Develop and deploy Serverless JARs
by Achille Negrier, Edward Feng, Giorgi Kikolashvili and Shiyu Wang
- Run Serverless JARs written in Scala or Java, with instant startup times and zero cluster management.
- Develop in your favorite IDE using Databricks Connect, testing against real data and production-like environments.
- Pay only for work done with elastic, usage-based billing, not for idle time or instance acquisition.
Serverless JARs and Databricks Connect for Scala
Serverless JARs enable teams to build and run Scala and Java Spark Jobs on fully managed Serverless compute. Teams can continue building production-grade Spark pipelines in the languages they already trust, with automated upgrades and without the operational overhead of managing clusters:
- Fast startup: With Serverless, Scala and Java jobs start in seconds instead of minutes. Engineers can run and iterate on code immediately, without waiting for clusters to spin up.
- Versionless upgrades: Serverless continuously runs on the latest supported Spark runtime, so you never have to plan or manage Databricks Runtime upgrades.
- No infrastructure to manage: There’s no cluster provisioning, no capacity planning, and no runtime management. Databricks automatically handles infrastructure, scaling, and performance optimization, so developers can focus on writing code.
- Pay only for what you use: Instead of paying for always-on clusters or idle capacity, teams are billed only for the compute they actually use.
How do Serverless JARs work?
You can run JARs with Lakeflow Jobs on Serverless compute. Serverless JARs are built on Spark 4 (Scala 2.13) and Spark Connect, using the same architecture as Python. The decoupling of user code from the engine enables versionless upgrades, removes dependency conflicts, and enables native fine-grained access controls with Lakeguard.
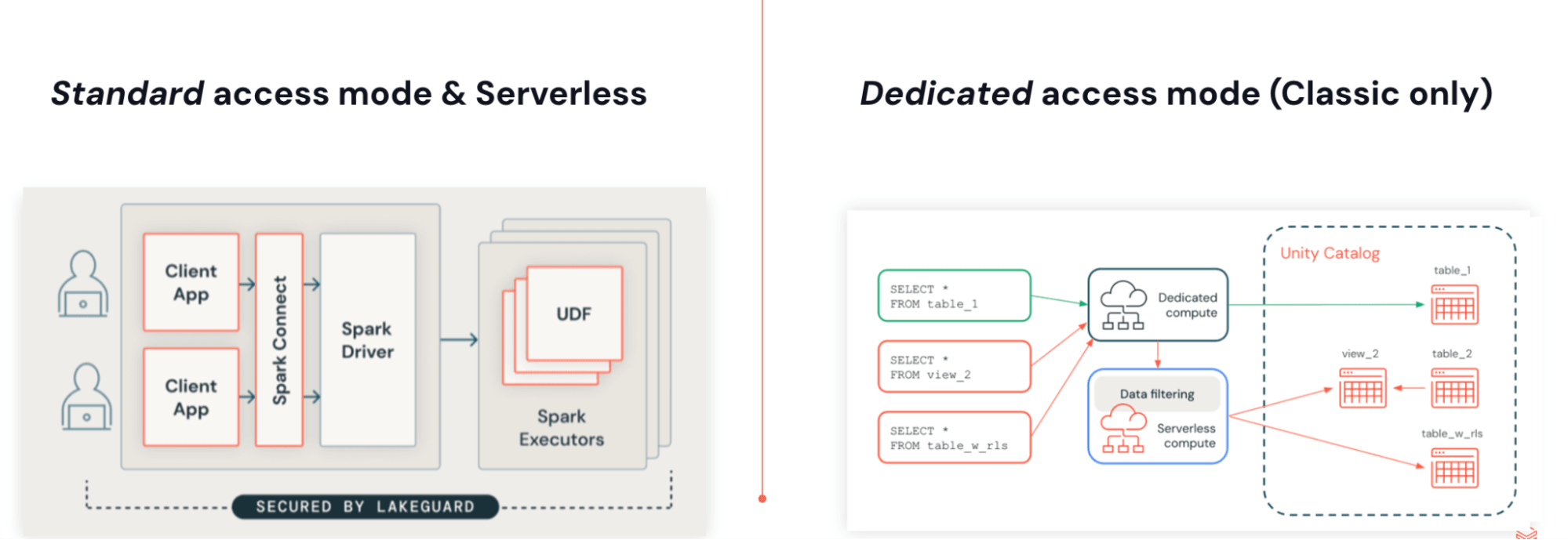
This architecture has a few key benefits:
- Versionless execution: Applications are no longer tied to specific Databricks Runtime Version. Serverless always runs on the latest supported runtime, eliminating the need to plan, schedule, or manage Databricks Runtime upgrades.
- Native fine-grained access controls with Lakeguard: Because all execution happens on the server, Databricks can enforce row-level filters and attribute-based access controls (ABAC) at a low cost.
- Slim and independent set of dependencies: The Serverless environment runs isolated from Spark, so it can provide an independent and reduced set of dependencies which also eliminates dependency conflicts.
Develop using Databricks Connect and Databricks Asset Bundles
With Databricks Connect, you can write and debug code interactively in your IDE of choice, such as IntelliJ or Cursor, using Serverless compute with near-instant startup times.
This makes development cycles faster and more reliable, as you can test against real data and environments without leaving your IDEs. Once you have finished developing, you can productionise your job using Databricks Asset Bundles.
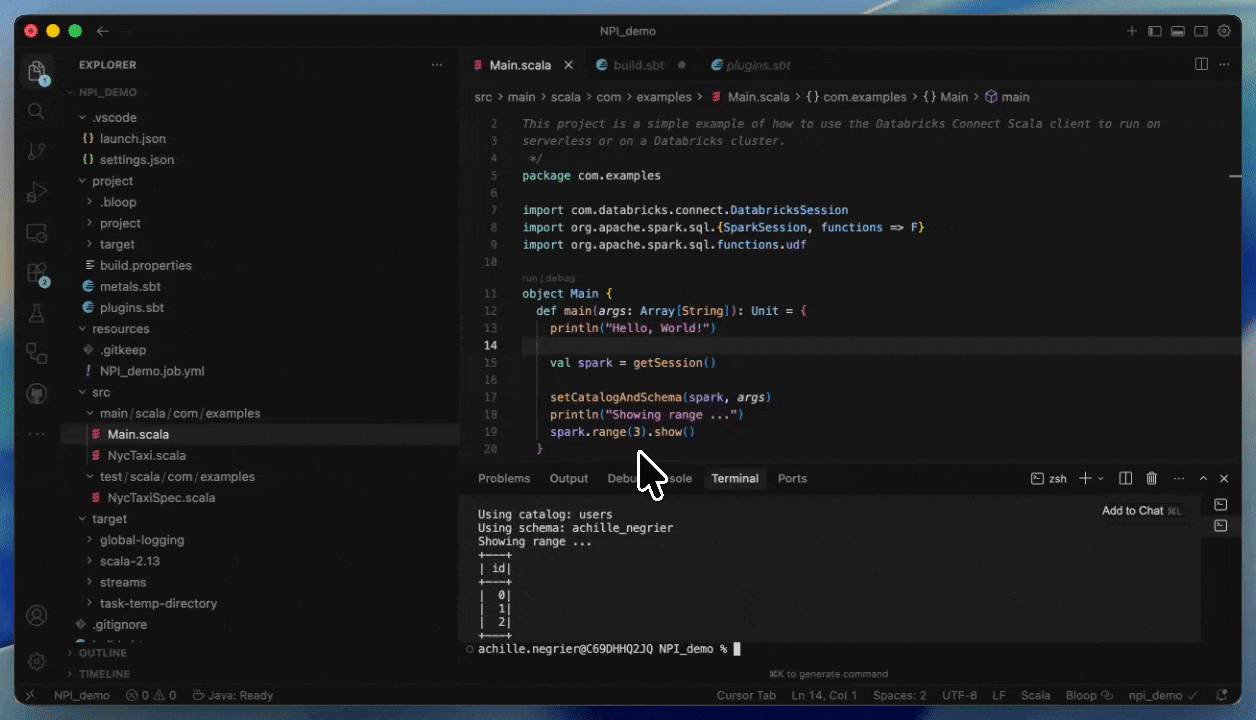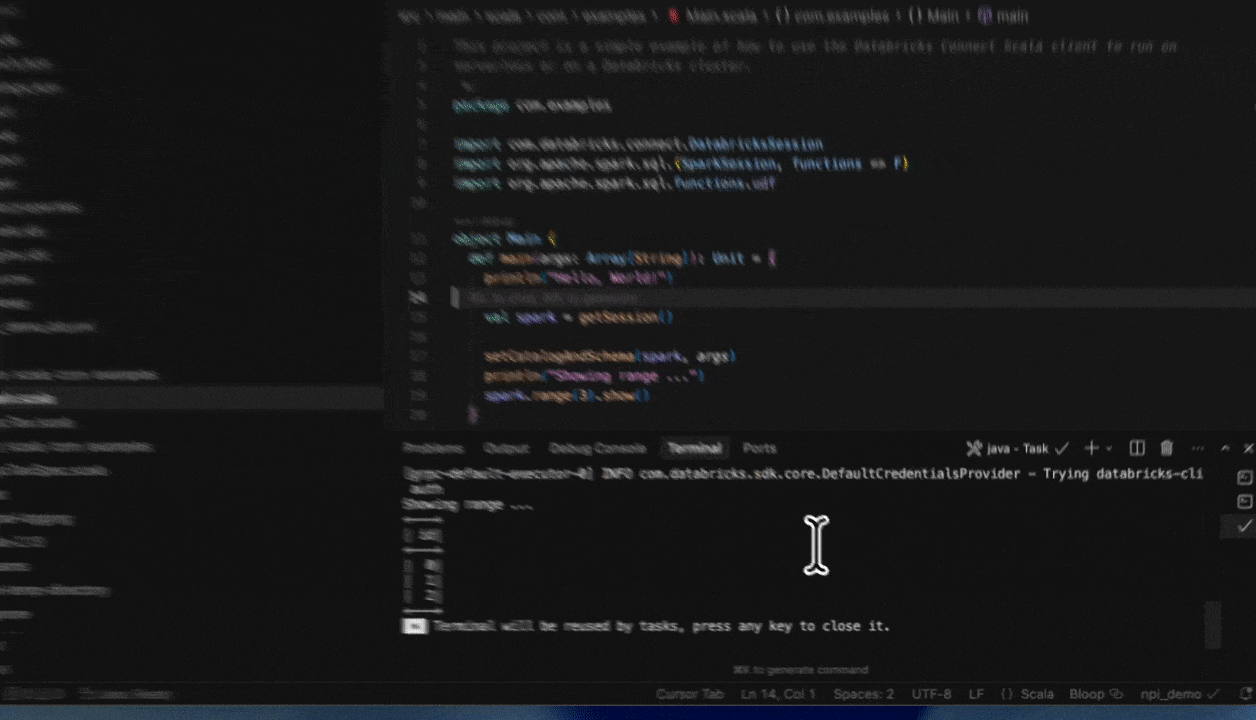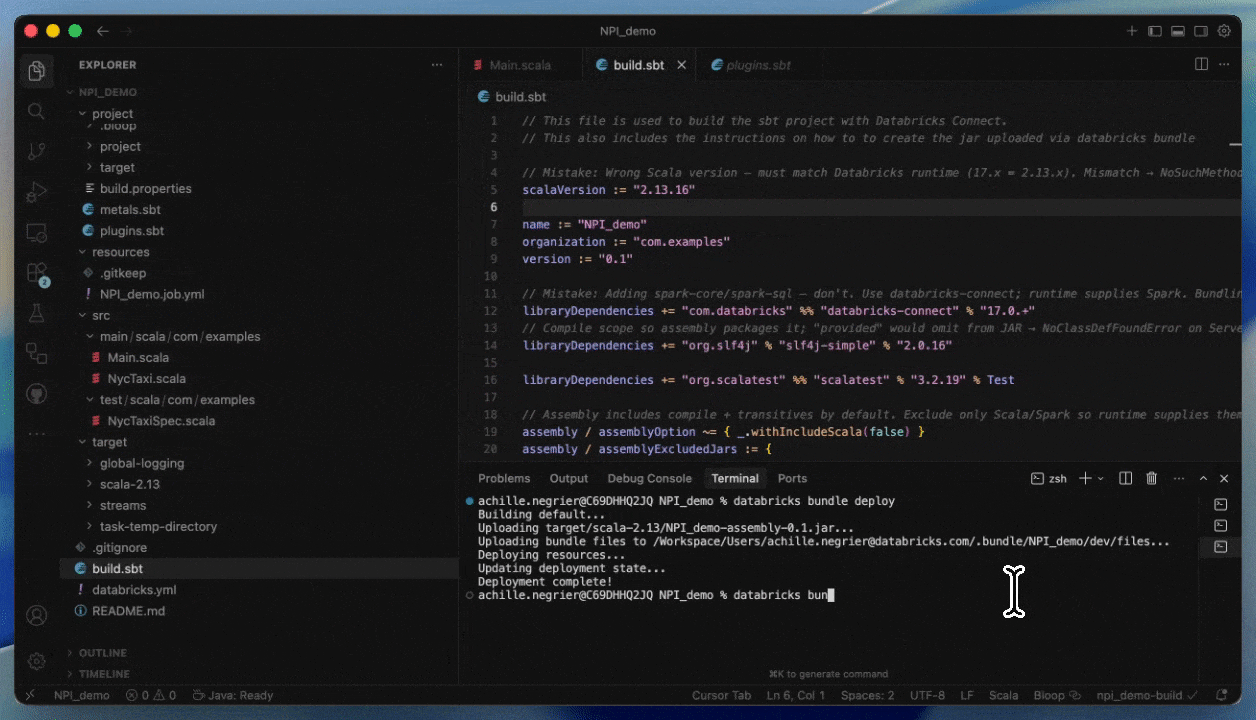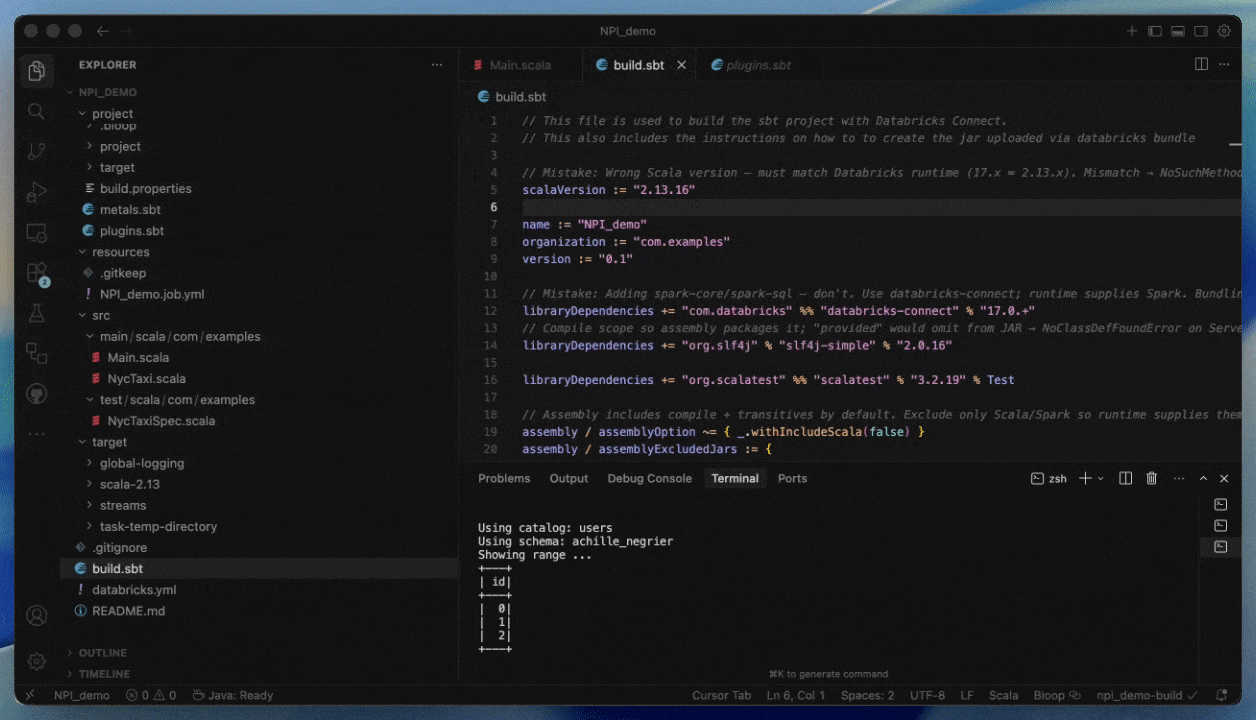
How to deploy on Serverless by providing a JAR
Step 1: Compile your JAR for Serverless
- Compile with Spark 4 (Scala 2.13) and Spark Connect
- Bundle all non-Spark dependencies explicitly or provide them as additional JARs
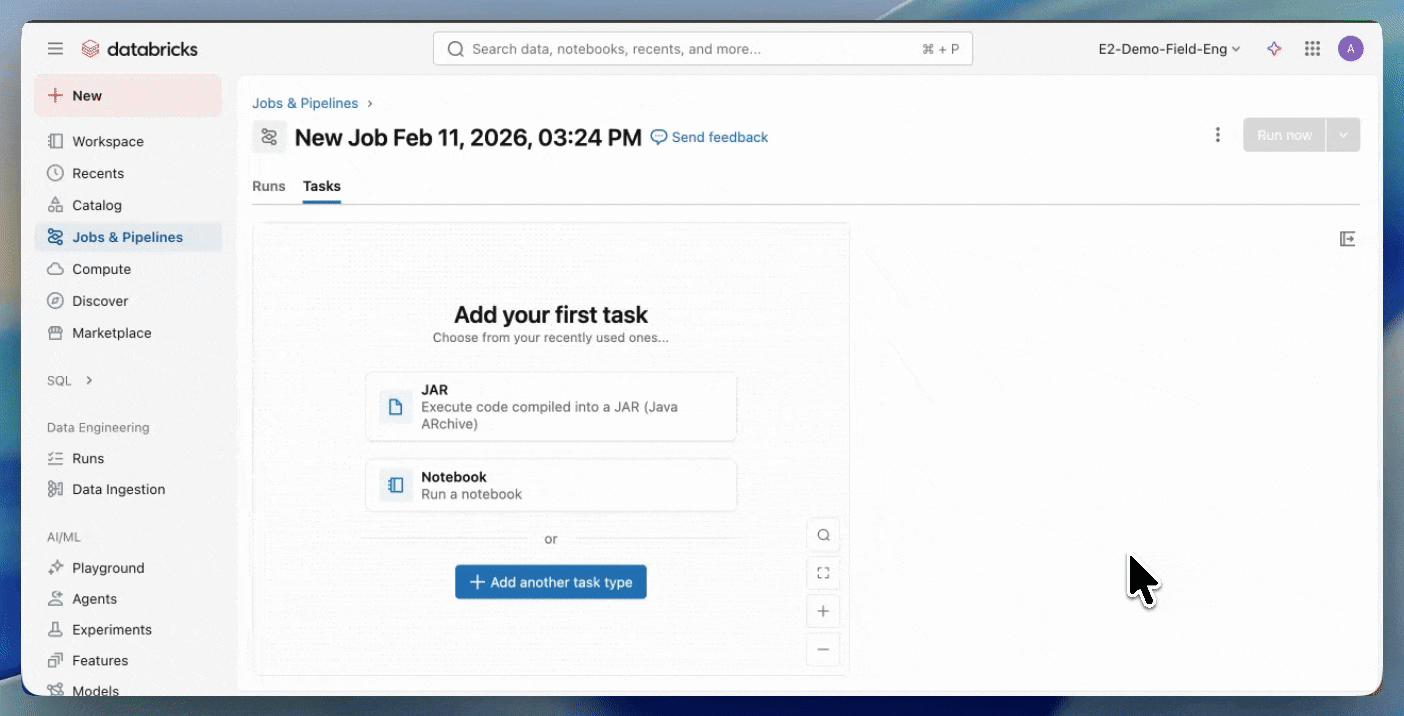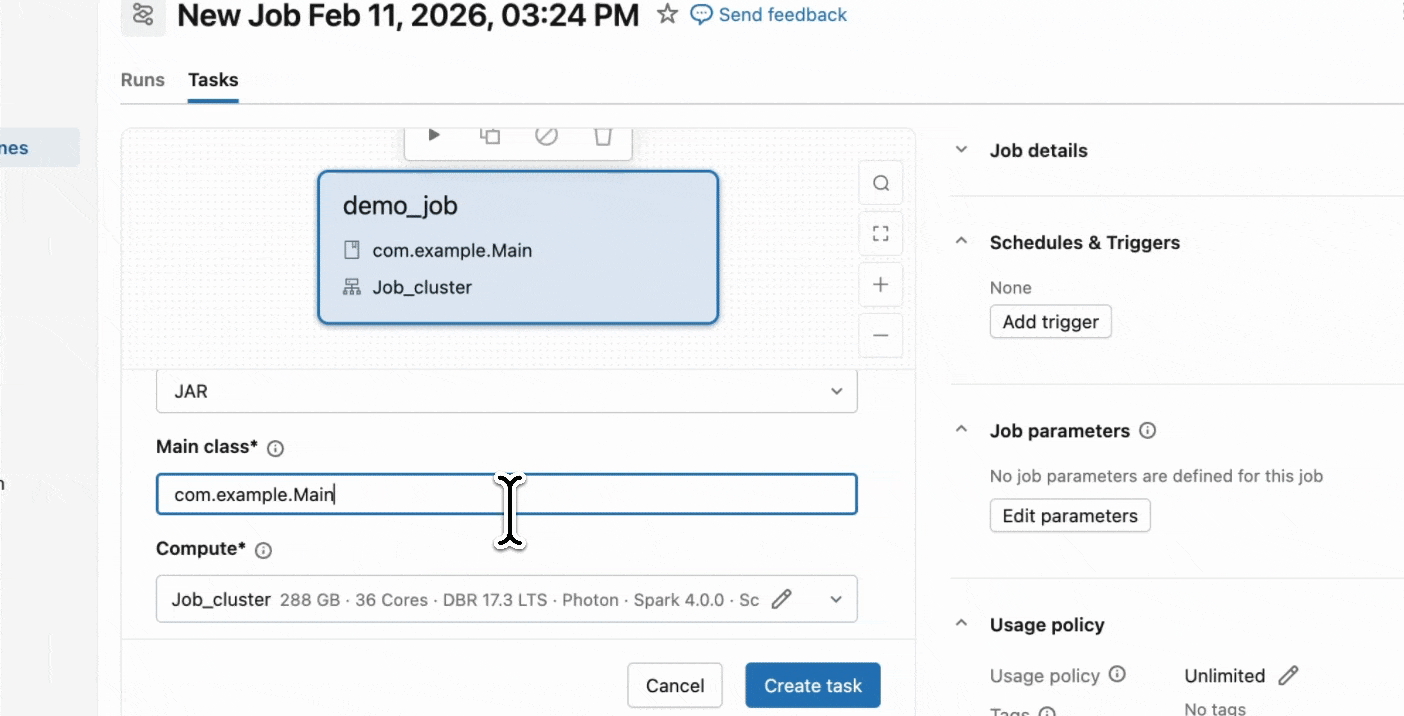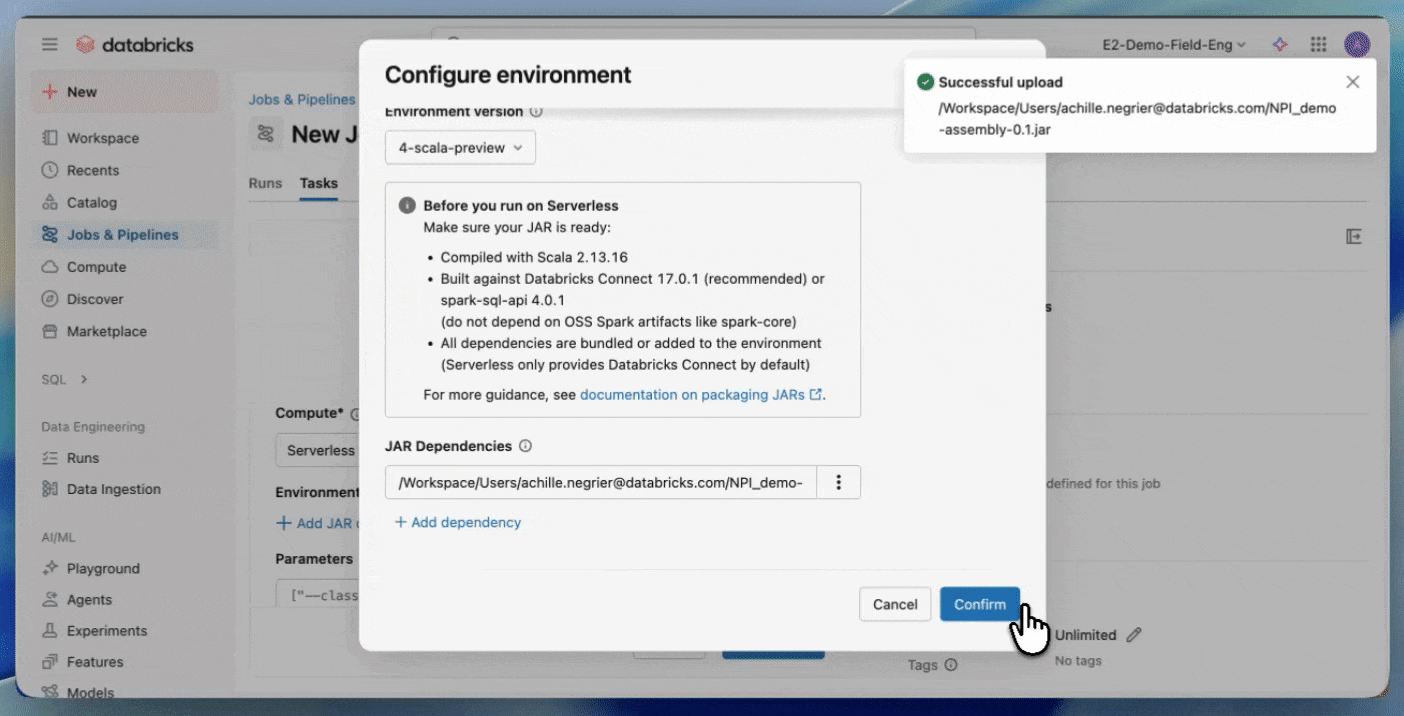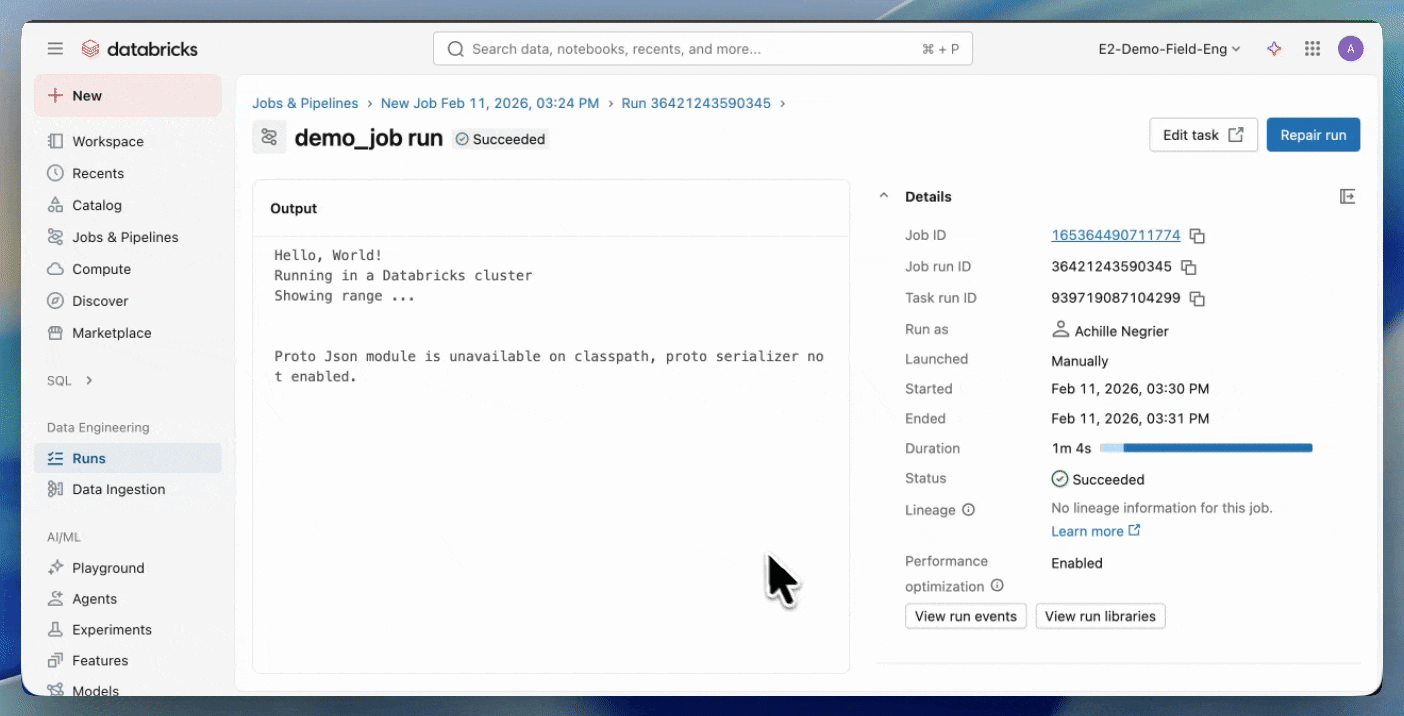
Step 2: Create a Serverless job
- Upload your JAR to a Unity Catalog volume or to a UC workspace folder.
- Create a new job using a JAR task and select Serverless as the compute.
Get started with Serverless JARs.
To get started quickly, follow the tutorial on developing and deploying Scala Jobs using the Databricks Asset Bundle template. For a tutorial on manually compiling a JAR, see Run Scala code on Serverless compute.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.