Databricks for Good and Virtue Foundation: Partnering to Connect Medical Volunteers to Critical Health Services in 72 Countries
by Priyanka Mehta and Shaunak Sen
- The Virtue Foundation partnered with Databricks for Good to leverage AI to enhance global healthcare outcomes.
- The outcome has resulted in the Virtue Foundation being able to better match clinician skills to volunteer opportunities in developing countries where those clinician skills are most needed.
- Together, the Databricks and Virtue Foundation teams are providing updated core datasets in a readily accessible and actionable format.
Introduction
Virtue Foundation is a nonprofit focused on global health delivery and creating an efficient marketplace for global philanthropic healthcare. To date, they’ve delivered care to over 50,000 patients with a special focus on Ghana and Mongolia. The backbone of this marketplace is the curation of global healthcare facility data through VF Match, a platform that connects medical professionals to volunteer opportunities in 72 low and low-middle income countries. Databricks for Good has been partnering closely with Virtue Foundation since 2024 to leverage AI to aggregate data across these countries and make it actionable.
An initial proof of concept demonstrated that LLMs could extract structured information from disparate web data sources to create a map of healthcare infrastructure and, most importantly, the gaps in services in under-resourced areas. However, scaling this functionality and moving it into production posed many challenges. Since that first iteration, we’ve built a Databricks-based platform that has transformed the POC into a production-grade system aggregating data from thousands of healthcare facilities and non-profits across the globe.
In this article, we walk through how we improved on our earlier work to further enable Virtue Foundation to match their community of medical volunteers with critical needs in these countries.
Building the Foundation: 72 Countries of Healthcare Data
The core of VF Match is the Foundational Data Refresh (FDR): a comprehensive healthcare facility and nonprofit dataset built from the ground up from various web-based sources. We systematically ingest and refresh data from 72 low and low-middle income countries across the globe.
Two complementary data sources power this refresh:
- Overture Maps: An open-source geospatial dataset by Meta and Microsoft, providing authoritative locations for healthcare facilities.
- Bright Data: Industrial web-scraping infrastructure that captures real-time information from across the internet.
The heart of FDR is an information extraction pipeline powered by OpenAI’s GPT models. Processing more than 25 million web pages through LLMs with production guarantees required rethinking traditional LLM inference pipelines. Rather than attempting one-shot extraction, our pipeline breaks the task into targeted steps: classifying medical relevance, identifying organization type (either a medical facility or NGO), and extracting specialties, equipment, and procedures.
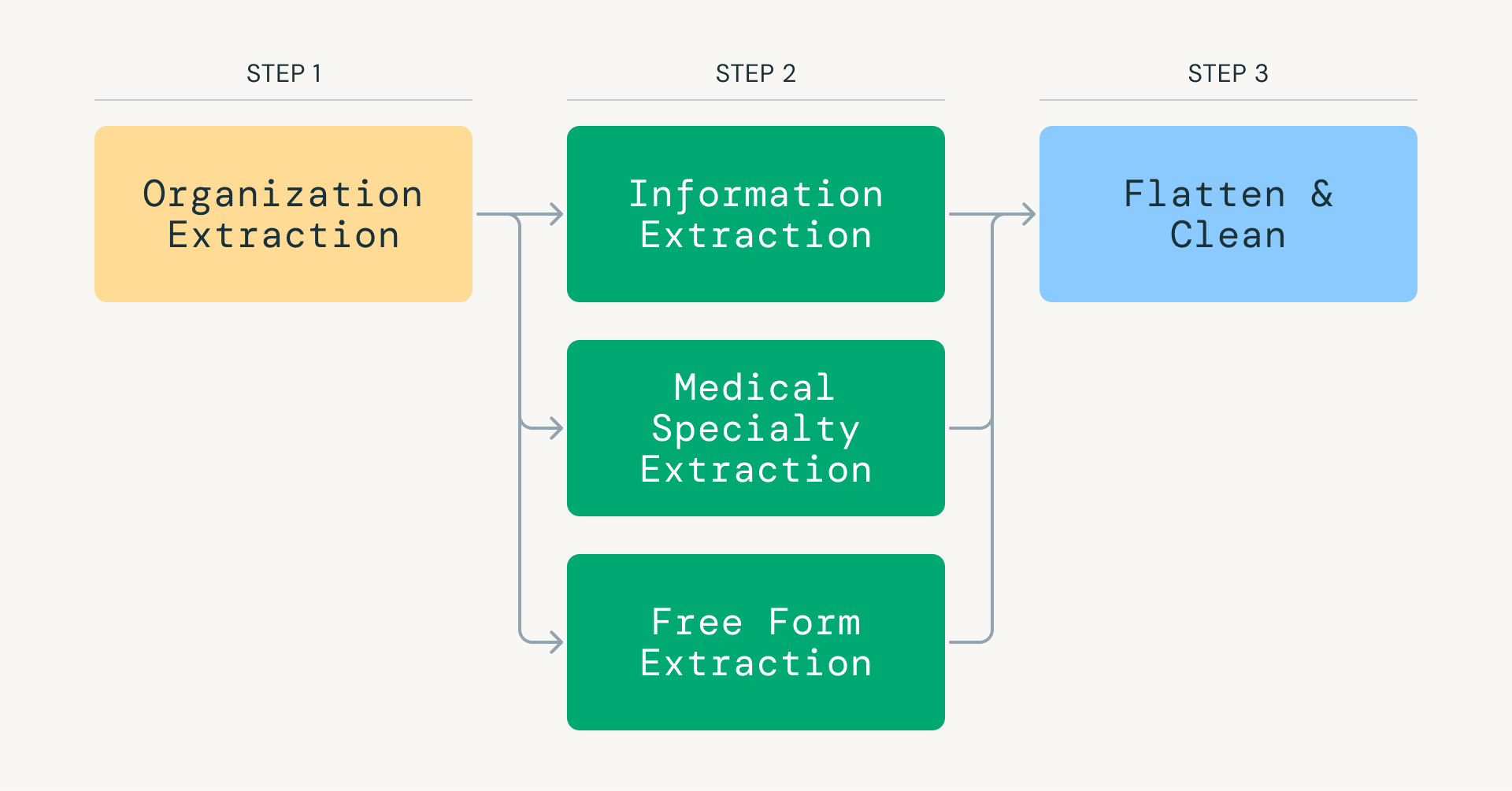
This approach dramatically reduces token consumption while focusing each model invocation on a narrow, high-precision task. Databricks and Apache Spark are used to efficiently orchestrate and parallelize the scraped data, distributing workloads across thousands of executors and enabling high-throughput LLM inference.
A number of critical features make this pipeline scalable and ready for production:
- Extensible data modeling: Data at each step is stored in a star schema, simplifying downstream analytics and improving query performance.
- Status-based checkpointing: Every record tracks its processing state, enabling pipelines to resume from any point without reprocessing rows with expensive LLM calls.
- Configurable extraction registry: Each extraction method is controlled by a structured object specifying the system prompt, making extraction logic modular, reproducible, and extensible.
- Scalable distributed processing: The system processes skewed, multi-terabyte workloads using Spark for parallelism, Photon for performance at scale, and production-grade orchestration.
These guarantees are enforced through Lakeflow Jobs, which orchestrate more than 15 interdependent tasks with conditional branching, parallel execution, and intelligent retry policies. The result is a system that processes healthcare facility data at scale with the precision of medical experts.
Entity Resolution at Scale
Once the facility and nonprofit data is scraped and extracted using an LLM, a classic challenge emerges: entity resolution. The same facility may appear across multiple data sources with name variations, inconsistent addresses, or missing contact details. Traditional deduplication breaks down in these scenarios due to messy data, so we use Splink, an open source probabilistic record linkage framework. Using the information sourced in our IE step, Splink evaluates match pairs via weighted comparisons across fields like phone number, street address, and more. The result is a unified key per facility, ensuring that end users see one authoritative record for each medical facility and NGO.
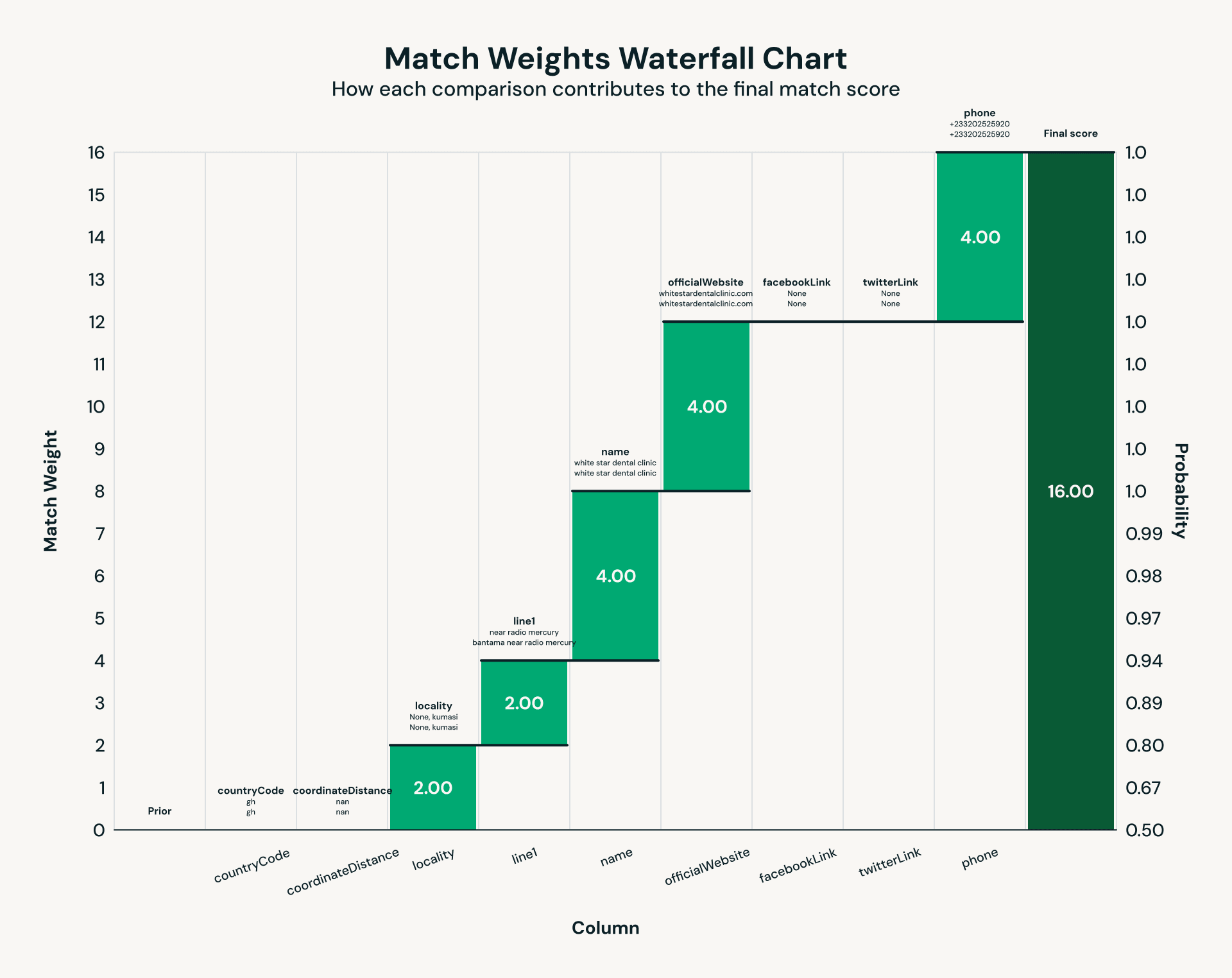
Running probabilistic matching across thousands of healthcare facilities and non-profits revealed classic performance bottlenecks that emerge at terabyte scale. The core of record linkage is pairwise comparison, which creates inherently skewed workloads: common comparisons produce massive partitions while most others remain much smaller. Early runs made this painfully clear, with one Spark partition running for 30 minutes while the median completed in 52 seconds – a textbook case of stragglers (the “curse of the last reducer”) degrading job performance. Enabling Photon, Databricks’ vectorized query engine, reduced worst-case data partitions from 30 minutes to approximately 2 minutes: a 15x improvement.
VF Agent: Natural Language Meets Healthcare Data
Looking to the future, we have developed a prototype of an agent that enables experts to analyze data using natural language. We use a multi-agent architecture built in LangGraph and leverage Databricks Model Serving, AI Search, and Genie.
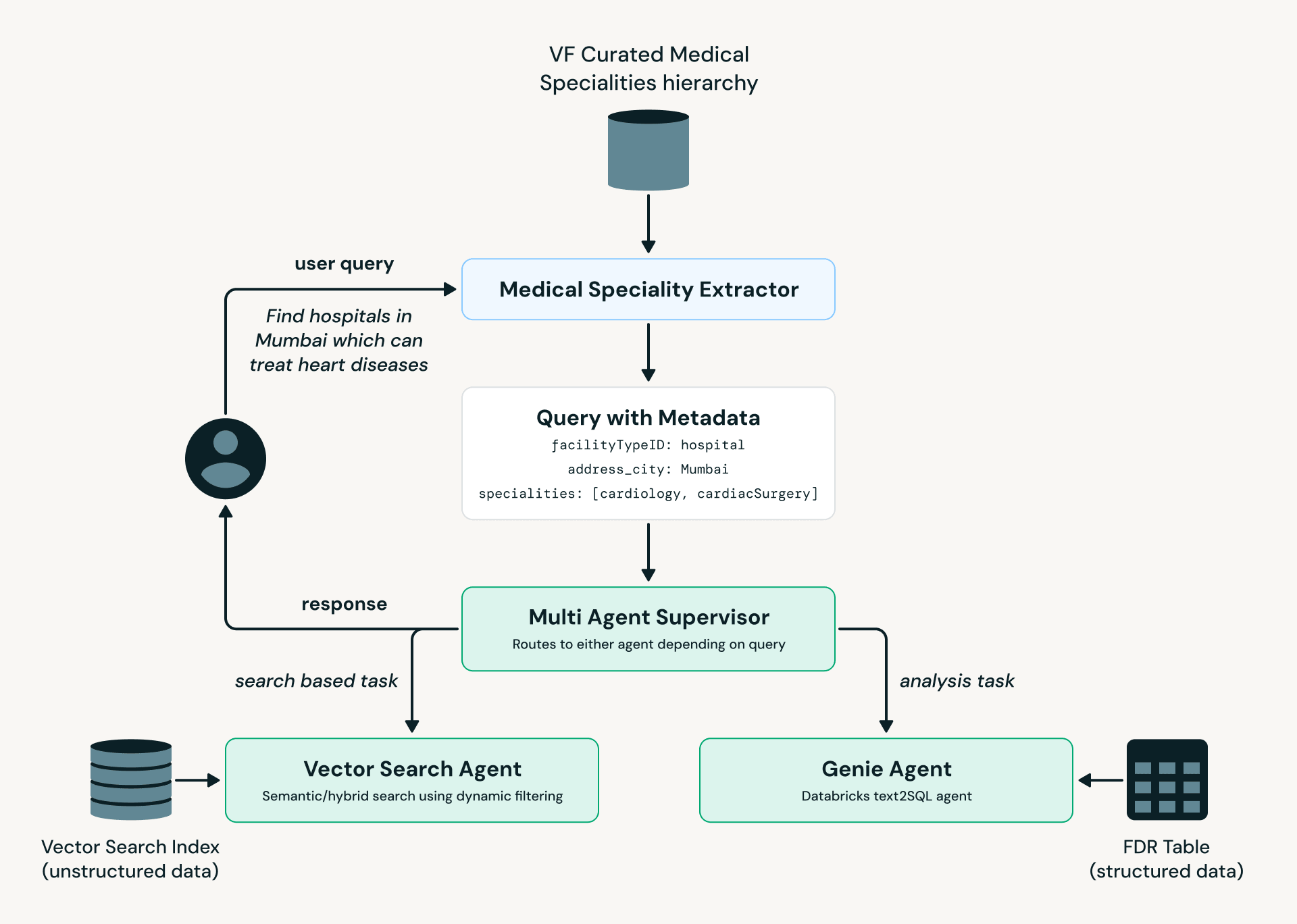
As illustrated in the diagram above, the Medical Specialty Extractor converts user language into standardized medical terminology, which is then passed to the Multi-Agent Supervisor. Based on the query's intent and complexity, it is routed to either the AI Search Agent (facility discovery and search) or the Genie Agent (analytical queries against structured data).
Summary
Healthcare professionals can now discover up-to-date opportunities faster, find matches to their medical specialties, and access global data on thousands of facilities worldwide. The Virtue Foundation’s journey from proof of concept to production demonstrates what’s possible when advanced AI systems are paired with a unified data platform.
The final result is a global view of healthcare infrastructure – surfacing where medical volunteers are needed most.
If you would like to learn more about this project please see:
- Databricks x Virtue Foundation Project Overview - YouTube
- UN Bloomberg Interview (YouTube) - around minute 38:00
- Video testimonial: Bright Initiative x Virtue Foundation x Databricks
Please read more about some of our other Databricks for Good projects below:
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.