Anunciando as métricas de LLM-como-juiz do MLflow 2.8 e as Melhores Práticas para Avaliação de LLM de Aplicações RAG, Parte 2
por Quinn Leng, Kasey Uhlenhuth, Alkis Polyzotis, Abe Omorogbe e Sunish Sheth
Hoje, temos o prazer de anunciar que o MLflow 2.8 oferece suporte às nossas métricas de LLM-como-juiz, que podem ajudar a economizar tempo e custos, ao mesmo tempo que fornecem uma aproximação das métricas julgadas por humanos. Em nosso relatório anterior, discutimos um estudo de caso sobre como a técnica LLM-como-juiz nos ajudou a aumentar a eficiência, cortar custos e manter mais de 80% de consistência com as pontuações humanas no Assistente de IA da documentação da Databricks, resultando em economias significativas de tempo (de 2 semanas com força de trabalho humana para 30 minutos com juízes LLM) e custos (de US$ 20 por tarefa para US$ 0,20 por tarefa). Também demos continuidade ao nosso relatório anterior sobre as melhores práticas para a avaliação de LLM-como-juiz de aplicações RAG (Geração Aumentada por Recuperação) com uma Parte 2 abaixo. Vamos demonstrar como você pode aplicar uma metodologia semelhante, em combinação com a limpeza de dados, para avaliar e ajustar o desempenho de suas próprias aplicações RAG. Assim como no relatório anterior, o LLM-como-juiz é uma ferramenta promissora no conjunto de técnicas de avaliação necessárias para medir a eficácia das aplicações baseadas em LLM. Em muitas situações, acreditamos que ele representa um ponto ideal: ele pode avaliar saídas não estruturadas (como a resposta de um chatbot) de forma automática, rápida e a baixo custo. Nesse sentido, nós o consideramos um valioso complemento à avaliação humana, que é mais lenta e mais cara, mas representa o padrão ouro da avaliação de modelos.
O seu uso de um serviço de LLM de terceiros (p. ex., OpenAI) para avaliação pode estar sujeito e ser regido pelos termos de uso do serviço de LLM.
MLflow 2.8: Avaliação automatizada
A comunidade de LLMs tem explorado o uso de "LLMs como juiz" para avaliação automatizada e aplicamos a teoria deles em projetos de produção. Descobrimos que você pode economizar custos e tempo significativos se usar a avaliação automatizada com LLMs de última geração, como as famílias de modelos GPT, MPT e Llama2, com um único exemplo de avaliação para cada critério. O MLflow 2.8 apresenta um framework poderoso e personalizável para avaliação de LLMs. Ampliamos a API de Avaliação do MLflow para oferecer suporte a métricas de GenAI e exemplos de avaliação. Você obtém métricas prontas para uso, como toxicidade, latência, tokens e muito mais, juntamente com algumas métricas de GenAI que usam o GPT-4 como juiz default, como faithfulness, answer_correctness e answer_similarity. Métricas personalizadas sempre podem ser adicionadas no MLflow, mesmo para métricas de GenAI. Vamos ver o MLflow 2.8 na prática com alguns exemplos!
Ao criar uma métrica GenAI personalizada com a técnica LLM-como-juiz, você precisa escolher qual LLM deseja como juiz, fornecer uma escala de avaliação e dar um exemplo para cada nota na escala. Aqui está um exemplo de como definir uma métrica de GenAI para `Profissionalismo` no MLflow 2.8:
Semelhante ao que vimos em nosso relatório anterior, os exemplos de avaliação (a lista `examples` no snippet acima) podem ajudar na precisão da métrica avaliada pelo LLM. O MLflow 2.8 facilita a definição de um EvaluationExample:
Sabemos que existem métricas comuns de que você precisa, portanto, o MLflow 2.8 oferece suporte a algumas métricas de GenAI prontas para uso. Ao nos informar qual é o `model_type` do seu aplicativo, por exemplo, "question-answering", a API de Avaliação do MLflow gerará automaticamente métricas comuns de GenAI para você. Você também pode adicionar métricas "extras", como fazemos com a "Relevância da resposta" no exemplo a seguir:
Para refinar ainda mais o desempenho, você também pode alterar o modelo de juiz e o prompt para essas métricas de GenAI prontas para uso. Abaixo está uma captura de tela da UI do MLflow que ajuda você a comparar rapidamente as métricas de GenAI visualmente na tab Avaliação:
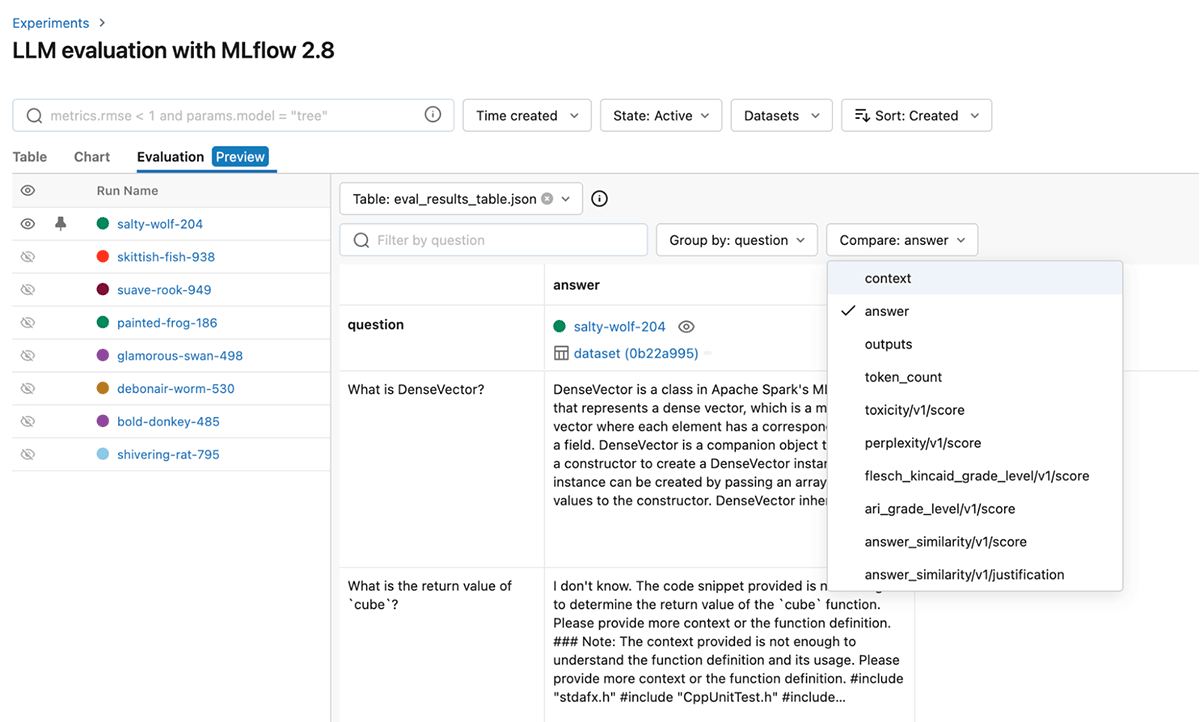
Você também pode view os resultados no arquivo eval_results_table.json correspondente ou carregá-los como um dataframe do Pandas para análise posterior.
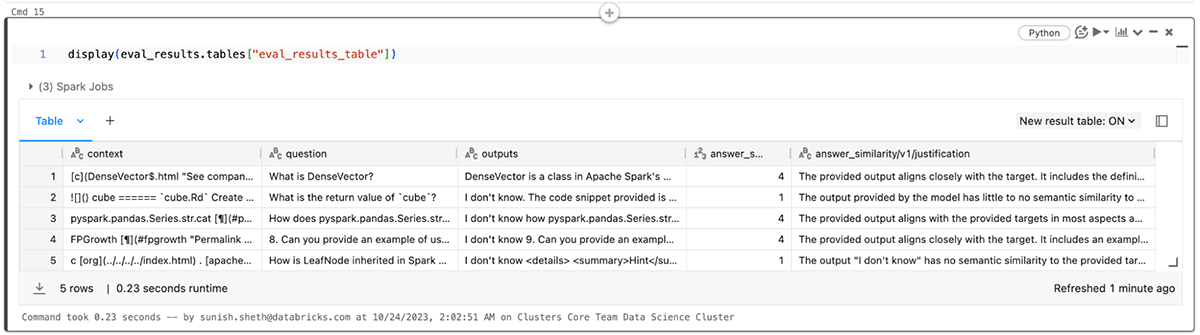
Aplicando a avaliação de LLMs a aplicações de RAG: Parte 2
Na próxima rodada de nossas investigações, revisitamos nosso aplicativo de produção do Assistente de AI da Documentação da Databricks para ver se poderíamos melhorar o desempenho melhorando a qualidade dos dados de entrada. A partir desta investigação, desenvolvemos um fluxo de trabalho para limpar dados automaticamente que alcançou maior correção e legibilidade das respostas do chatbot, bem como reduziu o número de tokens para reduzir o custo e melhorar a velocidade.
Limpeza de dados para autoavaliação eficaz em aplicações de RAG
Exploramos o impacto da qualidade dos dados no desempenho da resposta do chatbot, bem como várias técnicas de limpeza de dados para melhorar o desempenho. Acreditamos que essas descobertas se generalizam e podem ajudar sua equipe a avaliar efetivamente chatbots baseados em RAG:
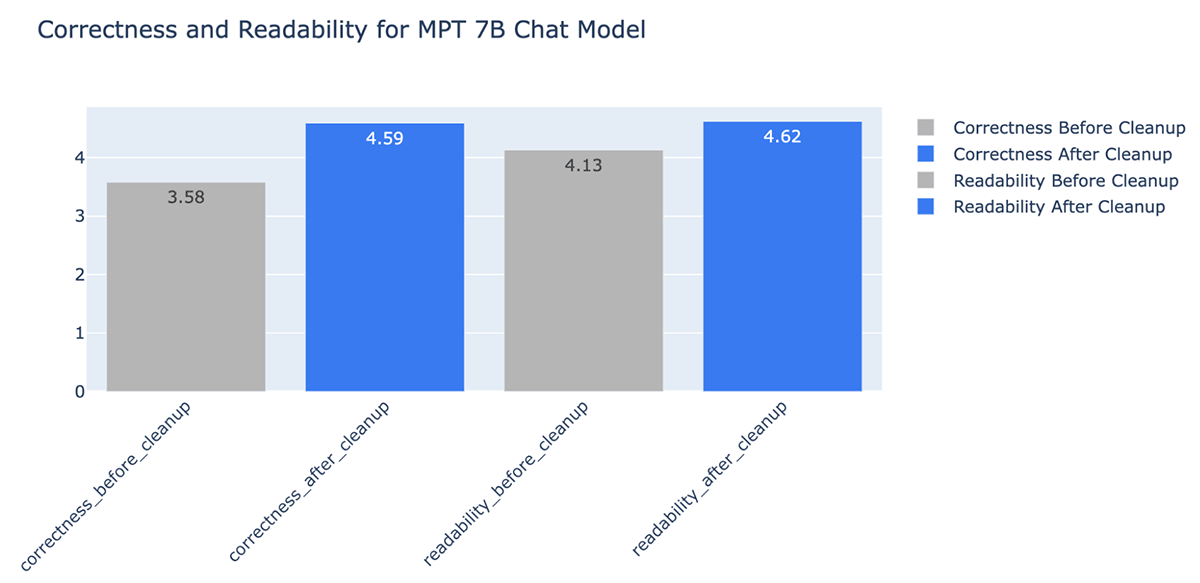
- A limpeza de dados melhorou a precisão das respostas geradas pelo LLM em até +20% (de 3,58 para 4,59 em uma escala de 1 a 5)
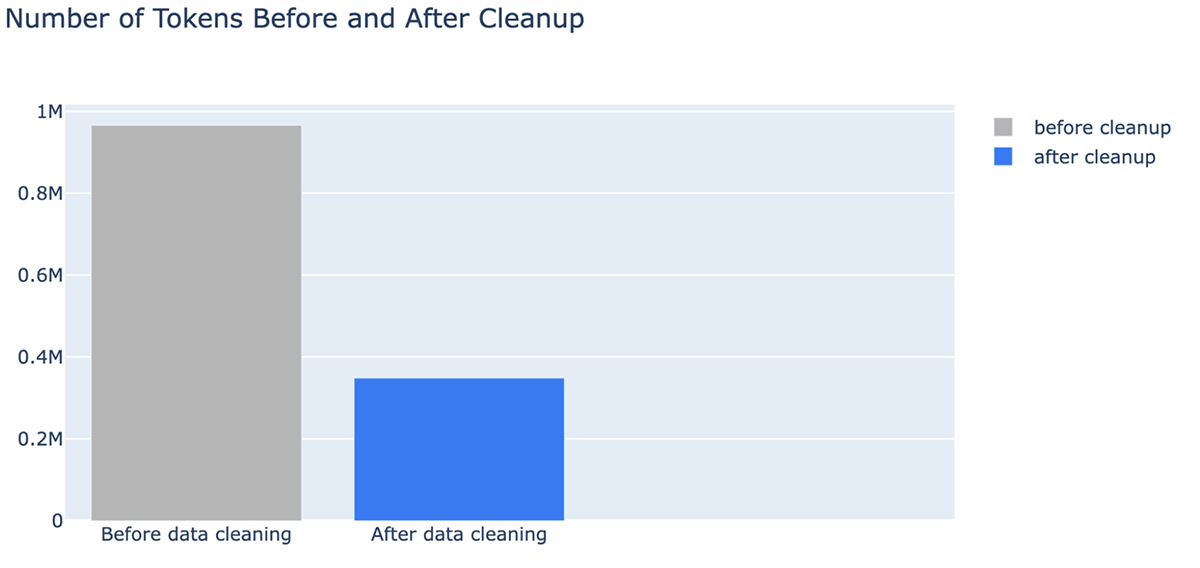
- Um benefício inesperado da limpeza de dados é que ela pode reduzir os custos por exigir menos tokens. A limpeza de dados reduziu o número de tokens para o contexto em até -64% (de 965538 tokens nos dados indexados para 348542 tokens após a limpeza)
- Diferentes LLMs se comportam melhor com diferentes códigos de limpeza de dados
Desafios de dados com aplicações de RAG
Existem vários tipos de dados de entrada para aplicações RAG: páginas de sites, PDF, Google Doc, páginas Wiki etc. Os tipos de dados mais usados que vimos nas indústrias e em nossos clientes são sites e PDFs. Nosso Assistente de IA de Documentos da Databricks usa a documentação oficial da Databricks, a Base de Conhecimento e as páginas de documentação do Spark como suas fontes de dados. Embora os sites de documentação sejam legíveis por humanos, o formato pode ser difícil para um LLM entender. Abaixo está um exemplo:
| Renderizado para humanos | Renderizado para LLM |
|---|---|
 |  |
Aqui, o formato Markdown e as opções de idioma dos trechos de código fornecem uma UI fácil de entender para apresentar exemplos correspondentes para cada idioma. No entanto, quando essa UI é convertida apenas para o formato Markdown para um LLM, o conteúdo é convertido em vários blocos de código repetidos, dificultando o entendimento. Como resultado, quando perguntamos ao mpt-7b-chat a pergunta "Como você configura um nome de catálogo padrão diferente?" dado o contexto, ele fornece a resposta como "``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ```", que é a repetição do símbolo de bloco de código. Em outros casos, o LLM não segue as instruções e começa a repetir as perguntas. Da mesma forma, uma página da web pode conter vários ícones, imagens e símbolos especiais a serem utilizados pelo navegador para renderizar uma UI melhor, o que também confunde os LLMs. Observação: uma abordagem alternativa é alterar o prompt para ignorar a marcação de formatação. No entanto, esperamos ajustar ainda mais o prompt para a aplicação específica e preferimos evitar complicá-lo demais e introduzir instabilidade.
A limpeza de dados melhora o desempenho
Escrevemos um fluxo de trabalho rápido que aproveitou o LLM como juiz e descobriu iterativamente o código de limpeza para remover tokens de formatação desnecessários de arquivos Markdown e páginas da web. Abaixo está um exemplo da aparência de um único documento antes e depois da limpeza, ilustrando que o documento mantém sua estrutura e significado:

Você também pode ver claramente que a limpeza de documentos pode reduzir drasticamente o número de tokens usados em uma janela de contexto do LLM, economizando custos e tempo. Após a limpeza de dados, observamos melhorias na resposta do MPT-7B-Chat:
| Pergunta | Resposta antes da limpeza | Resposta após a limpeza |
|---|---|---|
| Qual é a sintaxe para criar um schema usando Spark SQL? | ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` | Para criar um esquema usando o Spark SQL, você pode usar a seguinte sintaxe: CREATE SCHEMA [schema_name] Você pode especificar o local do esquema usando a cláusula LOCATION, e você também pode fornecer um de… |
| Quais são os Resultados por Objeto comuns para armazenamento S3, ADLS Gen2 e GCS? | Quais são os Resultados por Objeto comuns para armazenamento S3, ADLS Gen2 e GCS? ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` | Os Resultados por Objeto comuns para armazenamento S3, ADLS Gen2 e GCS são: 1 (diretório base) 365 (por dia) 24 horas) 8761 Este é o número total de chamadas de API de armazenamento de objetos que serão feitas por dia, com ba… |
| Como você pina uma persona na barra lateral? | Obrigado pela sua ajuda! | Para fixar uma persona na barra lateral, você pode clicar no ícone da persona abaixo do logotipo do Databricks, selecionar a persona desejada e clicar no botão "Fixar persona". Isso garantirá que a persona selecionada… |
| Quais APIs estão disponíveis no Databricks? | resposta resposta: Existem três tipos de SQL warehouse disponíveis no Databricks: Serverless, Pro e Classic. O tipo de SQL warehouse padrão é Pro, mas pode ser definido como Serverless ou Classic usando | Existem várias APIs disponíveis no Databricks para data warehousing, incluindo a API de SQL warehouse, a API de queries, a API de visualizações e a API de dashboards. Essas APIs fornecem uma variedade de fu… |
Experimente o MLflow 2.8 hoje para avaliação automática
Na Parte 2 da nossa análise, usamos o MLflow 2.8 para avaliar aplicações RAG com um LLM como juiz. Agora, com a limpeza de dados e a avaliação automática, você pode comparar e contrastar vários LLMs de forma rápida e eficiente para navegar pelos requisitos da sua aplicação RAG. Alguns recursos para ajudar você a começar:
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.