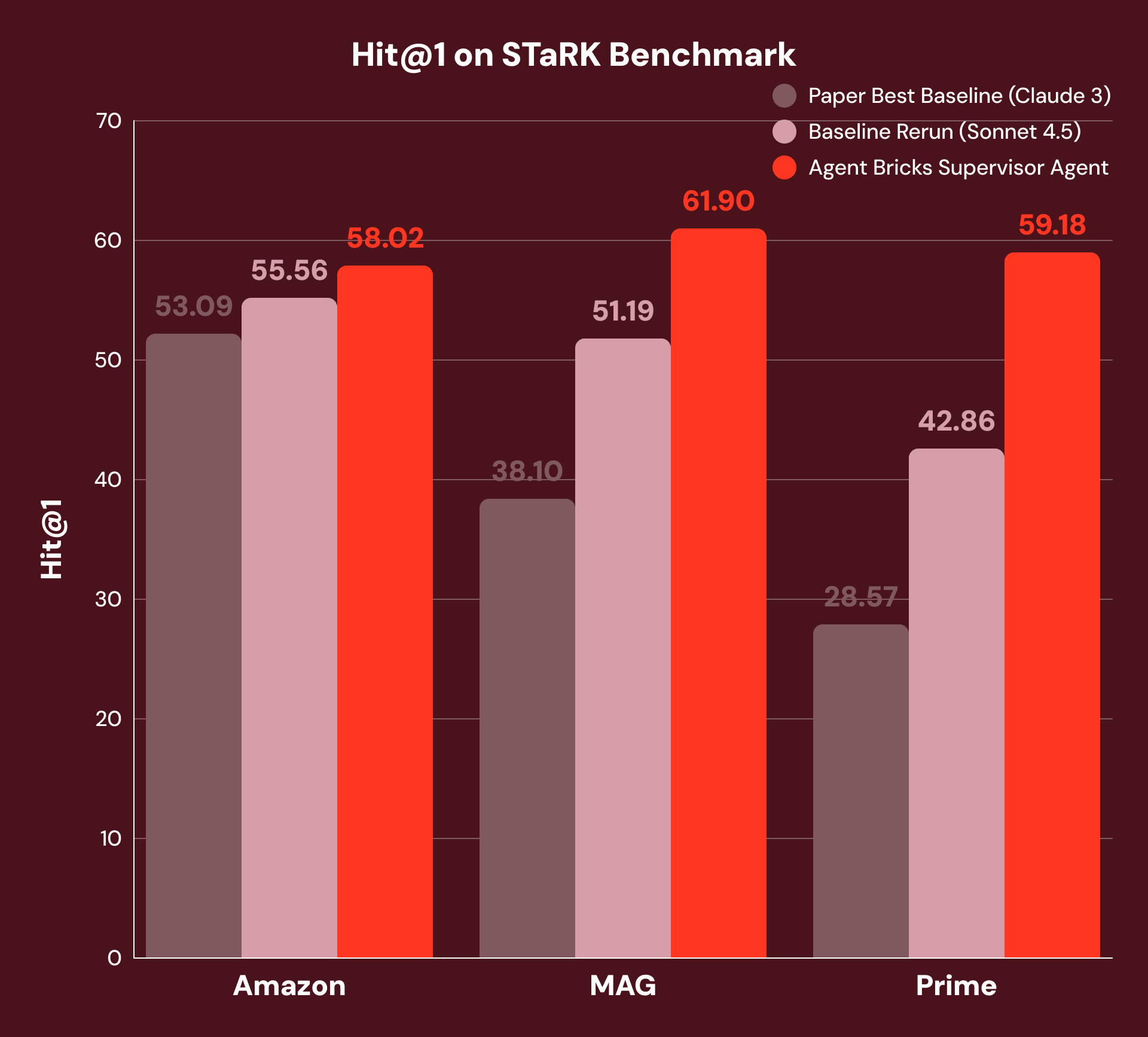
With our approach, SA decomposes each question, routes sub-questions to the appropriate tool, and synthesizes results across multiple reasoning steps. As Figure 3 shows, this achieves +4% Hit@1 on Amazon, +21% on MAG, and +38% on Prime over both the best of the original baselines and our rerun baselines with the current SoTA foundational model. We see the best improvements in MAG and Prime where the answer requires the tightest integration of structured and unstructured data.
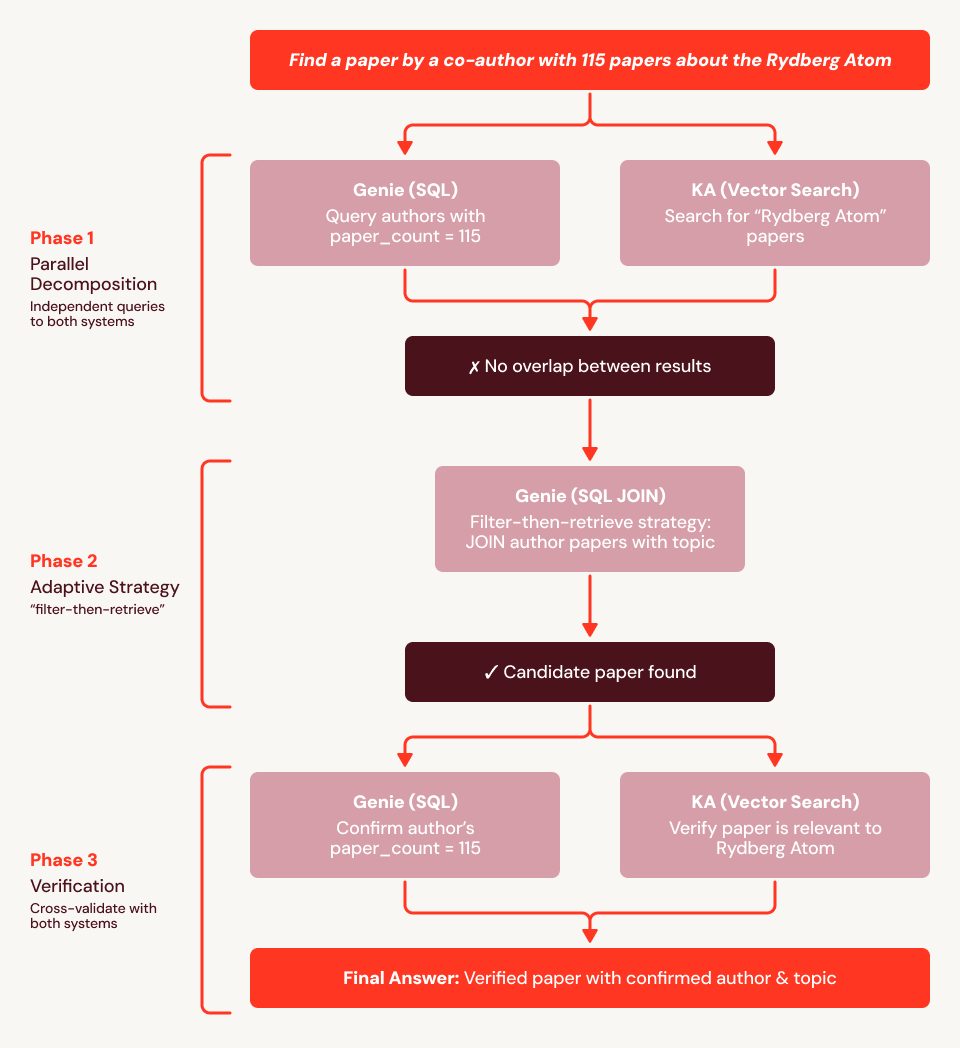
Using our example question from above (“Find me a paper written by a co-author with 115 papers and is about the Rydberg atom”), we find the baseline fails because the embeddings cannot encode the structural constraint (“co-author has exactly 115 papers”). In Figure 4, we show an execution trace for SA: it first uses Genie to find all 759 authors with 115 papers and Knowledge Assistant to retrieve Rydberg papers, then cross-references the two sets. When no overlap is found, SA adapts: it issues a SQL JOIN of the 115-paper author list against all papers mentioning "Rydberg" in the title or abstract, surfacing the answer directly from the structured data. It then calls Knowledge Assistant to verify relevance and Genie to confirm the author's paper count, and successfully returns the correct paper.
The Agentic Advantage on Knowledge-Intensive Tasks
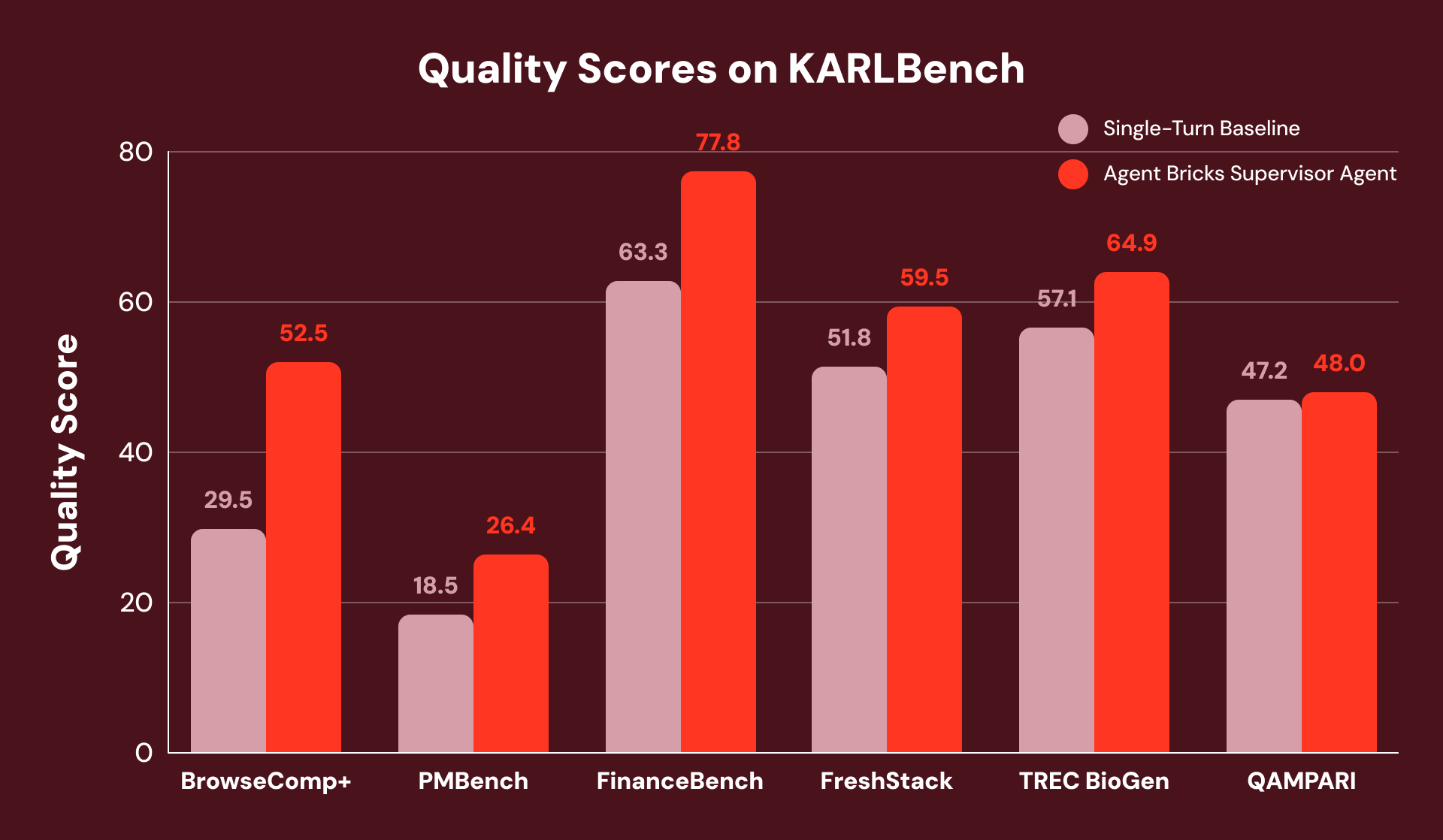
To compare the performance of Agent Bricks SA with a strong single-turn baseline (similar to the best published baseline for STaRK) where no structured data is required, we evaluate them using KARLBench, a grounded reasoning benchmark suite that collectively stress-tests different retrieval and reasoning capabilities:
- BrowseComp+: process-of-elimination entity search
- TREC BioGen: biomedical literature synthesis
- FinanceBench: numerical reasoning over financial filings
- QAMPARI: exhaustive entity recall
- FreshStack: technical troubleshooting over documentation
- PMBench: Databricks internal enterprise document comprehension
Overall, the Supervisor Agent achieves consistent gains across all six benchmarks, with the largest improvements on tasks that demand either exhaustive analysis or self-correction. On FinanceBench, it recovers from initially incomplete retrieval by detecting gaps and reformulating queries, yielding overall +23% improvement.
For example, BrowseComp+’s questions each have 5-10 interlocking constraints, like “Find a player who left a Russian club (2015-2020), naturalized European (2010-2016), height 1.95-2.06m. What was their block success rate at the COVID-postponed Olympics?” The single-turn baseline issues one broad query that correctly identifies the player but fails to surface granular statistics documents and fails the question.
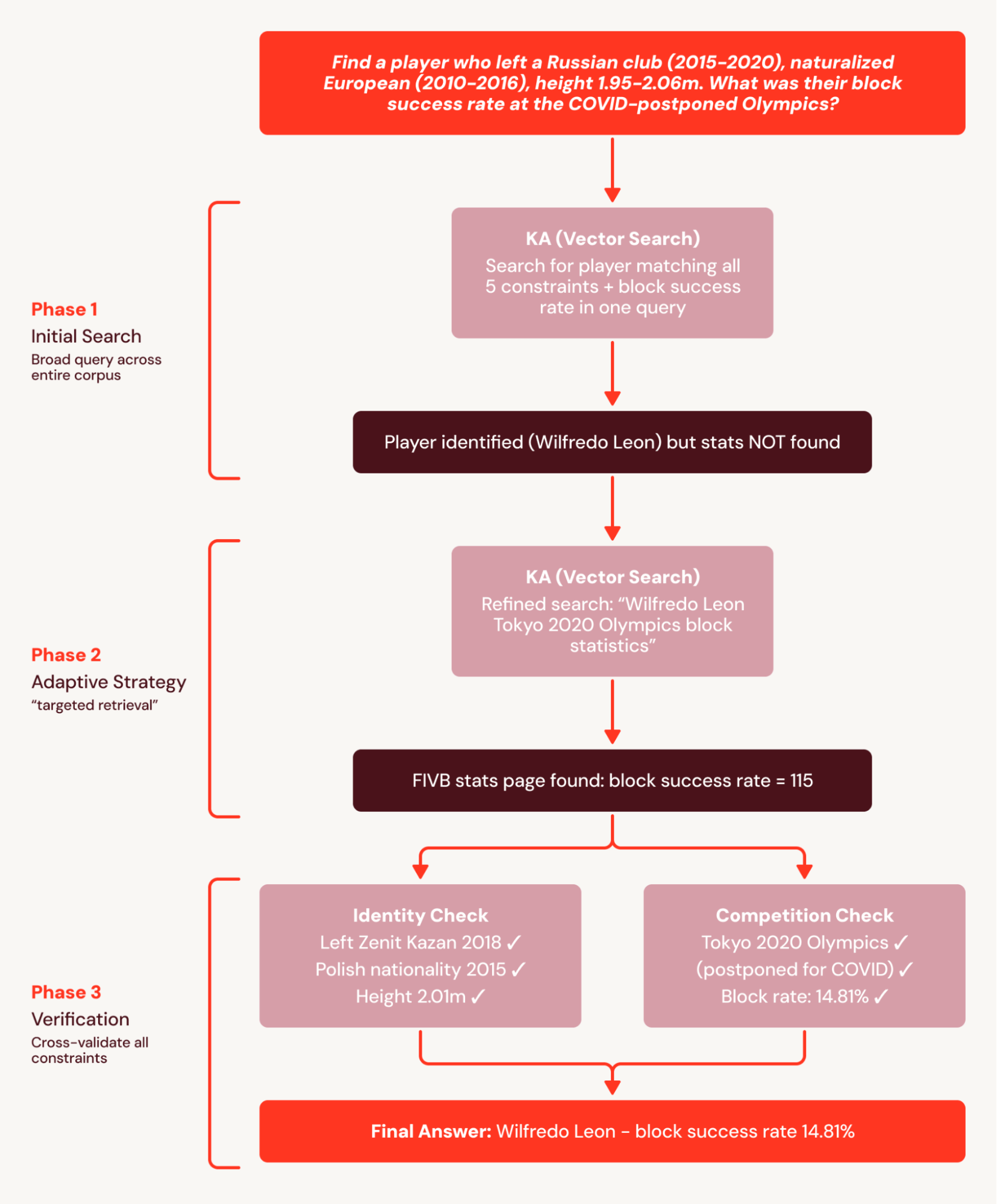
SA breaks this task into a coordinated search plan and decomposes the plan into searchable subsets. This avoids the single-turn baseline failure where stats are not found because they are retrieved in a subsequent search. As a result, SA achieves a +78% relative improvement.
In another example from PMBench, one of the questions is “what are the guardrail types customers are using” which requires 26 nuggets (see definition in KARL report) across 10+ customer conversation documents for an exhaustive answer. Single-turn baseline finds only one customer mention because it cannot search across every guardrail category in a single question. SA searches each guardrail category separately (“PII detection,” “hallucination,” “toxicity,” “prompt injection”), and incrementally surfaces more and more customer mentions in the process.
What We Learned
The results across our experiments point to a few key takeaways:
- Grounded reasoning agents can benefit from a hybrid of structured and unstructured data retrieval if given access to the right tools and data representations.
- For high-quality retrieval scenarios, building custom RAG pipelines over heterogeneous datasets should be avoided, even if SoTA models are used for the re-ranking stage. Multi-step reasoning where, at each step, the agent selects the right data source and reflects on its utility, is crucial for upleveling performance.
- A declarative approach to agent building such as the one implemented by the Databricks Supervisor Agent provides a good trade-off between ease of use and quality.
We use the Databricks Supervisor Agent to build agents for all three STaRK domains and six unstructured datasets in KARLBench. The only things that differ across these nine tasks are the instructions and tools — no custom code was required to process these diverse datasets. Thus, building a performant agent for a new enterprise task is largely a matter of writing precise instructions and equipping it with the right tools, rather than building a new system from scratch.
Agent Bricks Supervisor Agent is available to all our customers. You can get started with Agent Bricks SA simply by creating an agent and connecting it to your existing agents, tools and MCP servers. Explore the documentation to see how Supervisor Agent fits into your production workflows.
Authors: Xinglin Zhao, Arnav Singhvi, Mark Rizkallah, Jonathan Li, Jacob Portes, Elise Gonzales, Sabhya Chhabria, Kevin Wang, Yu Gong, Moonsoo Lee, Michael Bendersky and Matei Zaharia.
1See our recent publication “KARL: Knowledge Agents via Reinforcement Learning” for more details how aroll is used for synthetic data generation, scalable RL training and online inference for agentic task.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.