Criando aplicativos RAG de alta qualidade com a Databricks
Um novo conjunto de ferramentas para colocar aplicações de IA generativa em produção
por Patrick Wendell e Hanlin Tang
A Geração Aumentada por Recuperação (RAG) emergiu rapidamente como uma forma poderosa de incorporar dados proprietários e dados tempo-real em aplicativos de Modelos de Linguagem Grandes (LLM). Hoje, temos o prazer de anunciar o lançamento de um conjunto de ferramentas RAG para ajudar os usuários do Databricks a criar aplicativos LLM de produção e de alta qualidade usando seus dados corporativos.
Os LLMs ofereceram um grande avanço na capacidade de prototipar rapidamente novas aplicações. Mas, depois de trabalhar com milhares de empresas que desenvolvem aplicações RAG, descobrimos que o maior desafio delas é fazer com que essas aplicações atinjam a qualidade de produção. Para atender ao padrão de qualidade exigido para aplicativos voltados para o cliente, a saída de IA deve ser precisa, atual, ciente do contexto empresarial e segura.
Para alcançar alta qualidade com aplicativos RAG, os desenvolvedores precisam de ferramentas avançadas para entender a qualidade de seus dados e dos resultados do modelo, juntamente com uma plataforma subjacente que lhes permita combinar e otimizar todos os aspectos do processo RAG. O RAG envolve muitos componentes, como preparação de dados, modelos de recuperação, modelos de linguagem (SaaS ou de código aberto), pipelines de classificação e pós-processamento, engenharia de prompte treinamento de modelos com dados corporativos personalizados. O Databricks sempre se concentrou em combinar seus dados com técnicas de ML de ponta. Com o lançamento de hoje, estendemos essa filosofia para permitir que os clientes aproveitem seus dados na criação de aplicativos de AI de alta qualidade.
O lançamento de hoje inclui o Public Preview de:
- Um serviço de busca vetorial para potencializar a busca semântica em tabelas existentes no seu lakehouse.
- Disponibilização online de recursos e funções para oferecer contexto estruturado a aplicativos de RAG.
- Modelos de base totalmente gerenciado, que fornecem LLMs de base com pagamento por token.
- Uma interface flexível de monitoramento de qualidade para observar o desempenho de produção de aplicativos RAG.
- Um conjunto de ferramentas de desenvolvimento de LLM para comparar e avaliar vários LLMs.
Esses recursos foram projetados para lidar com os três maiores desafios que observamos na criação de aplicativos RAG de produção:
Desafio nº 1 - Fornecendo dados tempo-real para seu aplicativo RAG
As aplicações RAG combinam seus dados estruturados e não estruturados mais recentes para gerar respostas da mais alta qualidade e mais personalizadas. Mas manter a infraestrutura de serviço de dados online pode ser muito difícil e, historicamente, as empresas tiveram que unir vários sistemas e manter complexos pipeline de dados para carregar dados de central data lake para camadas de serviço personalizadas. Proteger importantes datasets também é muito difícil quando as cópias são distribuídas em diferentes pilhas de infraestrutura.
Com este lançamento, o Databricks oferece suporte nativo para o serviço e a indexação de seus dados para recuperação online. Para dados não estruturados (texto, imagens e vídeo), o AI Search indexará e servirá dados automaticamente de tabelas Delta, tornando-os acessíveis por meio de busca por similaridade semântica para aplicações RAG. Internamente, o AI Search gerencia falhas, lida com novas tentativas e otimiza o tamanho dos lotes para oferecer a você o melhor desempenho, throughput e custo. Para dados estruturados, o recurso and Function Serving oferece queries em escala de milissegundos de dados contextuais, como dados de usuário ou de account, que as empresas geralmente querem injetar em prompts para personalizá-los com base nas informações do usuário.
O Unity Catalog rastreia automaticamente a linhagem entre as cópias offline e online dos datasets servidos, tornando a depuração de problemas de qualidade de dados muito mais fácil. Ele também aplica de forma consistente as configurações de controle de acesso entre datasets online e offline, o que significa que as empresas podem auditar e controlar melhor quem está visualizando informações proprietárias confidenciais.
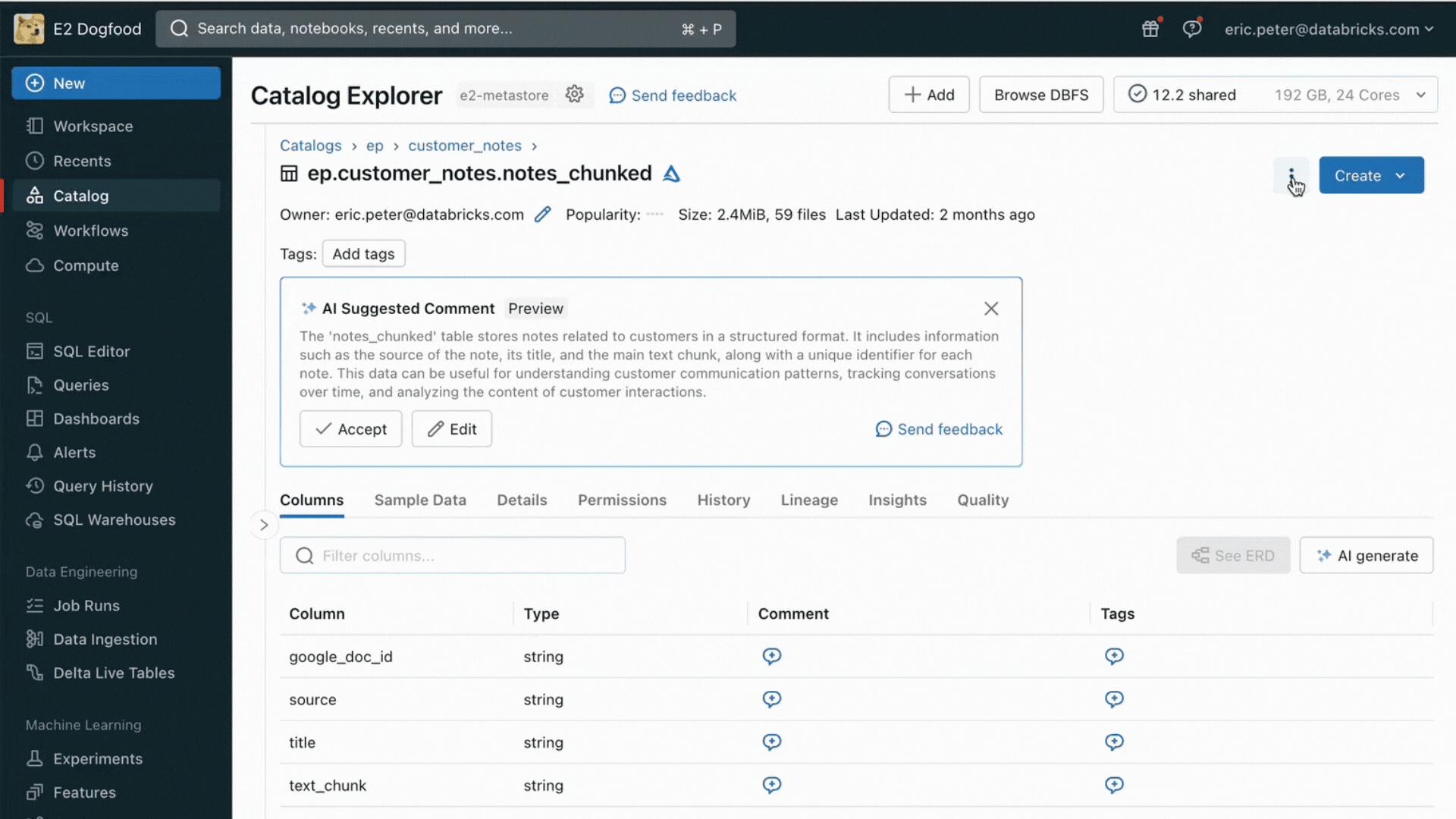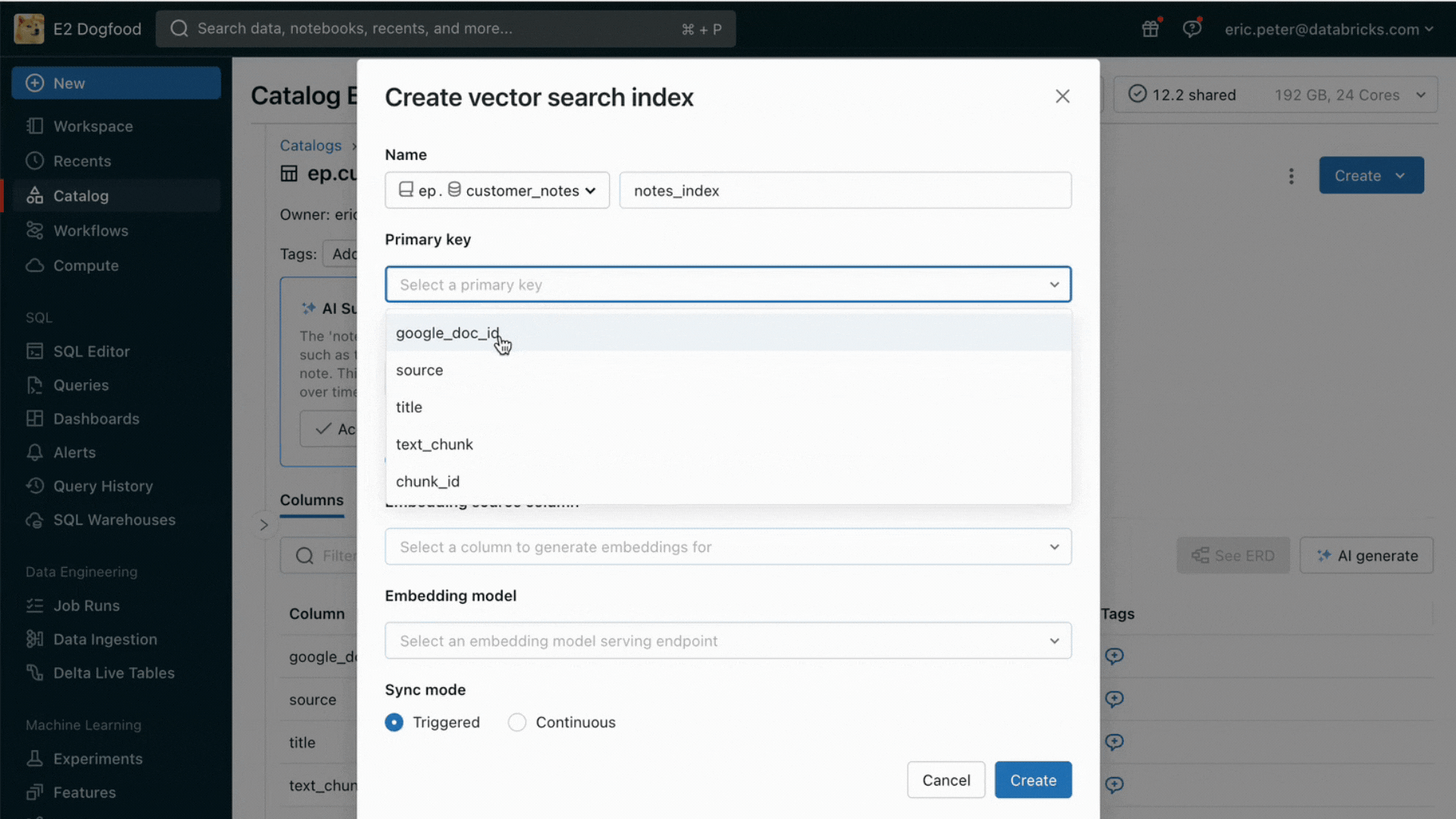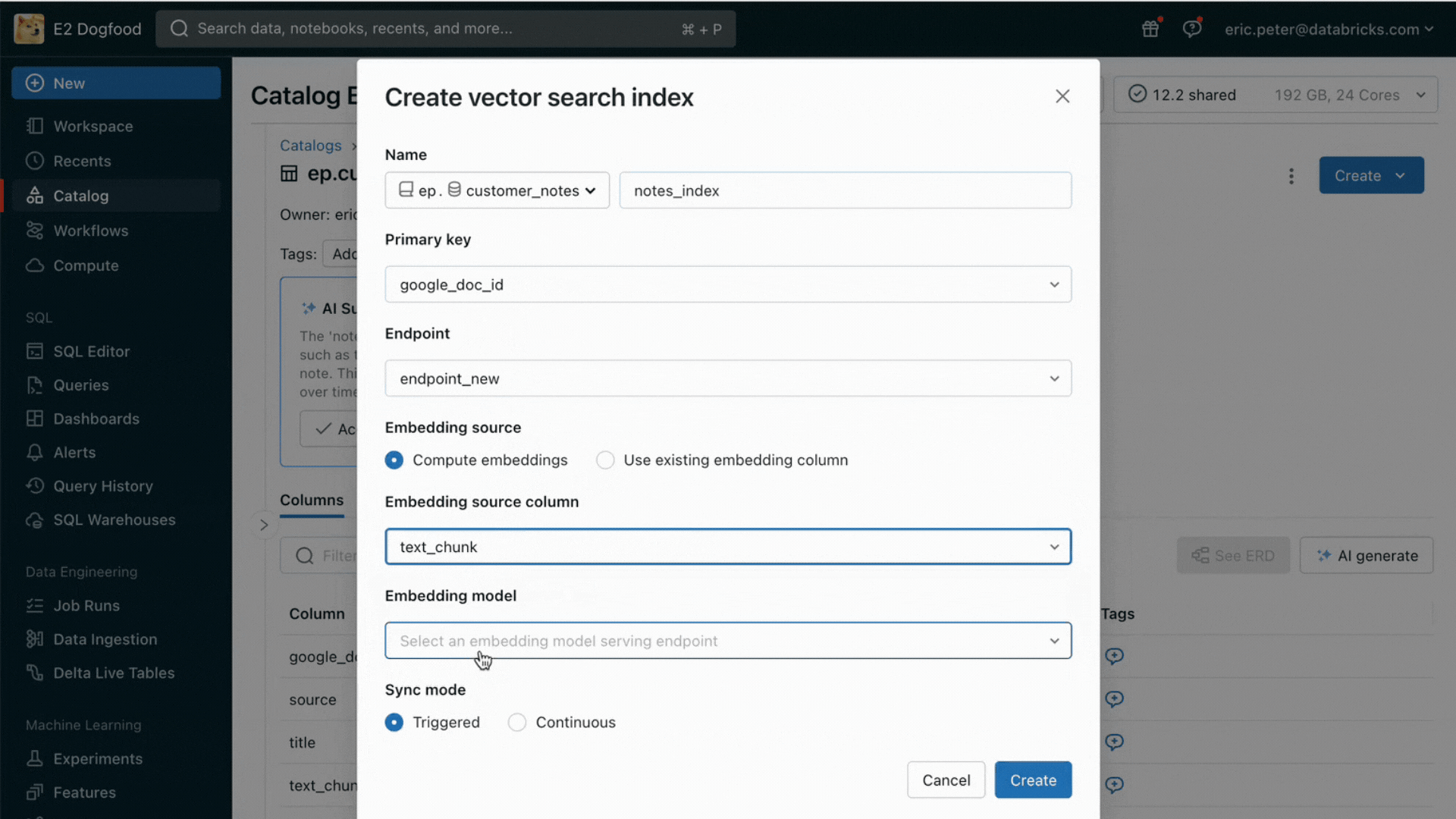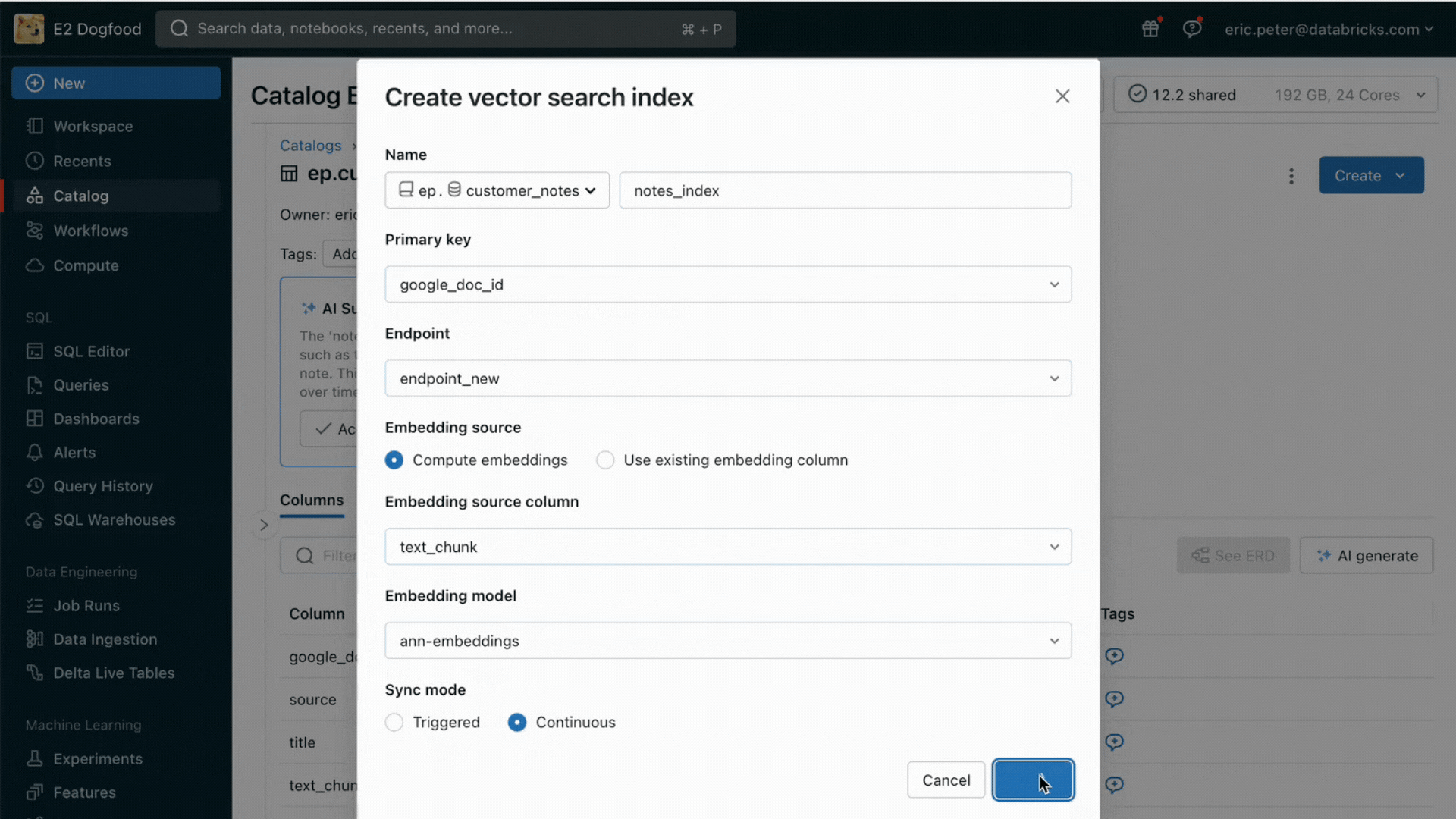
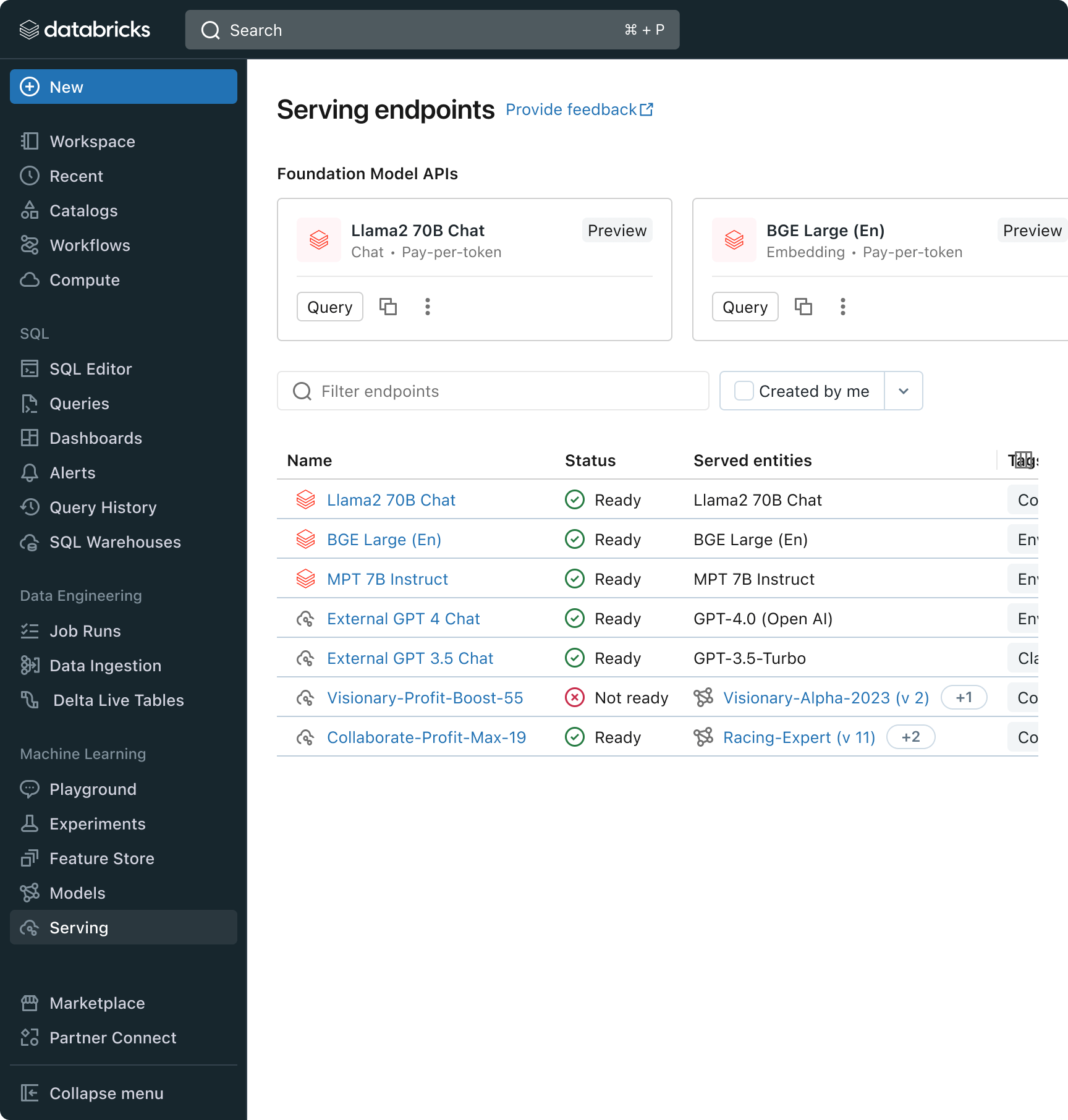
Desafio nº 2: Comparando, ajustando e servindo Modelos Fundamentais
Um dos principais determinantes da qualidade em uma aplicação RAG é a escolha do modelo LLM base. Comparar modelos pode ser difícil porque eles variam em várias dimensões, como capacidade de raciocínio, propensão a alucinações, tamanho da janela de contexto e custo de serviço. Alguns modelos também podem passar por um ajuste fino para aplicações específicas, o que pode melhorar ainda mais o desempenho e potencialmente reduzir os custos. Com novos modelos sendo lançados quase toda semana, comparar as permutações do modelo base para encontrar a melhor opção para uma aplicação específica pode ser extremamente trabalhoso. Para complicar ainda mais, os provedores de modelo geralmente têm APIs diferentes, o que dificulta muito a comparação rápida ou a preparação para o futuro de aplicações RAG.
Com este lançamento, o Databricks agora oferece um ambiente unificado para desenvolvimento e avaliação de LLMs, fornecendo um conjunto consistente de ferramentas entre famílias de modelos em uma plataforma agnóstica em nuvem. Os usuários do Databricks podem acessar os principais modelos do Azure OpenAI serviço, AWS Bedrock e Anthropic, modelos de código aberto como Llama 2 e MPT ou modelos totalmente personalizados e ajustados dos clientes. O novo AI Playground interativo permite conversar facilmente com esses modelos, enquanto nossa cadeia de ferramentas integrada com o MLflow possibilita comparações detalhadas, acompanhando as principais métricas, como toxicidade, latência e contagem de tokens. A comparação de modelos lado a lado no Playground ou MLflow permite que os clientes identifiquem o melhor modelo candidato para cada caso de uso, suportando até mesmo a avaliação do componente de recuperação.
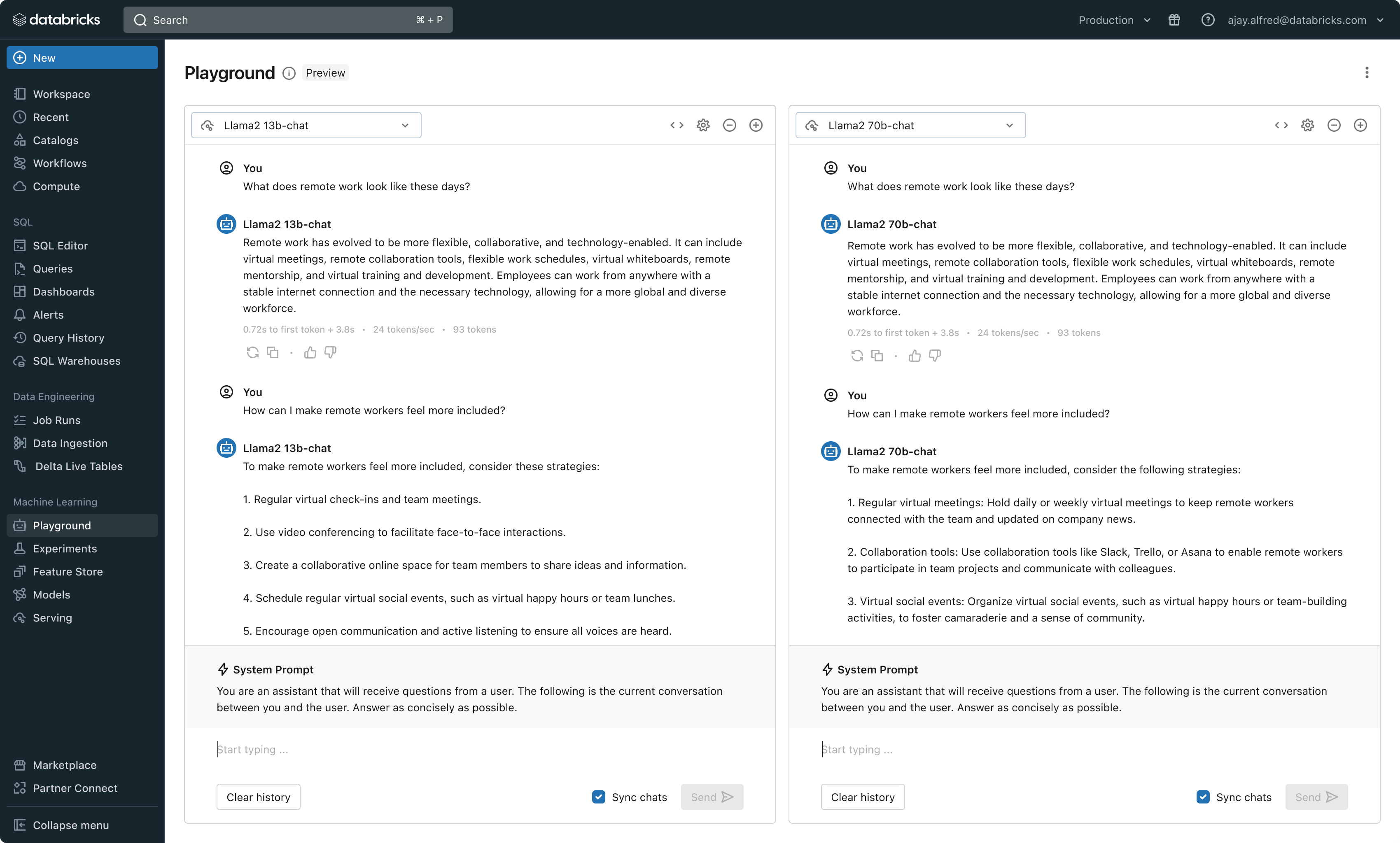
O Databricks também está lançando as APIs de Modelo de Base, um conjunto totalmente gerenciado de modelos LLM, incluindo as populares famílias de modelos Llama e MPT. As APIs de modelos fundacionais podem ser usadas com pagamento por token, reduzindo drasticamente o custo e aumentando a flexibilidade. Como as APIs de Foundation Model são servidas de dentro da infraestrutura da Databricks, os dados confidenciais não precisam transitar para serviços de terceiros.
Na prática, alcançar alta qualidade geralmente significa combinar modelos de base de acordo com os requisitos específicos de cada aplicação. A arquitetura do Model Serving do Databricks agora oferece uma interface unificada para implantar, governar e consultar qualquer tipo de LLM, seja um modelo totalmente personalizado, um modelo gerenciado pelo Databricks ou um modelo de fundação de terceiros. Essa flexibilidade permite que os clientes escolham o modelo certo para o job certo e estejam preparados para os avanços futuros no conjunto de modelos disponíveis.
Desafio nº 3: Garantindo qualidade e segurança em produção
Depois que uma aplicação de LLM é implantada, pode ser difícil saber o quão bem ela está funcionando. Ao contrário do software tradicional, as aplicações baseadas em linguagem não têm uma única resposta correta ou condições óbvias de “erro”. Isso significa que entender a qualidade (quão bem isso está funcionando?) ou o que constitui um resultado anômalo, inseguro ou tóxico (isto é seguro?) não é trivial. Na Databricks, vimos muitos clientes hesitarem em implementar aplicações de RAG porque não têm certeza se a qualidade observada em um pequeno protótipo interno se traduzirá para sua base de usuários em grande escala.
Incluído nesta versão, o Lakehouse Monitoring oferece uma solução de monitoramento de qualidade totalmente gerenciada para aplicações RAG. O Lakehouse Monitoring analisa automaticamente os resultados de aplicativos em busca de conteúdo tóxico, alucinado ou inseguro. Esses dados podem então alimentar dashboards, alertas ou outros pipelines de dados downstream para ações subsequentes. Como o monitoramento é integrado à linhagem de datasets e modelos, os desenvolvedores podem diagnosticar rapidamente erros relacionados a, por exemplo, pipelines de dados desatualizados ou modelos que mudaram de comportamento inesperadamente.
O monitoramento não se trata apenas de segurança, mas também de qualidade. O Monitoramento do Lakehouse pode incorporar conceitos no nível do aplicativo, como feedback do usuário no estilo “gostei/não gostei”, ou até mesmo métricas derivadas, como a “taxa de aceitação do usuário” (a frequência com que um usuário final aceita as recomendações geradas por AI). Em nossa experiência, medir as métricas do usuário de ponta a ponta reforça substancialmente a confiança das empresas de que as aplicações de RAG estão funcionando bem em produção. Os pipelines de monitoramento também são totalmente gerenciados pelo Databricks, para que os desenvolvedores possam dedicar tempo a seus aplicativos em vez de gerenciar a infraestrutura de observabilidade.
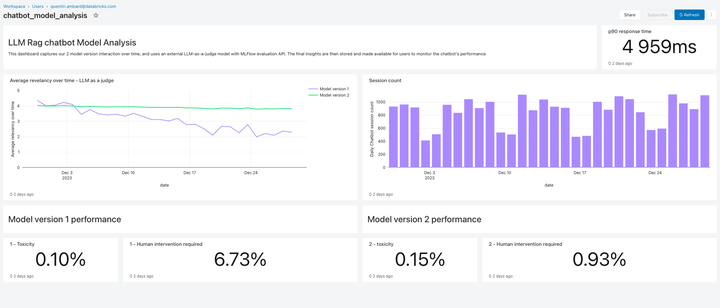
Os recursos de monitoramento desta versão são apenas o começo. Fique ligado para muito mais!
Passos seguintes
Temos publicações detalhadas no blog ao longo desta semana e da próxima que abordam em detalhes as melhores práticas de implementação. Então, volte ao nosso blog da Databricks, explore nossos produtos com a nova demonstração de RAG, assista ao Webinar de IA Generativa sob demanda da Databricks, faça um treinamento em IA Generativa com nossa Trilha de Aprendizagem para Engenheiro de Gen AI e confira uma demonstração rápida em vídeo do conjunto de ferramentas RAG em ação:
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.