Monitoramento Ambiental Contínuo Usando a Nova API transformWithState
Explorando um caso prático com a nova API de streaming com estado do Apache Spark™
por Thangam Vaiyapuri, Jay Palaniappan, Anish Shrigondekar e Karthikeyan Ramasamy
- Aprenda a construir pipelines de monitoramento operacional usando a nova API transformWithState do Spark 4.0
- Use ValueState, ListState e MapState para rastrear, alertar e analisar dados de sensores em várias cidades
- Aproveite recursos como TTL, timers e suporte a Pandas para melhorar a confiabilidade e a capacidade de depuração
As capacidades de streaming do Apache Spark™ evoluíram dramaticamente desde a sua criação, começando com um processamento simples e sem estado, onde cada lote operava de forma independente. A verdadeira transformação veio com a adição de capacidades de processamento com estado através de APIs como mapGroupsWithState e mais tarde flatMapGroupsWithState, permitindo que os desenvolvedores mantenham e atualizem o estado em micro-lotes de streaming. Essas operações com estado abriram possibilidades para processamento de eventos complexos, detecção de anomalias e reconhecimento de padrões em fluxos de dados contínuos.
A última adição do Apache Spark Structured Streaming, transformWithState, representa uma evolução significativa no processamento de fluxo com estado e oferece várias vantagens sobre seus predecessores,flatMapGroupsWithState e applyInPandasWithState,para executar processamento com estado arbitrário de forma mais eficaz. Com o Apache Spark 4.0, este framework alcançou novos patamares de expressividade e desempenho. Esta última evolução oferece o conjunto de ferramentas abrangente necessário para construir aplicações de dados em tempo real sofisticadas que mantêm o contexto ao longo do tempo enquanto processam milhões de eventos por segundo.
Análise Profunda do Cenário
Consideraremos os sistemas de monitoramento ambiental como exemplo para demonstrar as capacidades do transformWithStateInPandas, onde coletamos, processamos e analisamos fluxos contínuos de dados de sensores. Embora nosso exemplo se concentre em dados ambientais, a mesma abordagem se aplica a muitos casos de uso operacionais, como telemetria de equipamentos, rastreamento de logística ou automação industrial.
A Fundação
Imagine que você está monitorando a temperatura, umidade, níveis de CO2 e matéria particulada de um local ao longo de um período de tempo, e precisamos acionar um alerta se qualquer uma das médias dessas medições ultrapassar ou ficar abaixo de um limite.
É aqui que as APIs ValueState entram em jogo. Eles podem ser usados para armazenar estado como primitivas ou estruturas complexas. Vamos ver como funciona.
Implementação do ValueState
Vamos começar com um único sensor. A cada poucos segundos, este sensor envia uma leitura que se parece com a seguinte:
Para cada sensor, localização e cidade, precisamos manter um estado que acompanhe não apenas as condições atuais, mas também o contexto histórico. Você pode pensar nisso como a memória do sensor, mantendo o controle de tudo, desde a última leitura de timestamp até o número de alertas gerados. Projetamos nosso esquema ValueState para capturar este quadro completo:
Armazenando Dados Ambientais em uma Tabela Delta
Depois de definir nosso processador com estado como TemperatureMonitor, passaremos o processador para o operador transformWithStateInPandas e persistiremos a saída em uma tabela Delta. Isso garante que os dados do TemperatureMonitor estejam disponíveis para serviços externos e análises.
Inspeção da Saída
Vamos olhar os dados processados por TemperatureMonitor e armazenados nas tabelas Delta de saída. Ela possui as leituras ambientais de vários sensores em diferentes locais (Paris, Nova York, Londres, Tóquio e Sydney) junto com seus alertas acionados.
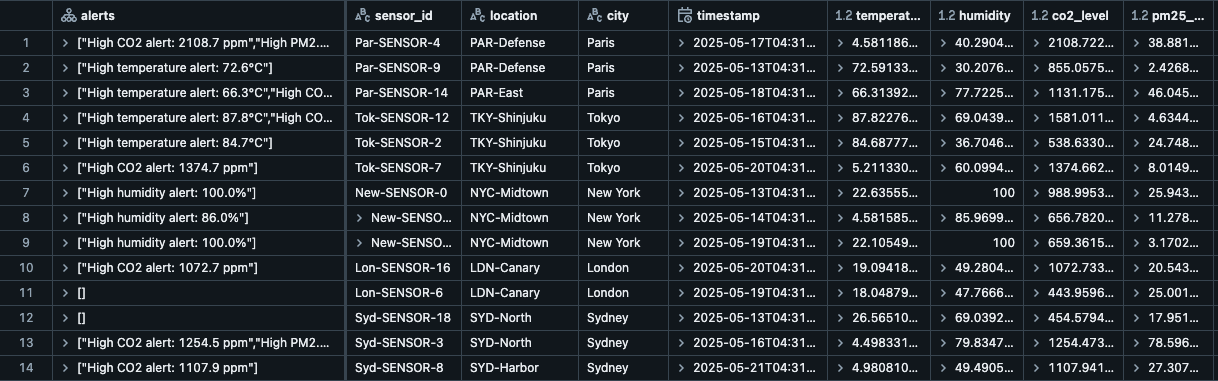
Como você pode ver, transformWithState nos ajuda a processar efetivamente o estado e emitir vários alertas ambientais para alta umidade, temperatura, níveis de CO2, etc., em diferentes localizações.
Gerenciando Histórico Ambiental
Agora, vamos imaginar uma cidade onde sensores monitoram continuamente as condições ambientais em diferentes localizações. Quando ocorre um pico de temperatura, os administradores da cidade podem precisar saber: Isso é um problema localizado ou um problema em toda a cidade?
As APIs ListState estendem o gerenciamento de estado para lidar com coleções ordenadas, perfeitas para dados de séries temporais e análise histórica. Isso se torna crucial ao rastrear padrões e tendências ao longo de uma linha do tempo ou de um limite arbitrário que escolhemos.
Implementação do ListState - Armazenamento Histórico Inteligente para Cidades
Vamos considerar um cenário onde uma cidade contém vários sensores transmitindo dados constantemente. Quando qualquer localização dentro da cidade relata uma temperatura que excede nosso limite de 25°C, então capturamos os dados e os armazenamos em uma ListState consciente do tempo:
No exemplo abaixo, usamos a classe EnvironmentalMonitorListProcessor e ListState junto com o TTL (Time To Live) integrado para manter este histórico dos dados do sensor com uma atualização de uma hora:
Expirar Valores de Estado Antigos usando Tempo de Vida (TTL)
Os valores de estado usados pela transformWithState suportam um valor opcional de tempo de vida (TTL), que é calculado com base no tempo de processamento do valor mais uma duração definida em milissegundos. Quando o TTL expira, o valor correspondente é removido da loja de estado.
O TTL com ListState é crucial para manter automaticamente apenas os dados relevantes dentro de um objeto de estado, pois remove automaticamente os registros desatualizados após um período de tempo especificado.
Neste exemplo, o TTL garante que as análises em toda a cidade permaneçam atuais e relevantes. Cada entrada de estado recebe um carimbo de data/hora de expiração, e uma vez que expira, o estado é limpo automaticamente, prevenindo o crescimento ilimitado do estado enquanto mantém o contexto histórico recente da cidade.
Reconhecimento de Padrões em Toda a Cidade
Com o histórico armazenado no objeto ListState, podemos identificar padrões e realizar vários cálculos. Por exemplo, em EnvironmentalMonitorListProcessor determinamos as tendências de temperatura comparando a leitura atual com a leitura histórica mais recente.
Configuração de Consulta de Streaming
Agora vamos conectar o EnvironmentalMonitorListProcessor em um pipeline de streaming, armazenar os resultados em uma tabela Delta e inspecioná-los mais adiante.
Inspeção da Saída

Como você pode ver na captura de tela acima, a tabela Delta agora mostra análise temporal em diferentes localizações. Ao combinar o armazenamento temporal do ListState com a análise em nível de cidade, criamos um sistema que não apenas detecta problemas ambientais, mas entende seu contexto e evolução em cidades inteiras. As APIs ListState, juntamente com a gestão de TTL, fornecem uma maneira eficiente de lidar com dados ambientais históricos, evitando o crescimento ilimitado do estado, tornando-o ideal para sistemas de monitoramento ambiental em toda a cidade.
Realizando Análises Baseadas em Localização
Agora, vamos imaginar um cenário em que planejadores de cidades inteligentes implantam sensores ambientais em diversas zonas urbanas - desde interseções movimentadas do centro da cidade até bairros residenciais e complexos industriais. Cada zona possui padrões ambientais únicos que variam de acordo com a hora do dia e a estação do ano.
Usando as APIs MapState, o sistema pode manter leituras ambientais específicas do local e identificar locais onde as leituras excedem os limites aceitáveis. Esta arquitetura usa localizações da cidade como chaves para monitoramento paralelo em vários ambientes, preservando os valores máximos de medição para rastrear tendências ambientais importantes enquanto evita o crescimento ilimitado do estado.
O EnvironmentalMonitorProcessor aproveita as sofisticadas capacidades de armazenamento de chave-valor do MapState para organizar dados por localização dentro das cidades. Isso permite a análise em tempo real de condições em mudança em diferentes ambientes urbanos, transformando dados brutos de sensores em inteligência acionável para o gerenciamento ambiental urbano.
Lógica de Processamento
A estrutura MapState é inicializada com a localização como chave da seguinte forma:
O processo de atualização de estado em nossa implementação leva os valores máximos para cada parâmetro ambiental, garantindo que rastreamos os níveis máximos de poluição em cada local:
Configuração de Consulta de Streaming
A implementação agora pode ser integrada em um pipeline de Streaming Estruturado Spark da seguinte maneira:
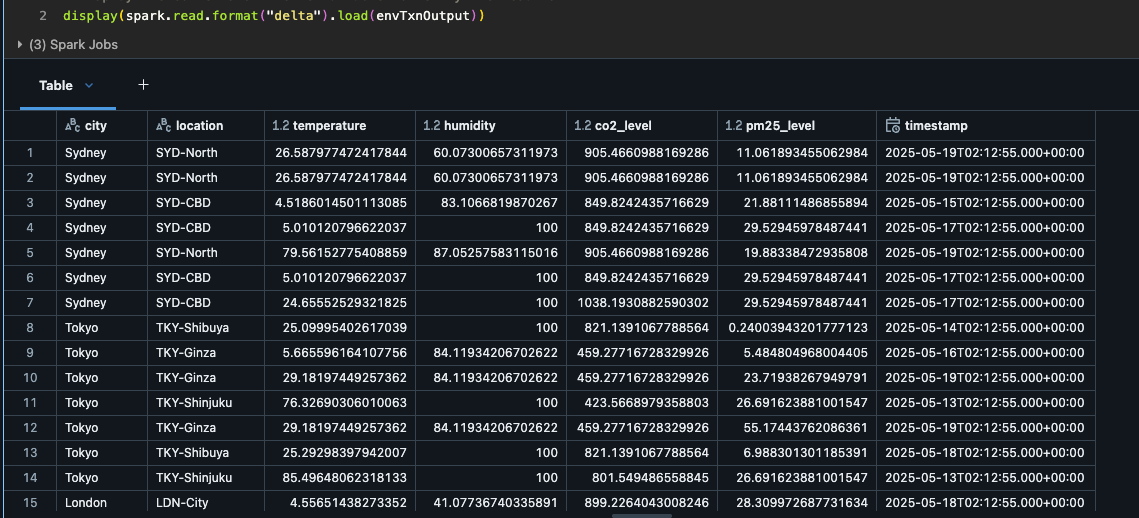
Inspeção da Saída
A saída da tabela Delta agora mostra um monitoramento ambiental abrangente em vários locais/cidades.
Juntando Tudo
Nas seções acima, mostramos como vários casos de uso de monitoramento ambiental podem ser facilmente suportados usando a nova API transformWithState no Apache Spark. Em resumo, a implementação acima pode habilitar os seguintes casos de uso:
- Monitoramento de limite de múltiplos parâmetros: Detecção em tempo real de violações em temperatura, umidade, CO2 e níveis de PM2.5
- Alerta em tempo real: Notificação imediata de mudanças nas condições ambientais
- Monitoramento paralelo da cidade: Rastreamento independente de várias áreas urbanas
Melhor Capacidade de Depuração e Observabilidade
Junto com o código do pipeline mostrado acima, um dos recursos mais poderosos da nova API transformWithState é sua integração perfeita com o leitor de estado no Apache Spark. Esta capacidade fornece uma visibilidade sem precedentes do estado interno mantido pelo nosso sistema de monitoramento ambiental, tornando o desenvolvimento, a depuração e o monitoramento operacional significativamente mais eficazes.
Acessando Informações de Estado
Ao gerenciar um sistema crítico de monitoramento ambiental em várias cidades, entender o estado subjacente é essencial para solucionar anomalias, verificar a integridade dos dados e garantir o funcionamento adequado do sistema. O leitor de fonte de dados de estado nos permite consultar tanto metadados de alto nível quanto valores de estado detalhados.
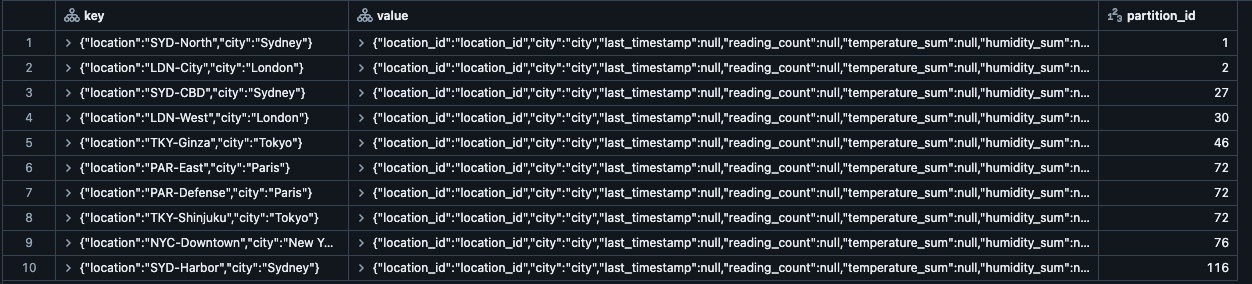
Inspeção da Saída
Como mostrado na captura de tela abaixo, os usuários agora podem obter acesso detalhado a todas as suas linhas de estado para todos os tipos compostos, aumentando assim a capacidade de depuração e observabilidade desses pipelines.
Conclusão
A API transformWithState do Apache Spark™ 4.0 representa um avanço significativo para o processamento de estado arbitrário em aplicações de streaming. Com o caso de uso de monitoramento ambiental acima, mostramos como os usuários podem construir e executar cargas de trabalho operacionais poderosas usando a nova API. Sua abordagem orientada a objetos e conjunto de recursos robustos permitem o desenvolvimento de pipelines de streaming avançados que podem lidar com requisitos complexos enquanto mantêm a confiabilidade e o desempenho. Incentivamos todos os usuários do Spark a experimentar a nova API para seus casos de uso de streaming e aproveitar todos os benefícios que esta nova API tem a oferecer!
Você pode baixar o código acima aqui: https://github.com/databricks-solutions/databricks-blogposts/tree/main/2025-05-transformWithStateInPandas/python/environmentalMonitoring
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.