Arquitetura de Liquid Clustering da Arctic Wolf otimizada para escala de petabytes
- A Arctic Wolf processa mais de 1 trilhão de eventos de segurança por dia, gerando mais de 260 bilhões de observações enriquecidas mantidas em um Delta Lake em escala de petabytes. Nossa arquitetura foi projetada para fornecer acesso quase em tempo real a esses dados.
- Recentemente, migramos para o uso de liquid clustering em tabelas gerenciadas do Unity Catalog com Otimização Preditiva (PO), complementando nossas tabelas externas particionadas com clusterização incremental e ciente da carga de trabalho para um melhor desempenho de query.
- Juntos, o liquid clustering e a PO mantêm as tabelas ajustadas para consultas até 8x mais rápidas e melhoram o frescor dos dados, de horas para minutos.
Todos os dias, a Arctic Wolf processa mais de um trilhão de eventos, extraindo bilhões de registros enriquecidos para obter percepções relevantes para a segurança. Isso equivale a mais de 60 TB de telemetria compactada, impulsionando a detecção e resposta a ameaças orientadas por IA, 24x7, sem interrupções. Para potencializar a busca por ameaças em tempo real, precisávamos que esses dados estivessem disponíveis para os clientes e para o Centro de Operações de Segurança o mais rápido possível, com o objetivo de que a maioria das queries retornasse em 15 segundos.
Historicamente, tivemos que usar outros datastores rápidos para fornecer acesso a dados recentes, pois o particionamento + z-ordering não conseguiam acompanhar. Quando detectamos atividade suspeita, nossa equipe pode analisar imediatamente três meses de contexto histórico para entender os padrões de ataque, o movimento lateral e todo o escopo do comprometimento. Essa análise histórica em tempo real de mais de 3,8 PB de dados compactados é fundamental na caça a ameaças moderna: a diferença entre conter uma violação em horas versus dias pode significar milhões em danos evitados.
Quando cada segundo conta, a velocidade e a atualidade dos dados importam. A Arctic Wolf precisava acelerar o acesso a datasets massivos sem aumentar os custos de ingestão ou adicionar complexidade. O desafio? As investigações eram lentas devido à alta E/S de arquivos e a dados desatualizados. Ao repensar a forma como os dados são organizados, nossa arquitetura gerencia eficientemente a distorção de dados multi-tenant, em que uma pequena fração de clientes gera a maior parte dos eventos, e também acomoda dados que chegam com atraso, podendo aparecer até semanas após a ingestão inicial. Os benefícios mensuráveis incluem a redução da contagem de arquivos de mais de 4 milhões para 2 milhões, query times reduzidos em aproximadamente 50% em todos os percentis e a redução das queries de 90 dias de 51 segundos para apenas 6,6 segundos. A atualidade dos dados melhorou de horas para minutos, permitindo o acesso à telemetria de segurança quase imediatamente.
Continue lendo para saber como o liquid clustering e as tabelas gerenciadas do Unity Catalog tornaram isso possível, proporcionando desempenho consistente e insights quase em tempo real em grande escala.
Gargalos legados: por que a Arctic Wolf reconstruiu
Nossa tabela legada, particionada por data-hora de ocorrência e z-ordered por identificador do tenant, não podia ser consultada quase em tempo real devido ao grande número de arquivos pequenos divididos entre as partições. Além disso, os dados só ficavam disponíveis para períodos anteriores às últimas 24 horas, pois tínhamos que executar o comando OPTIMIZE com ordenação Z antes que os dados pudessem ser consultados.
Mesmo assim, os problemas de desempenho persistiram devido à chegada tardia de dados. Isso ocorre quando um sistema fica offline antes de transmitir os dados, o que resultaria em novos dados sendo inseridos em partições mais antigas e impactando o desempenho.
Dados desatualizados nos cegam. Esse atraso é a diferença entre conter um adversário e permitir que ele se mova lateralmente.
Para mitigar esses desafios de desempenho e fornecer a atualização de dados de que precisávamos, duplicamos nossos dados quentes em um acelerador de dados e os combinamos em consultas com dados do nosso Data Lake para atender aos nossos requisitos de negócios. Este sistema era caro para sua execução e exigia um esforço de engenharia significativo para sua manutenção.
Para resolver os desafios do uso de um acelerador de dados, redesenhamos nossa disposição de dados para distribuir os dados de maneira uniforme e dar suporte a dados de chegada tardia. Isso otimiza o desempenho de queries e permite o acesso quase em tempo real para casos de uso atuais e emergentes de IA agentiva.
Construindo a base de dados de transmissão com clusters líquidos
Com nossa nova arquitetura, nosso key objetivo é poder realizar query os dados mais recentes, fornecer desempenho de query consistente para clientes de diferentes portes, enquanto as queries devem retornar em segundos.
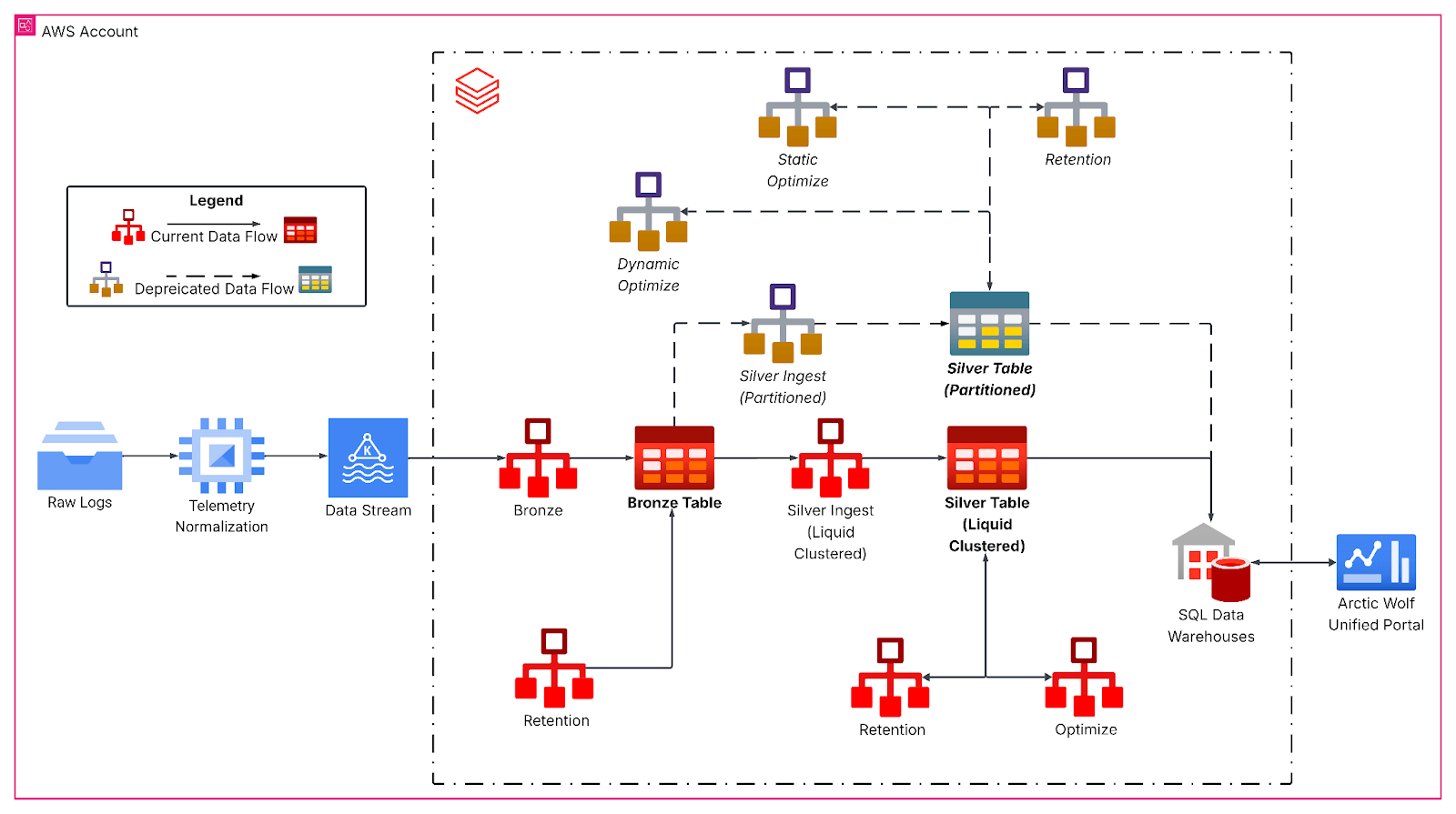
O pipeline reprojetado segue uma arquitetura medalhão, começando com a ingestão contínua do Kafka em uma camada bronze para dados brutos de eventos. Em seguida, Jobs horários de transmissão estructurada achatam os payloads JSON aninhados e gravam em tabelas silver com liquid clustering, formando a base analítica principal. Aqui, as transformações de bronze para silver lidam com a evolução do esquema, geram colunas temporais derivadas e preparam os dados para cargas de trabalho analíticas downstream com SLAs de latência rigorosos.
O Liquid Clustering substituiu esquemas de particionamento rígidos por chaves de clustering multidimensionais cientes da carga de trabalho e alinhadas aos padrões de consulta, especificamente por identificador de locatário, granularidade de data, tamanho da tabela e características de chegada dos dados. Isso tornou os dados mais distribuídos uniformemente e, em nosso caso, aumentou o tamanho médio dos arquivos para mais de 1 GB, reduzindo drasticamente o número de arquivos lidos durante típicas queries em janelas de tempo para nossa tabela.
Análise Aprofundada: clusters na Gravação
Além disso, nossos jobs de transmissão estructurada utilizam a clusterização na gravação para manter a disposição do arquivo à medida que novos dados chegam. Funciona como uma operação OPTIMIZE localizada, aplicando o clustering apenas aos dados recém-ingeridos. Assim, os dados ingeridos já estão otimizados. No entanto, se os lotes de ingestão forem muito pequenos, eles produzem muitos arquivos pequenos, mas bem clusterizados, que ainda precisam ser clusterizados durante um OPTIMIZE global para alcançar uma disposição de dados ideal. Em contraste, se o tamanho do lote na ingestão se aproximar do tamanho do lote necessário pelo Optimize global, uma otimização adicional geralmente é desnecessária.
Para workloads que fazem a ingestão de volumes de dados muito grandes (por exemplo, terabytes), recomendamos o processamento em lotes na origem, como o uso de foreachBatch com maxBytesPerTrigger, para garantir um clustering e uma disposição de arquivo eficientes. Com maxBytesPerTrigger, podemos controlar o tamanho do lote, eliminando muitas pequenas ilhas clusterizadas que exigiriam reconciliação por meio da operação OPTIMIZE. Com tamanhos próximos aos que a operação OPTIMIZE processa, conseguimos criar lotes (batches) ideais para reduzir o trabalho adicional exigido pelo OPTIMIZE.
Impacto na Security analítica da Arctic Wolf
A migração da Arctic Wolf para o Liquid Clustering proporcionou melhorias substanciais e quantificáveis em desempenho, atualização de dados e eficiência operacional. As Tabelas Gerenciadas do UC com Otimização Preditiva também reduziram a necessidade de programar manutenções.
O número de arquivos caiu de mais de 4 milhões para 2 milhões, minimizando a E/S de arquivos durante as queries e mantendo uma boa qualidade do cluster. Como resultado, o desempenho das querys melhorou drasticamente, permitindo que os analistas de segurança investigassem incidentes mais rapidamente: ~50% mais rápido em todos os percentis e ~90% mais rápido para um grande número de nossos clientes, com as querys de 90 dias caindo de 51 segundos para 6,6 segundos.
Ao implementar o clustering na gravação, reduzimos a atualidade dos dados de horas para minutos, acelerando o tempo para geração de percepções em aproximadamente 90%. Essa melhoria permite a detecção de ameaças quase em tempo real no Data Lake da Arctic Wolf.
A transição para a clusterização líquida e as tabelas gerenciadas do Unity Catalog eliminou o particionamento legado, reduziu a dívida técnica e desbloqueou recursos avançados de governança e desempenho. Com uma arquitetura capaz de processar e consultar mais de 260 bilhões de linhas diariamente, fornecemos acesso mais rápido e eficiente a dados de segurança críticos de todas essas fontes. Combinado com nossa Equipe Concierge Security® 24/7 e a detecção de ameaças em tempo real, isso permite uma resposta e mitigação de ameaças mais rápidas e precisas. Esses diferenciais ajudam nossos clientes a alcançar uma postura de segurança mais forte e ágil e maior confiança na capacidade da Arctic Wolf de proteger seus ambientes e apoiar o sucesso contínuo dos negócios.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.