Erros caros de armazenamento do S3 no Delta Lake (e como corrigi-los)
Otimize buckets do Cloud Storage para tabelas do Delta Lake: corrija erros, reduza custos e aumente o desempenho.
por Zach King
- Políticas de ciclo de vida e versionamento de objetos
- Classes de armazenamento
- Implantação de bucket de práticas recomendadas
1. Introdução: A Base
O armazenamento de objetos na nuvem, como o S3, é a base de qualquer Lakehouse. Você é o proprietário dos dados armazenados em sua Lakehouse, não os sistemas que os utilizam. À medida que o volume de dados aumenta, seja devido a pipelines de ETL ou a mais usuários consultando tabelas, os custos de armazenamento em cloud também aumentam.
Na prática, identificamos erros comuns na forma como esses buckets de armazenamento são configurados, o que resulta em custos desnecessários para as tabelas do Delta Lake. Se não forem controlados, esses hábitos podem levar ao desperdício de armazenamento e ao aumento dos custos de rede.
Neste blog, discutiremos os erros mais comuns e ofereceremos os passos táticos para detectá-los e corrigi-los. Usaremos um equilíbrio de ferramentas e estratégias que aproveitam tanto a Databricks Data Intelligence Platform quanto os serviços da AWS.
2. key considerações de arquitetura
Há três aspectos do cloud para tabelas Delta que consideraremos neste blog ao otimizar os custos:
- Controle de versão de objeto vs. tabela - como o S3 vs. Delta Lake controla seus dados.
- Classes de armazenamento (quente/fria/congelada/de arquivamento): armazenamento mais barato para acesso infrequente e de longo prazo.
- Transferência de dados - o custo de leitura e gravação de dados com o S3.
Versionamento de objeto vs. de tabela
Recursos nativo cloud por si só para o versionamento de objetos não funcionam de forma intuitiva para tabelas do Delta Lake. Na verdade, isso basicamente contradiz o Delta Lake, já que os dois competem para resolver o mesmo problema – a retenção de dados – de maneiras diferentes.
Para entender isso, vamos analisar como as tabelas Delta lidam com o versionamento e depois comparar com o versionamento de objetos nativo do S3.
Como as tabelas Delta lidam com o versionamento
As tabelas do Delta Lake gravam cada transação como um arquivo de manifesto (em formato JSON ou Parquet) no diretório _delta_log/, e esses manifestos apontam para os arquivos de dados subjacentes da tabela (em formato Parquet). Quando os dados são adicionados, modificados ou excluídos, novos arquivos de dados são criados. Assim, no nível do arquivo, cada objeto é imutável. Essa abordagem otimiza o acesso eficiente aos dados e a integridade robusta dos dados.
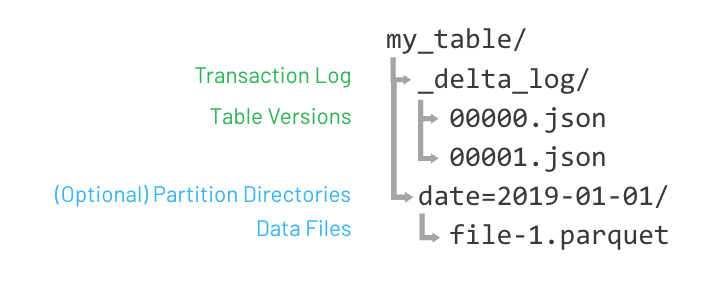
O Delta Lake gerencia inerentemente o versionamento de dados, armazenando todas as alterações como uma série de transações no log de transações. Cada transação representa uma nova versão da tabela, permitindo que os usuários façam viagem do tempo para estados anteriores, revertam para uma versão mais antiga e auditem a linhagem de dados.
Como o S3 lida com o versionamento de objetos
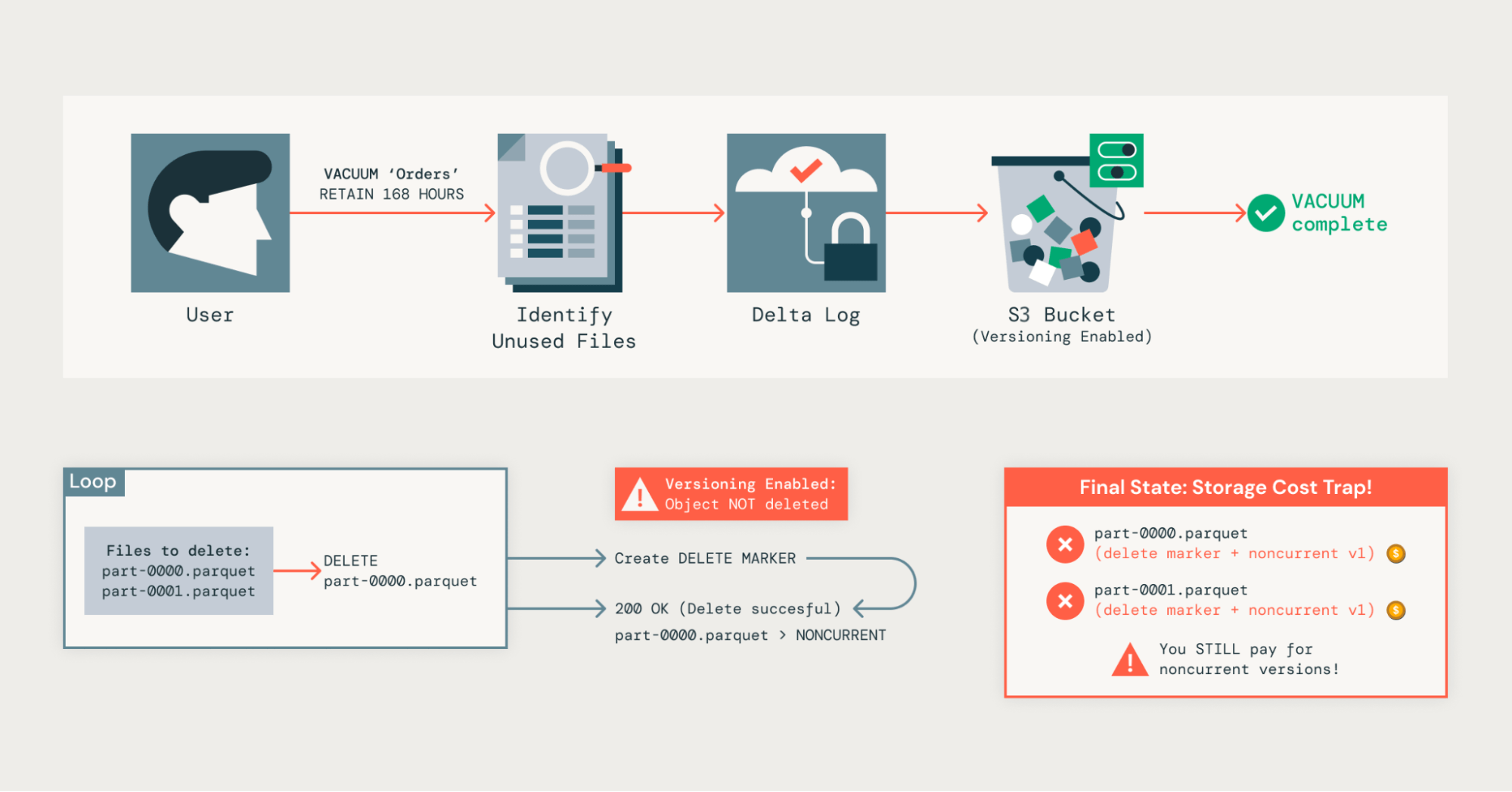
O S3 também oferece versionamento de objetos nativo como um recurso no nível do bucket. Quando ativado, o S3 retém várias versões de um objeto; só pode haver uma versão atual do objeto, e pode haver várias versões não atuais.
Quando um objeto é substituído ou excluído, o S3 marca a versão anterior como não atual e, em seguida, cria a nova versão como atual. Isso oferece proteção contra exclusões ou substituições acidentais.
O problema é que isso entra em conflito com o controle de versão do Delta Lake de duas maneiras:
- O Delta Lake apenas grava novos arquivos de transação e de dados; ele não os sobrescreve.
- Se os objetos de armazenamento fizerem parte de uma tabela Delta, só devemos operar neles usando um cliente do Delta Lake, como o Databricks Runtime nativo ou qualquer mecanismo que ofereça suporte à API REST do Unity Catalog de código aberto.
- O Delta Lake já oferece proteção contra exclusão acidental por meio de versionamento em nível de tabela e recursos de viagem do tempo.
- Executamos o comando vacuum nas tabelas Delta para remover arquivos que não são mais referenciados no log de transações.
- No entanto, devido ao versionamento de objetos do S3, isso não exclui totalmente os dados; em vez disso, eles se tornam uma versão não atual, pela qual ainda pagamos.
Níveis de armazenamento
Comparando classes de armazenamento
O S3 oferece classes de armazenamento flexíveis para armazenar dados inativos, que podem ser amplamente categorizadas como quentes, frias, geladas e de arquivamento. Elas se referem à frequência com que os dados são acessados e ao tempo necessário para recuperá-los:

Classes de armazenamento mais frias têm um custo menor por GB para armazenar dados, mas incorrem em custos e latência mais altos ao recuperá-los. Também queremos aproveitar esses recursos para o armazenamento do Lakehouse, mas, se aplicados sem cuidado, eles podem ter consequências significativas para o desempenho da query e até resultar em custos mais altos do que simplesmente armazenar tudo no S3 Standard.
Erros de classe de armazenamento
Usando políticas de ciclo de vida, o S3 pode mover arquivos automaticamente para diferentes classes de armazenamento após um período de tempo desde a criação do objeto. Camadas frias como o S3-IA parecem uma opção segura à primeira vista, pois ainda têm um tempo de recuperação rápido; no entanto, isso depende dos padrões de query exatos.
Por exemplo, digamos que temos uma tabela Delta particionada por uma coluna DATE created_dt, e ela serve como uma tabela ouro para fins de relatórios. Aplicamos uma política de ciclo de vida que move os arquivos para o S3-IA após 30 dias para economizar custos. No entanto, se um analista query a tabela sem uma cláusula WHERE, ou precisar usar dados mais antigos e usar WHERE created_dt >= curdate() - INTERVAL 90 DAYS, vários arquivos no S3-IA serão recuperados e incorrerão no custo de recuperação mais alto. O analista pode não perceber que está fazendo algo errado, mas a equipe de FinOps notará os custos elevados de recuperação do S3-IA.
Pior ainda, digamos que, após 90 dias, movamos os objetos para a classe S3 Glacier Deep Archive ou Glacier Flexible Retrieval. O mesmo problema ocorre, mas dessa vez a query falha porque tenta acessar arquivos que devem ser restaurados ou descongelados antes de serem usados. Essa restauração é um processo manual normalmente executado por um engenheiro de cloud ou administrador de plataforma, que pode levar até 12 horas para ser concluído. Como alternativa, você pode escolher o método de recuperação "Expedited", que leva de 1 a 5 minutos. Consulte a documentação da Amazon para obter mais detalhes sobre a restauração de objetos das classes de armazenamento de arquivamento do Glacier.
Veremos em breve como mitigar essas armadilhas das classes de armazenamento.
Custos de transferência de dados
A terceira categoria de erros caros de armazenamento do Lakehouse é a transferência de dados. Considere em qual região da cloud seus dados estão armazenados, de onde eles são acessados e como as solicitações são roteadas na sua rede.
Quando os dados do S3 são acessados de uma região diferente da do bucket do S3, há custos de saída de dados. Isso pode se tornar rapidamente um item significativo na sua fatura e é mais comum em casos de uso que exigem suporte a várias regiões, como cenários de alta disponibilidade ou recuperação de desastres.
NAT Gateways
O erro mais comum nesta categoria é deixar o tráfego do S3 passar pelo seu NAT Gateway. Por padrão, os recursos em sub-redes privadas acessarão o S3 roteando o tráfego para o endpoint público do S3 (por exemplo, s3.us-east-1.amazonaws.com). Como este é um host público, o tráfego passará pelo NAT Gateway da sua sub-rede, que custa aproximadamente US$ 0,045 por GB. Isso pode ser encontrado no AWS Cost Explorer em Serviço = Amazon EC2 e Tipo de uso = NatGateway-Bytes ou Tipo de uso = <REGION>-DataProcessing-Bytes.
Isso inclui instâncias do EC2 iniciadas por clusters clássicos do Databricks e warehouses, porque as instâncias do EC2 são iniciadas na sua VPC da AWS. Se suas instâncias do EC2 estiverem em uma Zona de Disponibilidade (AZ) diferente da do Gateway NAT, você também terá um custo adicional de aproximadamente US$ 0,01 por GB. Isso pode ser encontrado no AWS Cost Explorer em Serviço = Amazon EC2 e Tipo de uso = <REGION>-DataTransfer-Regional-Bytes ou Tipo de uso = DataTransfer-Regional-Bytes.
Como essas cargas de trabalho normalmente são uma fonte significativa de leituras e gravações no S3, esse erro pode ser responsável por uma porcentagem substancial dos seus custos relacionados ao S3. A seguir, detalharemos as soluções técnicas para cada um desses problemas.
3. Detalhes da solução técnica
Correção dos custos de NAT Gateway S3
Endpoints de Gateway do S3
Vamos começar com o que talvez seja o problema mais fácil de corrigir: a rede da VPC, para que o tráfego do S3 não use o gateway NAT e não passe pela Internet pública. A solução mais simples é usar um endpoint de gateway do S3, um serviço de endpoint de VPC regional que lida com o tráfego do S3 para a mesma região da sua VPC, ignorando o gateway NAT. Os endpoints de gateway do S3 não têm custos, nem para o endpoint nem para os dados transferidos por ele.
Script: Identificar Endpoints de gateway S3 ausentes
Fornecemos o seguinte script Python para localizar VPCs em uma região que atualmente não têm um S3 Gateway Endpoint.
Observação: para usar este ou qualquer outro script deste blog, você precisa ter o Python 3.9 ou superior instalado e o boto3 (pip install boto3). Além disso, esses scripts não podem ser executados no compute Serverless sem usar as Credenciais de Serviço do Unity Catalog, pois o acesso aos seus recursos da AWS é necessário.
Salve o script como check_vpc_s3_endpoints.py e faça a execução do script com:
Você verá um resultado como o seguinte:
Depois de identificar essas VPCs candidatas, consulte a documentação da AWS para criar endpoints de gateway do S3.
Rede S3 multirregional
Para casos de uso avançados que exigem padrões de S3 de várias regiões, podemos utilizar Endpoints de interface do S3, que exigem mais esforço de configuração. Confira nosso blog completo com exemplos de comparações de custos para obter mais detalhes sobre esses padrões de acesso:
https://www.databricks.com/blog/optimizing-aws-s3-access-databricks
Compute clássica vs. Serverless
A Databricks também oferece serverless compute totalmente gerenciado, incluindo serverless Lakeflow Jobs, serverless SQL warehouses e serverless Lakeflow Spark Declarative Pipelines. Com serverless compute, a Databricks faz o trabalho pesado para você e já encaminha o tráfego do S3 por meio dos S3 Gateway Endpoints!
Consulte Serverless compute plane networking para mais detalhes sobre como Serverless compute roteia o tráfego para o S3.
Suporte a arquivamento no Databricks
O Databricks oferece suporte a arquivamento para o S3 Glacier Deep Archive e o Glacier Flexible Retrieval, disponível em Visualização Pública para o Databricks Runtime 13.3 LTS e versões posteriores. Use este recurso se precisar implementar políticas de ciclo de vida da classe de armazenamento do S3, mas quiser mitigar a recuperação lenta/cara discutida anteriormente. Habilitar o suporte a arquivamento basicamente informa ao Databricks para ignorar arquivos mais antigos que o período especificado.
O suporte a arquivamento só permite querys que podem ser respondidas corretamente sem tocar nos arquivos arquivados. Portanto, é altamente recomendável que você use VIEWs para restringir as consultas e acessar somente os dados não arquivados nessas tabelas. Caso contrário, as queries que exigem dados em arquivos arquivados ainda falharão, fornecendo aos usuários uma mensagem de erro detalhada.
Observação: o Databricks não interage diretamente com as políticas de gerenciamento do ciclo de vida no bucket S3. Você deve usar esta propriedade da tabela em conjunto com uma política regular de gerenciamento do ciclo de vida do S3 para implementar totalmente o arquivamento. Se você habilitar essa configuração sem definir políticas de ciclo de vida para o armazenamento de objetos em cloud, o Databricks ainda ignorará os arquivos com base no limite especificado, mas nenhum dado será arquivado.
Para usar o suporte a arquivamento na sua tabela, primeiro defina a propriedade da tabela:
Em seguida, crie uma política de ciclo de vida do S3 no bucket para transicionar objetos para o Glacier Deep Archive ou Glacier Flexible Retrieval após o mesmo número de dias especificado na propriedade da tabela.
Identificar buckets problemáticos
Em seguida, identificaremos os candidatos a baldes S3 para otimização de custos. O script a seguir itera os buckets do S3 na sua conta da AWS e registra os buckets que têm o controle de versão de objeto ativado, mas nenhuma política de ciclo de vida para excluir versões não atuais.
O script deve gerar os buckets candidatos da seguinte forma:
Estimar a economia de custos
Em seguida, podemos usar o Cost Explorer e o S3 Lens para estimar a possível economia de custos para os objetos não correntes não verificados de um bucket do S3.
A Amazon lançou o serviço S3 Lens, que oferece um dashboard pronto para uso para o uso do S3, que geralmente está disponível em https://console.aws.amazon.com/s3/lens/dashboard/default.
Primeiro, navegue até o painel do S3 Lens > Visão geral > Tendências e distribuições. Para a métrica principal, selecione % de bytes de versões não atuais e, para a métrica secundária, selecione Bytes de versões não atuais. Opcionalmente, você pode filtrar por account, região, classe de armazenamento e/ou buckets na parte superior do painel.
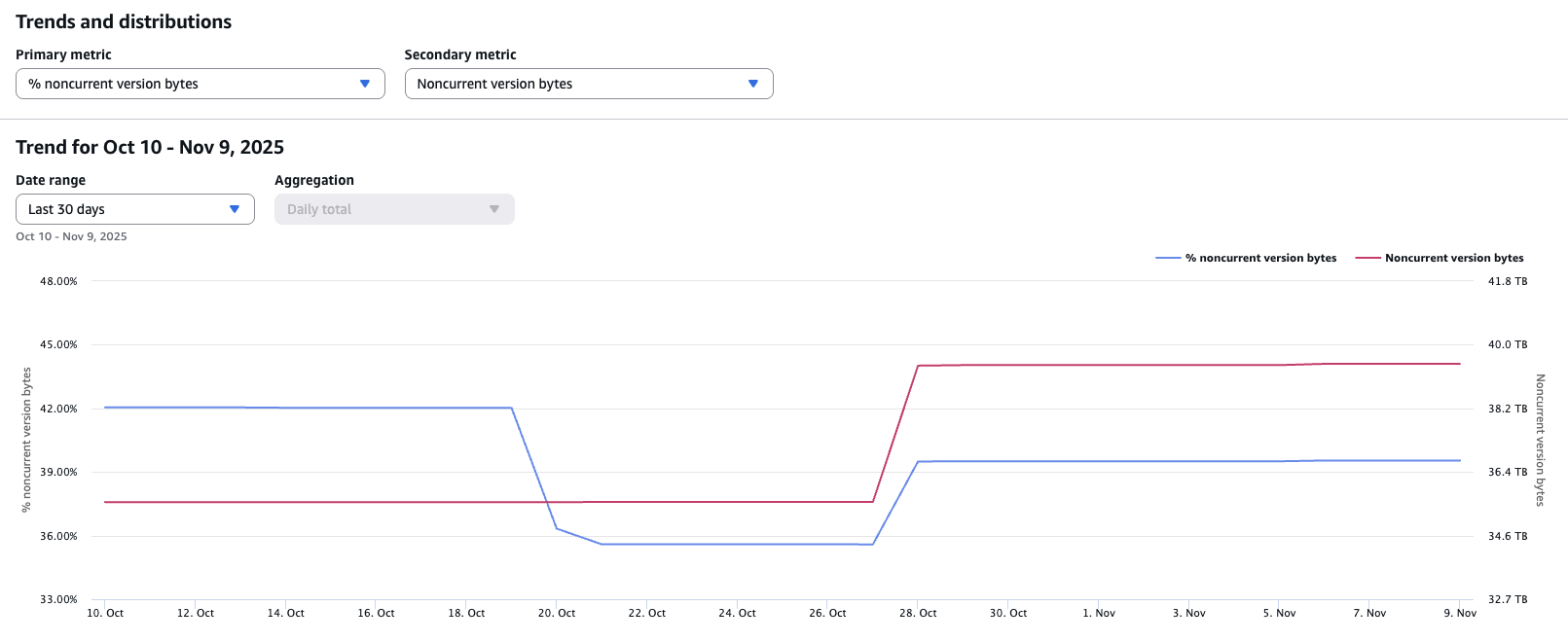
No exemplo acima, 40% do armazenamento é ocupado por bytes de versões não atuais, ou ~40 TB de dados físicos.
Em seguida, navegue até o AWS Cost Explorer. No lado direito, altere os filtros:
- Serviço: S3 (Simple Storage Service)
- Grupo de tipos de uso: selecione todos os grupos de tipos de uso S3: Storage * que se aplicam:
- S3: Storage - Express One Zone
- S3: Armazenamento - Glacier
- S3: Armazenamento - Glacier Deep Archive
- S3: Storage - Intelligent Tiering
- S3: Armazenamento - One Zone IA
- S3: Armazenamento - Redundância Reduzida
- S3: Storage - Standard
- S3: Armazenamento - Acesso padrão infrequente
Aplique os filtros e altere Agrupar por para Operação da API para obter um gráfico como o seguinte:
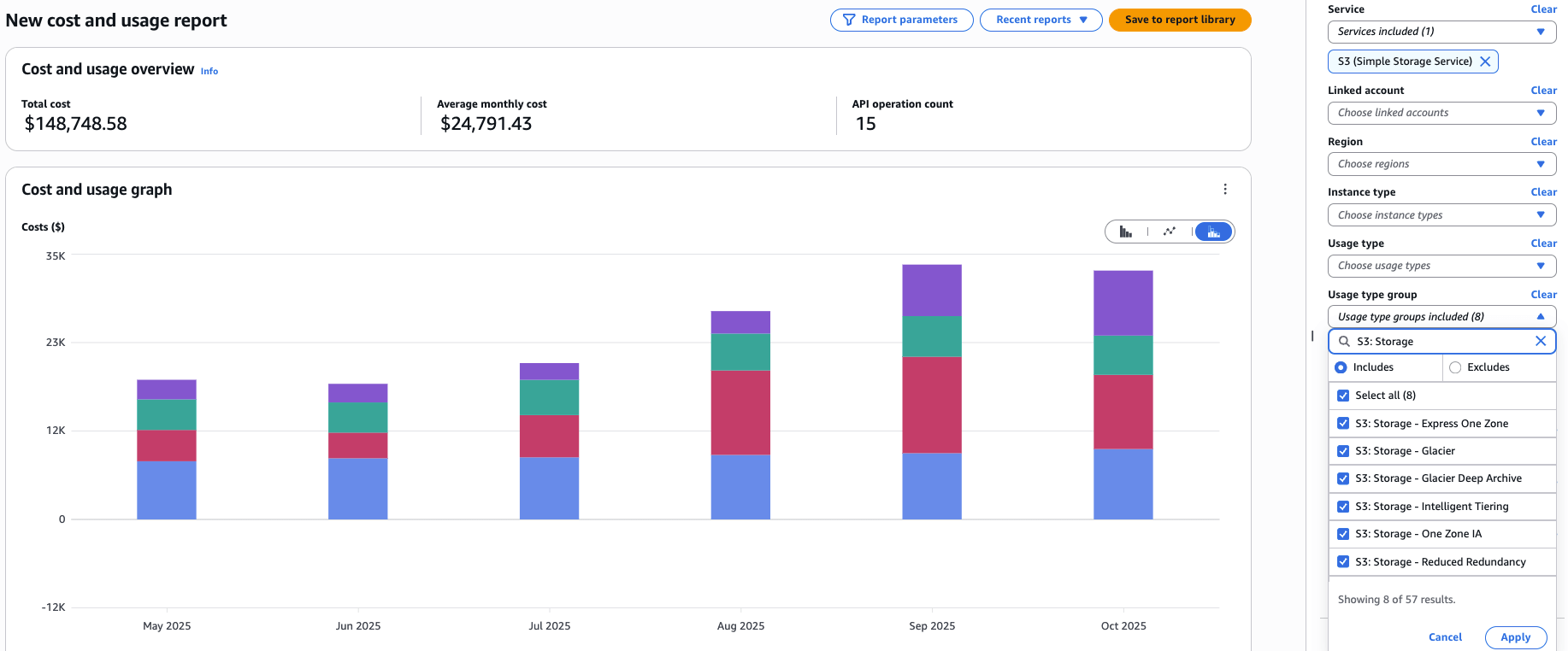
Observação: se você filtrou para buckets específicos no S3 Lens, deve corresponder a esse escopo no Cost Explorer, filtrando por Tag:Name para o nome do seu bucket S3.
Combinando esses dois relatórios, podemos estimar que, ao eliminar os bytes de versões não atuais de nossos buckets do S3 usados para tabelas do Delta Lake, economizaríamos ~40% do custo médio mensal de armazenamento do S3 (US$ 24.791) → US$ 9.916 por mês!
Implementar otimizações
Em seguida, começamos a implementar as otimizações para versões não atuais em um processo de duas etapas:
- Implemente políticas de ciclo de vida para versões não atuais.
- (Opcional) Desative o versionamento de objetos no bucket S3.
Políticas do ciclo de vida para versões não atuais
No console da AWS (UI), navegue até a tab Gerenciamento do bucket S3 e clique em Criar regra de ciclo de vida.
Escolha um escopo de regra:
- Se o seu bucket armazena apenas tabelas Delta, selecione 'Aplicar a todos os objetos no bucket'.
- Se suas tabelas Delta estiverem isoladas em um prefixo dentro do bucket, selecione "Limitar o escopo desta regra usando um ou mais filtros" e insira o prefixo (por exemplo, delta/).
Em seguida, marque a caixa de seleção Excluir permanentemente versões não atuais de objetos.
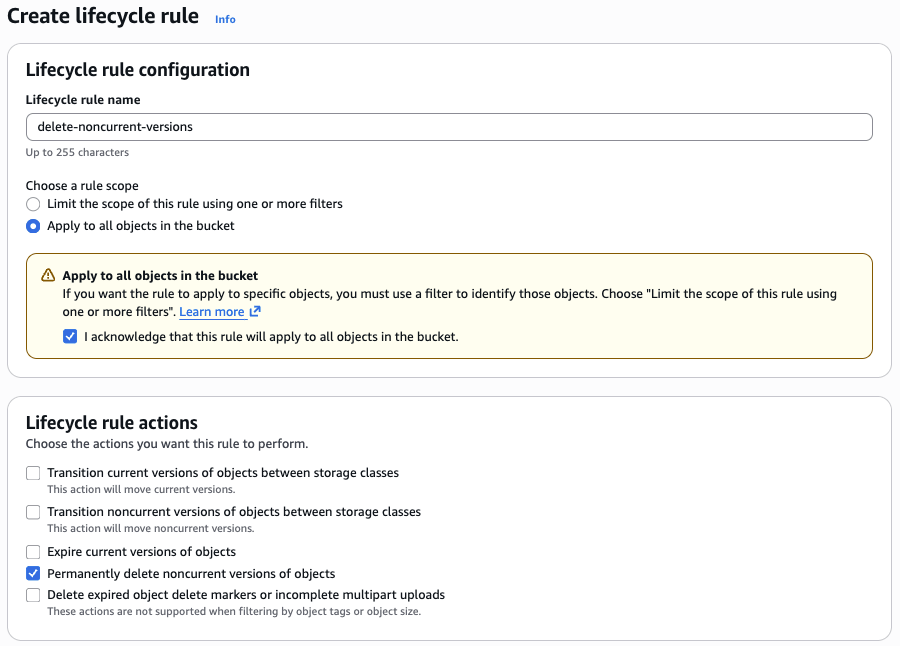
Em seguida, insira quantos dias você deseja manter os objetos não circulantes depois que eles se tornarem não circulantes. Observação: Isso serve como um backup para proteger você contra exclusão acidental. Por exemplo, se usarmos 7 dias para a política de ciclo de vida, quando fizermos VACUUM em uma tabela Delta para remover arquivos não utilizados, teremos 7 dias para restaurar os objetos de versão não atual no S3 antes que eles sejam excluídos permanentemente.
Revise a regra antes de continuar e clique em ‘Criar regra’ para concluir a configuração.

Isso também pode ser feito no Terraform com o recurso aws_s3_bucket_lifecycle_configuration:
Desativar o versionamento de objetos
Para desativar o controle de versão de objeto em um bucket S3 usando o console do AWS, navegue até a tab Propriedades do bucket e edite a propriedade de controle de versão do bucket.
Observação: para os buckets existentes que têm o controle de versão ativado, você só pode suspender o controle de versão, não desativá-lo. Isso suspende a criação de versões de objetos para todas as operações, mas preserva as versões de objetos existentes.
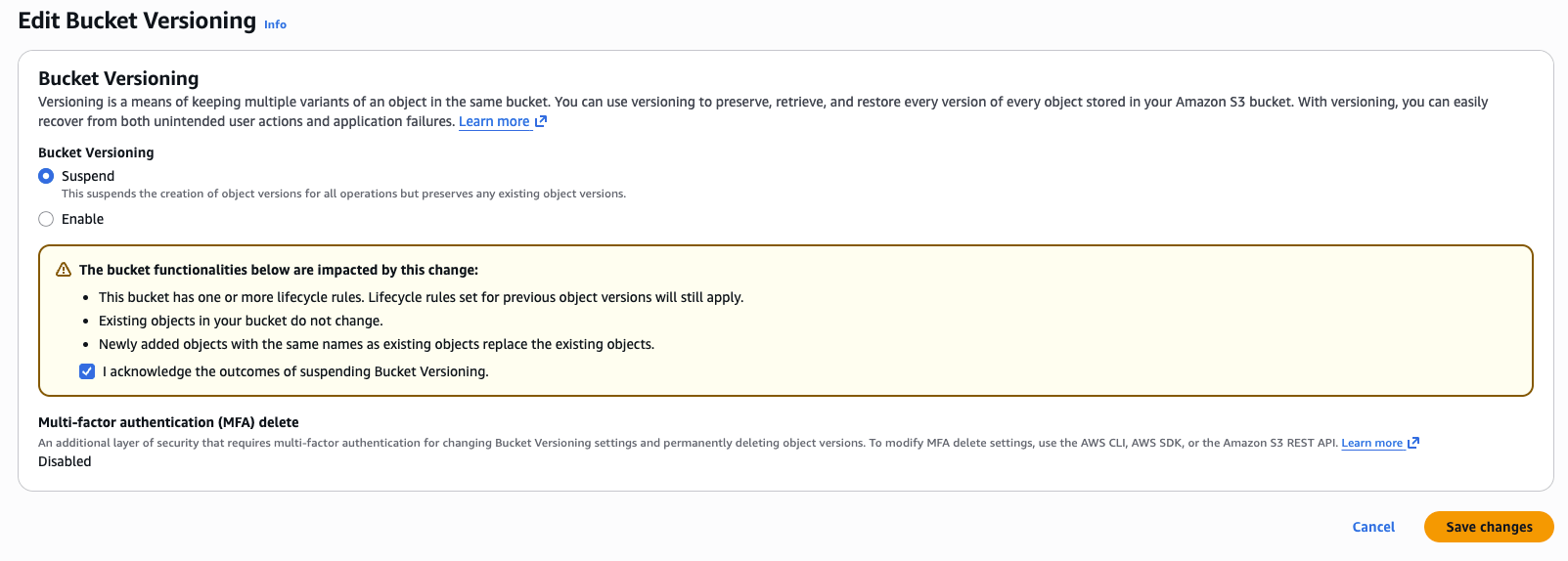
Isso também pode ser feito no Terraform com o recurso aws_s3_bucket_versioning:
Padrões para implantações futuras
Para garantir que os futuros buckets do S3 sejam implantados com as melhores práticas, use os módulos do Terraform fornecidos em terraform-databricks-sra, como o módulo unity_catalog_catalog_creation, que cria automaticamente os seguintes recursos:
- Um bucket do S3 configurado como um Local Externo do Unity Catalog
- IAM role configurada como uma Credencial de Armazenamento do Unity Catalog
- Criação de um novo catálogo, usando o bucket como o armazenamento gerenciado padrão
- Key do KMS gerenciada pelo cliente para criptografar o bucket do S3
- Desativou o controle de versão do S3
- Acesso público ao bucket do S3 desativado
Além dos módulos da Arquitetura de Referência de Segurança (SRA), você pode consultar os guias do provedor Terraform do Databricks para implantar Endpoints de gateway de VPC para o S3 ao criar novos Workspaces.
4. Cenários do mundo real
Ao aplicar as técnicas descritas neste blog para otimizar os custos do S3, os clientes podem reduzir significativamente os custos do armazenamento do Lakehouse sem comprometer o desempenho.
First Orion é uma empresa de tecnología de telecomunicações que fornece soluções de comunicação e mensagens de marca e proteção avançada de chamadas que ajudam empresas e grandes operadoras a oferecer interações telefônicas seguras e personalizadas, enquanto protegem os consumidores de golpes e fraudes. A First Orion otimizou seus buckets S3 do Unity Catalog usando estas práticas recomendadas, resultando em uma economia mensal de armazenamento de US$ 16 mil.
Normalmente, não há desvantagens ao aplicar essas otimizações de armazenamento. No entanto, alterar as configurações do S3, como políticas de ciclo de vida e versionamento, deve sempre ser feito com cuidado. Essas configurações são um fator crucial na recuperação de desastres e podem resultar na perda permanente de dados se não forem tratadas com cuidado.
5. Principais conclusões
- Se você observar altos custos de NatGateway-Bytes ou DataProcessing-Bytes, talvez precise de um S3 Gateway Endpoint.
- Evite classes de armazenamento de arquivamento em buckets do S3, a menos que utilize com muito cuidado o suporte a arquivamento do Databricks.
- Desative o controle de versão de objetos do S3 em buckets destinados ao armazenamento Lakehouse ou use políticas de ciclo de vida para remover objetos de versões não atuais após um curto período de tempo.
- Utilize módulos Terraform comprovados para implantar uma nova infraestrutura com as melhores práticas de armazenamento do Delta Lake, evitando assim problemas recorrentes.
6. os passos & recursos
Comece a otimizar seu armazenamento em cloud hoje para o armazenamento do Lakehouse! Use as ferramentas fornecidas neste blog para identificar rapidamente os buckets do S3 e as VPCs candidatas.
Entre em contato com sua equipe de account da Databricks se tiver dúvidas sobre como otimizar seu armazenamento cloud.
Se você tiver uma história de sucesso que gostaria de compartilhar sobre o uso dessas recomendações, compartilhe estes blogs e marque-nos com #databricks #dsa!
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.