Meet KARL: A faster agent for enterprise knowledge, powered by custom RL
Reinforcement Learning for Enterprise Agents
For the full tech report, click here. Interested in trying Databricks custom RL on your enterprise agent? Click here.
The improved reasoning abilities of current models has led to an explosion of agents deployed for knowledge work, such as writing code, asking questions about enterprise data, and automating common workflows. While models used in enterprise tasks are very powerful, they are also extremely expensive, and inference costs have begun to grow unsustainably for many use cases. In this post and the corresponding tech report, we describe our experience using reinforcement learning (RL) to build custom models to power use cases that are a key part of our Agent Bricks product. This example demonstrates that, for relatively low costs, it is possible to build custom models that strictly dominate frontier models on all three critical dimensions: inference cost, latency, and quality. Our findings are consistent with other industry observations, such as Cursor’s Composer model, where RL-based customization was able to drastically improve both speed and quality compared to alternatives.
KARL: A Faster, Stronger, Cheaper Knowledge Agent for Databricks Users
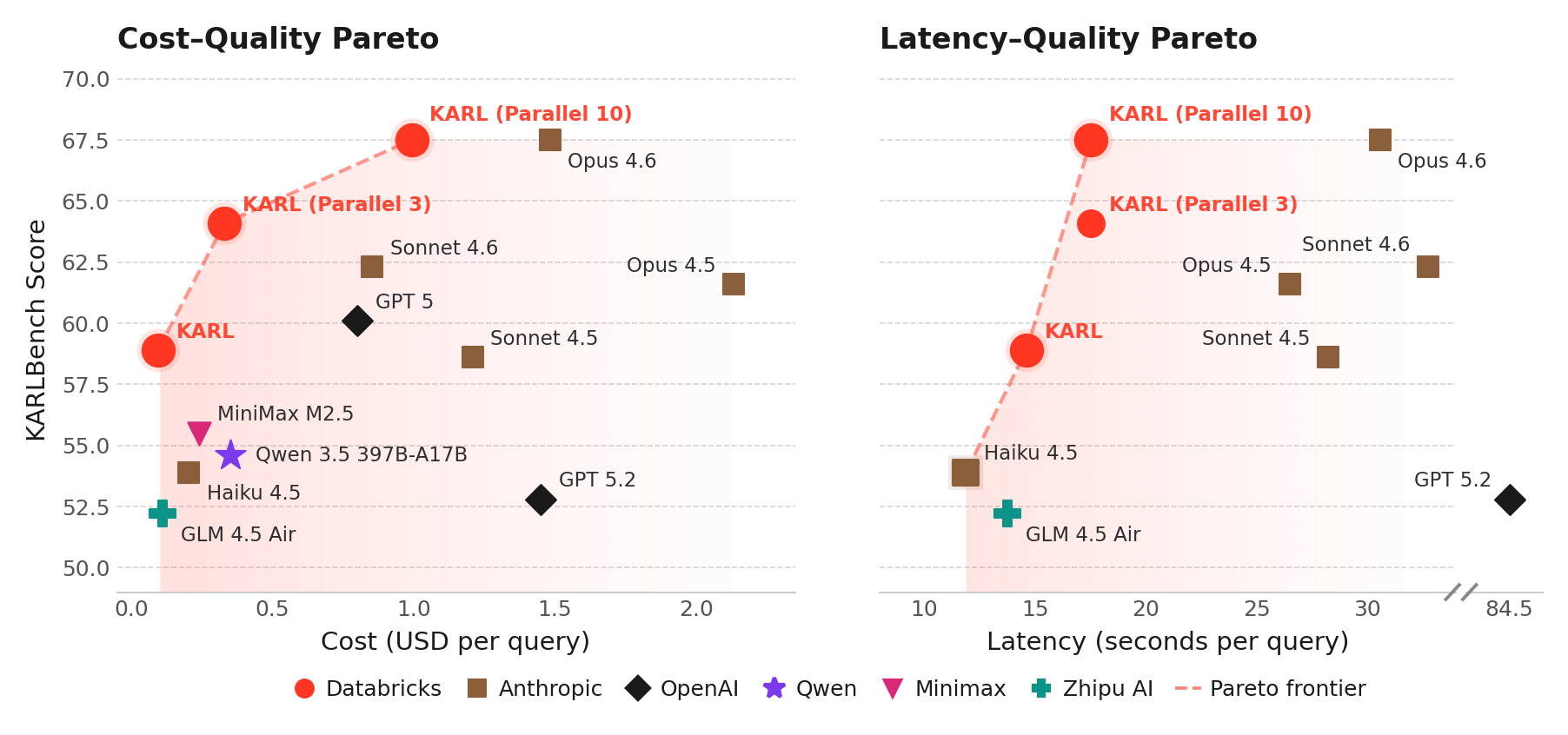
The model we trained, which we call KARL, addresses a critical enterprise capability, grounded reasoning: answering questions by searching for documents, fact-finding, cross-referencing information, and reasoning over dozens or hundreds of steps. Grounded reasoning is required for several Databricks products, such as Agent Bricks Knowledge Assistant. Unlike math and coding, grounded reasoning tasks are hard-to-verify – there’s often no single correct answer. In situations like this, guiding reinforcement learning to a good solution is especially hard.
Using RL techniques and infrastructure developed at Databricks, KARL matches the performance of the world's most powerful proprietary models at a fraction of the serving cost and latency, including on new grounded reasoning tasks it had never seen. (See the tech report for full details.) We did this with just a few thousand GPU hours of training and entirely synthetic data.
In internal testing with human users, KARL provided better and more comprehensive responses than our existing products and the latest frontier models. This research is making its way into the Databricks agents you use today, like Agent Bricks, grounding answers in your unstructured and structured data in the Databricks Lakehouse.
A reusable RL pipeline for Databricks customers
We are excited to share that the same RL pipelines and infrastructure we used to create KARL (and other agents we’ll talk about soon) are now available to Databricks customers seeking to improve model performance and reduce costs for their high-volume agentic workloads. Nearly all real-world enterprise tasks are hard-to-verify, so KARL paves the way – not just for a better experience for Databricks users – but for our customers to create their own custom RL models for their popular agents. Our Custom RL private preview, backed by AI Runtime, enables you to use the KARL infrastructure to build a more efficient, domain-specific version of your agent. If you have an AI agent that’s scaling fast and are interested in optimizing it with RL, sign up here to express your interest in this preview.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.