Uma abordagem com foco em IA para a engenharia de dados com Lakeflow e Agent Bricks
Como o Lakeflow e o Agent Bricks trazem automação com tecnologia de IA para todas as etapas do seu pipeline de ETL
por Joanna Zouhour
- O Lakeflow oferece uma plataforma de engenharia de dados que prioriza a AI, que permite que eles aproveitem e coloquem em produção modelos de AI em seu ETL com as funções de AI do Agent Bricks
- Os engenheiros de dados podem orquestrar facilmente seus modelos de AI em escala com o Lakeflow Jobs, automatizando seu pipeline de ETL dentro do contexto empresarial
- Da correspondência aproximada (fuzzy matching) à extração e ao resumo de dados, os usuários do Lakeflow Jobs podem desbloquear casos de uso de pipeline e extrair novos key entendimentos que podem potencializar seus casos de uso posteriores de analítica, BI e ML.
Os engenheiros de dados estão cada vez mais focados em um problema central: usar IA para aprimorar o ETL e construir pipelines confiáveis e de nível de produção sem introduzir nova complexidade. Eles precisam de uma IA que realmente entregue resultados, otimizando os fluxos de trabalho sem adicionar ferramentas desconectadas ou remover o contexto.
O Databricks Lakeflow traz uma plataforma unificada de engenharia de dados com IA incorporada e segura que automatiza todo o seu processamento de dados, permite obter mais percepções e oferece suporte a uma gama mais ampla de problemas de negócios. Seja com código de pipeline gerado por IA ou orquestrando workloads de IA, os engenheiros de dados que usam o Lakeflow podem evitar gastar horas em trabalho manual de integração e, em vez disso, focar em padrões estratégicos e de maior valor que geram impacto real para seus negócios.
Neste blog, exploraremos como você pode produtizar e escalar seus modelos de IA, implementando-os em seu pipeline de dados para gerar percepções de negócios automaticamente.
Extraia facilmente mais percepções de seus dados em escala
As equipes de dados estão sobrecarregadas com entradas não estruturadas, sejam contratos, faturas, transcrições ou avaliações. Processá-las geralmente significa lidar com modelos de NLP frágeis, regras rígidas ou limpeza manual. O resultado: saídas não confiáveis, longos prazos de entrega e percepções valiosas presas em documentos, enquanto os engenheiros perdem tempo com análises repetitivas em vez de gerar impacto.
Com o Databricks Lakeflow, você pode resolver isso incorporando de forma transparente transformações com tecnologia de IA em seus fluxos de trabalho existentes por meio das Funções de IA do Databricks Agent Bricks. Essas funções permitem integrar IA de alta qualidade diretamente ao seu processo de ETL, automatizando a extração, a transformação e a classificação de dados estruturados e não estruturados em escala.
Existem vários tipos de funções de AI no Agent Bricks que você pode escolher. Algumas delas não exigem prompts e são específicas para tarefas, como:
ai_extract: extrai entidades específicas do texto de entrada com base nos rótulos que você fornece. Por exemplo, pessoa, local, organizaçãoai_classify: Classifica o texto de entrada de acordo com os rótulos que você fornece. Por exemplo, “urgente” vs. “não urgente” ou categorias de tópico.ai_translate: Traduz o texto para um idioma de destino especificado.
Estamos especialmente entusiasmados com nossa função de IA recém-lançada, ai_parse_document, que pode ser usada para transformar quaisquer dados não estruturados nos formatos estruturados necessários. Usando modelos de base multimodais, a ai_parse_doc permite analisar texto, extrair tabelas, raciocinar sobre figuras e transformar imagens em descrições geradas por IA. Essa função abre novas possibilidades para o processamento de dados que antes eram quase impossíveis de analisar. Saiba mais aqui
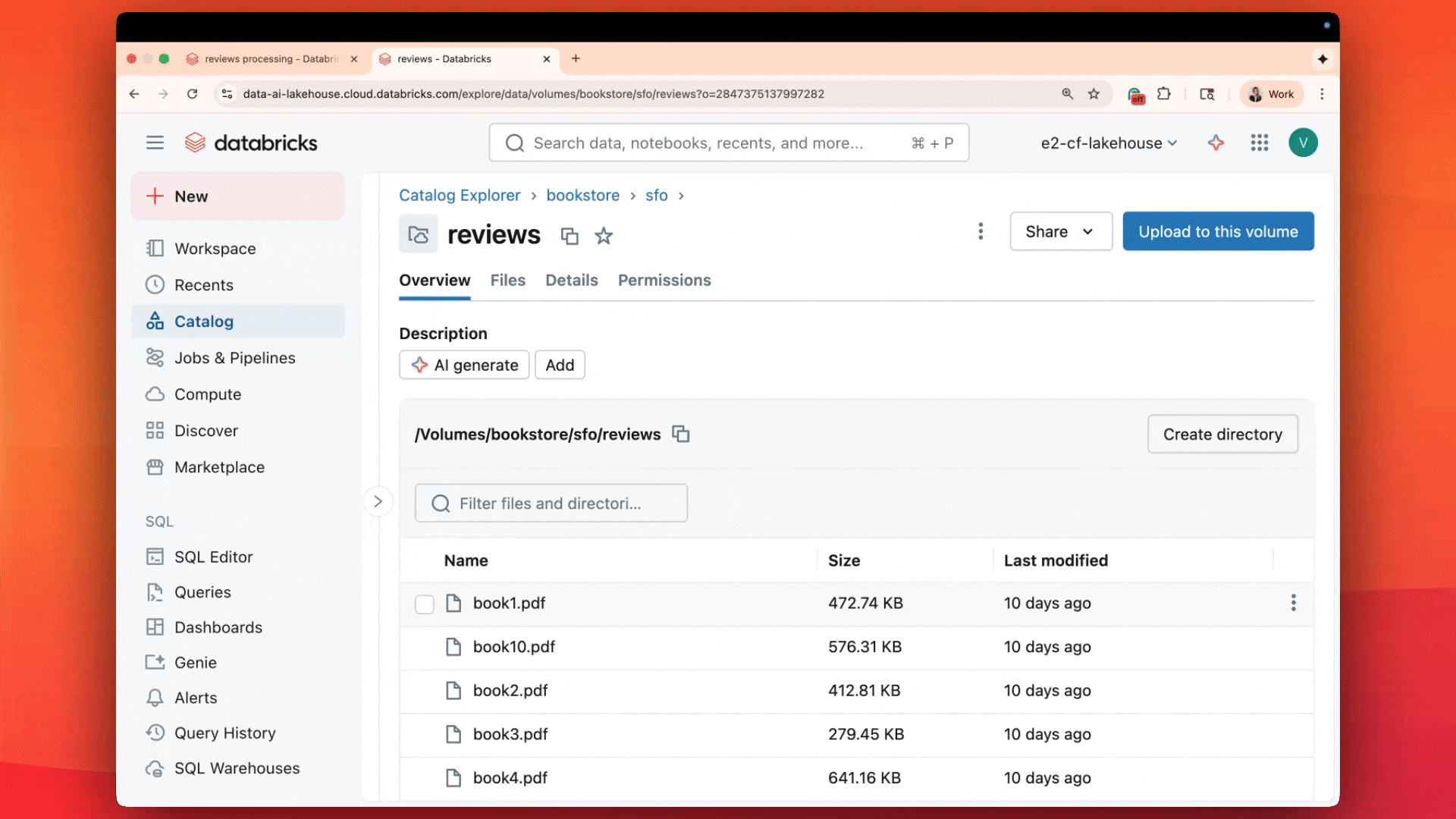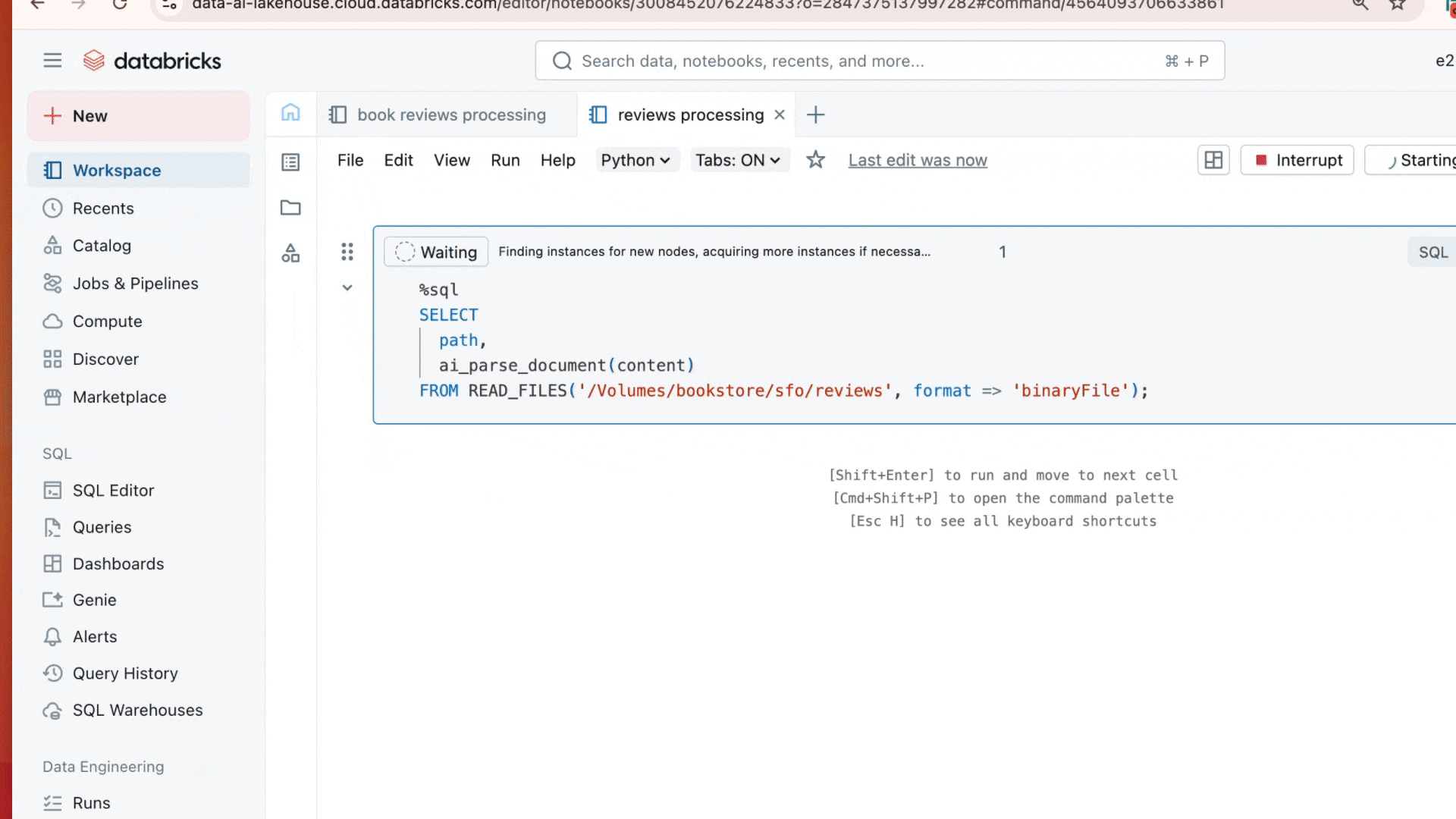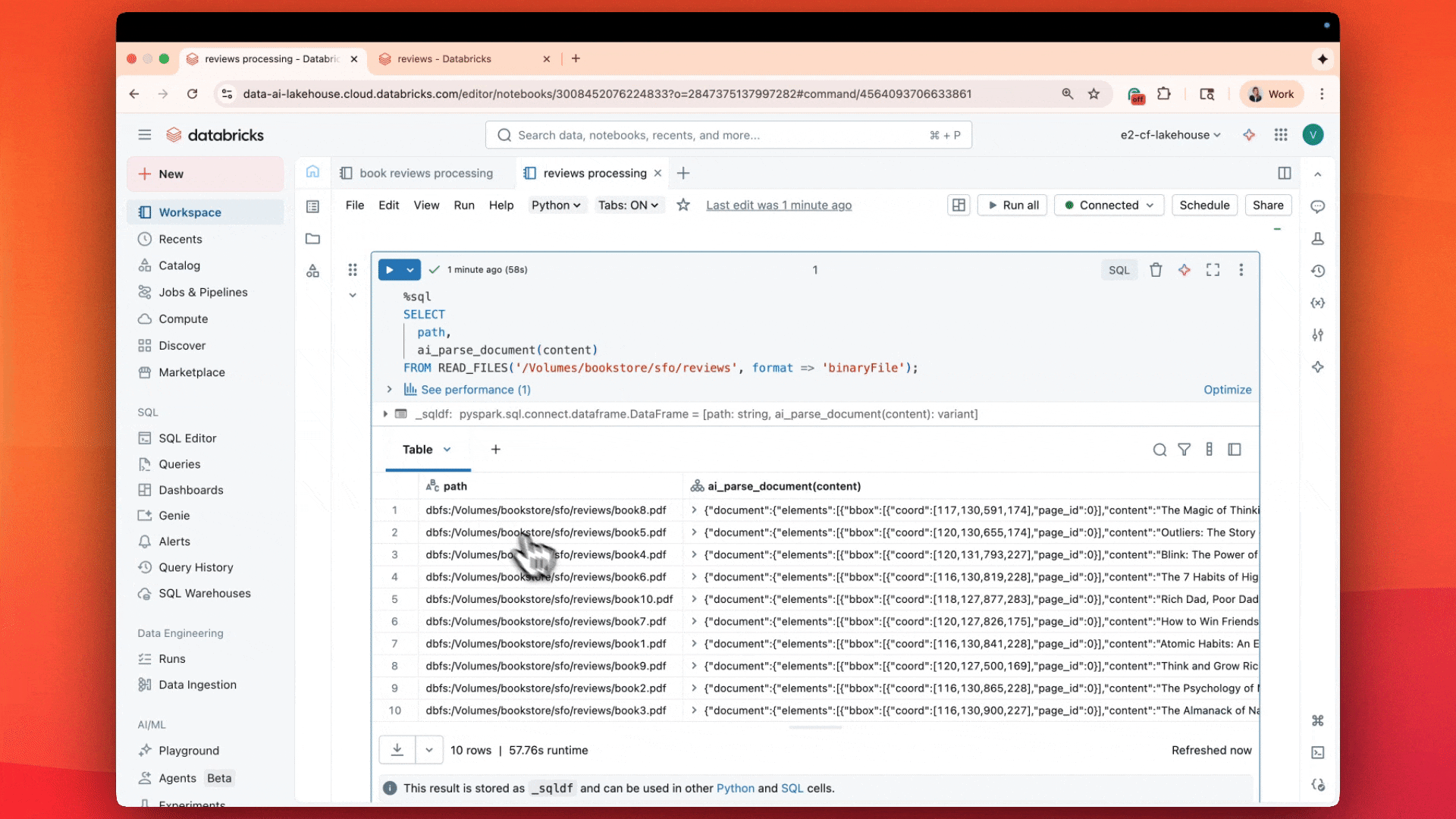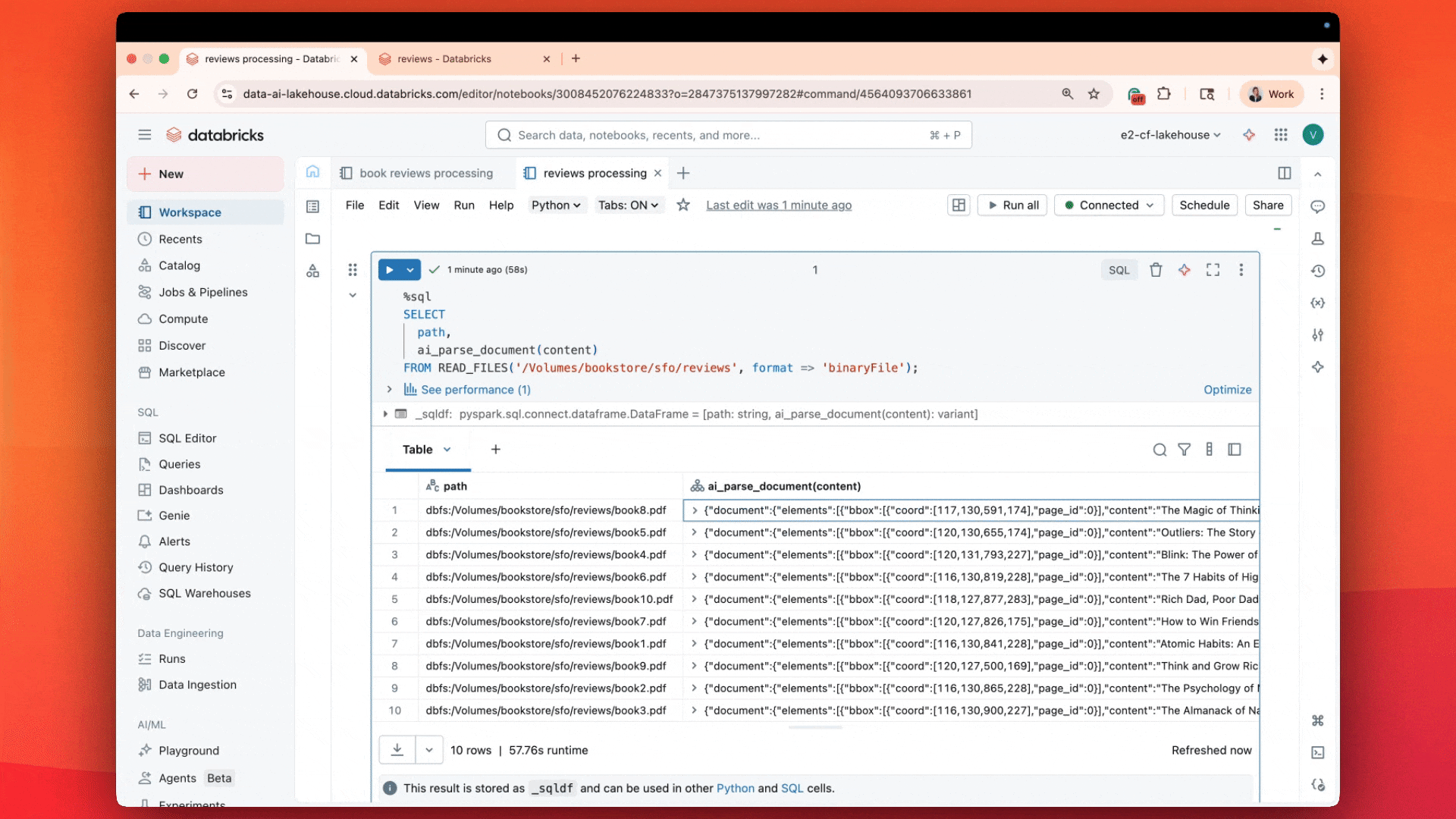
Também oferecemos uma função mais geral chamada ai_query(), impulsionada pela nossa plataforma de inferência em lote serverless. Essa função permite executar transformações orientadas por AI em grandes conjuntos de dados usando qualquer LLM de sua escolha de uma só vez.
Para maximizar o desempenho em milhões de linhas, nosso mecanismo de inferência em lotes sem servidor automaticamente realiza o provisionamento e escala os recursos de compute e executa cargas de trabalho em paralelo. Isso remove a sobrecarga por solicitação e oferece um processamento significativamente mais rápido, reduzindo os runtimes de horas para minutos e, ao mesmo tempo, melhorando a eficiência de custos para cargas de trabalho de IA de alto volume.
Com o Lakeflow, você pode facilmente colocar seus modelos de IA em produção e orquestrá-los nativamente em sua solução de engenharia de dados usando o Lakeflow Jobs. Com as funções de IA, você pode trazer mais eficiência para sua orquestração e viabilizar mais casos de uso, como:
- Gere novos dados. Use AI para escrever resumos sobre as percepções dos clientes para acelerar a geração de relatórios ou para projetar a receita futura.
- Estruture e organize dados em categorias específicas e relevantes para os negócios. Execute a execução de sentimentos em milhões de avaliações multilíngues ou automatize a segmentação de clientes usando prompts de linguagem natural em escala.
- Melhore a qualidade dos dados. Use a correspondência aproximada (fuzzy matching) e a resolução de entidades para corrigir duplicatas e inconsistências em escala.
A combinação do Lakeflow e do Agent Bricks permite que você execute seus modelos de AI em uma plataforma de dados única, unificada e governada, para que sua AI — e as percepções que ela extrai — tenham o contexto de negócios e empresarial correto.
Casos de uso práticos de funções de IA e do Lakeflow
Exemplo 1: Transformando transcrições brutas de chamadas em percepções de negócios
Imagine que sua equipe de vendas precisa de uma forma confiável para transformar transcrições de chamadas longas e não estruturadas em resumos claros e acionáveis. Com centenas de chamadas por dia, muitas com duração de 45 a 60 minutos, a revisão manual rapidamente se torna impossível.
Com o Databricks, você pode aproveitar as funções de IA integradas para analisar de forma fácil e rápida todas essas transcrições, extrair as principais percepções e gerar recomendações de acompanhamento.
Em vez de criar um serviço de AI separado ou gerenciar agentes personalizados, você pode simplesmente escrever uma query e executá-la como parte do seu orquestrador com o Lakeflow Jobs. Seu modelo de AI é então implementado diretamente em uma plataforma de engenharia de dados governada e unificada, onde você obtém processamento em lotes escalável que permanece totalmente integrado aos seus fluxos de trabalho de pipeline de ventas existentes, enquanto permanece no contexto de negócios e empresarial correto.
Vamos ver como isso funciona na prática. Após ingerir transcrições de chamadas em seu pipeline, você pode aplicar funções de IA para converter texto não estruturado em sinais utilizáveis:
ai_analyze_sentimentpara revelar o sentimento geral da chamada (positivo, negativo, neutro)ai_extractpara extrair informação importantes das chamadas, incluindo nome do cliente, nome da empresa, cargo, número de telefone etc.ai_classifypara categorizar o tipo de chamada (urgência, tópico etc.)
Isso oferece uma base estruturada para analítica e automação downstream.
Em seguida, use o ai_query para resumir cada chamada usando o modelo de IA de sua escolha (em nosso exemplo, estamos usando um LLM “databricks-meta-llama-3-3-70b-instruct”):
Esta query produz resumos consistentes e de alta qualidade que as equipes de ventas e de account podem analisar rapidamente.
Em seguida, você pode gerar acompanhamentos personalizados no mesmo fluxo de trabalho:
Essas anotações podem ser enviadas diretamente para seu CRM ou ferramentas de vendas em grande escala, para que suas equipes saibam exatamente qual o curso de ação correto a tomar logo após o término da chamada. Você também pode compartilhar essas anotações com sua equipe de BI para descobrir lacunas e ajudar a melhorar a experiência geral de serviço ao cliente.
Exemplo 2: Otimizando o processamento de sinistros de seguro
Imagine que você está criando um pipeline de processamento de sinistros para uma seguradora que precisa de aprovações mais rápidas e consistentes. Atualmente, as solicitações geralmente chegam por email com anexos não estruturados, como documentos digitalizados, fotos e PDFs, o que dificulta a ingestão e o processamento em escala.
Com o Agent Bricks e o Lakeflow, os engenheiros de dados podem usar o ai_parse_document e o ai_query para extrair, normalizar e consolidar dados de e-mails recebidos automaticamente como parte de seus pipelines de ETL. Isso permite uma automação confiável de ponta a ponta que reduz a revisão manual, acelera as decisões e se integra perfeitamente aos fluxos de trabalho de dados existentes.
Veja como isso funcionaria:
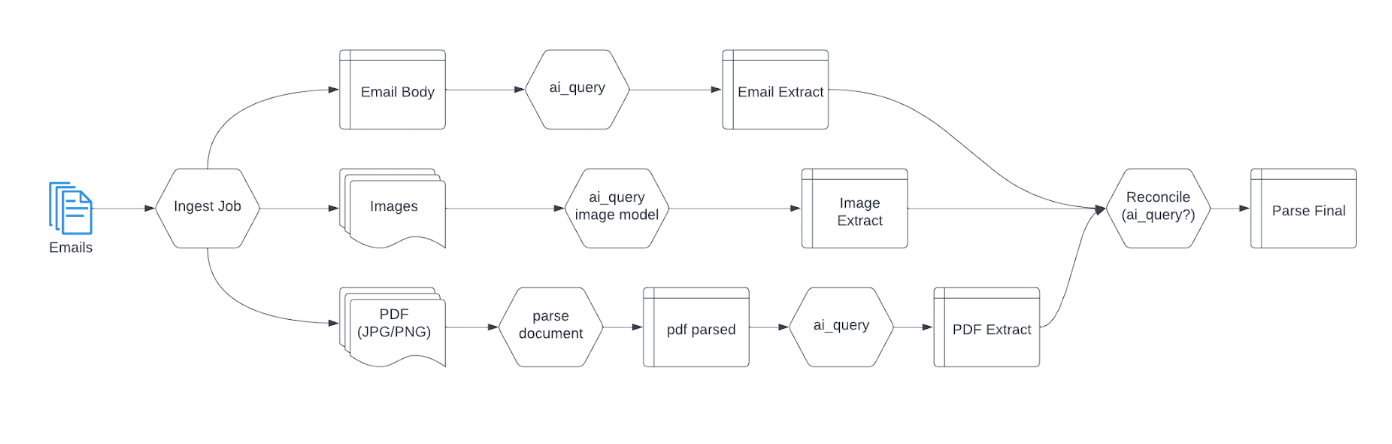
Usando o Lakeflow e o Agent Bricks, você pode ingerir seus arquivos de e-mail em seu lakehouse e, em seguida, extrair os dados de que precisa com:
ai_querypara ler o corpo do email e extrair informações importantes (por exemplo: nome, data de nascimento, endereço, número do seguro social)ai_querycom um modelo que pode ler especificamente o tipo de imagem de entrada. Esta função de AI gerará um texto que descreve a imagem anexada e extrairá seus metadados. Abaixo está um exemplo de query SQL dessa função:
- e
ai_parse_documentpara ler qualquer PDF (jpg ou png) anexado ao e-mail
Depois que os dados são extraídos, você pode usar o ai_query novamente para consolidar todas as informações em um arquivo que pode ser reutilizado em outro fluxo de trabalho ou compartilhado diretamente com uma equipe downstream (analista de BI, equipe de IA/ML etc.), dependendo do seu caso de uso.
Abaixo está um exemplo de DAG de como esse fluxo de trabalho ficaria no Lakeflow Jobs:
Há muito mais que você pode fazer combinando o Lakeflow e o Agent Bricks. Confira este vídeo para aprender como você pode transformar dados de vendas desorganizados em campanhas de marketing orientadas por IA.
Aplicações do mundo real de IA no Databricks
Muitos clientes e engenheiros de dados da Databricks solucionaram com sucesso vários problemas de negócios — preços, sucesso do cliente e marketing — usando IA e o Lakeflow para extrair percepções e aumentar a produtividade.
A Kard, uma fintech com sede em Nova York, usa as funções de AI do Agent Bricks para potencializar um sistema escalável e preciso de categorização de transações que substitui métodos legados manuais e inconsistentes. Essa abordagem moderna permite que a Kard processe com eficiência bilhões de transações, entregue recompensas personalizadas e forneça ricas percepções que impulsionam a fidelidade e o valor para o negócio.
A equipe de engenharia de dados do Banco Bradesco, um dos maiores bancos da América Latina, enfrentou gargalos de produtividade devido a longos processos de codificação, depuração e documentação. Ao adotar o Databricks Assistant, eles reduziram o tempo de codificação em 50% e capacitaram usuários técnicos e não técnicos a gerar e solucionar problemas de código usando linguagem natural, democratizando o acesso a dados, reduzindo custos e acelerando as decisões data-driven.
A Locala, uma plataforma global de publicidade omnichannel, usou o Lakeflow Jobs para orquestrar pipelines complexos de treinamento de LLM, os quais seu programador anterior, o Airflow, não conseguia gerenciar. Ao otimizar o ETL, o treinamento e a experimentação de modelos e a seleção de compute, o Lakeflow Jobs removeu a sobrecarga operacional de gerenciar fluxos de trabalho complexos, permitindo que um único data scientists criasse um Assistente de GenAI que se tornou um key recurso de ventas para a empresa de ad-tech.
Com o Lakeflow, você pode integrar facilmente recursos de IA em sua plataforma de engenharia de dados e orquestrar fluxos de trabalho de IA, tornando seus processos de dados mais eficientes, orientados por percepções e acessíveis. E vem mais por aí! Em breve, você poderá usar o Databricks Genie para potencializar sua plataforma de engenharia de dados para criação e depuração de pipelines usando processamento de linguagem natural.
- Comece a usar a Databricks Free Edition
- Confira a documentação do produto sobre as Databricks AI functions.
- Saiba mais sobre Databricks Genie
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.