Databricks para a Fundação Good and Virtue: Parceria para Conectar Voluntários Médicos a Serviços de Saúde Críticos em 72 Países
por Priyanka Mehta e Shaunak Sen
- A Fundação Virtue fez uma parceria com a Databricks for Good para alavancar a IA e melhorar os resultados globais de saúde.
- O resultado permitiu que a Fundação Virtue combinasse melhor as habilidades dos médicos com oportunidades de voluntariado em países em desenvolvimento, onde essas habilidades são mais necessárias.
- Juntas, as equipes da Databricks e da Fundação Virtue estão fornecendo conjuntos de dados principais atualizados em um formato prontamente acessível e acionável.
Introdução
A Virtue Foundation é uma organização sem fins lucrativos focada na prestação de cuidados de saúde globais e na criação de um mercado eficiente para filantropia de saúde global. Até o momento, eles forneceram cuidados a mais de 50.000 pacientes com foco especial em Gana e Mongólia. A espinha dorsal deste mercado é a curadoria de dados de instalações de saúde globais através do VF Match, uma plataforma que conecta profissionais médicos a oportunidades de voluntariado em 72 países de baixa e média-baixa renda. A Databricks for Good tem feito parceria próxima com a Virtue Foundation desde 2024 para alavancar IA na agregação de dados desses países e torná-los acionáveis.
Um conceito de prova inicial demonstrou que LLMs poderiam extrair informações estruturadas de fontes de dados web díspares para criar um mapa da infraestrutura de saúde e, mais importante, as lacunas nos serviços em áreas com poucos recursos. No entanto, escalar essa funcionalidade e movê-la para produção apresentou muitos desafios. Desde essa primeira iteração, construímos uma plataforma baseada em Databricks que transformou o POC em um sistema de nível de produção, agregando dados de milhares de instalações de saúde e ONGs em todo o mundo.
Neste artigo, detalhamos como melhoramos nosso trabalho anterior para permitir que a Virtue Foundation corresponda melhor sua comunidade de voluntários médicos com necessidades críticas nesses países.
Construindo a Base: 72 Países de Dados de Saúde
O núcleo do VF Match é o Foundational Data Refresh (FDR): um conjunto de dados abrangente de instalações de saúde e ONGs construído do zero a partir de várias fontes baseadas na web. Nós ingerimos e atualizamos sistematicamente dados de 72 países de baixa e média-baixa renda em todo o mundo.
Duas fontes de dados complementares alimentam esta atualização:
- Overture Maps: Um conjunto de dados geoespaciais de código aberto da Meta e Microsoft, fornecendo locais autoritativos para instalações de saúde.
- Bright Data: Infraestrutura industrial de web scraping que captura informações em tempo real de toda a internet.
O coração do FDR é um pipeline de extração de informações alimentado pelos modelos GPT da OpenAI. Processar mais de 25 milhões de páginas da web com LLMs com garantias de produção exigiu repensar os pipelines tradicionais de inferência de LLM. Em vez de tentar extração one-shot, nosso pipeline divide a tarefa em etapas direcionadas: classificar relevância médica, identificar o tipo de organização (seja uma instalação médica ou ONG) e extrair especialidades, equipamentos e procedimentos.
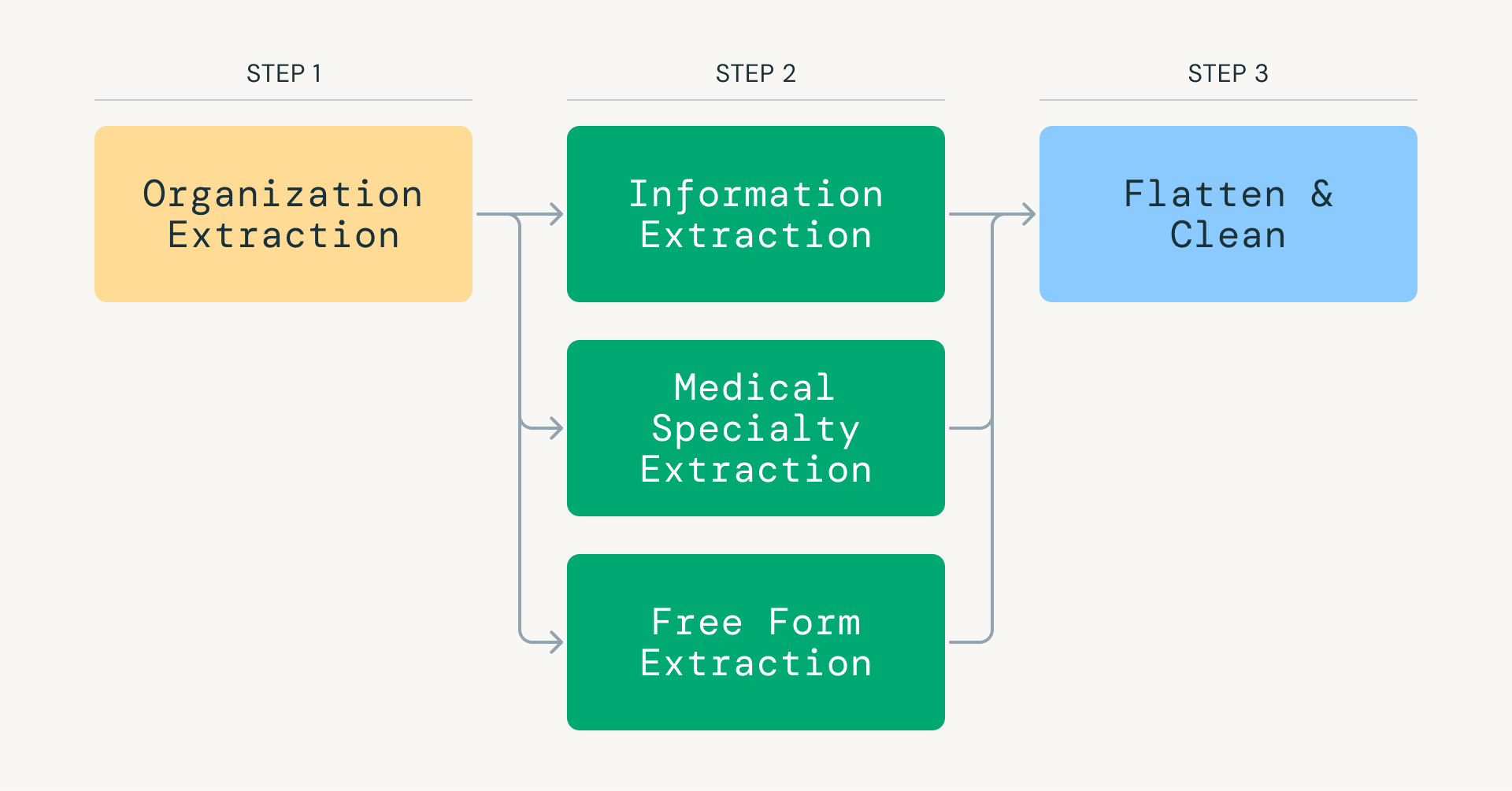 Fig 1: Etapas chave do Foundational Data Refresh (FDR).">
Fig 1: Etapas chave do Foundational Data Refresh (FDR).">Essa abordagem reduz drasticamente o consumo de tokens, focando cada invocação de modelo em uma tarefa estreita e de alta precisão. Databricks e Apache Spark são usados para orquestrar e paralelizar eficientemente os dados raspados, distribuindo cargas de trabalho por milhares de executores e permitindo inferência de LLM de alto rendimento.
Vários recursos críticos tornam este pipeline escalável e pronto para produção:
- Modelagem de dados extensível: Os dados em cada etapa são armazenados em um esquema estrela, simplificando análises downstream e melhorando o desempenho de consultas.
- Checkpointing baseado em status: Cada registro rastreia seu estado de processamento, permitindo que os pipelines retomem de qualquer ponto sem reprocessar linhas com chamadas caras de LLM.
- Registro de extração configurável: Cada método de extração é controlado por um objeto estruturado especificando o prompt do sistema, tornando a lógica de extração modular, reproduzível e extensível.
- Processamento distribuído escalável: O sistema processa cargas de trabalho enviesadas e de vários terabytes usando Spark para paralelismo, Photon para desempenho em escala e orquestração de nível de produção.
Essas garantias são aplicadas através dos Lakeflow Jobs, que orquestram mais de 15 tarefas interdependentes com ramificação condicional, execução paralela e políticas inteligentes de retentativa. O resultado é um sistema que processa dados de instalações de saúde em escala com a precisão de especialistas médicos.
Resolução de Entidades em Escala
Uma vez que os dados de instalações e ONGs são raspados e extraídos usando um LLM, um desafio clássico surge: resolução de entidades. A mesma instalação pode aparecer em várias fontes de dados com variações de nome, endereços inconsistentes ou detalhes de contato ausentes. A deduplicação tradicional falha nesses cenários devido a dados bagunçados, então usamos Splink, um framework de linkage probabilístico de registros de código aberto. Usando as informações obtidas em nossa etapa de IE, Splink avalia pares correspondentes através de comparações ponderadas em campos como número de telefone, endereço de rua e mais. O resultado é uma chave unificada por instalação, garantindo que os usuários finais vejam um registro autoritativo para cada instalação médica e ONG.
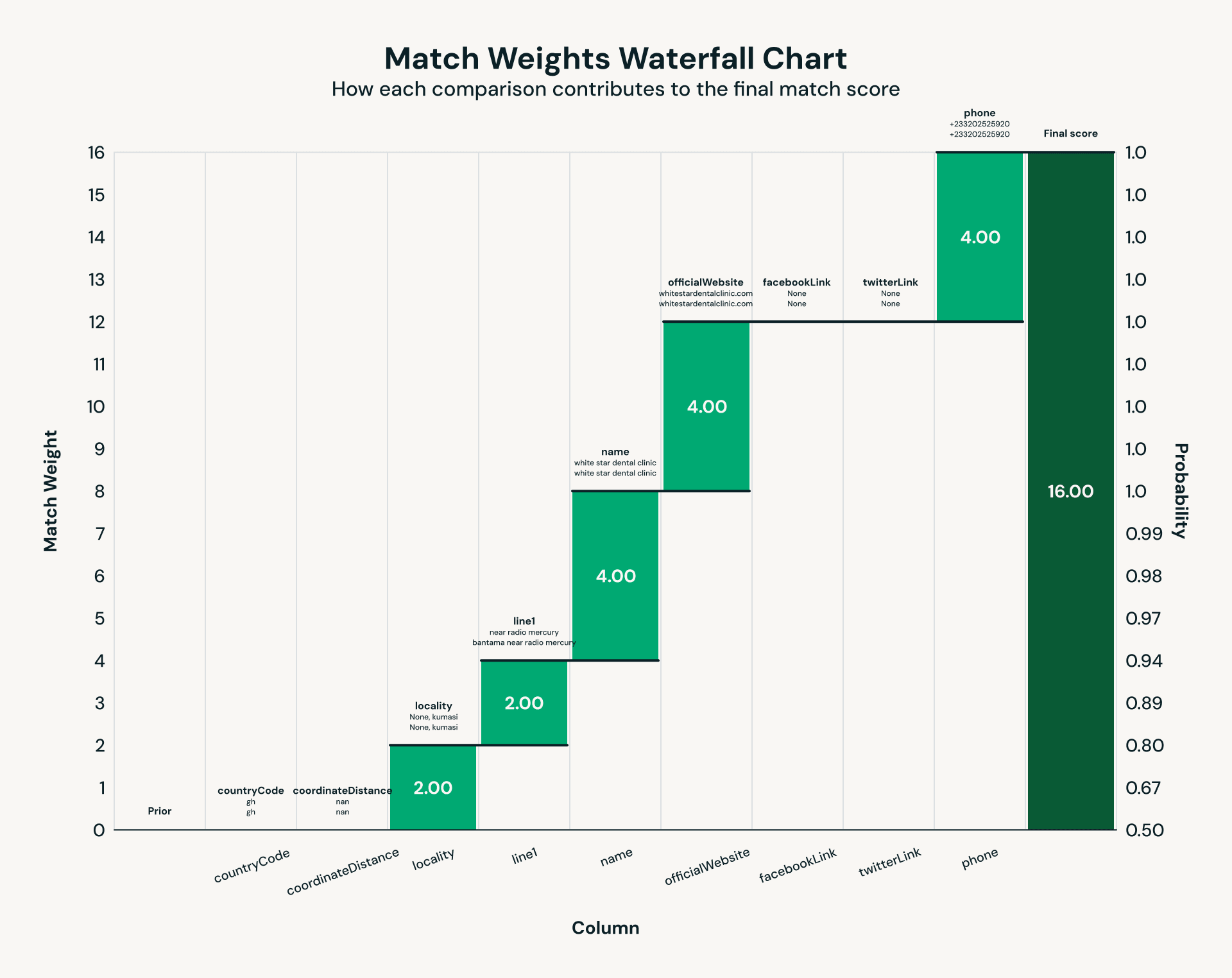 Fig 2: Exemplo de conjunto de regras para resolução de entidades via Splink.">
Fig 2: Exemplo de conjunto de regras para resolução de entidades via Splink.">Executar correspondência probabilística em milhares de instalações de saúde e ONGs revelou gargalos de desempenho clássicos que surgem em escala de terabytes. O núcleo do linkage de registros é a comparação par a par, que cria cargas de trabalho inerentemente enviesadas: comparações comuns produzem partições massivas, enquanto a maioria das outras permanece muito menor. Execuções iniciais deixaram isso dolorosamente claro, com uma partição Spark rodando por 30 minutos enquanto a mediana completava em 52 segundos – um caso clássico de stragglers (a “maldição do último redutor”) degradando o desempenho do job. Habilitar o Photon, o motor de consulta vetorizado da Databricks, reduziu as partições de dados de pior caso de 30 minutos para aproximadamente 2 minutos: uma melhoria de 15x.
VF Agent: Linguagem Natural Encontra Dados de Saúde
Olhando para o futuro, desenvolvemos um protótipo de um agente que permite aos especialistas analisar dados usando linguagem natural. Usamos uma arquitetura multi-agente construída em LangGraph e alavancamos Databricks Model Serving, AI Search e Genie.
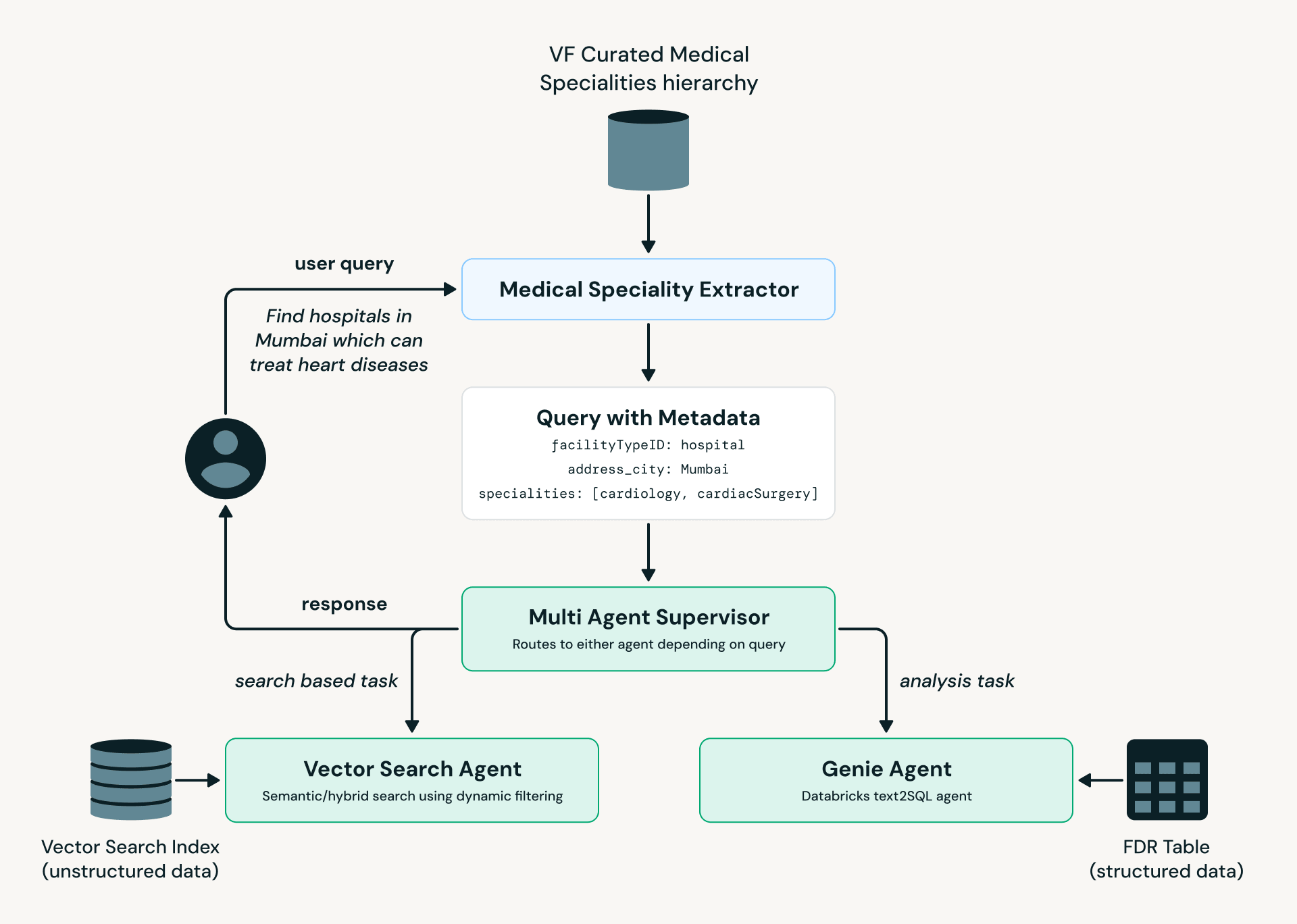 Fig 3: VF Agent: Diagrama de Fluxo de Processo">
Fig 3: VF Agent: Diagrama de Fluxo de Processo">Como ilustrado no diagrama acima, o Medical Specialty Extractor converte a linguagem do usuário em terminologia médica padronizada, que é então passada para o Multi-Agent Supervisor. Com base na intenção e complexidade da consulta, ela é roteada para o AI Search Agent (descoberta e busca de instalações) ou para o Genie Agent (consultas analíticas contra dados estruturados).
Resumo
Profissionais de saúde agora podem descobrir oportunidades atualizadas mais rapidamente, encontrar correspondências para suas especialidades médicas e acessar dados globais sobre milhares de instalações em todo o mundo. A jornada da Virtue Foundation do conceito de prova para a produção demonstra o que é possível quando sistemas avançados de IA são combinados com uma plataforma de dados unificada.
O resultado final é uma visão global da infraestrutura de saúde – mostrando onde os voluntários médicos são mais necessários.
Se você gostaria de saber mais sobre este projeto, por favor, veja:
- Visão Geral do Projeto Databricks x Virtue Foundation - YouTube
- Entrevista UN Bloomberg (YouTube) - por volta de 38:00
- Depoimento em vídeo: Bright Initiative x Virtue Foundation x Databricks
Leia mais sobre outros projetos do Databricks for Good abaixo:
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.