Construindo Busca de Produtos em Tempo Real no Databricks
por Jiayi Wu, Luke Lefebure e Adam Gurary
- Como criar um sistema de busca de produtos em tempo real no Databricks, cobrindo os componentes de ingestão, recuperação e ranqueamento necessários para potencializar experiências de busca modernas.
- Uma arquitetura de referência usando Databricks AI Search, Lakeflow e Lakebase para processar dados de produtos, recuperar resultados relevantes e incorporar sinais operacionais em tempo real, como preços, inventário e preferências do usuário.
- Melhores práticas e métricas para operar buscas em escala, incluindo avaliação da qualidade da recuperação, monitoramento de latência e como agentes e aplicações podem ser construídos sobre sistemas de busca.
Imagine que você está projetando um sistema de busca para um marketplace online que vende carros. Em milissegundos, os usuários esperam resultados que caibam no orçamento, correspondam às suas preferências, estejam disponíveis perto deles e pareçam relevantes.
É assim que funciona a busca moderna em produtos da web. Não é apenas uma ferramenta de consulta, mas um motor de decisão em tempo real que deve recuperar, filtrar, classificar e responder quase instantaneamente — tudo isso enquanto equilibra métricas de negócios e técnicas como receita, taxa de cliques, latência e relevância.
A Databricks fornece a plataforma ponta a ponta para construir esses sistemas — desde ingestão de dados escalável (Lakeflow) até recuperação baseada em vetores (AI Search) para dados operacionais em tempo real (Lakebase) para experiências de busca baseadas em agentes (Agent Bricks). Este blog detalha como essas peças se unem para potencializar a busca de produtos em tempo real.
Componentes para Busca de Produtos
A busca de produtos não se trata apenas de responder a uma pergunta ou apresentar informações por meio de um chatbot. É um processo de descoberta e decisão — dinâmico, personalizado e profundamente ligado à receita. Os compradores esperam navegar, comparar e explorar. O objetivo não é gerar uma única resposta, mas apresentar um conjunto classificado de escolhas que pareçam relevantes, confiáveis e dignas de consideração.
Um sistema de busca de produtos em tempo real geralmente tem 3 segmentos (Figura 1).
- Ingestão prepara os dados do produto para busca. Títulos, descrições e atributos de produtos são processados, convertidos em embeddings, enriquecidos com metadados e indexados para recuperação rápida.
- Recuperação encontra o que pode ser relevante gerando um conjunto de candidatos usando busca full-text, semântica ou híbrida combinada com filtragem estruturada.
- Refinamento determina como os resultados devem ser interpretados e ordenados, aplicando compreensão de consulta, lógica de classificação, personalização e regras de negócios.

{kind=link}
Por Trás da Barra de Busca
Nenhuma dessas experiências existe sem uma infraestrutura robusta e métricas significativas.
- A infraestrutura torna a velocidade e a relevância possíveis.
- As métricas provam que seu sistema é realmente rápido e relevante — não apenas no papel.
A busca moderna de produtos exige ambos: a base de engenharia para entregar resultados e a disciplina de métricas para validar continuamente que esses resultados são bons o suficiente.
Visão Geral da Arquitetura
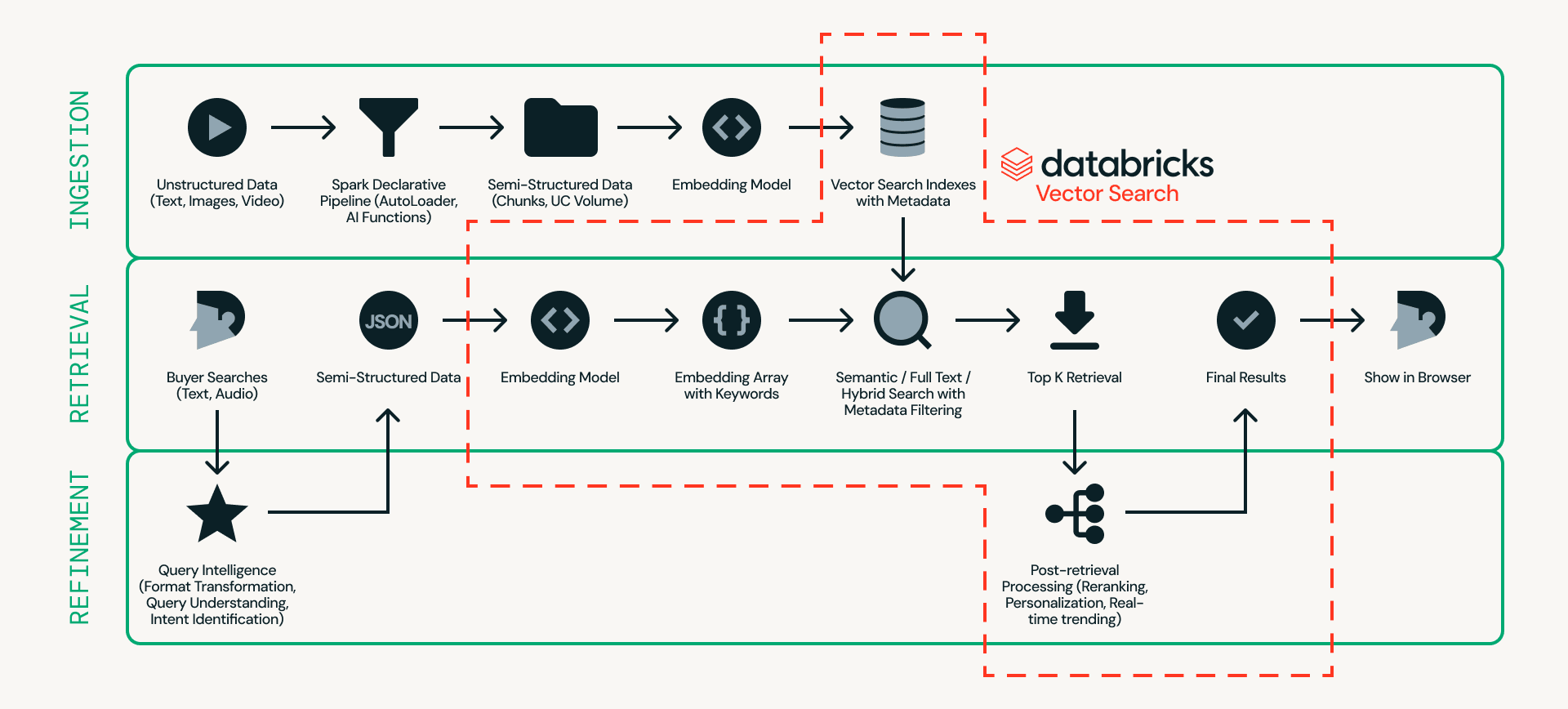
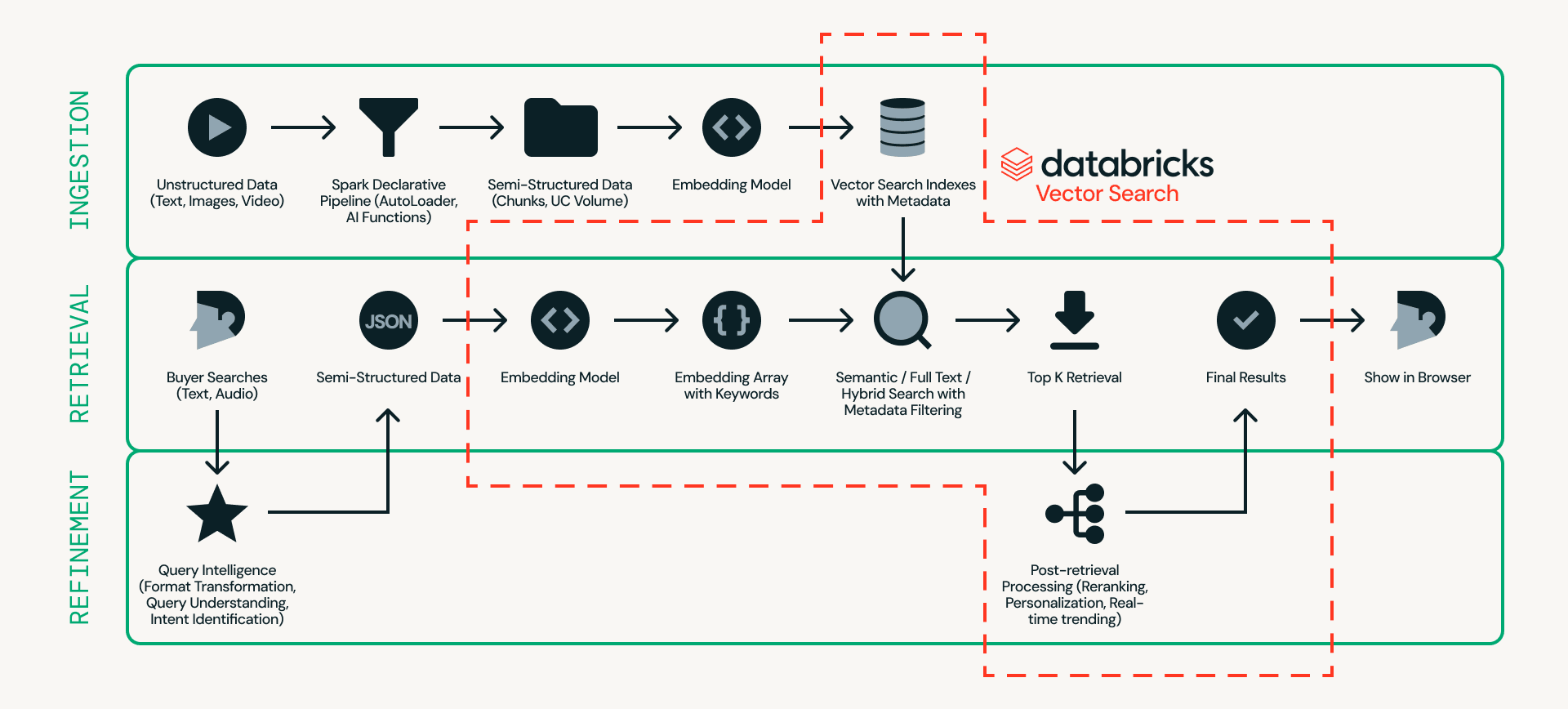
Primeiro, vamos analisar a arquitetura. A Figura 2 mostra um exemplo detalhado de uma arquitetura de busca de produtos em tempo real.
{kind=link}
No centro deste projeto está o Databricks AI Search, que lida com ingestão, recuperação e refinamento em uma única plataforma — eliminando a necessidade de conectar múltiplos sistemas externos.
- Ingestão prepara os dados do produto para que possam ser buscados de forma eficiente. Fontes não estruturadas, como listagens de produtos e imagens, são processadas por meio de pipelines escaláveis usando Databricks Auto Loader, Lakeflow Spark Declarative Pipeline e AI Functions (por exemplo, ai_parse_document). Os dados podem então ser divididos em blocos (chunked) e convertidos em embeddings com metadados (por exemplo, modelo do carro, cor ou preço) no Databricks AI Search.
- Recuperação lida com consultas em tempo real. A entrada do usuário é transformada em embeddings e filtros estruturados, e o Databricks AI Search recupera os principais candidatos usando busca semântica, busca full-text ou busca híbrida com filtragem de metadados.
- Refinamento aprimora os candidatos recuperados em resultados finais. Embora a recuperação forneça uma base sólida, essa camada refina os resultados interpretando a intenção, aplicando lógica de classificação e incorporando personalização e regras de negócios quando necessário. O contexto operacional em tempo real, como estado da sessão, inventário, preços e preferências do usuário, pode ser servido via Lakebase, permitindo sinais de baixa latência abaixo de 10 ms para influenciar a ordenação final.
Algumas diretrizes práticas ao construir sistemas de busca na Databricks:
- Experimente modelos facilmente. Troque modelos de embedding com atrito mínimo e aproveite as capacidades nativas de reranking. Atualizações futuras permitirão o ajuste fino (fine-tuning) de modelos de reranking com um clique diretamente na plataforma, simplificando a otimização de relevância.
- Sirva o estado da aplicação na velocidade da busca. Use o Lakebase para armazenar o estado da aplicação em tempo real — contexto da sessão, inventário, preços, preferências do usuário — com latência inferior a 10 ms. A sincronização gerenciada de CDC (Change Data Capture) atualiza o Lakebase para o Delta automaticamente, para que os modelos de classificação e análises sempre reflitam os dados operacionais atuais sem pipelines personalizados.
- Teste para escala antes da produção. Valide a latência e a taxa de transferência sob tráfego realista, incluindo cenários de alto QPS (Queries Per Second). Você pode simular cargas de trabalho de produção hoje usando o notebook de teste de carga de busca, com suporte nativo de teste de carga com um clique em uma versão futura. Para tráfego sustentado, aproveite os endpoints de alto QPS para lidar com concorrência em escala e monitore o desempenho por meio da observabilidade do endpoint para rastrear latência, taxa de transferência e integridade do sistema.
- Construa buscas prontas para agentes desde o início. Cada índice do AI Search com embeddings gerenciados obtém automaticamente um servidor MCP gerenciado. Use-o para integração de agentes sem configuração, o VectorSearchRetrieverTool para controle baseado em código, ou aponte um Knowledge Assistant para seu índice para perguntas e respostas instantâneas com citações — alimentado pelo Instructed Retriever, que oferece 70% mais precisão do que sistemas RAG padrão.
Métricas que Importam
Um sistema de busca não é bem-sucedido porque parece elegante em um diagrama. Ele é bem-sucedido porque entrega resultados rápidos e relevantes que impulsionam resultados de negócios.
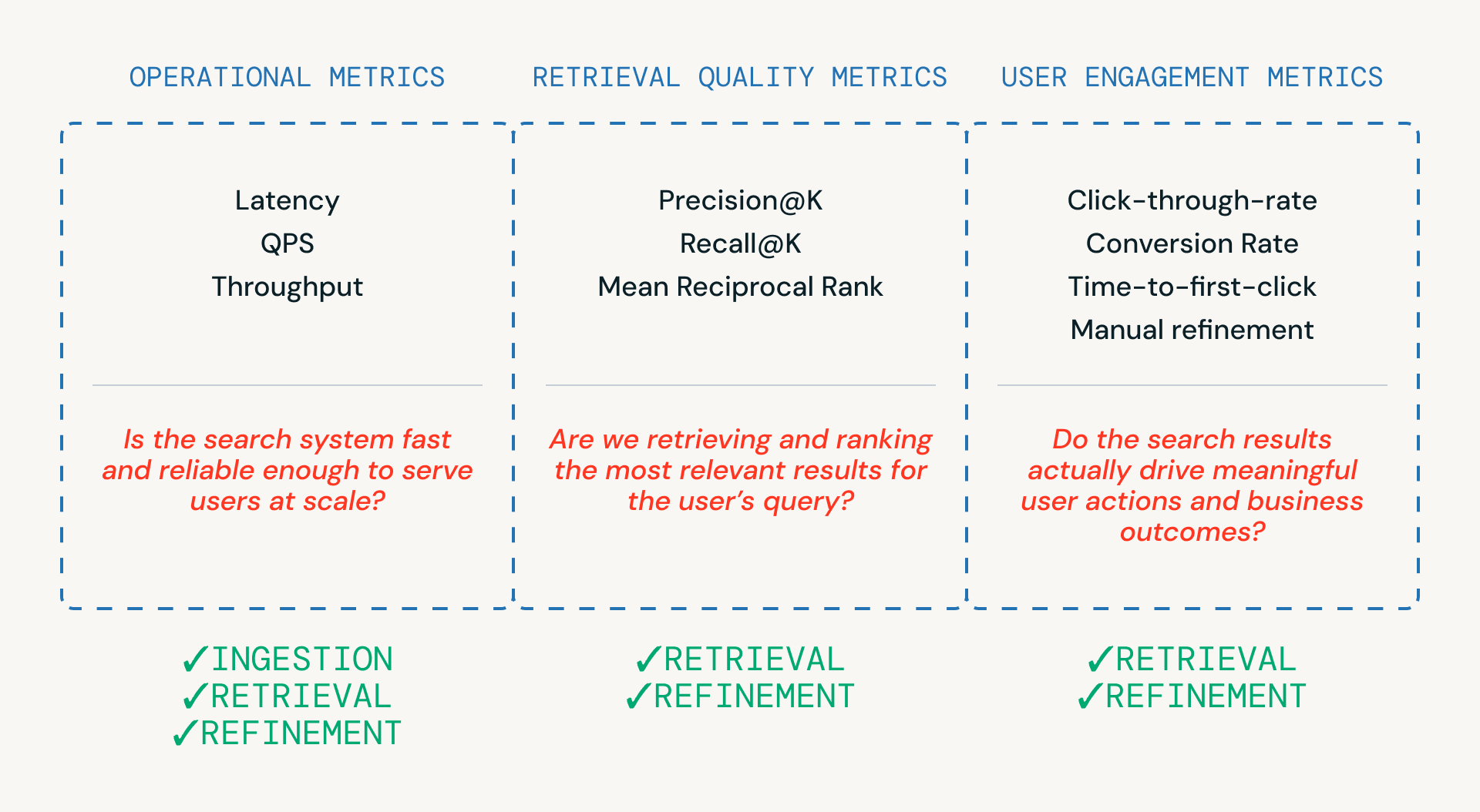
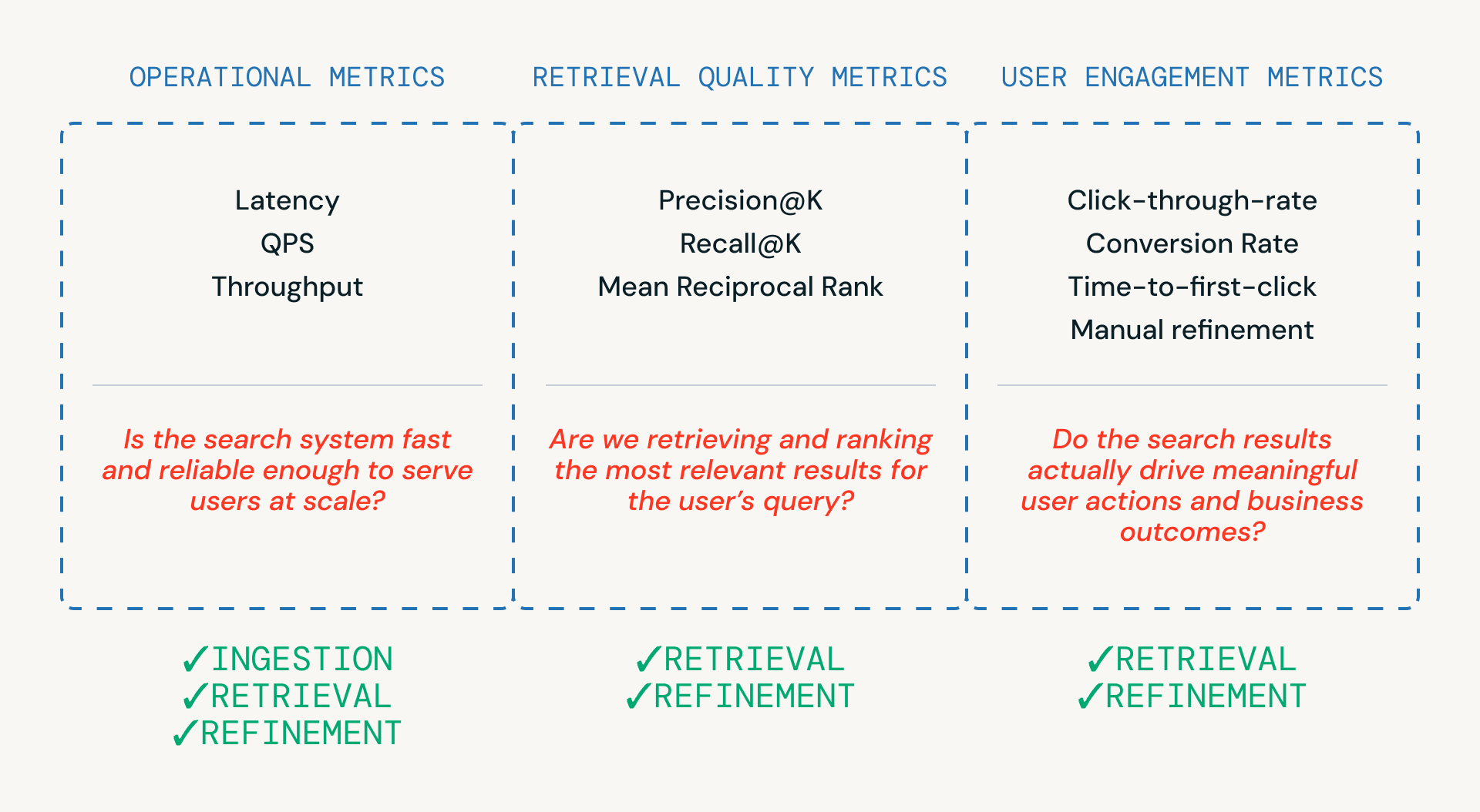
Como mostrado na Figura 3, três categorias de métricas ajudam as equipes a avaliar um pipeline de busca — cada uma ligada a uma camada diferente do sistema.
- Métricas operacionais garantem que o sistema seja rápido e confiável o suficiente para atender aos usuários em escala. Estas são críticas em todas as etapas de ingestão, recuperação e refinamento.
- Métricas de qualidade de recuperação medem se o sistema está realmente recuperando e classificando candidatos relevantes, e estão mais intimamente ligadas às fases de recuperação e refinamento, onde ocorrem a classificação e a reclassificação.
- Métricas de engajamento do usuário capturam o comportamento do mundo real — se os usuários clicam, refinam ou finalmente convertem - fornecendo feedback que informa melhorias na recuperação e nos refinamentos ao longo do tempo.
{kind=link}
Algumas diretrizes práticas ao avaliar sistemas de busca no Databricks:
- Equilibre as métricas, não otimize apenas uma. Sistemas de busca eficazes devem equilibrar múltiplas métricas — raramente você vence em todas as métricas ao mesmo tempo. Por exemplo, otimizar agressivamente a precisão pode aumentar a latência ou ocultar resultados relevantes, levando eventualmente a compradores frustrados.
- Monitore cuidadosamente a latência em tempo real. Divida a latência por estágios do pipeline e acompanhe a latência de cauda, como p95/p99, para identificar rapidamente gargalos. Técnicas como cache podem ajudar a atender a SLAs de latência rigorosos.
- Acompanhe as métricas sistematicamente. Use MLflow para registrar e avaliar métricas de recuperação e engajamento entre experimentos. A avaliação nativa da qualidade de recuperação estará disponível em breve no Databricks AI Search, tornando isso ainda mais fácil.
Busca em Produção em Escala — FOX Sports
A FOX Sports construiu sua barra de busca com IA no Databricks AI Search, lidando com milhares de QPS com uma melhoria de 2x na taxa de sucesso de consultas. Lançada para o Super Bowl LIX, sua arquitetura demonstra vários padrões abordados neste blog:
- Ingestão em tempo real. Spark Structured Streaming ingere continuamente conteúdo em Delta Sync Indexes conforme é publicado
- Recuperação em duas fases. Correspondência exata de entidades para jogadores e times, mais busca semântica ponderada pelo tempo para artigos e vídeos, orquestrada pelo Databricks Model Serving
- Otimização de produção. Uma camada de cache e um recurso de buscas em alta — impulsionando mais de 25% de todas as requisições de busca — lidam com picos de tráfego durante eventos ao vivo
Da Busca a Aplicações Inteligentes
A busca de produtos não existe isoladamente — é uma camada em uma pilha de aplicações mais ampla. Veja como o restante da plataforma Databricks estende o que você pode construir sobre o AI Search.
Aplicações em Tempo Real com Lakebase
Para aplicações de busca voltadas ao cliente — marketplaces, catálogos de produtos, plataformas de mídia — o índice de busca é apenas parte da história. As aplicações também precisam de um banco de dados transacional para o estado operacional: níveis de estoque, preços, sessões de usuário, preferências de personalização. Lakebase fornece isso como um banco de dados totalmente gerenciado e compatível com PostgreSQL, nativamente integrado à plataforma Databricks. A sincronização bidirecional gerenciada com Delta Lake significa que os modelos de classificação são treinados com os dados operacionais mais recentes, e insights analíticos fluem de volta para a camada de aplicação — tudo governado pelo Unity Catalog.
Busca com Agentes usando Agent Bricks
O Databricks fornece automaticamente um servidor MCP gerenciado para cada índice de AI Search, desbloqueando múltiplos padrões de integração:
- Assistente de Conhecimento. Um chatbot de perguntas e respostas sobre seus documentos. Aponte-o para um índice de AI Search e obtenha busca de documentos pronta para produção com citações. Usa Instructed Retriever por baixo dos panos — 70% mais preciso que RAG puro e 30% melhor que RAG agentico.
- Agentes personalizados. Use a VectorSearchRetrieverTool ou MCP com qualquer framework (OpenAI Agents SDK, LangGraph, LlamaIndex). Controle total sobre parâmetros de recuperação, embeddings e filtros. Implante como Databricks Apps com rastreamento MLflow.
- Agente Supervisor. Orquestre múltiplos subagentes: um Assistente de Conhecimento para Q&A de documentos, um Genie space para consultas de dados estruturados e UC Functions para lógica de negócios personalizada — tudo coordenado por um único supervisor.
Conclusão
Construir um sistema moderno de busca de produtos requer mais do que um índice de busca. Requer infraestrutura projetada para lidar com escala, desempenho e observabilidade do mundo real:
- Execução de baixa latência. Compreensão de consultas, recuperação, filtragem e reclassificação devem ser concluídas dentro de orçamentos rigorosos de latência p95/p99.
- Capacidade de recuperação híbrida. Combine similaridade semântica (embeddings) com filtragem estruturada, como preço, categoria ou disponibilidade.
- Escalabilidade sob carga. Sustente alta QPS e concorrência durante o tráfego de pico sem degradar o desempenho.
- Observabilidade. Mantenha visibilidade clara sobre detalhamento de latência, desempenho de classificação e saúde geral do sistema.
- Pronto para agentes por padrão. Cada índice de AI Search é uma ferramenta MCP, imediatamente utilizável por Knowledge Assistant, agentes personalizados e Agentes Supervisores.
- Suporte operacional full-stack. Lakebase fornece o banco de dados transacional para estado de aplicação em tempo real, sincronizado com Delta sem ETL.
Pronto para construir? Siga o guia de qualidade de recuperação para benchmarkar e otimizar seu pipeline de busca, veja como a FOX Sports construiu busca com IA em escala, e mergulhe na documentação do AI Search para começar.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.