Desenvolver e implantar JARs Serverless
por Achille Negrier, Edward Feng, Giorgi Kikolashvili e Shiyu Wang
- Execute JARs Serverless escritos em Scala ou Java, com tempos de inicialização instantâneos e zero gerenciamento de cluster.
- Desenvolva em seu IDE favorito usando Databricks Connect, testando com dados reais e ambientes semelhantes à produção.
- Pague apenas pelo trabalho realizado com faturamento elástico baseado no uso, não por tempo ocioso ou aquisição de instância.
JARs Serverless e Databricks Connect para Scala
JARs Serverless permitem que equipes criem e executem Jobs Scala e Java no Spark em computação Serverless totalmente gerenciada. As equipes podem continuar construindo pipelines Spark de nível de produção nas linguagens em que já confiam, com atualizações automatizadas e sem a sobrecarga operacional de gerenciar clusters:
- Inicialização rápida: Com o Serverless, jobs Scala e Java iniciam em segundos em vez de minutos. Os engenheiros podem executar e iterar no código imediatamente, sem esperar que os clusters sejam iniciados.
- Atualizações sem versão: O Serverless é executado continuamente no runtime Spark mais recente suportado, para que você nunca precise planejar ou gerenciar atualizações do Databricks Runtime.
- Nenhuma infraestrutura para gerenciar: Não há provisionamento de cluster, nem planejamento de capacidade, nem gerenciamento de runtime. O Databricks gerencia automaticamente a infraestrutura, o dimensionamento e a otimização de desempenho, para que os desenvolvedores possam se concentrar em escrever código.
- Pague apenas pelo que você usa: Em vez de pagar por clusters sempre ativos ou capacidade ociosa, as equipes são cobradas apenas pela computação que realmente usam.
Como funcionam os JARs Serverless?
Você pode executar JARs com Lakeflow Jobs em computação Serverless. JARs Serverless são construídos sobre Spark 4 (Scala 2.13) e Spark Connect, usando a mesma arquitetura do Python. O desacoplamento do código do usuário do engine permite atualizações sem versão, remove conflitos de dependência e habilita controles de acesso nativos e granulares com Lakeguard.
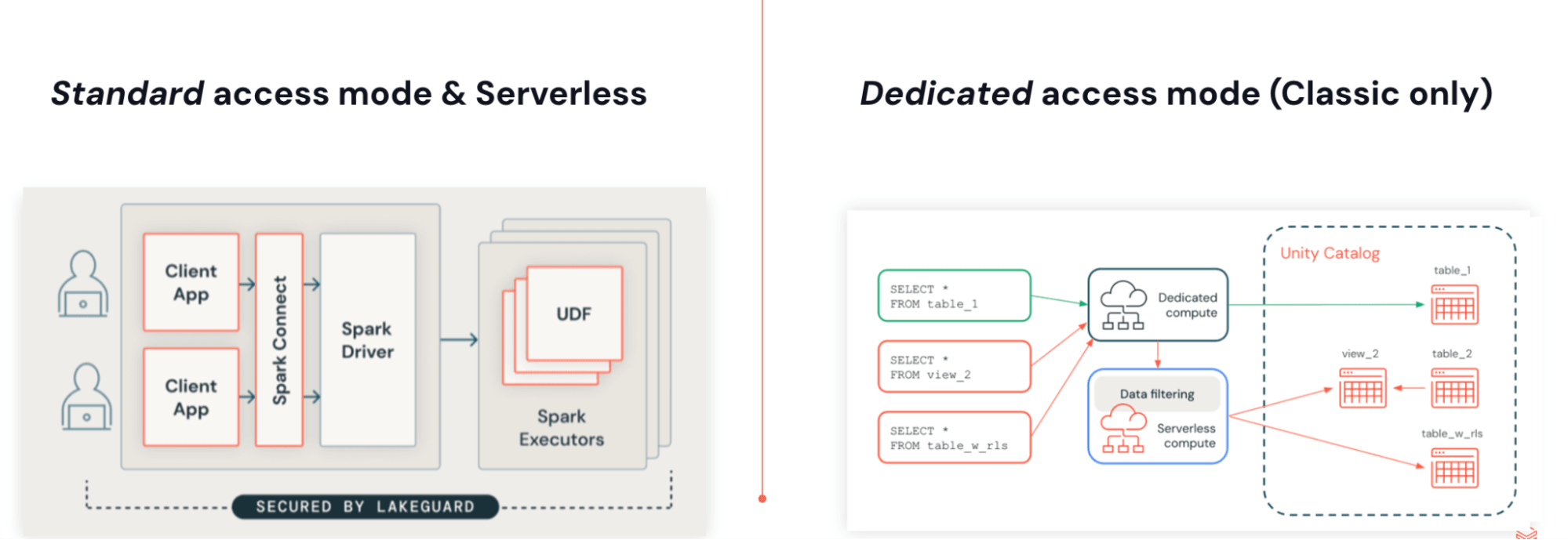
Esta arquitetura tem alguns benefícios chave:
- Execução sem versão: Aplicações não estão mais vinculadas a uma versão específica do Databricks Runtime. O Serverless sempre é executado no runtime mais recente suportado, eliminando a necessidade de planejar, agendar ou gerenciar atualizações do Databricks Runtime.
- Controles de acesso nativos e granulares com Lakeguard: Como toda a execução acontece no servidor, o Databricks pode impor filtros em nível de linha e controles de acesso baseados em atributos (ABAC) a um baixo custo.
- Conjunto de dependências enxuto e independente: O ambiente Serverless é executado isolado do Spark, para que possa fornecer um conjunto independente e reduzido de dependências, o que também elimina conflitos de dependência.
Desenvolver usando Databricks Connect e Databricks Asset Bundles
Com o Databricks Connect, você pode escrever e depurar código interativamente em seu IDE preferido, como IntelliJ ou Cursor, usando computação Serverless com tempos de inicialização quase instantâneos.
Isso torna os ciclos de desenvolvimento mais rápidos e confiáveis, pois você pode testar com dados reais e ambientes sem sair do seu IDE. Assim que terminar o desenvolvimento, você pode colocar seu job em produção usando Databricks Asset Bundles.
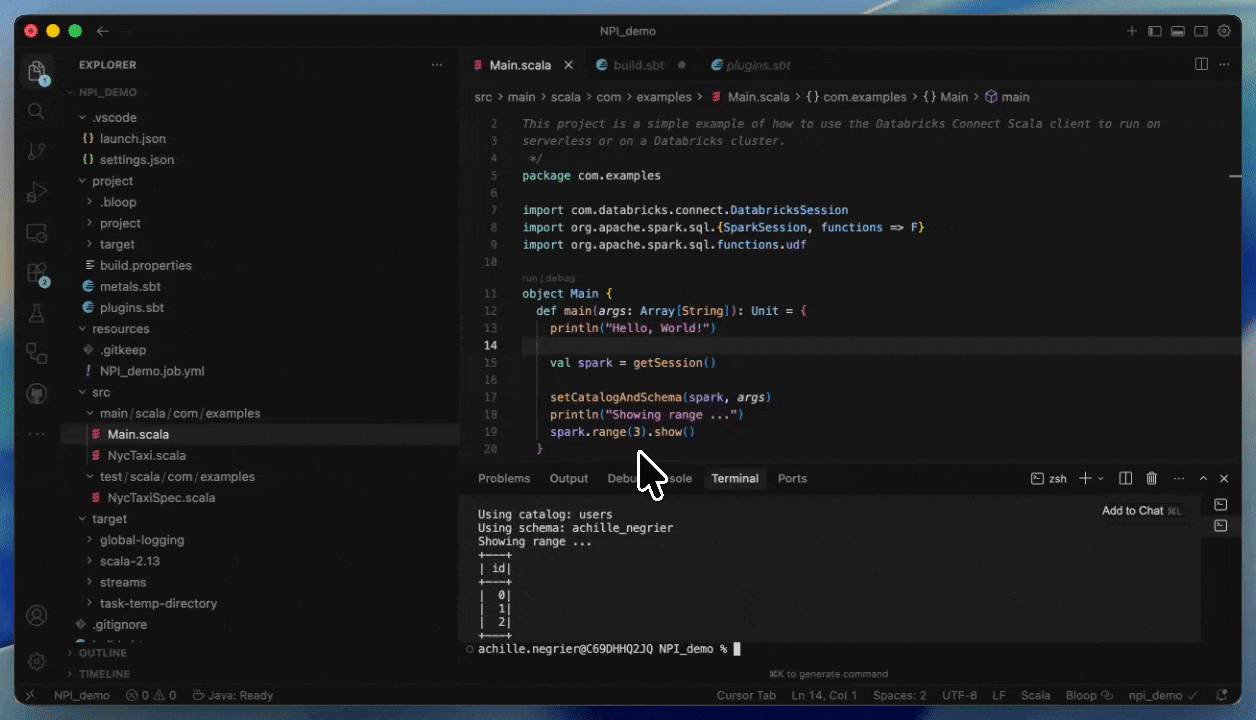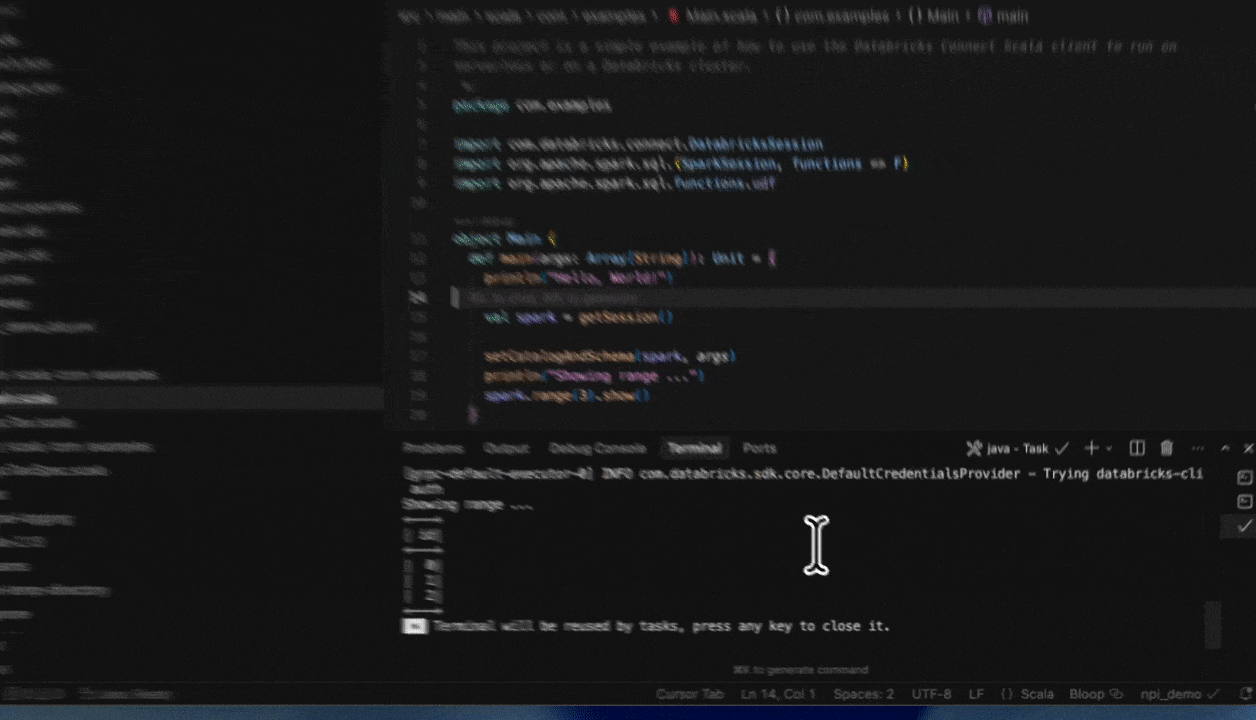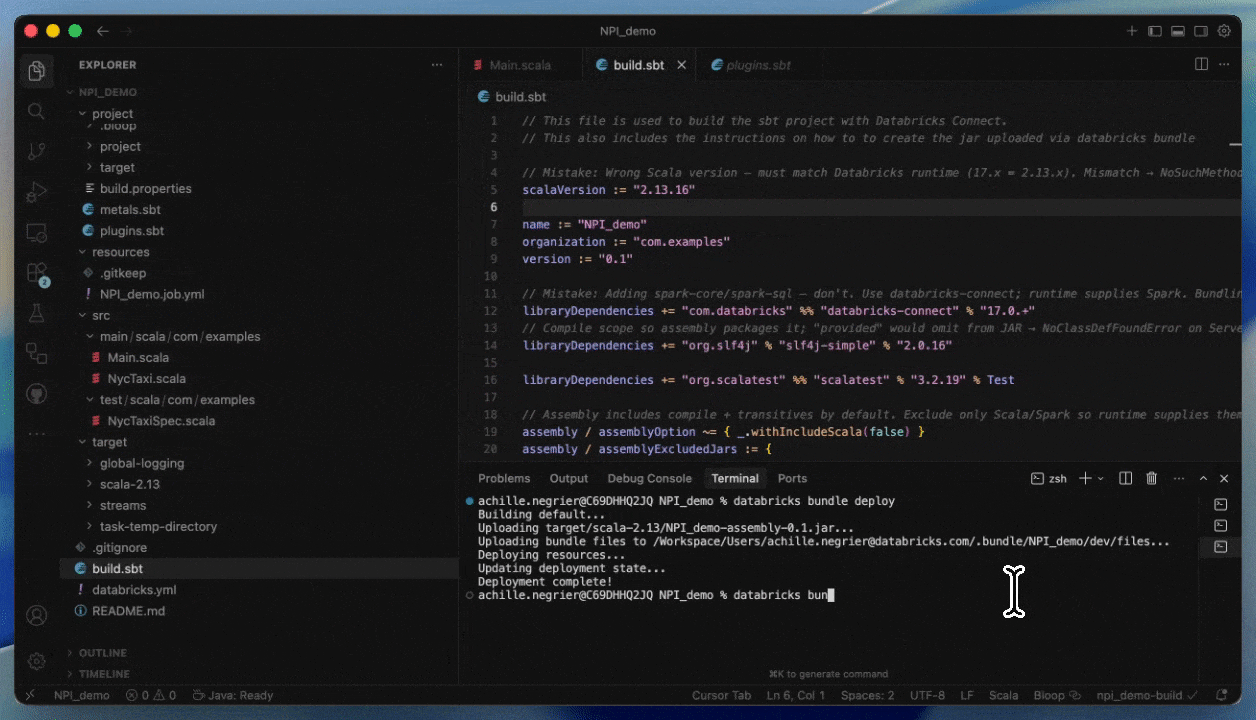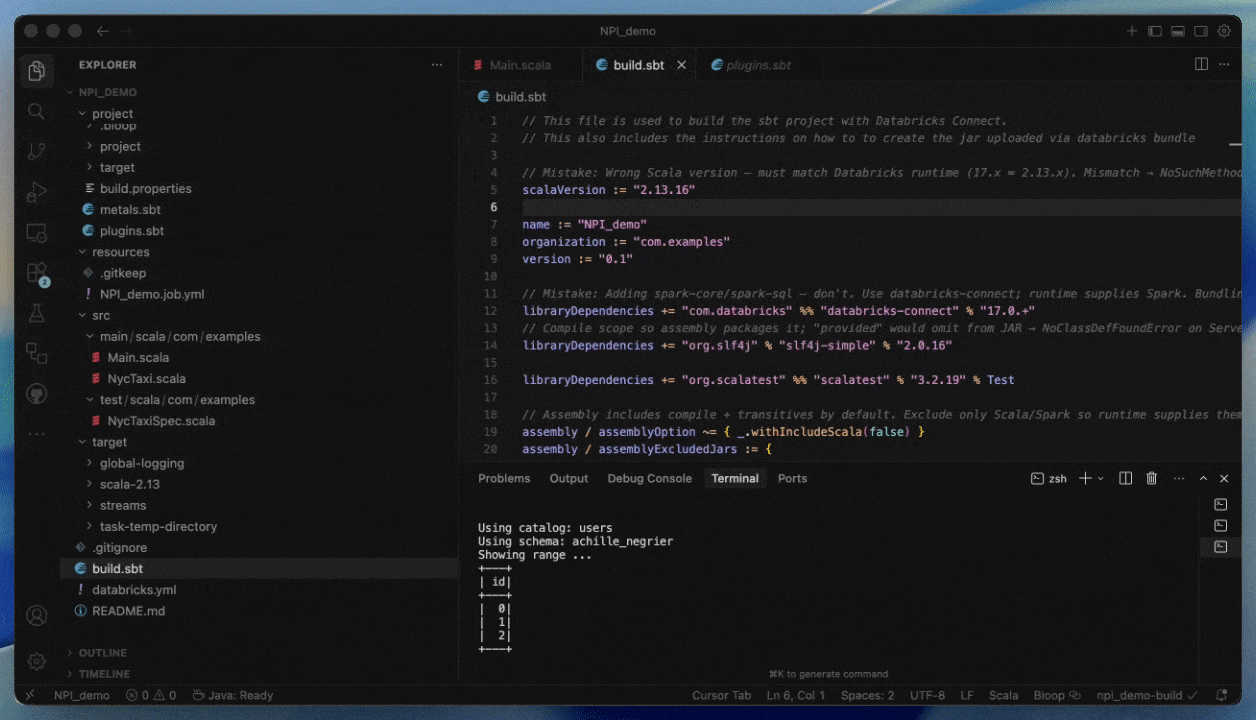
Como implantar no Serverless fornecendo um JAR
Etapa 1: Compilar seu JAR para Serverless
- Compile com Spark 4 (Scala 2.13) e Spark Connect
- Empacote todas as dependências não-Spark explicitamente ou forneça-as como JARs adicionais
Etapa 2: Criar um job Serverless
- Faça upload do seu JAR para um volume do Unity Catalog ou para uma pasta de workspace do UC.
- Crie um novo job usando uma tarefa JAR e selecione Serverless como a computação.
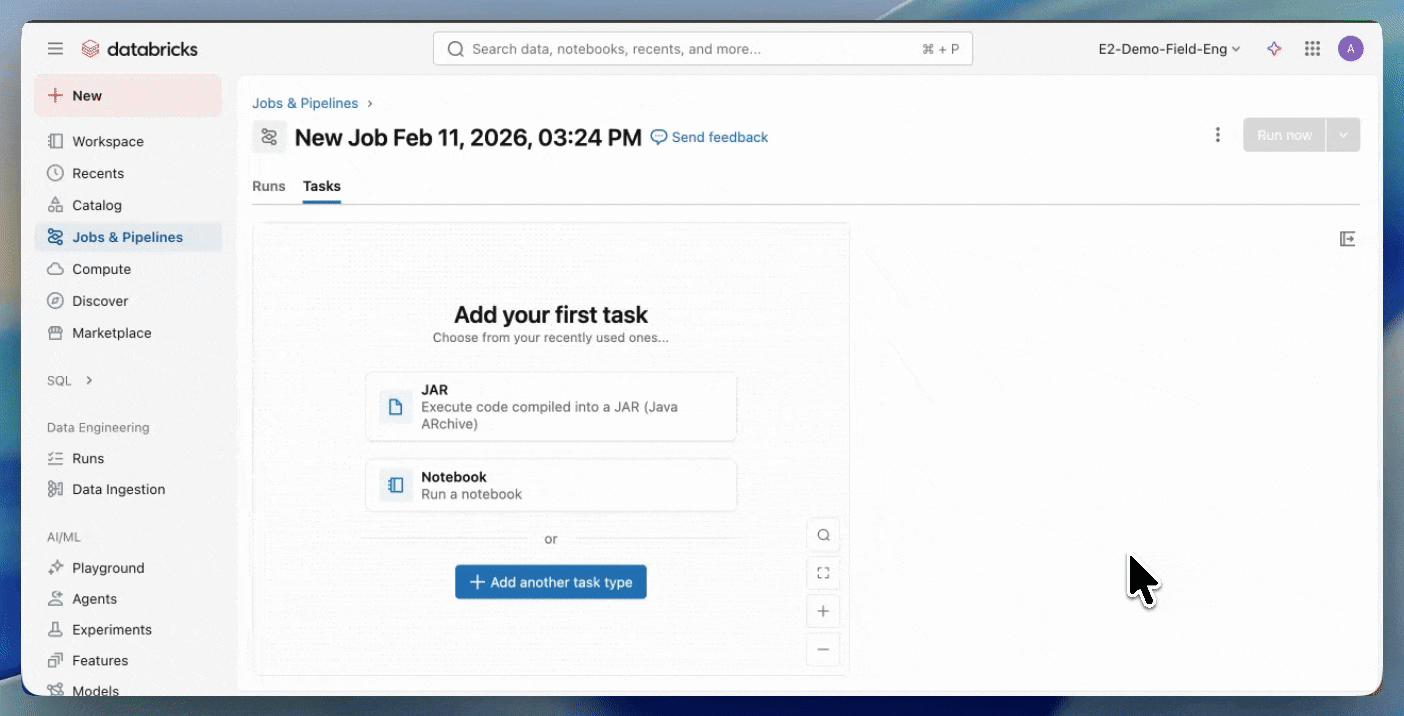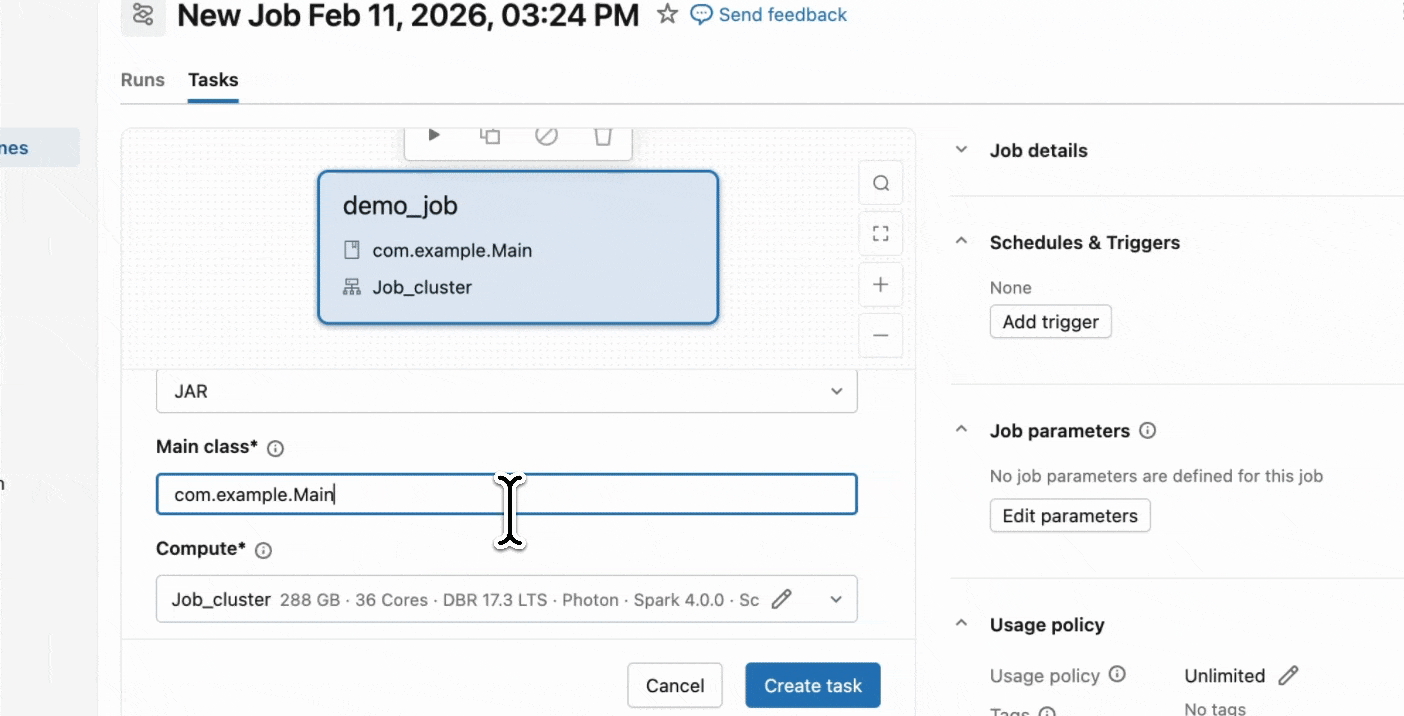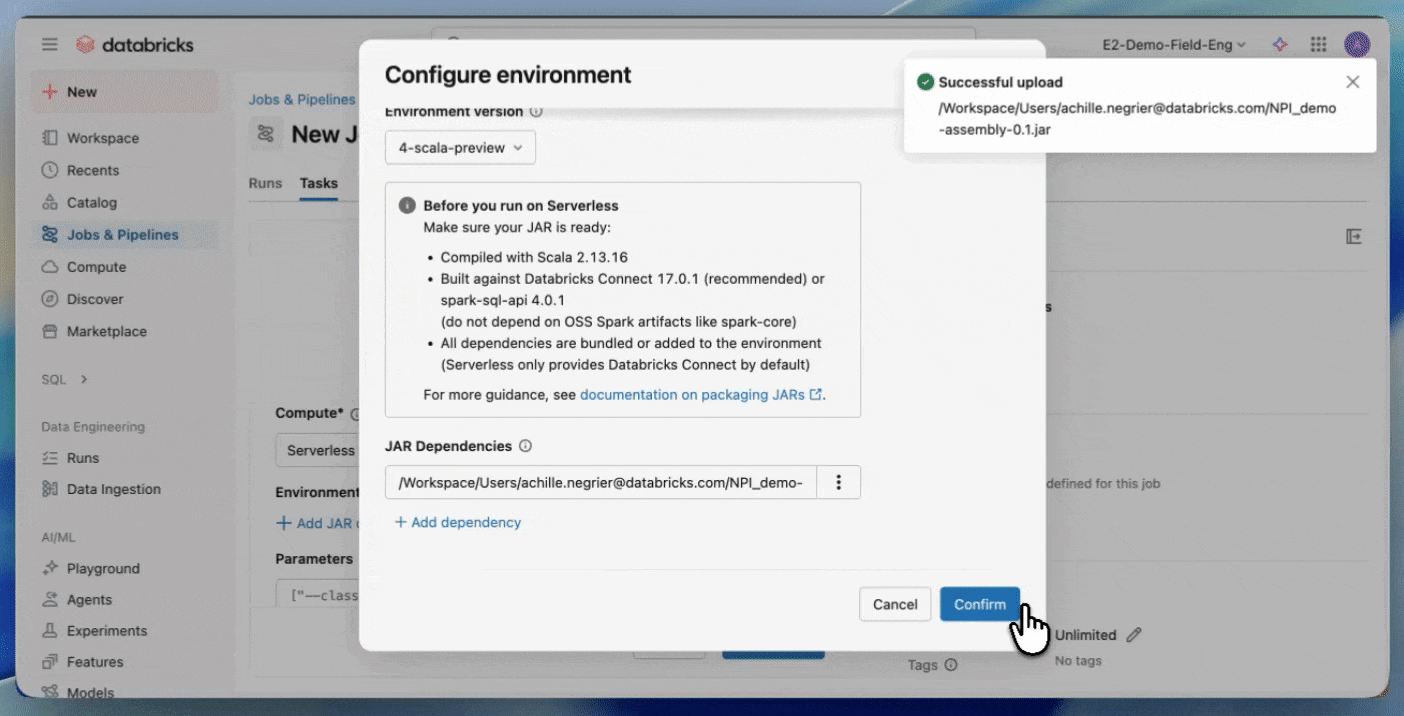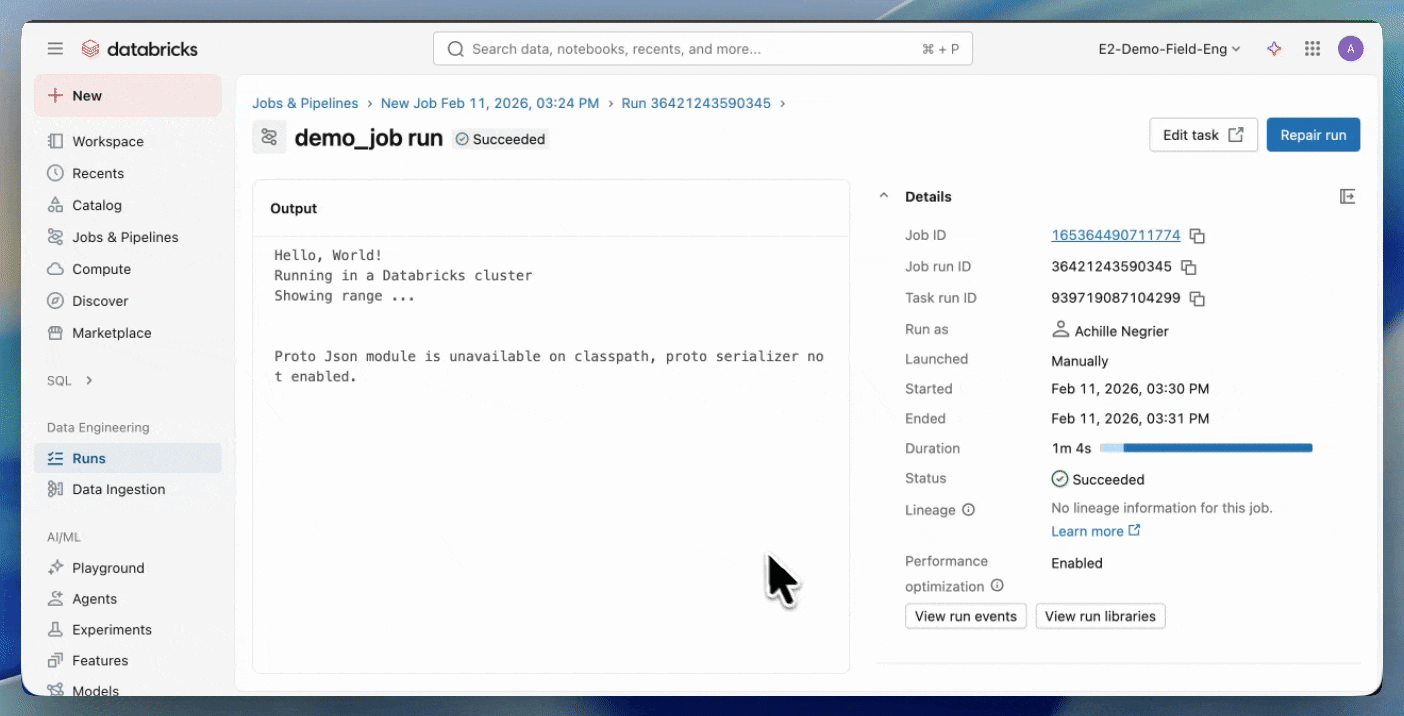
Comece a usar JARs Serverless.
Para começar rapidamente, siga o tutorial sobre como desenvolver e implantar Jobs Scala usando o template Databricks Asset Bundle. Para um tutorial sobre como compilar um JAR manualmente, veja Executar código Scala em computação Serverless.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.