Construindo um Copilot de Risco Regulatório com Databricks Agent Bricks (Parte 1: Extração de Informações)
Aprenda a transformar cartas de rejeição não estruturadas da FDA em percepções acionáveis usando as funções do Databricks AI e o Agent Bricks.
por Guanyu Chen e Diego Malaver
- Analise PDFs complexos: diferentemente das abordagens tradicionais que exigem equipes e milhares de linhas de código, basta usar a função ai_parse_document() para analisar textos e imagens de forma confiável de documentos PDF complexos, como as Cartas de Resposta Completas (CRLs) do FDA.
- Extraia percepções de forma colaborativa: Descubra como usar os Bricks do Agente de Extração de Informações para permitir que especialistas de negócios e engenheiros de AI definam, testem e aperfeiçoem de forma colaborativa a extração de dados estruturados em tempo real.
- Coloque em produção com SQL: Implantação com um único clique do seu agente aperfeiçoado como um endpoint serverless e use a função ai_query() para construir um pipeline escalável e pronto para produção para processar novos documentos diretamente no seu Lakehouse.
Em julho de 2025, o FDA dos EUA divulgou publicamente um lote inicial de mais de 200 Cartas de Resposta Completa (CRLs), cartas de decisão explicando por que as solicitações de medicamentos e produtos biológicos não foram aprovadas na primeira análise, marcando uma grande mudança na transparência. Pela primeira vez, patrocinadores, clínicos e equipes de dados podem analisar o setor usando a própria linguagem da agência sobre deficiências clínicas, de CMC, segurança, rotulagem e bioequivalência, por meio de PDFs abertos, centralizados e disponíveis para download do FDA.
À medida que a FDA continua a liberar novos CRLs, a capacidade de gerar percepções rapidamente a partir desses e de outros dados não estruturados, e adicioná-los à sua inteligência/dados internos, torna-se uma grande vantagem competitiva. As organizações que conseguem aproveitar efetivamente as percepções desses dados não estruturados, na forma de PDFs, documentos, imagens e outros, podem reduzir o risco de suas próprias submissões, identificar armadilhas comuns e, por fim, acelerar seu caminho para o mercado. O desafio é que esses dados, como muitos outros dados regulatórios, estão presos em PDFs, que são notoriamente difíceis de processar em escala.
Este é exatamente o tipo de desafio que o Databricks foi criado para resolver. Este blog demonstra como usar as mais recentes ferramentas de IA do Databricks para acelerar a extração de informações importantes presas em PDFs, transformando esses documentos críticos em uma fonte de inteligência acionável.
O que é preciso para ter sucesso com IA
Dada a profundidade técnica necessária, os engenheiros muitas vezes lideram o desenvolvimento de forma isolada, criando uma grande lacuna entre a construção da IA e os requisitos de negócio. Quando um especialista no assunto (SME) vê o resultado, muitas vezes não é o que ele precisava. O ciclo de feedback é muito lento e o projeto perde o ritmo.
Durante as fases iniciais de teste, é crucial estabelecer uma linha de base. Em muitos casos, abordagens alternativas exigem a perda de meses sem verdades fundamentais, baseando-se, em vez disso, na observação subjetiva e em “vibes”. Essa falta de evidência empírica atrasa o progresso. Por outro lado, as ferramentas do Databricks fornecem recursos de avaliação prontos para uso e permitem que os clientes enfatizem a qualidade imediatamente, usando uma estrutura iterativa para obter confiança matemática na extração. O sucesso da AI exige uma nova abordagem baseada em iteração rápida e colaborativa.
O Databricks oferece uma plataforma unificada onde SMEs de negócios e engenheiros de IA podem trabalhar juntos em tempo real para construir, testar e implantar agentes com qualidade de produção. Esta estrutura se baseia em três princípios fundamentais:
- Alinhamento estreito entre negócios e área técnica: especialistas no assunto e líderes técnicos colaboram na mesma UI para obter feedback instantâneo, substituindo os lentos ciclos de email.
- Avaliação da Verdade Fundamental: Rótulos de "verdade fundamental" definidos pelo negócio são integrados diretamente ao fluxo de trabalho para pontuação formal.
- Uma Abordagem de Plataforma Completa: Isso não é uma sandbox ou uma solução pontual; está totalmente integrado com pipelines automatizados, avaliação LLM-como-Juiz, throughput de GPU confiável para produção e governança de ponta a ponta do Unity Catalog.
Essa abordagem de plataforma unificada é o que transforma um protótipo em um sistema de IA confiável e pronto para produção. Vamos percorrer os quatro passos para construí-lo.
Do PDF à produção: um guia de quatro etapas
Construir um sistema de IA com qualidade de produção sobre dados não estruturados requer mais do que apenas um bom modelo; requer um fluxo de trabalho contínuo, iterativo e colaborativo. O Information Extraction Agent Brick, combinado com as funções de AI integradas do Databricks, facilita a análise de documentos, a extração de informações key e a operacionalização de todo o processo. Essa abordagem capacita as equipes a agir mais rápido e entregar resultados de maior qualidade. Abaixo, detalhamos os quatro passos principais para a construção.
Passo 1: Análise de PDFs não estruturados em texto com ai_parse_document()
O primeiro obstáculo é extrair texto limpo dos PDFs. Os CRLs podem ter disposições complexas com cabeçalhos, rodapés, tabelas, gráficos, em várias páginas e em várias colunas. Uma extração de texto simples geralmente falhará, produzindo resultados imprecisos e inutilizáveis.
Diferentemente de soluções pontuais frágeis que têm dificuldade com a disposição, a ai_parse_document() utiliza IA multimodal de última geração para entender a estrutura do documento, extraindo o texto com precisão na ordem de leitura, preservando hierarquias de tabelas irregulares e gerando legendas para figuras.
Além disso, o Databricks oferece uma vantagem em inteligência de documentos ao escalar de forma confiável para lidar com volumes de nível empresarial de PDFs complexos a um custo de 3 a 5 vezes menor que o dos principais concorrentes. As equipes não precisam se preocupar com limites de tamanho de arquivo, e o OCR e o VLM internos garantem a análise precisa de “PDFs problemáticos” históricos que contêm figuras densas e irregulares e outras estruturas desafiadoras.
O que antes exigia que vários cientistas de dados configurassem e mantivessem pilhas de análise personalizadas de vários fornecedores agora pode ser realizado com uma única função nativa de SQL, permitindo que as equipes processem milhões de documentos em paralelo sem os modos de falha que afetam os analisadores menos escaláveis.
Para começar, primeiro aponte um Volume do UC para seu armazenamento em cloud que contém seus PDFs. Em nosso exemplo, vamos apontar a função SQL para os PDFs CRL gerenciados por um Volume:
Este único comando processa todos os seus PDFs e cria uma tabela estruturada com o conteúdo analisado e o texto combinado, deixando-o pronto para o próximo passo.
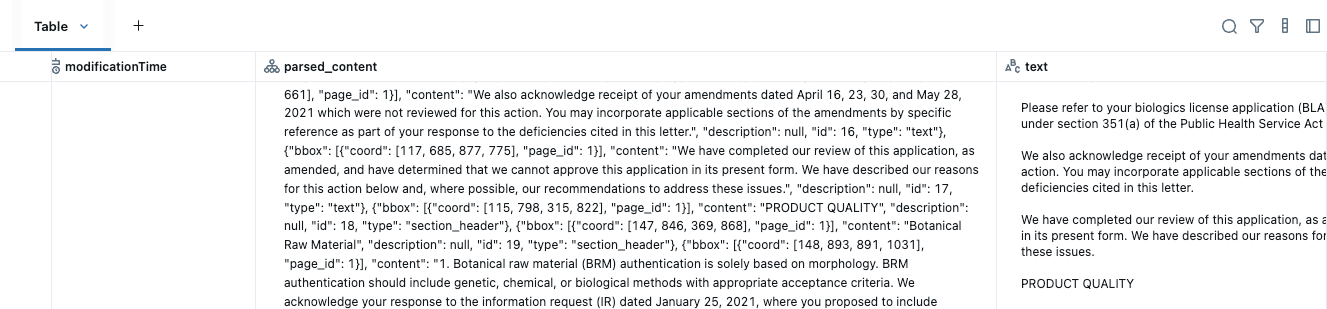
Observe que não precisamos configurar nenhuma infraestrutura, rede ou chamadas externas de LLM ou GPU. O Databricks hospeda as GPUs e o back-end do modelo, permitindo uma throughput confiável e escalável sem configuração adicional. Diferentemente das plataformas que cobram taxas de licenciamento, o Databricks usa um modelo de preços baseado em compute, o que significa que você paga apenas pelos recursos que usa. Isso permite otimizações de custo poderosas por meio da paralelização e da personalização no nível da função em seus pipelines de produção.
Passo 2: Extração iterativa de informação com Agent Bricks
Depois de ter o texto, o próximo objetivo é extrair campos específicos e estruturados. Por exemplo: Qual foi a deficiência? Qual foi o ID do NDA? Qual foi a citação de rejeição? É aqui que os engenheiros de IA e os SMEs de negócios precisam colaborar de perto. O SME sabe o que procurar e pode trabalhar com o engenheiro para instruir rapidamente o modelo sobre como encontrá-lo.
O Agent Bricks: Extração de Informações oferece uma UI colaborativa em tempo real para este fluxo de trabalho específico.
Conforme mostrado abaixo, a interface permite que um líder técnico e um especialista de negócios (SME) trabalhem juntos:
- O especialista de negócios fornece campos específicos que precisam ser extraídos (por exemplo,
deficiency_summary_paragraphs, NDA_ID, FDA_Rejection_Citing). - O Agente de Extração de Informações traduzirá esses requisitos em prompts eficazes — essas diretrizes editáveis estão no painel direito.
- Tanto o Líder Técnico quanto o Especialista de Negócios podem ver imediatamente a saída JSON no painel central e validar se o modelo está extraindo corretamente as informações do documento à esquerda. A partir daqui, qualquer um dos dois pode reformular um prompt para garantir extrações precisas.
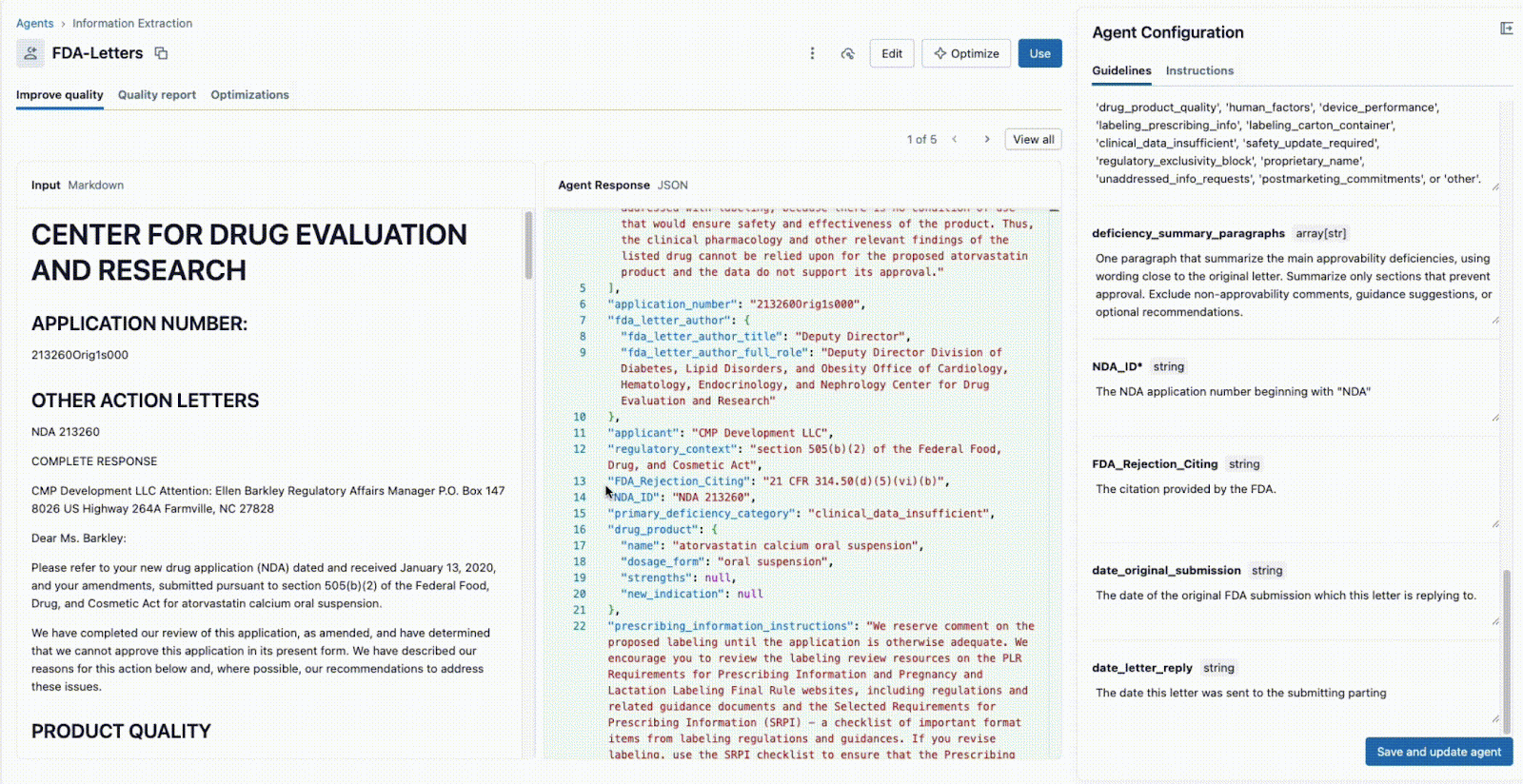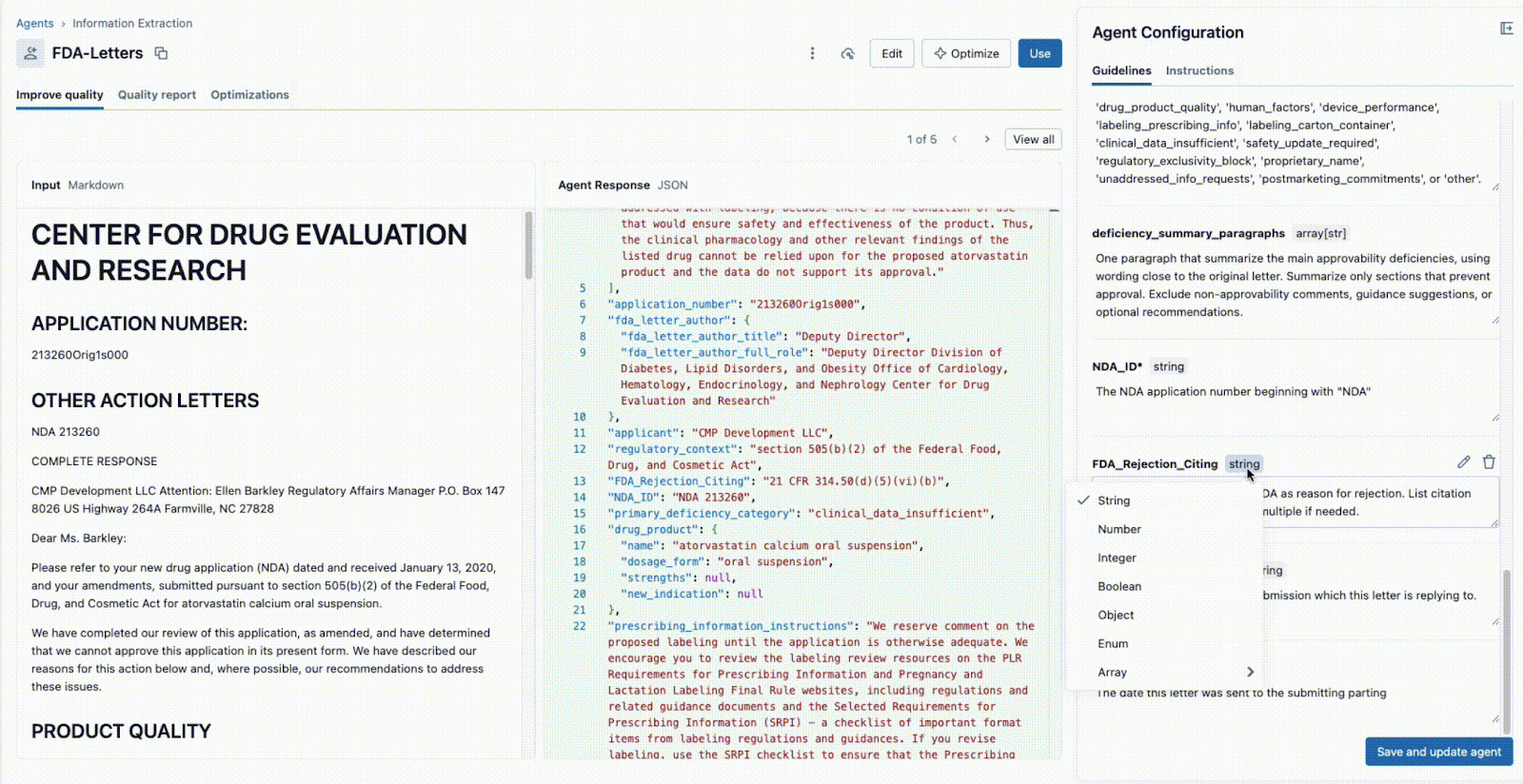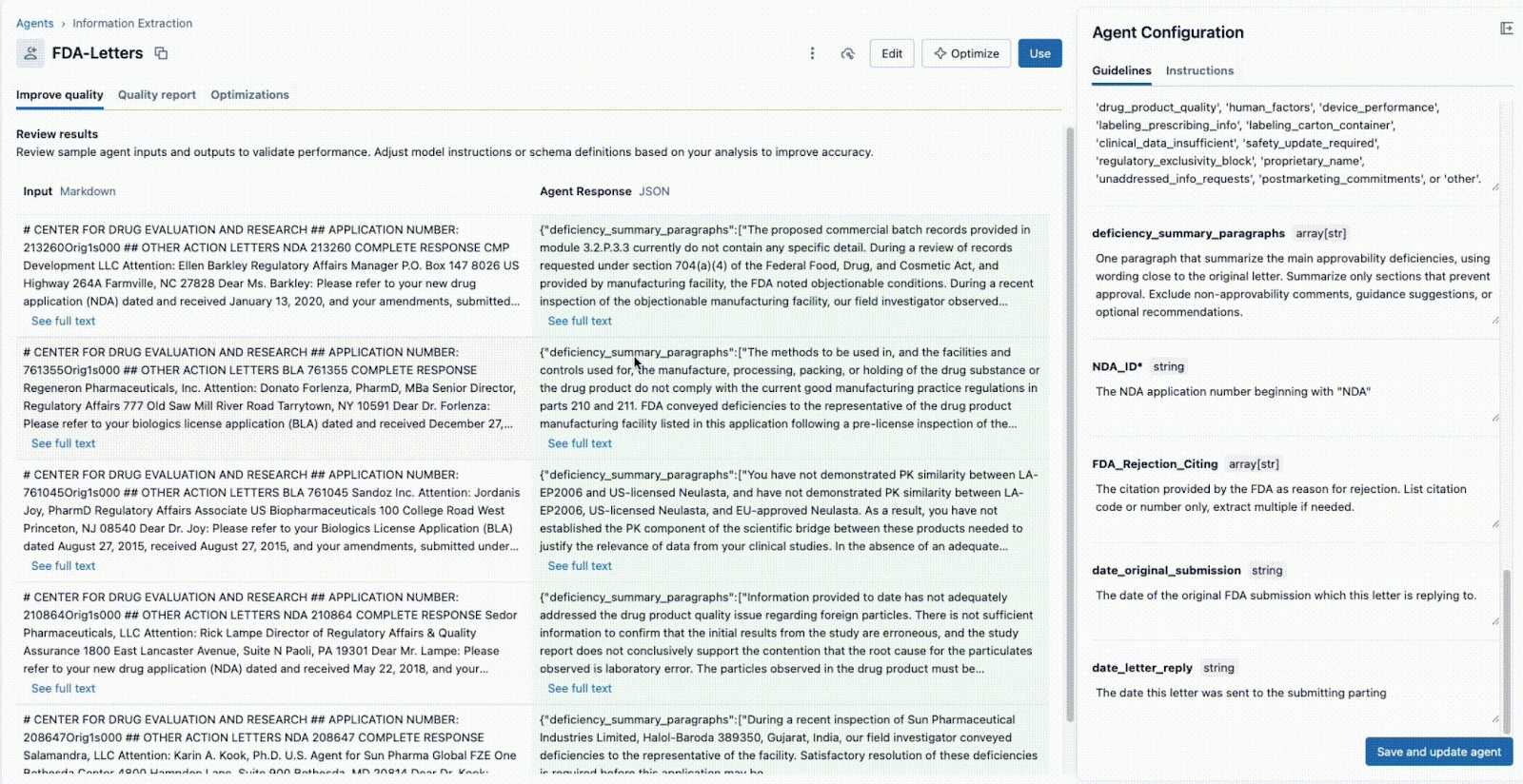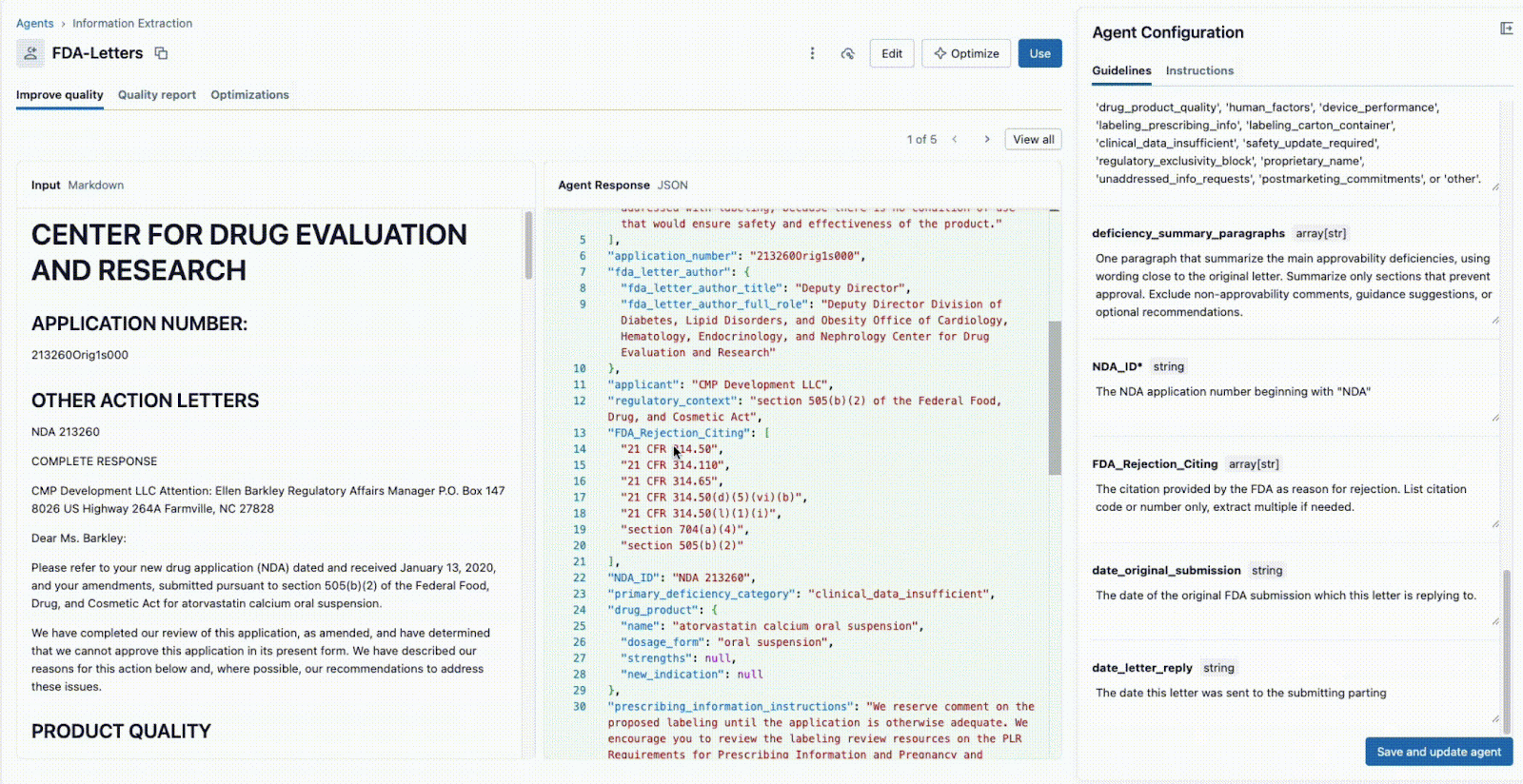
Esse ciclo de feedback instantâneo é a chave para o sucesso. Se um campo não for extraído corretamente, a equipe pode ajustar o prompt, adicionar um novo campo ou refinar as instruções e ver o resultado em segundos. Este processo iterativo, em que vários especialistas colaboram em uma única interface, é o que diferencia os projetos de IA bem-sucedidos daqueles que falham em silos.
Passo 3: Avalie e valide o agente
No passo 2, criamos um agente que, a partir de uma “verificação de vibe”, parecia correto durante o desenvolvimento iterativo. Mas como garantimos alta precisão и escalabilidade ao apresentar novos dados? Uma alteração no prompt que corrige um documento pode quebrar outros dez. É aqui que entra a avaliação formal, uma parte crítica e integrada do fluxo de trabalho do Agent Bricks.
Este passo é o seu portão de qualidade e fornece dois métodos poderosos para validação:
Método A: Avaliar com rótulos de ground truth (O padrão ouro)
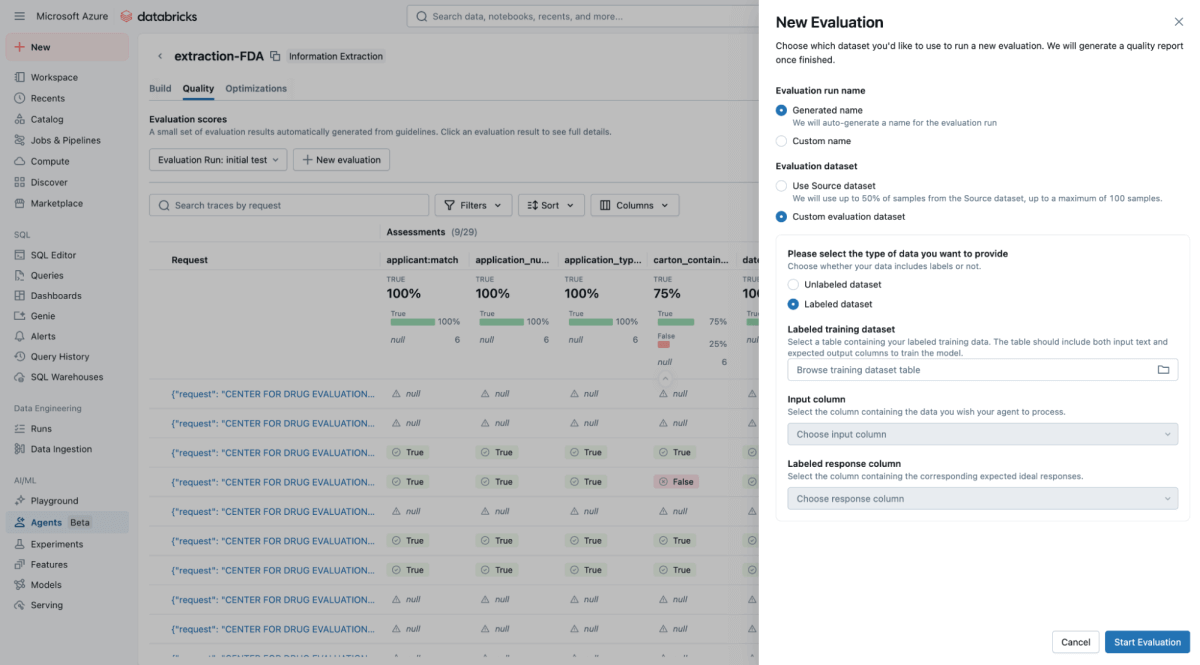
A IA, como qualquer projeto de ciência de dados, falha em um vacuum sem o conhecimento de domínio adequado. Um investimento dos SMEs para fornecer um "conjunto de ouro" (golden set), também conhecido como ground truth ou datasets rotulados, de informação correta e relevante, extraída manualmente e validada por humanos, ajuda muito a garantir que esta solução se generalize para novos arquivos e formatos. Isso ocorre porque os pares key-value rotulados ajudam rapidamente o agente a ajustar prompts de alta qualidade que levam a extrações precisas e relevantes para o negócio. Vamos ver em detalhes como o Agent Bricks usa esses rótulos para pontuar formalmente seu agente.
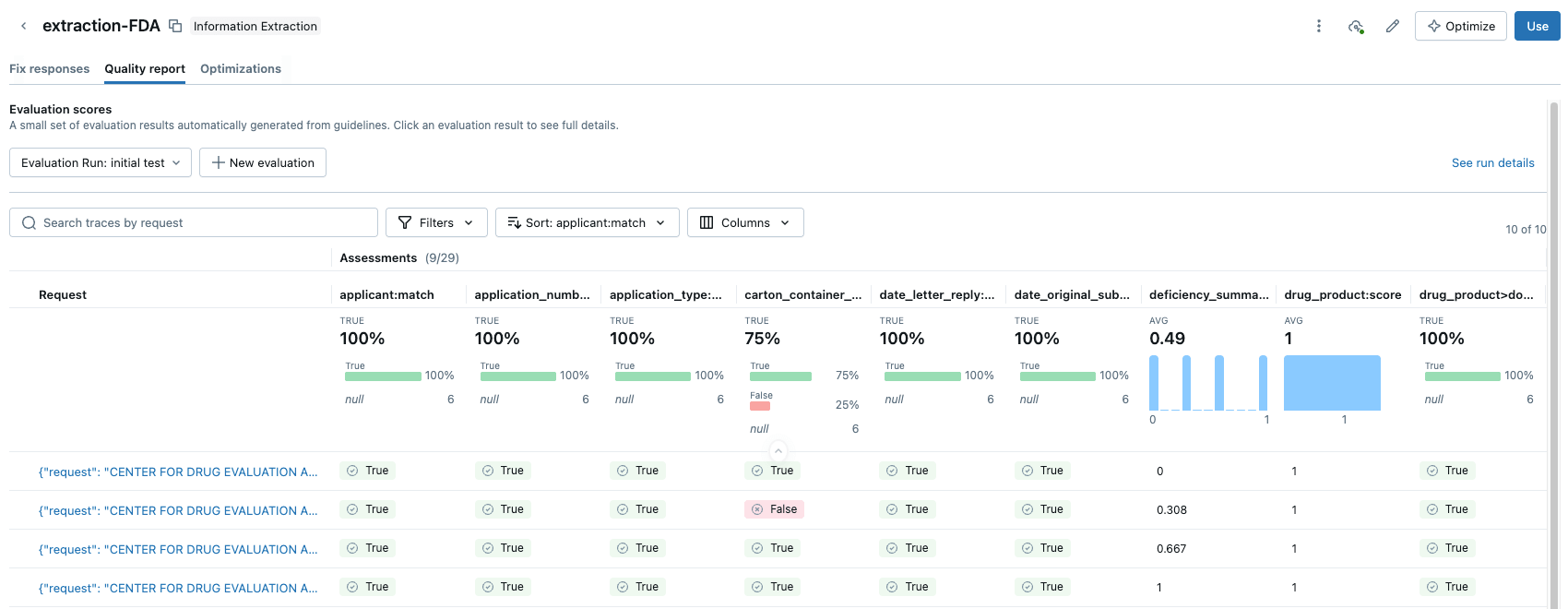
Na UI do Agent Bricks, forneça o testset de ground truth e, em segundo plano, o Agent Bricks é executado nos documentos de teste. A UI fornecerá uma comparação lado a lado da saída extraída do seu agente versus a resposta rotulada "correta".
A UI fornece uma pontuação de precisão clara para cada campo de extração, o que permite identificar regressões instantaneamente quando você altera um prompt. Com o Agent Bricks, você obtém confiança em nível de negócios de que o agente está operando com precisão igual ou acima da humana.
Método B: Sem rótulos? Use LLM como um juiz
Mas e se você estiver começando do zero e não tiver rótulos de referência? Este é um problema comum de "partida a frio".
O conjunto de avaliação Agent Bricks oferece uma solução poderosa: LLM-as-a-Judge. O Databricks oferece um conjunto de estruturas de avaliação, e o Agent Bricks usará modelos de avaliação para atuar como um avaliador imparcial. O modelo "Juiz" recebe o texto do documento original e um conjunto de prompts de campo para cada documento. A função do “Juiz” é gerar uma resposta "esperada" e, em seguida, avaliá-la em comparação com o resultado extraído pelo agente.
O LLM-as-a-Judge permite que você obtenha uma pontuação de avaliação escalável e de alta qualidade e, observe, também pode ser usado em produção para garantir que os agentes permaneçam confiáveis e generalizáveis à variabilidade e escala de produção. Mais sobre isso em um blog futuro.
Passo 4: Integração do Agent com ai_query() no seu pipeline de ETL
Neste ponto, você criou seu agente no passo 2 e validou sua precisão no passo 3, e agora tem a confiança para integrar a extração em seu fluxo de trabalho. Com um único clique, você pode implantar seu agente como um endpoint de modelo serverless — imediatamente, sua lógica de extração fica disponível como uma função simples e escalável.
Para fazer isso, use a função ai_query() em SQL para aplicar essa lógica a novos documentos à medida que eles chegam. A função ai_query() permite invocar qualquer endpoint de servindo modelo de forma direta e integrada em seu pipeline de dados de ETL de ponta a ponta.
Com isso, o Databricks Lakeflow Jobs garante que você tenha um pipeline de ETL totalmente automatizado e de nível de produção. Seu Job do Databricks pega os PDFs brutos que chegam ao seu armazenamento em cloud, os processa, extrai percepções estruturadas usando seu agente de alta qualidade e os armazena em uma tabela pronta para análise, geração de relatórios ou para serem referenciados na recuperação por um aplicativo de agente downstream.
O Databricks é a plataforma de IA de última geração, que quebra as barreiras entre as equipes profundamente técnicas e os especialistas de domínio que detêm o contexto necessário para construir IA significativa. O sucesso com IA não se resume a modelos ou infraestrutura; é a colaboração próxima e iterativa entre engenheiros e SMEs, onde cada um refina o pensamento do outro. O Databricks dá às equipes um ambiente único para desenvolver em conjunto, experimentar rapidamente, governar com responsabilidade e colocar a ciência de volta na ciência de dados.
O Agent Bricks é a personificação dessa visão. Com o ai_parse_document() para analisar conteúdo não estruturado, a interface de design colaborativa do Agent Bricks: Extração de Informação para acelerar extrações de alta qualidade e o ai_query() para aplicar a solução em pipelines de nível de produção, as equipes podem passar de milhões de PDFs desorganizados para percepções validadas mais rápido do que nunca.
Em nosso próximo blog, mostraremos como usar essas percepções extraídas e criar um agente de chat de nível de produção capaz de responder a perguntas em linguagem natural como: “Quais são os problemas mais comuns de prontidão de fabricação para medicamentos oncológicos?”
- Saiba mais: Leia a documentação oficial para ai_parse_document(), Agent Bricks: Extração de Informações e ai_query().
- Comece agora: Inscreva-se para um trial grátis do Databricks para criar suas próprias soluções com tecnologia de IA hoje mesmo.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.