Continuous Environmental Monitoring Using the New transformWithState API
Exploring a practical use case with Apache Spark’s™ new stateful streaming API
by Thangam Vaiyapuri, Jay Palaniappan, Anish Shrigondekar and Karthikeyan Ramasamy
- Learn to build operational monitoring pipelines using Spark 4.0’s new transformWithState API
- Use ValueState, ListState, and MapState to track, alert on, and analyze sensor data across cities
- Take advantage of features like TTL, timers, and Pandas support to improve reliability and debuggability
Apache Spark's™ streaming capabilities have evolved dramatically since their inception, beginning with simple stateless processing where each batch operated independently. The true transformation came with the addition of stateful processing capabilities through APIs like mapGroupsWithState and later flatMapGroupsWithState, enabling developers to maintain and update state across streaming micro-batches. These stateful operations opened possibilities for complex event processing, anomaly detection, and pattern recognition in continuous data streams.
Apache Spark Structured Streaming's latest addition, transformWithState, represents a significant evolution in stateful stream processing and offers several advantages over its predecessors,flatMapGroupsWithState and applyInPandasWithState,to run arbitrary stateful processing more effectively. With Apache Spark 4.0, this framework has reached new heights of expressiveness and performance. This latest evolution delivers the comprehensive toolset needed for building sophisticated real-time data applications that maintain context across time while processing millions of events per second.
Scenario Deep-Dive
We will consider environmental monitoring systems as an example to demonstrate transformWithStateInPandas capabilities, where we collect, process, and analyze continuous streams of sensor data. While our example focuses on environmental data, the same approach applies to many operational use cases, such as equipment telemetry, logistics tracking, or industrial automation.
The Foundation
Imagine you're monitoring the temperature, humidity, CO2 levels, and particulate matter of a location over a period of time, and we need to trigger an alert if any of the average values of these measurements go above to below a threshold.
This is where the ValueState APIs come into play. They can be used to store state as primitives or complex structs. Let’s see how it works.
ValueState Implementation
Let's start with a single sensor. Every few seconds, this sensor sends a reading that looks like the following:
For each sensor, location, and city, we need to maintain a state that tracks not just the current conditions but also the historical context. You can think of this as the sensor's memory, keeping track of everything from the last timestamp read to the number of alerts generated. We design our ValueState schema to capture this complete picture:
Storing Environmental Data in a Delta Table
After defining our stateful processor as TemperatureMonitor, we'll pass the processor to the transformWithStateInPandas operator and persist the output in a Delta table. This ensures that TemperatureMonitor's data is available for external services and analysis.
Inspecting the Output
Let’s look at the data processed by TemperatureMonitor and stored in the output Delta tables. It has the environmental readings from multiple sensors across different locations (Paris, New York, London, Tokyo, and Sydney) along with their triggered alerts.
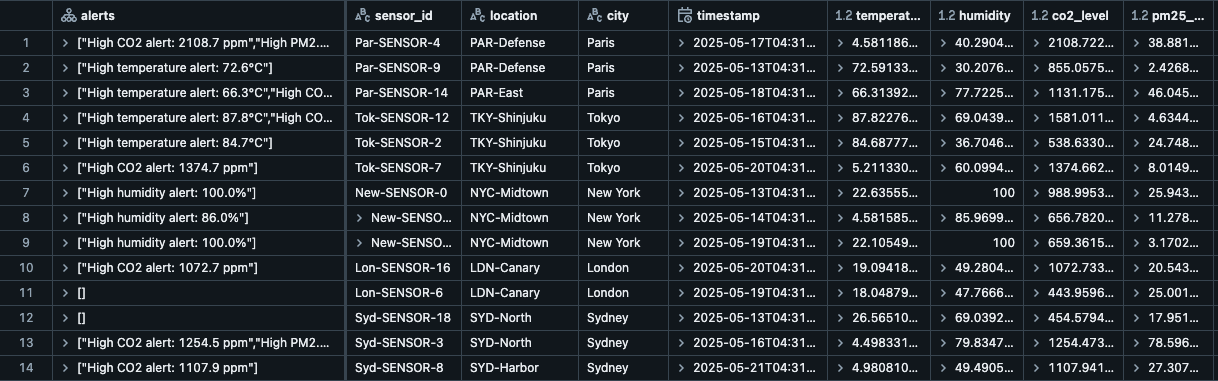
As you can see, transformWithState helps us effectively process state and raise various environmental alerts for high humidity, temperature, CO2 levels, etc., across different locations.
Managing Environmental History
Now let’s imagine a city where sensors continuously monitor environmental conditions across different locations. When a temperature spike occurs, the city administrators might need to know: Is this a localized issue or a city-wide issue?
ListState APIs extend state management to handle ordered collections, perfect for time-series data and historical analysis. This becomes crucial when tracking patterns and trends across a timeline or an arbitrary boundary that we choose.
ListState Implementation - Smart Historical Storage for Cities
Let’s consider a scenario where a city contains multiple sensors streaming data constantly. When any location within the city reports a temperature exceeding our threshold of 25°C, then we capture the data and store it in a time-aware ListState:
In the below example, we use the EnvironmentalMonitorListProcessor class and ListState along with the built-in TTL (Time To Live) to maintain this history of the sensor data with a one-hour freshness:
Expire Old State Values using Time to Live(TTL)
The state values used by transformWithState support an optional time to live (TTL) value, which is calculated based on the value’s processing time plus a set duration in milliseconds. When the TTL expires, the corresponding value is evicted from the state store.
TTL with ListState is crucial for automatically maintaining only relevant data within a state object, as it automatically removes outdated records after a specified time period.
In this example, TTL ensures that city-wide analytics remain current and relevant. Each state entry gets an expiration timestamp, and once it expires, the state is cleared automatically, preventing unbounded state growth while maintaining the city's recent historical context.
City-Wide Pattern Recognition
With the stored history in the ListState object, we can spot patterns and perform various calculations. For example, in EnvironmentalMonitorListProcessor we determine temperature trends by comparing the current reading with the most recent historical reading.
Streaming Query Setup
Now let’s wire EnvironmentalMonitorListProcessor into a streaming pipeline, store the results in a Delta table, and inspect them further.
Inspecting the Output

As you see in the screenshot above, the Delta table now shows temporal analysis across locations. By combining ListState's temporal storage with city-level analysis, we've created a system that not only detects environmental issues but understands their context and evolution across entire cities. The ListState APIs coupled with TTL management provide an efficient way to handle historical environmental data while preventing unbounded state growth, making it ideal for city-wide environmental monitoring systems.
Performing Location-Based Analytics
Now let’s imagine a scenario where smart city planners deploy environmental sensors across diverse urban zones - from busy downtown intersections to residential neighborhoods and industrial complexes. Each zone has unique environmental standards that vary by time of day and season.
Using MapState APIs, the system can maintain location-specific environmental readings and identify locations where readings exceed acceptable thresholds. This architecture uses city locations as keys for parallel monitoring across multiple environments, preserving maximum measurement values to track important environmental trends while preventing unbounded state growth.
The EnvironmentalMonitorProcessor leverages MapState's sophisticated key-value storage capabilities to organize data by location within cities. This allows for real-time analysis of changing conditions across different urban environments, transforming raw sensor data into actionable intelligence for urban environmental management.
Processing Logic
The MapState structure is initialized with the location as the key as follows:
The state update process in our implementation takes the maximum values for each environmental parameter, ensuring we track peak pollution levels at each location:
Streaming Query Setup
The implementation can now be integrated into a Spark Structured Streaming pipeline as follows:
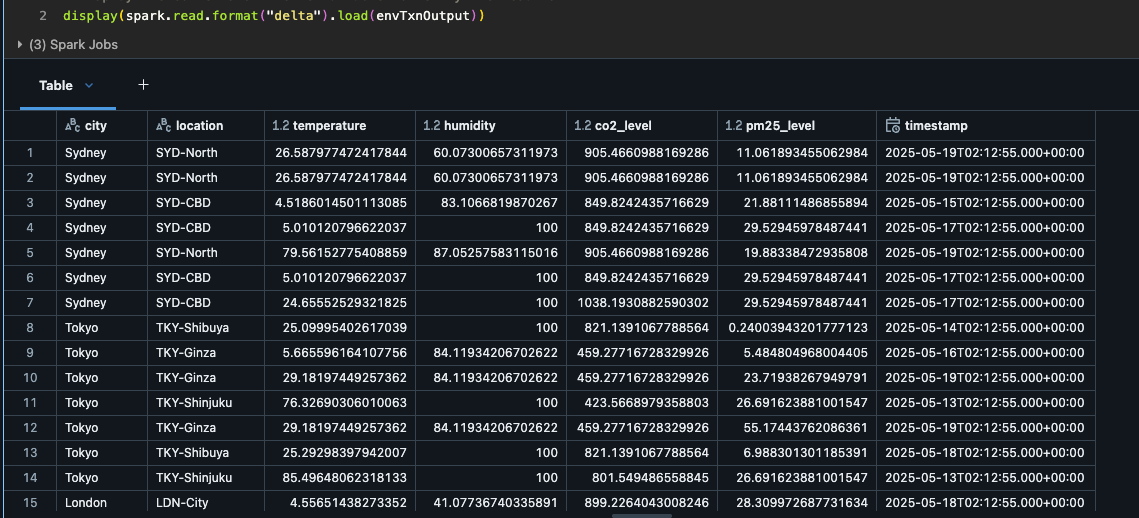
Inspecting the Output
The Delta table output now shows comprehensive environmental monitoring across multiple locations/cities.
Putting it Together
In the sections above, we have shown how various environmental monitoring use cases can be easily supported using the new transformWithState API in Apache Spark. In summary, the implementation above can enable the following use cases:
- Multi-parameter threshold monitoring: Real-time detection of violations across temperature, humidity, CO2, and PM2.5 levels
- Real-time alerting: Immediate notification of environmental condition changes
- Parallel city monitoring: Independent tracking of multiple urban areas
Enhanced Debuggability and Observability
Along with the pipeline code shown above, one of the new transformWithState API's most powerful features is its seamless integration with the state reader in Apache Spark. This capability provides unprecedented visibility into the internal state maintained by our environmental monitoring system, making development, debugging, and operational monitoring significantly more effective.
Accessing State Information
When managing a critical environmental monitoring system across multiple cities, understanding the underlying state is essential for troubleshooting anomalies, verifying data integrity, and ensuring proper system operation. The state data source reader allows us to query both high-level metadata and detailed state values.
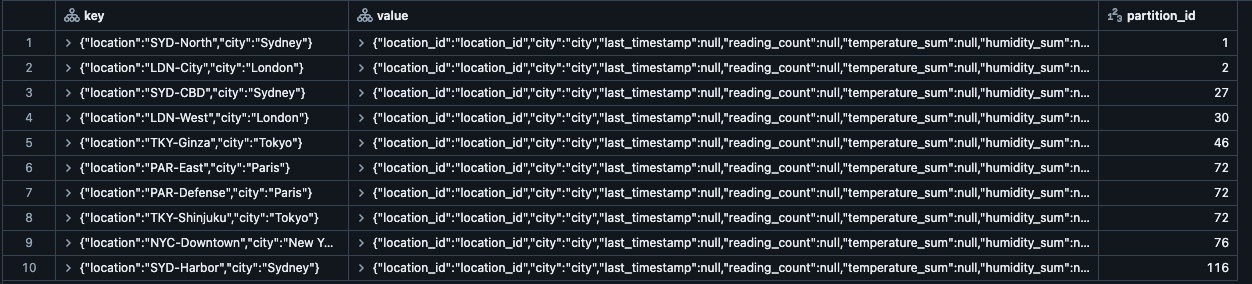
Inspecting the Output
As shown in the screenshot below, users can now get fine-grained access to all of their state rows for all composite types, thereby greatly increasing the debuggability and observability of these pipelines.
Conclusion
Apache Spark™ 4.0's transformWithState API represents a significant advancement for arbitrary stateful processing in streaming applications. With the environmental monitoring use case above, we have shown how users can build and run powerful operational workloads using the new API. Its object-oriented approach and robust feature set enable the development of advanced streaming pipelines that can handle complex requirements while maintaining reliability and performance. We encourage all Spark users to try out the new API for their streaming use cases and take advantage of all the benefits this new API has to offer!
You can download the above code here: https://github.com/databricks-solutions/databricks-blogposts/tree/main/2025-05-transformWithStateInPandas/python/environmentalMonitoring
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.