Construindo um aplicativo em tempo quase real com o Zerobus Ingest e o Lakebase
Aprenda como simplificar a ingestão de dados para casos de uso de IoT, clickstream e telemetria no Databricks
- Aprenda como o Zerobus Ingest elimina arquiteturas multi-hop para casos de uso de IoT, clickstream e telemetria
- Veja como o Lakebase elimina pipelines de ETL complexos e personalizados e integra dados transacionais para casos de uso operacionais
- Crie um dashboard quase em tempo real usando o Zerobus Ingest, o Lakebase e os Databricks Apps
Dados de eventos de IoT, clickstream e telemetria de aplicativos impulsionam analítica e IA críticas em tempo real quando combinados com a Databricks Data Intelligence Platform. Tradicionalmente, a ingestão desses dados exigia vários saltos de dados (barramento de mensagens, jobs do Spark) entre a fonte de dados e o lakehouse. Isso adiciona sobrecarga operacional, duplicação de dados, exige conhecimento especializado e geralmente é ineficiente quando o lakehouse é o único destino para esses dados.
Assim que esses dados chegam ao lakehouse, eles são transformados e selecionados para casos de uso analíticos subsequentes. No entanto, as equipes frequentemente precisam usar esses dados analíticos para casos de uso operacionais, e construir esses aplicativos personalizados pode ser um processo trabalhoso. Elas precisam provisionar e manter componentes de infraestrutura essenciais, como uma instância de banco de dados OLTP dedicada (com rede, monitoramento, backups e muito mais). Além disso, elas precisam gerenciar o processo de ETL reverso dos dados analíticos no banco de dados para disponibilizá-los no aplicativo em tempo real. Isso exigiria que a equipe criasse pipelines adicionais para enviar dados do lakehouse para o banco de dados operacional externo. Esses pipelines aumentam a infraestrutura que os desenvolvedores precisam configurar e manter, o que, no geral, desvia a atenção deles do objetivo principal: criar os aplicativos para seus negócios.
Então, como o Databricks simplifica tanto a ingestão de dados no lakehouse quanto o fornecimento de dados ouro para dar suporte a cargas de trabalho operacionais?
É aí que entram o Zerobus Ingest e o Lakebase.
Sobre o Zerobus Ingest
Zerobus Ingest, parte do Lakeflow Connect, é um conjunto de APIs que fornecem uma maneira simplificada de enviar dados de eventos diretamente para o lakehouse. Eliminando totalmente a camada de barramento de mensagens de coletor único, o Zerobus Ingest reduz a infraestrutura, simplifica as operações e oferece ingestão em tempo quase real em escala. Dessa forma, o Zerobus Ingest torna mais fácil do que nunca extrair o valor de seus dados.
O aplicativo produtor de dados deve especificar uma tabela de destino para gravar os dados, garantir que as mensagens sejam mapeadas corretamente para o esquema da tabela e, em seguida, iniciar uma transmissão para enviar dados para o Databricks. Do lado do Databricks, a API valida os esquemas da mensagem e da tabela, grava os dados na tabela de destino e envia uma confirmação ao cliente de que os dados foram persistidos.
Principais benefícios do Zerobus Ingest:
- Arquitetura simplificada: elimina a necessidade de fluxos de trabalho complexos e duplicação de dados.
- Desempenho em escala: suporta ingestão quase em tempo real (até 5 segundos) e permite que milhares de clientes gravem na mesma tabela (throughput de até 100 MB/s por cliente).
- Integração com a plataforma de inteligência de dados: acelera o tempo de retorno, permitindo que as equipes apliquem ferramentas de analítica e IA, como o MLflow para detecção de fraudes, diretamente em seus dados.
Capacidade de ingestão do Zerobus | Especificações |
Latência de ingestão | Quase em tempo real (≤5 segundos) |
throughput máxima por cliente | Até 100 MB/s |
Clientes concorrentes | Milhares por tabela |
Atraso de sincronização contínua (Delta → Lakebase) | 10 a 15 segundos |
Latência do gravador ForeachWriter em tempo real | 200–300 milissegundos |
Sobre o Lakebase
Lakebase é um banco de dados Postgres totalmente gerenciado, serverless e escalável, integrado à Plataforma Databricks, projetado para cargas de trabalho operacionais e transacionais de baixa latência que são executadas diretamente nos mesmos dados que potencializam casos de uso analíticos e de IA.
A separação completa de computação e armazenamento oferece provisionamento rápido e autoscale elástico. A integração do Lakebase com a Databricks Platform é um grande diferencial em relação aos bancos de dados tradicionais, porque o Lakebase disponibiliza os dados do Lakehouse diretamente para aplicações em tempo real e AI, sem a necessidade de pipelines de dados personalizados complexos. Ele foi criado para atender aos requisitos de criação de banco de dados, latência de consulta e simultaneidade para alimentar aplicações empresariais e cargas de trabalho de agentes. Por último, permite que os desenvolvedores façam facilmente o controle de versão e a branch de bancos de dados como se fossem código.
Principais benefícios do Lakebase:
- Sincronização automática de dados: Capacidade de sincronizar facilmente dados do Lakehouse (camada analítica) para o Lakebase como um snapshot, de forma agendada ou contínua, sem a necessidade de pipelines externos complexos.
- Integração com a Plataforma Databricks: O Lakebase se integra com o Unity Catalog, Lakeflow Connect, Spark Declarative Pipelines, Databricks Apps e muito mais.
- Permissões e governança integradas: gerenciamento consistente de funções e permissões para dados operacionais e analíticos. As permissões nativas do Postgres ainda podem ser mantidas por meio do protocolo Postgres.
Juntas, essas ferramentas permitem que os clientes ingiram dados de vários sistemas diretamente nas tabelas Delta e implementem casos de uso de ETL reverso em escala. A seguir, exploraremos como usar essas tecnologias para implementar um aplicativo quase em tempo real!
Como criar uma aplicação quase em tempo real
Como exemplo prático, vamos ajudar a 'Data Diners', uma empresa de entrega de comida, a capacitar sua equipe de gestão com um aplicativo para monitorar a atividade dos drivers e as entregas de pedidos em tempo real. Atualmente, eles não têm essa visibilidade, o que limita sua capacidade de mitigar problemas à medida que surgem durante as entregas.
Por que uma aplicação em tempo real é valiosa?
- Consciência operacional: A gerência pode ver instantaneamente onde cada driver está e como suas entregas atuais estão progredindo. Isso significa menos pontos cegos com pedidos atrasados ou quando um motorista precisa de ajuda.
- Mitigação de problemas: dados de localização e status em tempo real permitem que os coordenadores redirecionem motoristas, ajustem prioridades ou entrem em contato proativamente com os clientes em caso de atrasos, reduzindo entregas com falha ou atrasadas.
Vamos ver como construir isso com o Zerobus Ingest, o Lakebase e os Databricks Apps na Data Intelligence Platform!
Visão geral da arquitetura da aplicação
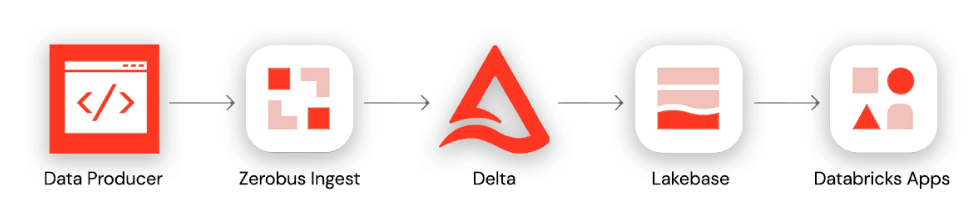
Esta arquitetura de ponta a ponta segue quatro estágios: (1) um produtor de dados usa o SDK do Zerobus para gravar eventos diretamente em uma tabela Delta no Databricks Unity Catalog. (2) um pipeline de sincronização contínua envia registros atualizados da tabela Delta para uma instância do Lakebase Postgres. (3) um backend FastAPI se conecta ao Lakebase via WebSockets para transmissão de atualizações em tempo real. (4) uma aplicação de front-end criada no Databricks Apps visualiza os dados ao vivo para os usuários finais.
Começando com nosso produtor de dados, o aplicativo "data diner" no celular do driver emitirá dados de telemetria de GPS sobre a localização do driver (coordenadas de latitude e longitude) a caminho da entrega dos pedidos. Esses dados serão enviados para um gateway de API, que, por fim, envia os dados para o próximo serviço na arquitetura de ingestão.
Com o SDK Zerobus, podemos escrever rapidamente um cliente para encaminhar eventos do gateway de API para nossa tabela de destino. Com a tabela de destino sendo atualizada em tempo quase real, podemos criar um pipeline de sincronização contínua para atualizar nossas tabelas do lakebase. Finalmente, aproveitando o Databricks Apps, podemos implantar um backend FastAPI que usa WebSockets para transmitir atualizações em tempo real do Postgres, juntamente com um aplicativo de front-end para visualizar o fluxo de dados ao vivo.
Antes da introdução do SDK Zerobus, a arquitetura de transmissão teria incluído múltiplos saltos antes que os dados chegassem à tabela de destino. Nosso gateway de API precisaria descarregar os dados para uma área de preparação como o Kafka, e precisaríamos do Spark Structured Streaming para gravar as transações na tabela de destino. Tudo isso adiciona complexidade desnecessária, especialmente considerando que o único destino é o lakehouse. Em vez disso, a arquitetura acima demonstra como a Databricks Data Intelligence Platform simplifica o desenvolvimento de aplicativos corporativos de ponta a ponta, desde a ingestão de dados até a analítica em tempo real e a implementação de aplicativos interativos.
Introdução
Pré-requisitos: do que você precisa
- Lakebase: disponibilidade geral na AWS e no Azure.
- Zerobus Ingest: Disponibilidade geral na AWS e no Azure
- Databricks Apps: Verifique se você tem as permissões para criar Databricks Apps.
Etapa 1: Crie uma tabela de destino no Databricks Unity Catalog
Os dados de eventos produzidos pelos aplicativos cliente ficarão em uma tabela Delta. Use o código abaixo para criar essa tabela de destino no catálogo e esquema desejados.
O passo 2: Autentique usando OAUTH
O passo 3: Crie o cliente Zerobus e ingira dados na tabela de destino
O código abaixo envia os dados de eventos de telemetria para o Databricks usando a API Zerobus.
Limitação e solução alternativa do Change Data Feed (CDF)
Atualmente, o Zerobus Ingest não oferece suporte a CDF. O CDF permite que o Databricks registre eventos de alteração para novos dados gravados em uma tabela delta. Esses eventos de alteração podem ser inserções, exclusões ou atualizações. Esses eventos de alteração podem ser usados para atualizar as tabelas sincronizadas no Lakebase. Para sincronizar dados com o Lakebase e continuar com nosso projeto, gravaremos os dados da tabela de destino em uma nova tabela e habilitaremos o CDF nessa tabela.
Etapa 4: Provisionar o Lakebase e sincronizar os dados com a instância do banco de dados
Para alimentar o aplicativo, vamos sincronizar os dados desta nova tabela habilitada para CDF em uma instância do Lakebase. Sincronizaremos esta tabela continuamente para dar suporte ao nosso painel em tempo quase real.
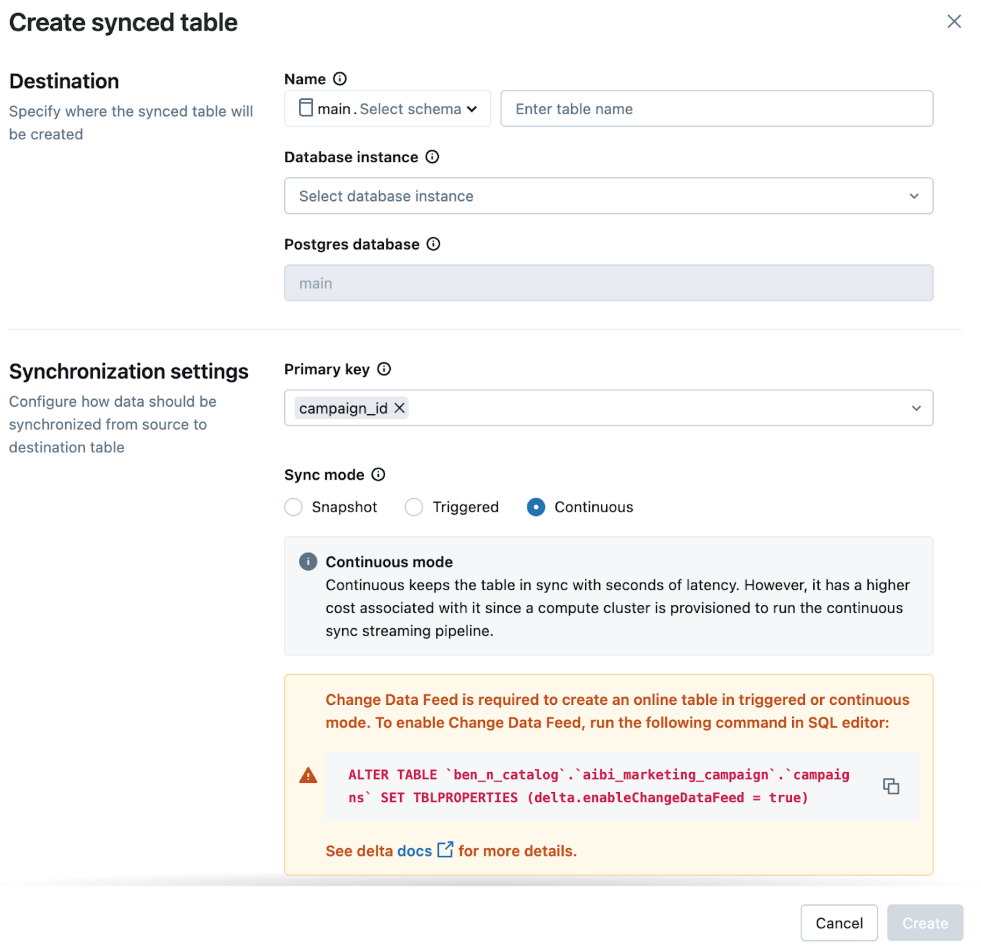
Na IU, selecionamos:
- Modo de Sincronização: Contínuo para atualizações de baixa latência
- Chave Primária: table_primary_key
Isso garante que o aplicativo reflita os dados mais recentes com o mínimo de atraso.
Observação: Você também pode criar o pipeline de sincronização programaticamente usando o SDK do Databricks.
Modo em tempo real via gravador ForeachWriter
As sincronizações contínuas do Delta para o Lakebase têm um atraso de 10 a 15 segundos, portanto, se você precisar de menor latência, considere usar o modo em tempo real por meio do gravador ForeachWriter para sincronizar dados diretamente de um DataFrame para uma tabela do Lakebase. Isso sincronizará os dados em milissegundos.
Consulte o c�ódigo do Lakebase ForeachWriter no Github.
O passo 5: Crie o app com FastAPI ou outro framework de sua escolha
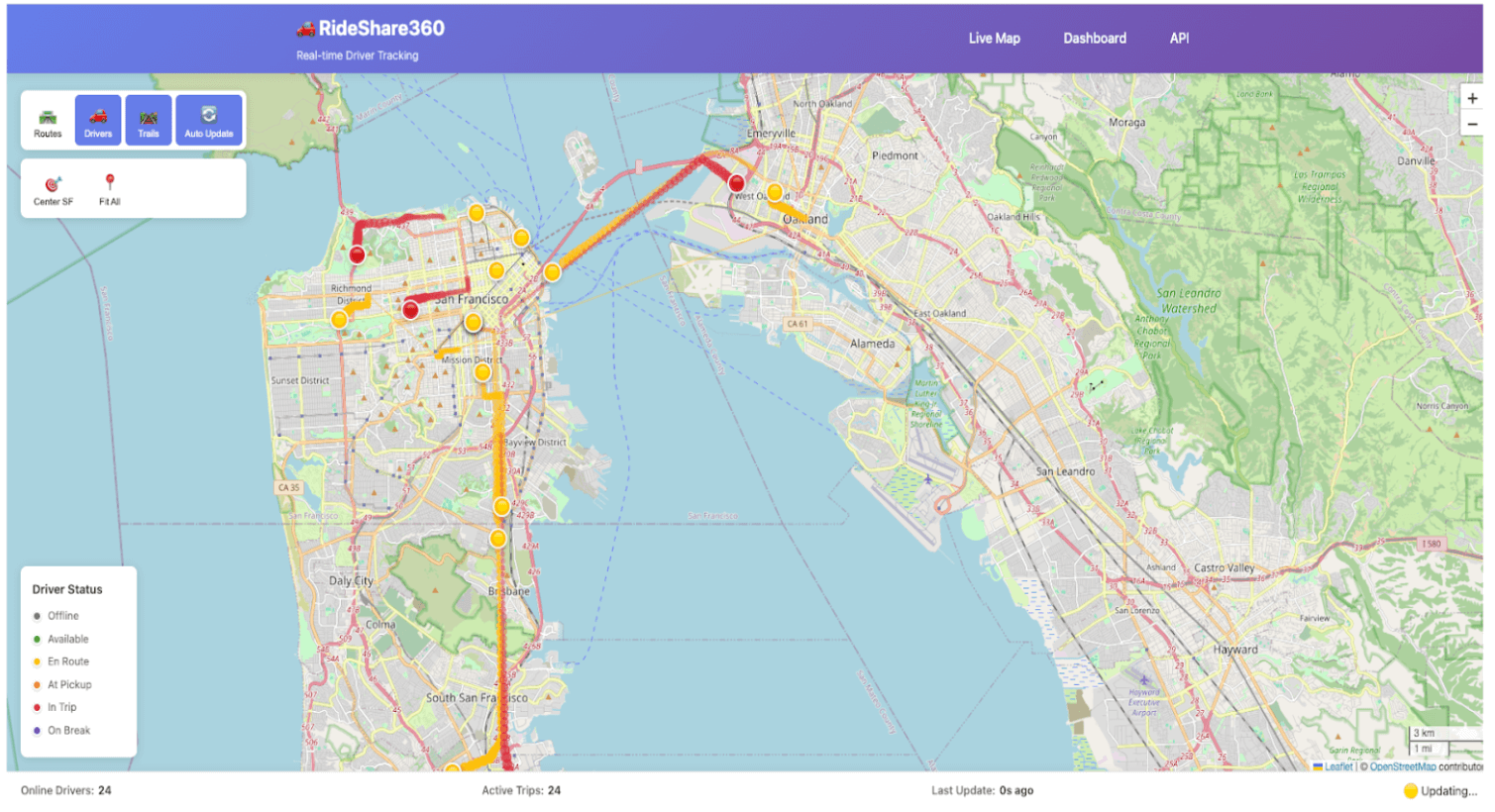
Com seus dados sincronizados com o Lakebase, agora você pode implantar seu código para criar seu aplicativo. Neste exemplo, o aplicativo busca dados de eventos do Lakebase e os usa para atualizar um aplicativo em tempo quase real para rastrear a atividade do driver durante as entregas de comida. Leia a documentação de introdução ao Databricks Apps para saber mais sobre a criação de aplicativos no Databricks.
Mais recursos
Confira mais tutoriais, demonstrações e aceleradores de soluções para criar seus próprios aplicativos para suas necessidades específicas.
- Crie uma aplicação de ponta a ponta: um simulador de navegação em tempo real rastreia uma frota de veleiros usando o SDK do Python e a API REST, com Databricks Apps e Databricks Asset Bundles. Leia o blog
- Crie uma solução de Gêmeos Digitais: Aprenda a maximizar a eficiência operacional, acelerar percepções em tempo real e a manutenção preditiva com os Databricks Apps e o Lakebase. Leia o blog
Saiba mais sobre o Zerobus Ingest, o Lakebase e o Databricks Apps na documentação técnica. Você também pode dar uma olhada no Livro de receitas do Databricks Apps e na Coleção de recursos do livro de receitas.
Conclusão
IoT, clickstream, telemetria e aplicativos semelhantes geram bilhões de pontos de dados todos os dias, que são usados para alimentar aplicativos críticos em tempo real em várias indústrias. Dessa forma, simplificar a ingestão a partir desses sistemas é fundamental. O Zerobus Ingest oferece uma maneira simplificada de enviar dados de eventos diretamente desses sistemas para o lakehouse, garantindo alto desempenho. Ele combina bem com o Lakebase para simplificar o desenvolvimento de aplicativos corporativos de ponta a ponta.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.