Melhores Práticas para Gerenciamento de Custos no Databricks
por Tomasz Bacewicz e Greg Wood
Este blog faz parte da nossa série Admin Essentials, onde focaremos em tópicos importantes para quem gerencia e mantém ambientes Databricks. Fique atento a blogs adicionais sobre outros tópicos e veja nossos blogs anteriores sobre as melhores práticas de organização funcional de workspace no Databricks e administração de workspace!
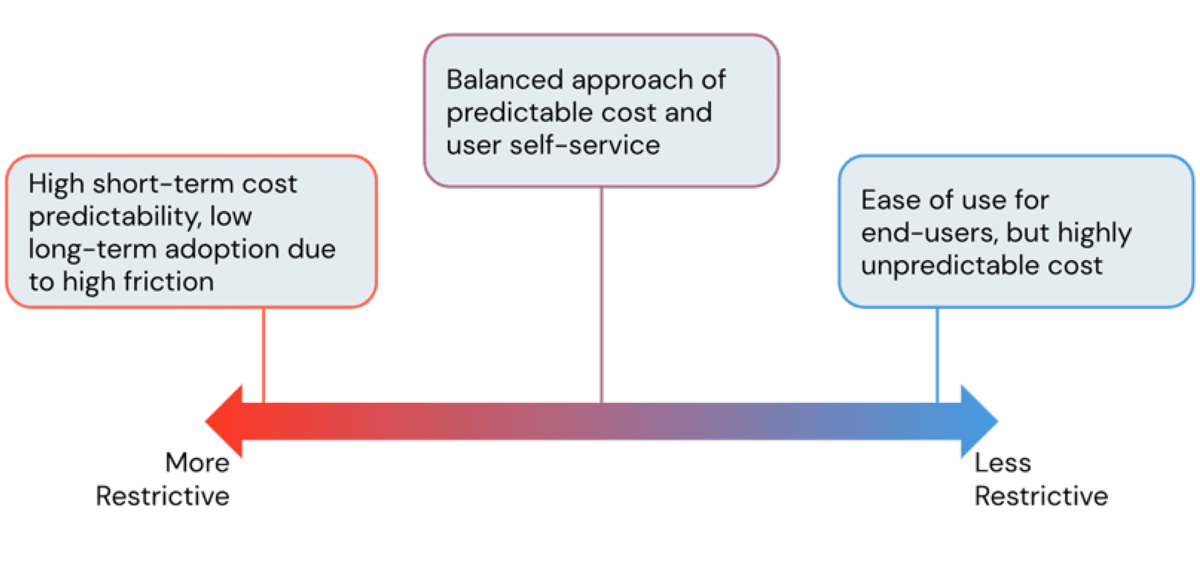
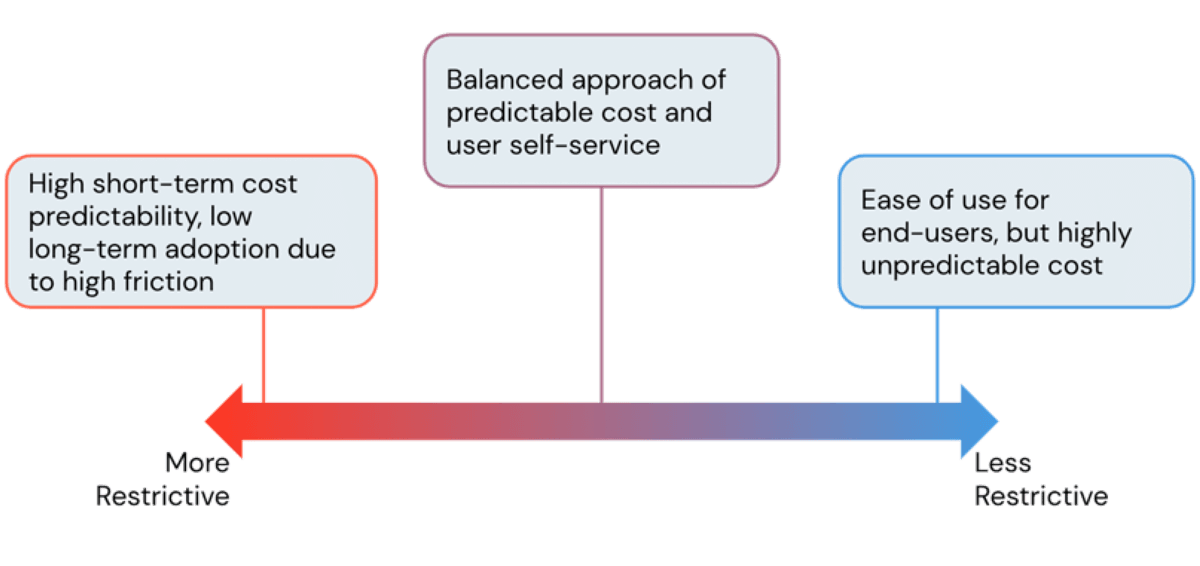
Uma das principais vantagens de usar uma plataforma em nuvem é sua flexibilidade. A Databricks Lakehouse Platform oferece aos usuários acesso fácil a computação quase instantânea e escalável horizontalmente. No entanto, com essa facilidade de criar recursos de computação, surge o risco de custos de nuvem dispararem quando não são gerenciados e sem salvaguardas. Como administradores, estamos sempre buscando o equilíbrio perfeito entre evitar custos exorbitantes de infraestrutura e, ao mesmo tempo, permitir que os usuários trabalhem sem atritos desnecessários. Neste blog, discutiremos as ferramentas de administração do Databricks para encontrar esse equilíbrio e controlar os custos sem limitar a produtividade do usuário.
{kind=link}
O que é um DBU?
Antes de mergulharmos nos controles de custo disponíveis na plataforma Databricks, é importante primeiro entender a base de custo para executar uma carga de trabalho. Uma Databricks Unit (DBU) é a unidade subjacente de consumo dentro da plataforma. Com exceção de um SQL Warehouse, a quantidade de DBUs consumidos é baseada no número de nós e na potência computacional dos tipos de instância de VM subjacentes que fazem parte do cluster respectivo (como os SQL warehouses são essencialmente um grupo de clusters, a taxa de DBU é a soma das taxas de DBU dos clusters que compõem o endpoint). No nível mais alto, cada nuvem terá taxas de DBU ligeiramente diferentes para clusters semelhantes (já que os tipos de nó variam entre as nuvens), mas o site Databricks possui calculadoras de DBU para cada provedor de nuvem compatível (AWS | Azure | GCP).
Para converter o uso de DBU em valores em dólar, você precisará da taxa de DBU do cluster, bem como do tipo de carga de trabalho que gerou o DBU respectivo (ex. Tarefa Automatizada, Computação de Propósito Geral, Delta Live Tables, Computação SQL, Computação Serverless) e do nível do plano de assinatura (Standard e Premium para Azure e GCP; Standard, Premium e Enterprise para AWS). Por exemplo, um workspace Databricks Enterprise tem uma taxa de lista de DBU de Tarefas de 20 centavos/DBU na AWS. Com um tipo de instância que roda a 3 DBU/hora, um cluster de tarefas de 4 nós seria cobrado a US$ 2,40 (US$ 0,2 * 3 * 4) por uma hora. As calculadoras de DBU podem ser usadas para calcular os encargos totais e os preços de lista são resumidos em uma matriz específica da nuvem, incluindo SKU e nível (AWS | Azure | GCP).
Como os custos são calculados através do uso de recursos de computação, e mais especificamente clusters, é vital gerenciar workspaces Databricks através de políticas de cluster. A próxima seção discutirá como diferentes atributos de políticas de cluster podem restringir o consumo de DBU e gerenciar efetivamente os custos da plataforma. As seções seguintes também revisarão alguns dos custos de nuvem subjacentes a serem considerados, bem como como monitorar o uso e a fatura do Databricks.
Gerenciando custos através de políticas de cluster
O que são políticas de cluster?
Uma política de cluster permite que um administrador controle o conjunto de configurações disponíveis ao criar um novo cluster, e essas políticas podem ser atribuídas a usuários individuais ou grupos de usuários. Por padrão, todos os usuários têm a permissão "permitir criação irrestrita de cluster" dentro de um workspace. Essa permissão raramente deve ser usada, pois permite que o usuário crie clusters sem restrições fora das políticas atribuídas, potencialmente levando a custos não gerenciados e descontrolados.
Dentro de uma política, um administrador pode restringir cada configuração através de um valor fixo imutável, um intervalo de valores mais permissivo e regex, ou um valor padrão completamente aberto. As políticas limitam efetivamente a quantidade de DBUs que podem ser consumidos por um único cluster através de restrições em tudo, desde configurações mais granulares, como tipos de instância de VM, até atributos "sintéticos" de nível mais alto, como o máximo de DBUs permitidos por hora ou tipos de carga de trabalho do cluster.
Embora à primeira vista possa parecer que clusters mais restritivos levam a custos mais baixos, isso nem sempre é o caso. Políticas muito restritivas levam a clusters que não conseguem concluir tarefas em tempo hábil, resultando em custos mais altos de trabalhos de longa execução. Portanto, é imperativo adotar uma abordagem orientada por casos de uso ao formular políticas de cluster, fornecendo às equipes a quantidade certa de poder computacional para suas cargas de trabalho. Para ajudar com isso, Databricks oferece recursos de desempenho, como runtimes Apache Spark otimizados e, mais notavelmente, o motor Photon, levando à economia de custos através de processamento mais rápido. Discutiremos políticas para runtimes em uma seção posterior, mas primeiro vamos começar com políticas que gerenciam a escalabilidade horizontal.
Limites de contagem de nós, escalabilidade automática e término automático
Uma preocupação comum em relação aos custos de computação são clusters subutilizados ou ociosos. Databricks oferece recursos de escalabilidade automática e término automático para aliviar essas preocupações dinamicamente e sem intervenção direta do usuário. Esses recursos podem ser aplicados através de políticas sem prejudicar os recursos computacionais disponíveis para o usuário.
Limites de contagem de nós e escalabilidade automática
As políticas podem impor que o recurso de escalabilidade automática do cluster seja ativado com um número mínimo definido de nós de trabalho. Por exemplo, uma política como a abaixo garantirá que a escalabilidade automática seja usada e permitirá que um usuário tenha um cluster com até 10 nós de trabalho, mas apenas quando eles forem necessários:
Como o tipo de imposição é "range" na contagem máxima de workers, ele pode ser alterado para um valor menor que 10 durante a criação. A contagem mínima de workers, no entanto, é definida como "fixed" para um valor de um, de modo que o cluster sempre escalará para apenas um worker quando estiver subutilizado, garantindo economia de custos em computação. Um campo adicional mostrado aqui é "defaultValue" que, como o nome sugere, define um valor padrão da quantidade máxima de workers na página de configuração do cluster. Isso é útil para reduzir o número máximo de workers em um cluster por padrão, para que o criador tenha que ser deliberado ao permitir que um cluster escale até 10 nós.
Compreender os casos de uso ao criar e atribuir políticas é vital em relação aos limites de contagem de nós e se a escalabilidade automática deve ser imposta. Por exemplo, impor escalabilidade automática funciona bem para:
- Clusters de computação compartilhados de propósito geral: uma equipe pode compartilhar um cluster para análise ad-hoc e trabalhos experimentais ou cargas de trabalho de machine learning.
- Trabalhos em lote de longa execução com complexidade variável: os trabalhos podem alavancar a escalabilidade automática para que o cluster escale de acordo com o grau de recursos necessários.
Observe que trabalhos que usam escalabilidade automática não devem ter sensibilidade ao tempo, pois escalar o cluster para cima pode atrasar a conclusão devido ao tempo de inicialização do nó. Para ajudar a aliviar isso, use um instance pool sempre que possível.
Cargas de trabalho de streaming padrão não puderam se beneficiar do auto-scaling historicamente; elas simplesmente escalavam para o número máximo de nós e permaneciam lá durante a execução do job. Uma opção mais pronta para produção para equipes que trabalham nesses tipos de cargas de trabalho é aproveitar o Delta Live Tables e o auto-scaling aprimorado (cargas de trabalho DLT podem ser impostas com a política "cluster_type" discutida posteriormente neste blog). Apesar do DLT ter sido desenvolvido com cargas de trabalho de streaming em mente, ele é igualmente aplicável para pipelines em batch ao aproveitar a opção Trigger.AvailableNow, permitindo atualizações incrementais das tabelas de destino.
Outra configuração comum de políticas de dimensionamento de cluster é a política de nó único. Clusters de nó único podem ser úteis para novos usuários que buscam explorar a plataforma, equipes de ciência de dados que utilizam bibliotecas de ML não distribuídas, bem como quaisquer usuários que precisam realizar análise exploratória de dados leve. Conforme descrito no exemplo de política de cluster de nó único, as políticas podem ser restritas para aproveitar um pool de instâncias específico. Consequentemente, a equipe designada a esta política terá um limite na quantidade de clusters de nó único que podem criar, com base na configuração de capacidade máxima do pool.
Auto-terminação
Outro atributo que pode ser definido ao criar um cluster na plataforma Databricks é o tempo de auto-terminação, que desliga um cluster após um período definido de inatividade. Períodos de inatividade são definidos pela falta de qualquer tipo de atividade no cluster, como jobs Spark, Structured Streaming ou chamadas JDBC. Atividades que não são consideradas atividades no cluster incluem a criação de uma conexão SSH no cluster e a execução de comandos bash.
A janela de auto-terminação mais comum é de uma hora. Como exemplo, aqui está a política definida em uma janela fixa de uma hora:
Neste exemplo, o atributo "hidden" também é adicionado a este controle, o que oculta o widget da página de configuração do cluster do usuário. Este atributo é aplicável apenas a clusters all-purpose, pois clusters de jobs e DLT serão automaticamente desligados quando todas as tarefas atribuídas a eles forem concluídas.
Runtimes de Cluster e Photon
Os Runtimes do Databricks são uma parte importante da otimização de desempenho no Databricks; os clientes frequentemente veem um benefício automático ao mudar para um cluster executando um runtime mais recente sem muitas outras alterações em sua configuração. Para um administrador que cria políticas de cluster, educar os criadores de cluster sobre os efeitos de executar um runtime mais recente é valioso para economia de custos. À medida que os usuários migram para runtimes mais recentes, runtimes antigos podem ser descontinuados e restringidos por meio de políticas. Para um exemplo rápido, aqui está o atributo "spark_version" que restringe os usuários a apenas DB Runtimes das versões 11.0 ou 11.1.
No entanto, esta política pode ser tornada mais flexível permitindo outras versões, runtimes de ML, runtimes Photon ou runtimes de GPU expandindo a lista de permissões ou usando regex.
O outro recurso de runtime a ser considerado ao otimizar o desempenho para reduzir custos é o uso do nosso motor Photon vetorizado. O Photon acelera inteligentemente partes de uma carga de trabalho por meio de um motor Spark vetorizado com o qual os clientes veem um aumento de 3x a 8x no desempenho. O aumento massivo no desempenho leva a jobs mais rápidos e, consequentemente, a custos totais mais baixos.
Tipos de instância de nuvem e instâncias spot
Durante a criação do cluster, os tipos de instância de VM podem ser selecionados separadamente para o nó driver e os nós worker. Os tipos de instância disponíveis têm uma taxa DBU calculada diferente e podem ser encontrados nas páginas de estimativa de preços do Databricks para cada nuvem respectiva (AWS, Azure, GCP). Por exemplo, na AWS, o tipo de instância m4.large com dois núcleos e 8 GB de memória consome 0,4 DBUs por hora, enquanto um tipo de instância m4.16xlarge com 64 núcleos e 256 GB de memória consome 12 DBUs por hora em modo de computação all-purpose. Com uma gama tão grande de uso de DBU entre os recursos de computação, é crucial restringir este atributo por meio de uma política.
Os tipos de instância de nuvem podem ser controlados de forma mais conveniente pelo tipo "allowlist" ou, de outra forma, pelo tipo "fixed" para permitir o uso de apenas um tipo de instância. O exemplo abaixo mostra o atributo "node_type_id", que define uma política nos tipos de nó worker disponíveis para o usuário, enquanto "driver_node_type_id" define uma política no tipo de nó driver.
Como administrador que cria essas políticas, é importante ter uma ideia do tipo de cargas de trabalho que cada equipe está executando e atribuir as políticas corretas apropriadamente. Cargas de trabalho com pequenas quantidades de dados devem exigir apenas tipos de instância com pouca memória, enquanto o treinamento de modelos de deep learning se beneficiaria mais de clusters de GPU, que geralmente consomem mais DBUs. Em última análise, restringir tipos de instância pode ser um ato de equilíbrio. Quando uma equipe precisa executar cargas de trabalho que exigem mais recursos do que os disponíveis devido a restrições de política, o job pode levar mais tempo para ser concluído e, consequentemente, aumentar os custos. Existem algumas práticas recomendadas a serem seguidas ao configurar um cluster para uma carga de trabalho definida. Por exemplo, escalar verticalmente (usando tipos de instância mais poderosos) em vez de escalar horizontalmente (adicionando mais nós) é recomendado para cargas de trabalho complexas que consistem em muitas transformações amplas que exigem embaralhamento de dados. Dito isso, equipes com menos experiência devem ter políticas restritas a tipos de instância menores, pois VMs desnecessariamente poderosas não fornecerão muito benefício para cargas de trabalho mais comuns e menos complexas.
Uma capacidade de economia de custos relativamente nova da plataforma Databricks é a capacidade de usar VMs habilitadas para AWS Graviton, que são construídas na arquitetura do conjunto de instruções Arm64. Com base em estudos fornecidos pela AWS, além de benchmarks executados com Databricks usando Photon, essas instâncias habilitadas para Graviton têm algumas das melhores relações preço/desempenho disponíveis no conjunto de tipos de instância EC2 da AWS.
Instâncias Spot
O Databricks oferece outra configuração que pode economizar custos especificamente nos custos de computação de VM subjacentes com instâncias spot (a opção disponível por meio do Databricks no GCP usa instâncias preemptíveis, que são semelhantes às instâncias spot). Instâncias spot são VMs sobressalentes oferecidas pelo provedor de nuvem subjacente, que são colocadas em leilão em um mercado ao vivo. Essas instâncias podem permitir descontos acentuados, às vezes oferecendo reduções de até 90% nos custos de computação da instância. A troca com instâncias spot é que elas podem ser retomadas pelo provedor de nuvem subjacente a qualquer momento com um curto período de aviso (2 minutos para AWS, 30 segundos para Azure e GCP).
Se estiver usando AWS, uma política de cluster pode ser definida que inclua o uso de instâncias spot, como:
No Azure:
Nesses exemplos, apenas um nó (especificamente o nó driver) pode ser uma instância sob demanda, enquanto todos os outros nós dentro do cluster serão instâncias spot durante a criação inicial do cluster. Como a opção de fallback está habilitada aqui, uma instância sob demanda será solicitada para substituir uma instância spot que foi devolvida ao provedor de nuvem. Embora as políticas no GCP não possam impor o atributo "first_on_demand" atualmente, nós preemptíveis ainda podem ser impostos assim:
Por padrão, apenas o nó driver usará uma instância sob demanda na inicialização do cluster quando instâncias preemptíveis estiverem habilitadas.
Ao executar processos tolerantes a falhas, como cargas de trabalho experimentais ou consultas ad-hoc, onde a confiabilidade e a duração da carga de trabalho não são prioridade, as instâncias spot podem fornecer uma maneira fácil de manter os custos das instâncias baixos. Portanto, as instâncias spot são mais adequadas para ambientes de desenvolvimento e homologação.
As taxas de despejo e os preços das instâncias spot podem variar entre os tamanhos de T-shirt e as regiões da nuvem. Portanto, o planejamento para configurações ideais de cluster pode ser auxiliado por ferramentas dos respectivos provedores de nuvem, como o AWS Spot Instance Advisor, o Azure Spot Pricing and History no portal da conta Azure, ou o Google Cloud Pricing Calculator.
Observe que o Azure tem uma alavanca adicional no controle de custos: instâncias reservadas podem ser usadas pelo Databricks, fornecendo outro desconto (potencialmente acentuado) sem adicionar instabilidade.
Marcação de cluster
A capacidade de observar os recursos que estão sendo aproveitados por uma equipe é habilitada pela marcação de cluster. Essas marcações se propagam para o nível do provedor de nuvem, de modo que o uso e os custos possam ser atribuídos tanto da plataforma Databricks quanto dos custos subjacentes da nuvem. No entanto, sem uma política de cluster, um usuário que cria um cluster não é obrigado a atribuir nenhuma marcação. Portanto, quando um administrador cria uma política para uma equipe que está solicitando acesso à plataforma Databricks, é vital que a política inclua uma imposição de marcação de cluster específica para a equipe à qual a política será atribuída.
Aqui está um exemplo de criação de uma política com uma marcação de centro de custo personalizada imposta:
Uma vez atribuída uma marcação para identificar a equipe que usa o cluster, os administradores podem analisar os logs de uso para vincular os DBUs e os custos gerados de volta à equipe que está aproveitando o cluster. Essas marcações também se propagarão para o nível de uso da VM, de modo que os custos de instância do provedor de nuvem também possam ser atribuídos de volta à equipe ou ao centro de custo. Opções de monitoramento de logs de uso em geral são discutidas em uma seção abaixo.
Uma distinção importante em relação às marcações de cluster ao usar um pool de clusters é que apenas as marcações do pool de clusters (e não as marcações do cluster) se propagam para as instâncias de VM subjacentes. A criação de pools de clusters não é restrita por políticas de cluster e, portanto, um administrador deve criar pools de clusters com as marcações apropriadas antes de atribuir permissões de uso a uma equipe. A equipe pode então ter acesso por meio de políticas para se conectar ao pool respectivo ao criar seus clusters. Isso garante que as marcações associadas à equipe que usa o pool sejam propagadas para o nível da instância de VM para faturamento.
Atributos virtuais de política
Além das configurações que são vistas na página de configuração do cluster, existem também atributos "virtuais" que podem ser restringidos por políticas. Especificamente, os dois atributos disponíveis nesta categoria são "dbus_per_hour" e "cluster_type".
Com o atributo "dbus_per_hour", os criadores de clusters podem ter alguma flexibilidade na configuração, desde que o uso de DBU fique abaixo da restrição definida na política. Este atributo em si não restringe os custos atribuídos às instâncias de VM subjacentes diretamente como os atributos anteriores discutidos (embora as taxas de DBU sejam frequentemente correlacionadas com as taxas de instâncias de VM). Aqui está um exemplo de uma definição de política que restringe o usuário a criar clusters que usam menos de 10 DBUs por hora:
O outro atributo virtual disponível é "cluster_type", que pode ser aproveitado para restringir os usuários dos diferentes tipos de clusters. Os tipos que são permitidos por meio deste atributo são "all-purpose", "job" e "dlt", sendo que este último se refere ao Delta Live Tables. Aqui está um exemplo de uso desta política:
As restrições de tipo de cluster são especialmente valiosas ao trabalhar com equipes distintas envolvidas em todo o ciclo de vida de desenvolvimento e implantação. Uma equipe trabalhando no desenvolvimento de um novo pipeline de ETL ou machine learning normalmente exigiria acesso a um cluster all-purpose, enquanto as equipes de engenharia de implantação usariam clusters de jobs ou Delta Live Tables (DLT). Essas políticas podem impor as melhores práticas, garantindo que o tipo de cluster correto seja usado para cada estágio específico do ciclo de vida de desenvolvimento e implantação.
Uma má prática comum é a implantação de cargas de trabalho automatizadas compartilhando um cluster all-purpose. À primeira vista, isso pode parecer a opção mais barata, pois o consumo pode ser vinculado a um único cluster. No entanto, esse tipo de configuração leva à contenção de recursos, o que prolonga o tempo que o cluster precisa ficar em execução, aumentando os custos de computação. Em vez disso, o uso de clusters de jobs, que são isolados para executar um job por vez, reduz a duração da computação necessária para concluir um conjunto de jobs. Isso leva a um menor uso de DBUs do Databricks, bem como a menores custos de instância da nuvem subjacente. Melhor desempenho, juntamente com as taxas de custo mais baixas por DBU que os clusters de jobs oferecem, levam a economias de custo dramáticas. Vimos clientes que economizaram dezenas de milhares de dólares simplesmente movendo apenas dez por cento de suas cargas de trabalho de clusters all-purpose para clusters de jobs. A reutilização de cluster de jobs pode ser aproveitada para garantir a conclusão oportuna de um conjunto de jobs, removendo o tempo de inicialização do cluster entre cada tarefa.
Para formular políticas que permitam às equipes criar clusters para a carga de trabalho correta, existem algumas melhores práticas a serem seguidas. Alguns padrões típicos de políticas restritivas são clusters de nó único, clusters apenas para jobs ou clusters all-purpose com escalonamento automático para as equipes compartilharem. Exemplos de políticas completas podem ser encontrados aqui.
Custos do provedor de nuvem
Do ponto de vista do consumo do Databricks (DBUs), todos os custos podem ser atribuídos aos recursos de computação utilizados. No entanto, os custos atribuídos à rede e ao armazenamento da nuvem subjacente também devem ser considerados.
Armazenamento
A vantagem de usar uma plataforma como o Databricks é que ela funciona perfeitamente com armazenamento em nuvem relativamente barato, como ADLS Gen2 no Azure, S3 na AWS ou GCS no GCP. Isso é especialmente vantajoso ao usar o formato Delta Lake, pois ele fornece governança de dados para uma camada de armazenamento de outra forma difícil de gerenciar, bem como otimizações de desempenho quando usado em conjunto com o Databricks.
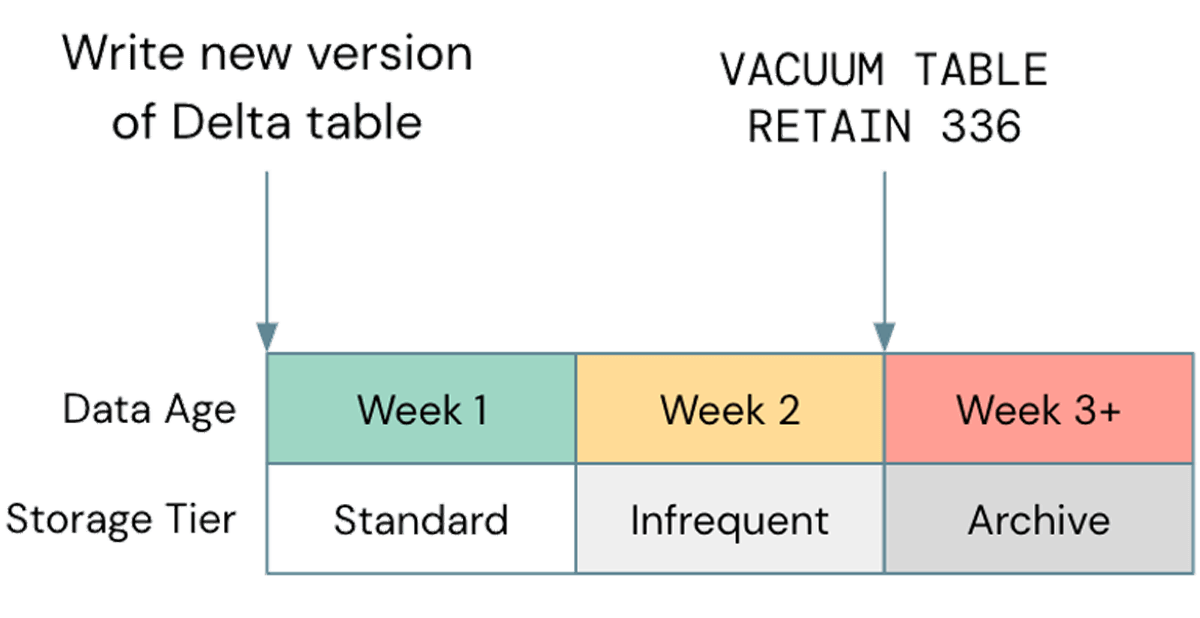
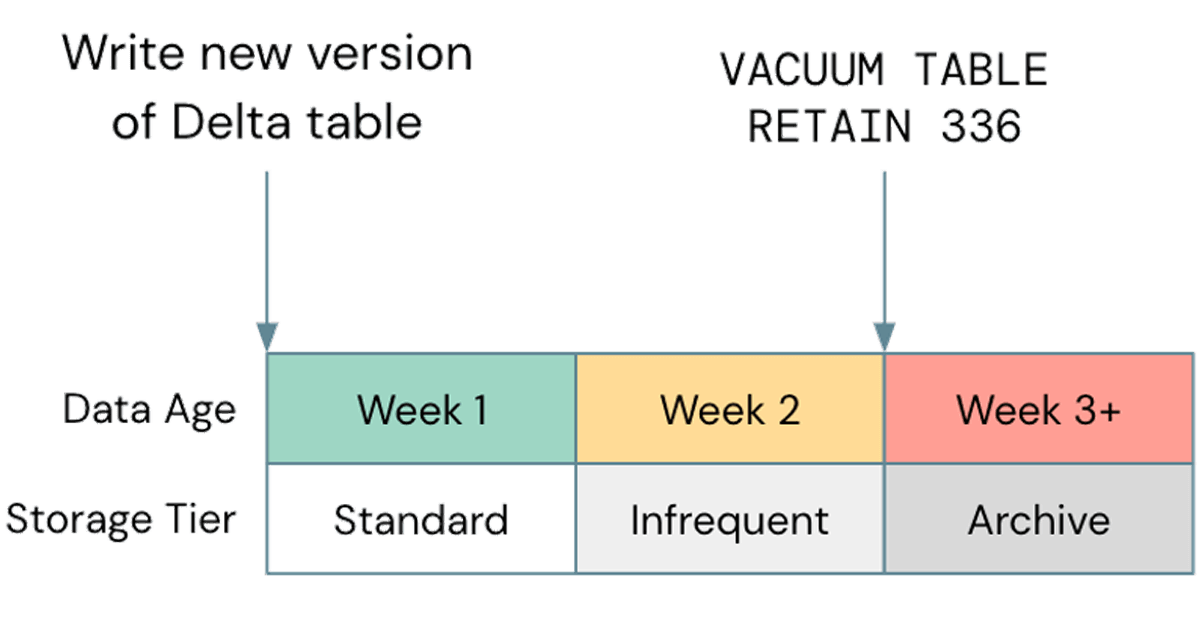
Uma má otimização comum, quando se trata de armazenamento, é negligenciar o uso do gerenciamento de ciclo de vida sempre que possível; em um caso recente, observamos um bucket S3 de um cliente com cerca de 2,5 PB, dos quais apenas cerca de 800 TB eram dados reais. Os 1,7 PB restantes eram dados versionados que não forneciam nenhum valor. Embora a exclusão de objetos antigos do seu armazenamento em nuvem seja uma prática recomendada geral, é importante alinhar isso com seu ciclo de Vacuum do Delta. Se o ciclo de vida do seu armazenamento excluir objetos antes que eles possam ser aspirados pelo Delta, suas tabelas podem quebrar; certifique-se de testar quaisquer políticas de ciclo de vida em dados não produtivos antes de implementá-las mais amplamente. Uma política de exemplo pode parecer com isto:
{kind=link}
Observe que os níveis de armazenamento não padrão, como Glacier no S3 ou Archive no ADLS, não são suportados pelo Databricks, portanto, certifique-se de executar o Vacuum antes que esses níveis sejam usados.
Rede
Os dados usados na plataforma Databricks podem vir de uma variedade de fontes diferentes, de data warehouses a sistemas de streaming como Kafka. No entanto, o utilizador de largura de banda mais comum é a escrita em camadas de armazenamento como S3 ou ADLS. Para reduzir os custos de rede, os workspaces do Databricks devem ser implantados com o objetivo de minimizar a quantidade de dados transferidos entre regiões e zonas de disponibilidade. Isso inclui implantar na mesma região da maioria dos seus dados, sempre que possível, e pode incluir o lançamento de workspaces regionais, se necessário.
Ao usar uma VPC gerenciada pelo cliente para um workspace Databricks na AWS, os custos de rede podem ser reduzidos aproveitando os Endpoints de VPC, que permitem a conectividade entre a VPC e os serviços da AWS sem um Internet Gateway ou Dispositivo NAT. O uso de endpoints reduz os custos incorridos com tráfego de rede e também torna a conexão mais segura. Endpoints de gateway especificamente podem ser usados para conectar ao S3 e DynamoDB, enquanto endpoints de interface podem ser usados de forma semelhante para reduzir o custo de instâncias de computação que se conectam ao plano de controle Databricks. Esses endpoints estão disponíveis desde que o workspace use Conectividade Segura de Cluster.
Da mesma forma no Azure, Private Link ou Service Endpoints podem ser configurados para que o Databricks se comunique com serviços como ADLS para reduzir os custos de NAT. No GCP, o Private Google Access (PGA) pode ser aproveitado para que o tráfego entre o Google Cloud Storage (GCS) e o Google Container Registry (GCR) use a rede interna do Google em vez da internet pública, consequentemente também evitando o uso de um dispositivo NAT.
Computação Serverless
Para cargas de trabalho de análise, uma opção a considerar é usar um SQL Warehouse com a opção Serverless habilitada. Com o Serverless SQL, a plataforma Databricks gerencia um pool de instâncias de computação que estão prontas para serem atribuídas a um usuário sempre que uma carga de trabalho é iniciada. Portanto, os custos das instâncias subjacentes são totalmente gerenciados pelo Databricks, em vez de ter duas cobranças separadas (ou seja, o custo de computação DBU e o custo de computação da nuvem subjacente).
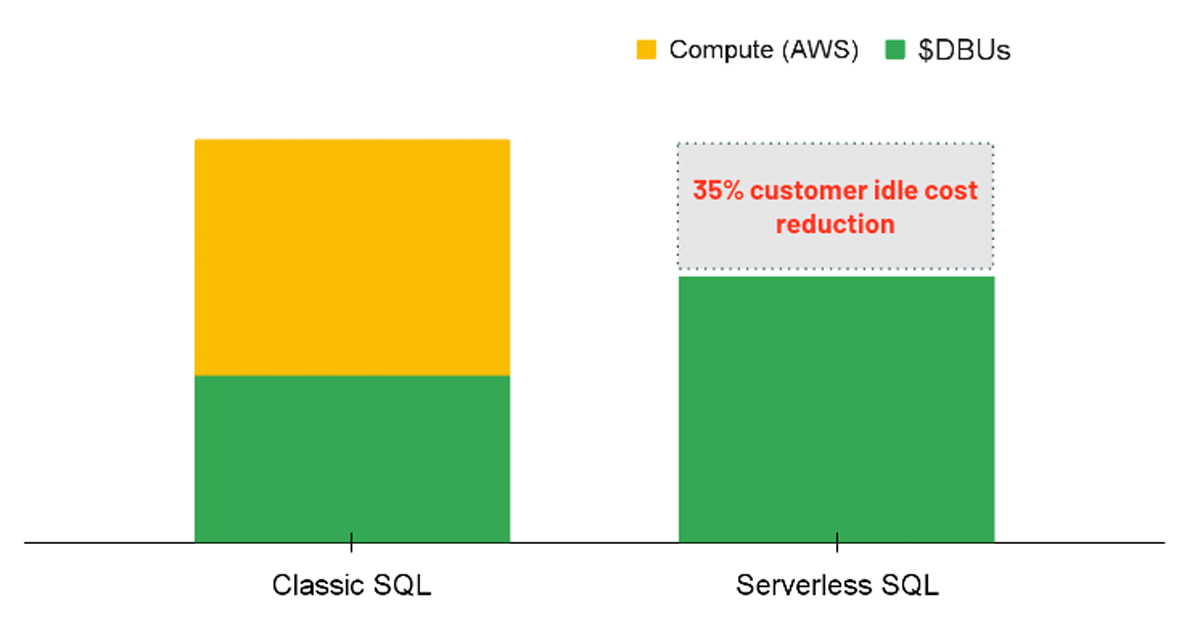
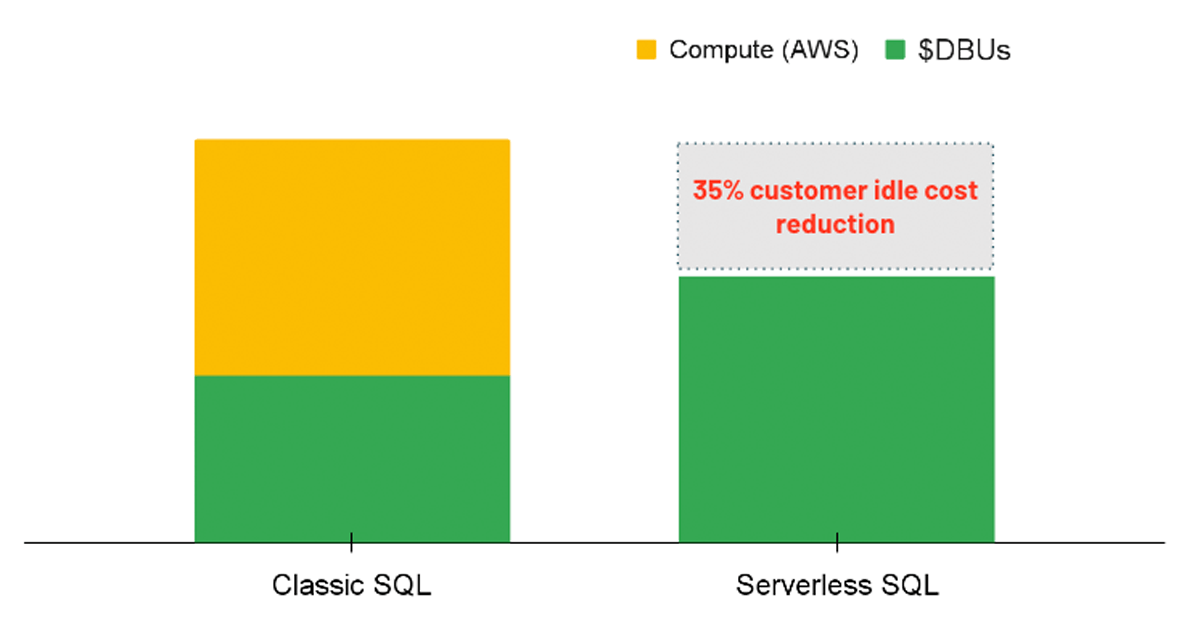{kind=link}
O Serverless leva a uma vantagem de custo ao fornecer recursos de computação instantâneos quando uma consulta é executada, reduzindo os custos ociosos de clusters subutilizados. Da mesma forma, o serverless permite um auto-scaling mais preciso para que as cargas de trabalho possam ser concluídas de forma eficiente, consequentemente economizando custos ao melhorar o desempenho. Embora a opção serverless ainda não seja diretamente aplicável por meio de uma política, os administradores podem habilitar a opção para todos os usuários com permissões de criação de SQL Warehouse.
Monitoramento de uso
Juntamente com o controle de custos por meio de políticas de cluster e configurações de implantação de workspace, é igualmente importante que os administradores tenham a capacidade de monitorar os custos. O Databricks oferece algumas opções para fazer isso, com recursos para automatizar notificações e alertas com base em análises de uso. Especificamente, os administradores podem usar o console de conta Databricks para uma visão geral rápida do uso, analisar logs de uso para uma visão mais granular e usar nossa nova API de Orçamentos para receber notificações ativas quando os orçamentos forem excedidos.
Usando o console de conta
Com a arquitetura Databricks Enterprise 2.0, o console de conta inclui uma página de uso que oferece aos administradores a capacidade de ver o uso por DBU ou valor em Dólares visualmente. O gráfico pode mostrar o consumo com uma visão agregada, agrupado por workspace ou agrupado por SKUs. Ao agrupar por SKUs, o uso é mostrado por clusters de jobs, clusters de propósito geral ou computação SQL como exemplos. Se o gráfico for segmentado por workspace, haverá um grupo mostrado para os nove principais workspaces por consumo de DBU, com o último agrupamento como uma soma combinada de todos os outros workspaces. Para entender os detalhes mais granulares de cada workspace individualmente, uma tabela pode ser encontrada na parte inferior da página que lista cada workspace separadamente junto com os valores de DBU/USD por SKU. Esta página é bem adequada para administradores obterem uma visão completa do uso e dos custos em todos os workspaces sob uma conta.
Como o Databricks é um serviço de primeira parte na plataforma Azure, a ferramenta Azure Cost Management pode ser aproveitada para monitorar o uso do Databricks (juntamente com todos os outros serviços no Azure). Diferentemente do Console de Conta para implantações Databricks no AWS e GCP, os recursos de monitoramento do Azure fornecem dados até o nível de granularidade de tags. Tags personalizadas no Azure podem ser criadas não apenas no nível do cluster, mas também no nível do workspace. Essas tags serão exibidas como grupos e filtros ao analisar os dados de uso. Dentro desses relatórios, o uso gerado pela computação Databricks será exibido juntamente com o uso da instância subjacente convenientemente na mesma visualização. Logs também podem ser entregues a um contêiner de armazenamento em uma programação e usados para análises e alertas mais automatizados, como explicado na próxima seção.
Os administradores têm a opção de baixar logs de uso manualmente do console de conta na página de uso ou com a API de Conta. No entanto, um processo mais eficiente para analisar esses logs de uso é configurar a entrega automatizada de logs para armazenamento em nuvem (AWS, GCP). Isso resulta em um CSV diário que contém o uso de cada workspace em um esquema granular.
Uma vez que a entrega de logs de uso tenha sido configurada em qualquer uma das três nuvens, uma prática recomendada comum é criar um pipeline de dados dentro do Databricks que ingira esses dados diariamente e os salve em uma tabela Delta usando um fluxo de trabalho agendado. Esses dados podem então ser usados para análise de uso ou para acionar alertas notificando administradores ou líderes de equipe responsáveis pelos gastos do centro de custo quando o consumo atingir um limite definido.
API de Orçamentos
Um recurso futuro para facilitar o orçamento dos custos de computação Databricks é o novo endpoint de orçamento (atualmente em Private Preview) dentro da API de Conta. Isso permitirá que qualquer pessoa que use um workspace Databricks seja notificada quando um limite de orçamento for atingido em qualquer período personalizado filtrado por workspace, SKU ou tag de cluster. Assim, um orçamento pode ser configurado para qualquer workspace, centro de custo ou equipe por meio desta API.
Resumo
Embora a Plataforma Databricks Lakehouse abranja muitos casos de uso e personas de usuários, nosso objetivo é fornecer um conjunto unificado de ferramentas para ajudar os administradores a equilibrar o controle de custos com a experiência do usuário. Neste blog, apresentamos várias estratégias para abordar esse equilíbrio:
- Use Políticas de Cluster para controlar quais usuários podem criar clusters, bem como o tamanho e o escopo desses clusters
- Projete seu ambiente para minimizar custos não-DBU gerados por workspaces Databricks, como custos de armazenamento e rede
- Use ferramentas de monitoramento para garantir que suas expectativas de custo sejam atendidas e que você tenha práticas eficazes em vigor
Confira nossos outros blogs focados em administradores, vinculados ao longo deste artigo, e fique atento a blogs adicionais em breve. Certifique-se também de experimentar novos recursos como Private Link (AWS | Azure) e Orçamentos!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.