Anunciando a Disponibilidade Geral do Databricks Lakeflow
A abordagem unificada para engenharia de dados em ingestão, transformação e orquestração
por Bilal Aslam e Michael Armbrust
- O Databricks Lakeflow resolve os desafios de engenharia de dados impostos por stacks fragmentados, oferecendo uma solução unificada para ingestão, transformação e orquestração na plataforma de inteligência de dados.
- O Lakeflow Connect adiciona mais conectores para bancos de dados, fontes de arquivos, aplicações corporativas e data warehouses. O Zerobus introduz escritas diretas de alta vazão com baixa latência.
- O Lakeflow Declarative Pipelines, construído sobre o novo padrão aberto Spark Declarative Pipelines, apresenta um novo IDE para engenheiros de dados para um melhor desenvolvimento de pipelines de ETL.
Temos o prazer de anunciar que o Lakeflow, a solução unificada de engenharia de dados da Databricks, está agora em Disponibilidade Geral. Ele inclui conectores de ingestão expandidos para fontes de dados populares, um novo “IDE para engenharia de dados” que facilita a criação e depuração de pipelines de dados, e capacidades expandidas para operacionalização e monitoramento de ETL.
No Data + AI Summit do ano passado, apresentamos o Lakeflow – nossa visão para o futuro da engenharia de dados – uma solução ponta a ponta que inclui três componentes principais:
- Lakeflow Connect: Ingestão confiável e gerenciada de aplicativos corporativos, bancos de dados, sistemas de arquivos e fluxos em tempo real, sem a sobrecarga de conectores personalizados ou serviços externos.
- Lakeflow Declarative Pipelines: Pipelines de ETL escaláveis construídos no padrão aberto do Spark Declarative Pipelines, integrados com governança e observabilidade, e proporcionando uma experiência de desenvolvimento simplificada através de um moderno “IDE para engenharia de dados”.
- Lakeflow Jobs: Orquestração nativa para a Plataforma de Inteligência de Dados, suportando fluxo de controle avançado, gatilhos de dados em tempo real e monitoramento abrangente.
Ao unificar a engenharia de dados, o Lakeflow elimina a complexidade e o custo de juntar diferentes ferramentas, permitindo que as equipes de dados se concentrem na criação de valor para o negócio. O Lakeflow Designer, o novo construtor visual de pipelines com IA, capacita qualquer usuário a criar pipelines de dados de nível de produção sem escrever código.
Foi um ano agitado, e estamos muito animados para compartilhar as novidades à medida que o Lakeflow atinge a Disponibilidade Geral.
Equipes de engenharia de dados lutam para acompanhar as necessidades de dados de suas organizações
Em todos os setores, a capacidade de uma empresa extrair valor de seus dados por meio de análise e IA é sua vantagem competitiva. Os dados estão sendo utilizados em todas as facetas da organização – para criar visões 360° do cliente e novas experiências para o cliente, para viabilizar novas fontes de receita, para otimizar operações e para capacitar funcionários. À medida que as organizações buscam utilizar seus próprios dados, elas acabam com um conjunto fragmentado de ferramentas. Engenheiros de dados acham difícil lidar com a complexidade das tarefas de engenharia de dados enquanto navegam por pilhas de ferramentas fragmentadas que são dolorosas de integrar e caras de manter.
Um desafio chave é a governança de dados – ferramentas fragmentadas dificultam a aplicação de padrões, levando a lacunas na descoberta, linhagem e observabilidade. Um estudo recente da The Economist descobriu que “metade dos engenheiros de dados diz que a governança consome mais tempo do que qualquer outra coisa”. A mesma pesquisa perguntou aos engenheiros de dados o que traria os maiores benefícios para sua produtividade, e eles identificaram “‘simplificar conexões de fontes de dados para ingestão de dados’, ‘usar uma única solução unificada em vez de múltiplas ferramentas’ e ‘melhor visibilidade em pipelines de dados para encontrar e corrigir problemas’ entre as principais intervenções”.
Uma solução unificada de engenharia de dados integrada à Plataforma de Inteligência de Dados
O Lakeflow ajuda as equipes de dados a enfrentar esses desafios, fornecendo uma solução ponta a ponta de engenharia de dados na Plataforma de Inteligência de Dados. Clientes Databricks podem usar o Lakeflow para todos os aspectos da engenharia de dados – ingestão, transformação e orquestração. Como todas essas capacidades estão disponíveis como parte de uma única solução, não há tempo gasto em integrações complexas de ferramentas ou custos extras para licenciar ferramentas externas.
Além disso, o Lakeflow é integrado à Plataforma de Inteligência de Dados e, com isso, vêm formas consistentes de implantar, governar e observar todos os casos de uso de dados e IA. Por exemplo, para governança, o Lakeflow se integra ao Unity Catalog, a solução de governança unificada para a Plataforma de Inteligência de Dados. Através do Unity Catalog, os engenheiros de dados obtêm visibilidade e controle total sobre todas as partes do pipeline de dados, permitindo que entendam facilmente onde os dados estão sendo usados e identifiquem a causa raiz dos problemas à medida que surgem.
Seja versionando código, implantando pipelines de CI/CD, protegendo dados ou observando métricas operacionais em tempo real, o Lakeflow aproveita a Plataforma de Inteligência de Dados para fornecer um local único e consistente para gerenciar as necessidades de engenharia de dados de ponta a ponta.
Lakeflow Connect: Mais conectores e gravações diretas rápidas no Unity Catalog
Neste último ano, vimos uma forte adoção do Lakeflow Connect, com mais de 2.000 clientes usando nossos conectores de ingestão para extrair valor de seus dados. Um exemplo é a Porsche Holding Salzburg, que já está vendo os benefícios de usar o Lakeflow Connect para unificar seus dados de CRM com análises para melhorar a experiência do cliente.
“Usar o conector do Salesforce do Lakeflow Connect nos ajuda a fechar uma lacuna crítica para a Porsche do lado do negócio em termos de facilidade de uso e preço. Do lado do cliente, somos capazes de criar uma experiência de cliente completamente nova que fortalece o vínculo entre a Porsche e o cliente com uma jornada do cliente unificada e não fragmentada.” —Lucas Salzburger, Gerente de Projeto, Porsche Holding Salzburg
Hoje, estamos expandindo a amplitude de fontes de dados suportadas com mais conectores integrados para ingestão simples e confiável. Os conectores do Lakeflow são otimizados para extração eficiente de dados, incluindo o uso de métodos de captura de dados de alteração (CDC) personalizados para cada fonte de dados respectiva.
Esses conectores gerenciados agora abrangem aplicativos corporativos, fontes de arquivos, bancos de dados e data warehouses, sendo lançados em vários estados de lançamento:
- Aplicativos corporativos: Salesforce, Workday, ServiceNow, Google Analytics, Microsoft Dynamics 365, Oracle NetSuite
- Fontes de arquivos: SFTP, SharePoint
- Bancos de dados: Microsoft SQL Server, Oracle Database, MySQL, PostgreSQL
- Data warehouses: Snowflake, Amazon Redshift, Google BigQuery
Além disso, um caso de uso comum que vemos de clientes é a ingestão de dados de eventos em tempo real, tipicamente com infraestrutura de barramento de mensagens hospedada fora de sua plataforma de dados. Para simplificar esse caso de uso no Databricks, estamos anunciando o Zerobus, uma API do Lakeflow Connect que permite aos desenvolvedores gravar dados de eventos diretamente em seu lakehouse com alta taxa de transferência (100 MB/s) e latência quase em tempo real (<5 segundos). Essa infraestrutura de ingestão simplificada oferece desempenho em escala e é unificada com a Plataforma Databricks para que você possa aproveitar ferramentas de análise e IA mais amplas imediatamente.
“A Joby consegue usar nossos agentes de fabricação com Zerobus para enviar gigabytes por minuto de dados de telemetria diretamente para nosso lakehouse, acelerando o tempo para insights – tudo com Databricks Lakeflow e a Plataforma de Inteligência de Dados.” —Dominik Müller, Líder de Sistemas de Fábrica, Joby Aviation Inc.
Lakeflow Declarative Pipelines: Desenvolvimento acelerado de ETL construído sobre padrões abertos
Após anos operando e evoluindo o DLT com milhares de clientes em petabytes de dados, pegamos tudo o que aprendemos e criamos um novo padrão aberto: Spark Declarative Pipelines. Esta é a próxima evolução no desenvolvimento de pipelines – declarativa, escalável e aberta.
E hoje, estamos animados em anunciar a Disponibilidade Geral do Lakeflow Declarative Pipelines, trazendo o poder do Spark Declarative Pipelines para a Plataforma de Inteligência de Dados Databricks. É 100% compatível com o padrão aberto, para que você possa desenvolver pipelines uma vez e executá-los em qualquer lugar. Também é 100% retrocompatível com pipelines DLT, para que usuários existentes possam adotar as novas capacidades sem reescrever nada. Lakeflow Declarative Pipelines são uma experiência totalmente gerenciada no Databricks: computação serverless sem intervenção, integração profunda com Unity Catalog para governança unificada e um IDE para Engenharia de Dados construído especificamente para isso.
O novo IDE para Engenharia de Dados é um ambiente moderno e integrado, construído para simplificar a experiência de desenvolvimento de pipelines. Ele inclui:
- Código e DAG lado a lado, com visualização de dependências e pré-visualizações instantâneas de dados
- Depuração sensível ao contexto que exibe problemas inline
- Integração Git integrada para desenvolvimento rápido
- Criação e configuração assistidas por IA
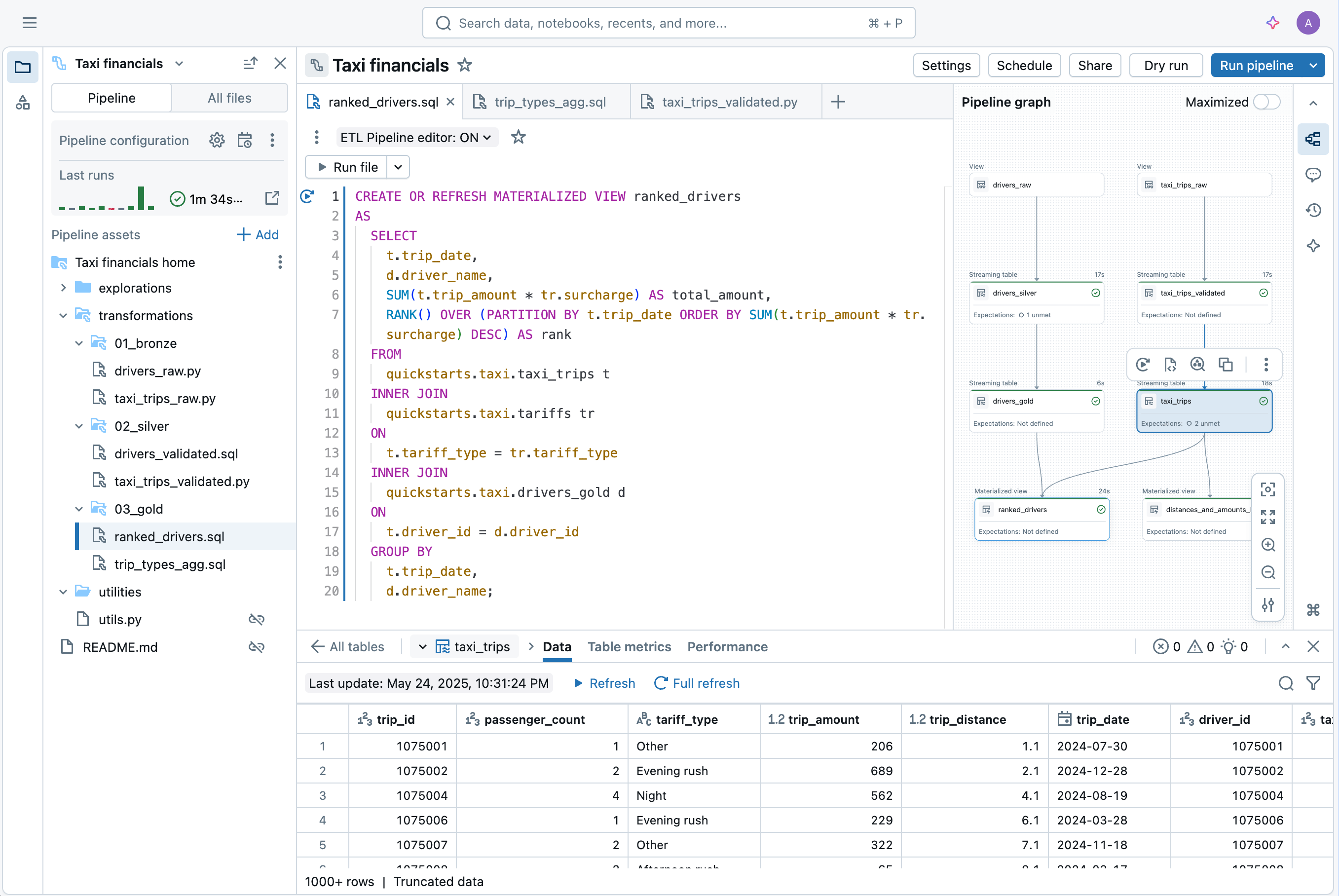
“O novo editor reúne tudo em um só lugar - código, gráfico de pipeline, resultados, configuração e solução de problemas. Chega de alternar entre abas do navegador ou perder o contexto. O desenvolvimento parece mais focado e eficiente. Posso ver diretamente o impacto de cada alteração de código. Um clique me leva à linha de erro exata, o que torna a depuração mais rápida. Tudo se conecta - código a dados; código a tabelas; tabelas ao código. Alternar entre pipelines é fácil, e recursos como pastas de utilitários pré-configuradas removem a complexidade. Isso parece a forma como o desenvolvimento de pipelines deveria funcionar.” —Chris Sharratt, Engenheiro de Dados, Rolls-Royce
Os Pipelines Declarativos do Lakeflow são agora a maneira unificada de construir pipelines escaláveis, governados e continuamente otimizados no Databricks - quer você esteja trabalhando em código ou visualmente através do Lakeflow Designer, uma nova experiência sem código que permite a praticantes de dados de qualquer nível técnico construir pipelines de dados confiáveis.
Lakeflow Jobs: Orquestração confiável para todas as cargas de trabalho com observabilidade unificada
O Databricks Workflows é confiável há muito tempo para orquestrar fluxos de trabalho de missão crítica, com milhares de clientes confiando em nossa plataforma para executar mais de 110 milhões de jobs todas as semanas. Com o GA do Lakeflow, estamos evoluindo o Workflows para Lakeflow Jobs, unificando este orquestrador maduro e nativo com o restante da stack de engenharia de dados.
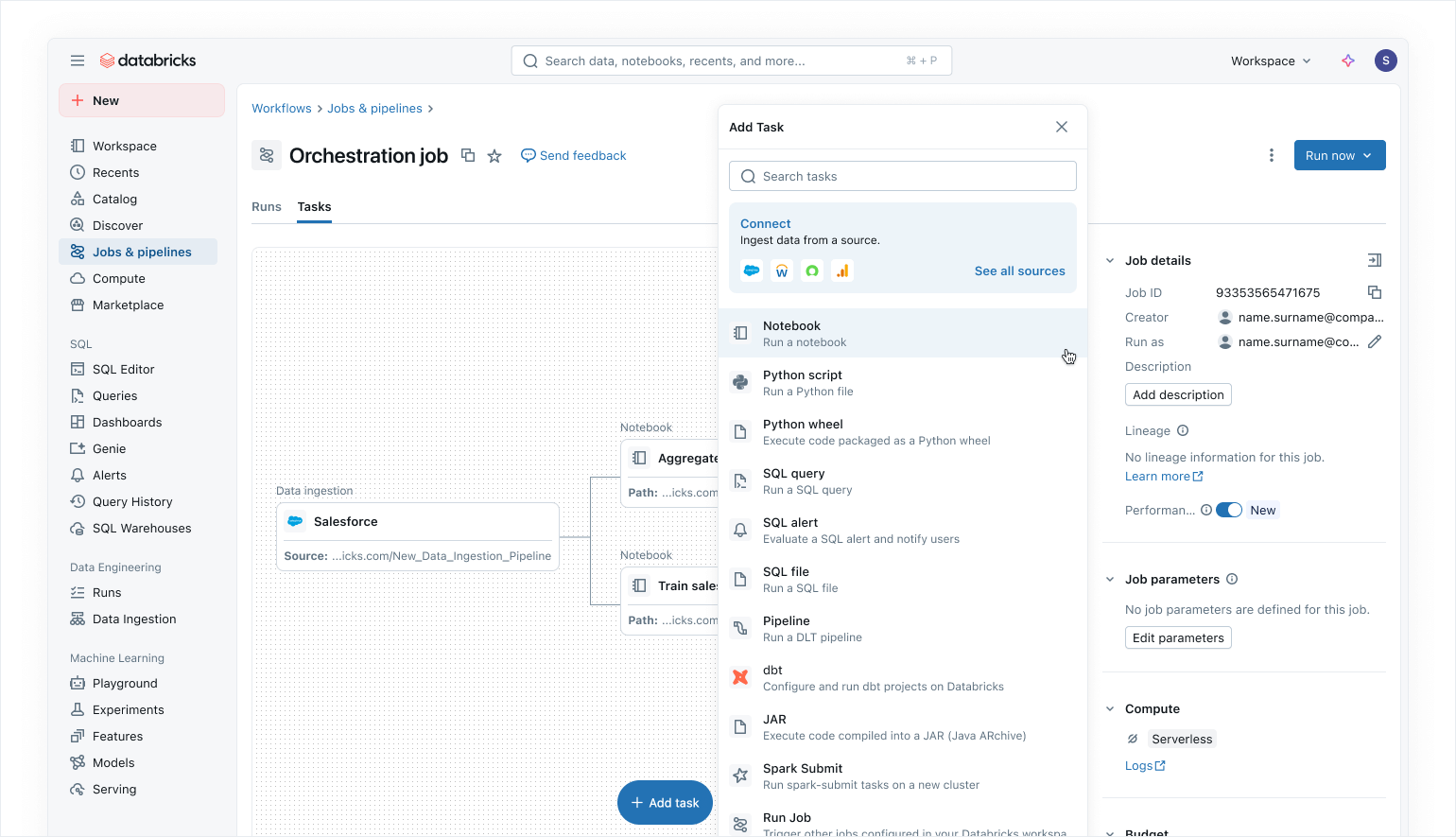
O Lakeflow Jobs permite orquestrar qualquer processo na Plataforma de Dados Inteligente com um conjunto crescente de recursos, incluindo:
- Suporte para uma coleção abrangente de tipos de tarefas para orquestrar fluxos que incluem Pipelines Declarativos, notebooks, consultas SQL, transformações dbt e até mesmo publicação de dashboards de IA/BI ou para o Power BI.
- Recursos de controle de fluxo, como execução condicional, loops e configuração de parâmetros no nível da tarefa ou do job.
- Triggers para execuções de jobs além do agendamento simples, com triggers de chegada de arquivos e os novos triggers de atualização de tabela, que garantem que os jobs só rodem quando novos dados estiverem disponíveis.
- Jobs serverless que fornecem otimizações automáticas para melhor desempenho e menor custo.
“Com os jobs serverless do Lakeflow, alcançamos uma melhoria de 3 a 5 vezes na latência. O que antes levava 10 minutos, agora leva apenas 2 a 3 minutos, reduzindo significativamente os tempos de processamento. Isso nos permitiu entregar ciclos de feedback mais rápidos para jogadores e treinadores, garantindo que eles obtenham os insights de que precisam em tempo quase real para tomar decisões acionáveis.” —Bryce Dugar, Gerente de Engenharia de Dados, Cincinnati Reds
Como parte da unificação do Lakeflow, o Lakeflow Jobs traz observabilidade de ponta a ponta para todas as camadas do ciclo de vida dos dados, desde a ingestão de dados até a transformação e orquestração complexa. Um conjunto diversificado de ferramentas se adapta a todas as necessidades de monitoramento: ferramentas de monitoramento visual fornecem busca, status e rastreamento em um relance; ferramentas de depuração como perfis de consulta ajudam a otimizar o desempenho; alertas e tabelas de sistema ajudam a identificar problemas e oferecem insights históricos; e expectativas de qualidade de dados aplicam regras e garantem altos padrões para suas necessidades de pipeline de dados.
Comece com o Lakeflow
Lakeflow Connect, Lakeflow Declarative Pipelines e Lakeflow Jobs estão todos em Disponibilidade Geral para todos os clientes Databricks hoje. Saiba mais sobre o Lakeflow aqui e visite a documentação oficial para começar com o Lakeflow em seu próximo projeto de engenharia de dados.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.