Atribuição granular de uso para pipelines dbt com tags de consulta
Adicione tags, acompanhe e otimize cada modelo dbt — desde a atribuição de custos e depuração de desempenho até o monitoramento do ambiente — com apenas uma linha de configuração ou o Genie.
- Adicione tags a cada consulta dbt com equipe, centro de custo, projeto e ambiente — zero alterações de código em seus modelos SQL
- Consulte system.query.history para ver exatamente quais modelos dbt custam mais e onde o tempo de computação é gasto
- Implante um projeto de referência completo com Declarative Automation Bundles: pipeline dbt, dashboard de análise de Query Tag e job agendado — tudo a partir de um único repositório do GitHub
Seu projeto dbt executa 80 modelos todas as noites. A fatura do warehouse dobrou no último trimestre. O desempenho dos modelos varia muito, e os efeitos das otimizações mais recentes não estão claros. O setor financeiro pergunta qual equipe é a responsável. Você abre o histórico de consultas e vê... 80 linhas idênticas rotuladas como 'Databricks Dbt'. Boa sorte.
Com as Query Tags (agora em Public Preview), as equipes de dados agora podem se beneficiar de tags injetadas automaticamente prontas para uso, como dbt_model_name, que enriquecem cada execução. Você também pode anexar suas próprias tags personalizadas — equipe, centro de custo, ambiente, qualquer coisa — a cada consulta que seu pipeline gera.
As tags são registradas em system.query.history, fazendo com que a atribuição de custos, a depuração de desempenho e o monitoramento de carga de trabalho estejam a apenas uma consulta SQL de distância (detalhes completos na documentação).
Este blog apresenta um projeto dbt de código aberto completo que demonstra as Query Tags de ponta a ponta: da configuração aos dashboards de atribuição de custos. Tudo o que é descrito aqui está disponível como um repositório do GitHub que você pode clonar e implantar em seu próprio workspace, ou simplesmente perguntar ao Genie.
Como o dbt-databricks se integra às Query Tags
O adaptador dbt-databricks (versão 1.11+) suporta Query Tags nativamente. Existem três níveis nos quais as tags podem ser aplicadas, cada um baseado no anterior:
Tags injetadas automaticamente
Além de suas tags personalizadas, o dbt-databricks injeta automaticamente metadados sobre a execução de cada modelo:
Tag | Valor de exemplo | Descrição |
@@dbt_model_name | fct_daily_usage_by_sku | O modelo dbt que está sendo executado |
@@dbt_materialized | table | Estratégia de materialização (table, view, incremental, metric_view) |
@@dbt_core_version | 1.11.6 | dbt-core versão |
@@dbt_databricks_version | 1.12.0a1 | dbt-databricks versão do adaptador |
Essas auto-tags significam que você obtém visibilidade por modelo com configuração zero — o adaptador faz isso por você.
Tags no nível do perfil
A abordagem mais simples: adicione um campo query_tags a um destino específico em seu perfil dbt. Cada consulta no projeto herda essas tags automaticamente.
Por exemplo, esta única linha marca cada consulta com quatro dimensões: quem é o proprietário (team), para onde vai o custo (cost_center), a qual pipeline ela pertence (project_name) e em qual ambiente ela é executada (env).
Tags no nível do modelo
Para uma atribuição mais granular, você pode fornecer tags em modelos específicos no dbt_project.yml ou na configuração do modelo em sua definição sql.
As tags no nível do modelo se fundem com as tags no nível do perfil. Se ambos definirem a mesma chave, o valor no nível do modelo terá prioridade.
Onde as tags aparecem – system.query.history
Depois de executar dbt run, cada instrução SQL aparece em system.query.history com a coluna query_tags preenchida como um MAP. Você pode consultá-la usando a sintaxe padrão de acesso a mapas:
Isso retorna cada consulta marcada dos últimos 7 dias, com as tags personalizadas e injetadas automaticamente extraídas em colunas individuais — prontas para agregação.
Você também pode encontrar as Query Tags para a consulta que executou na UI do Histórico de Consultas ou na UI de Monitoramento do SQL Warehouse.

No canto inferior direito do Perfil de Consulta, você verá as Query Tags que definiu, fornecendo todas as informações necessárias em um piscar de olhos.

Atribuição de custos com Query Tags
As Query Tags permitem que a atribuição de uso granular seja determinada diretamente por meio de consultas SQL, eliminando a necessidade de análise manual de logs ou divisão de recursos do warehouse.
Quais modelos dbt consomem mais recursos do warehouse?
Você pode responder a isso de duas maneiras: pergunte ao Genie em linguagem natural para exploração ad-hoc ou escreva você mesmo o SQL para obter um resultado repetível e pronto para o dashboard. Ambos leem os mesmos dados de system.query.history .
Opção 1: Genie

Genie escreve e executa a consulta equivalente, e você continua detalhando com perguntas de acompanhamento sem precisar tocar em nenhum SQL.
Opção 2: SQL
Qualquer um dos caminhos retorna o mesmo cenário. Em nosso projeto de referência, as quatro tabelas mart (materializadas como table) dominam o tempo de computação, enquanto as views de staging e as views de métricas são quase instantâneas. Isso informa imediatamente onde os esforços de otimização devem se concentrar.

Construindo um dashboard de automonitoramento
Nosso projeto de referência inclui um dashboard de AI/BI que consulta system.query.history filtrado pelas próprias query tags do projeto. O resultado: o pipeline que analisa os dados de faturamento também rastreia seus próprios custos — fazendo dogfooding das Query Tags em si mesmo.
O dashboard inclui:
- KPIs: Total de consultas marcadas, total de segundos de computação, modelos dbt distintos
- Atividade diária: Contagem de consultas e tempo de computação por dia, divididos por ambiente
- Detalhamento do modelo: Tempo de computação por modelo, colorido por tipo de materialização
- Divisão de materialização: Gráfico de pizza mostrando como a computação se distribui entre table, view e metric_view
- Tabela de detalhes da consulta: Cada consulta marcada com modelo, duração, ambiente e executor
Em nosso projeto de referência, os quatro modelos mart representaram 92% do tempo de computação — sem as Query Tags, essa percepção seria invisível.
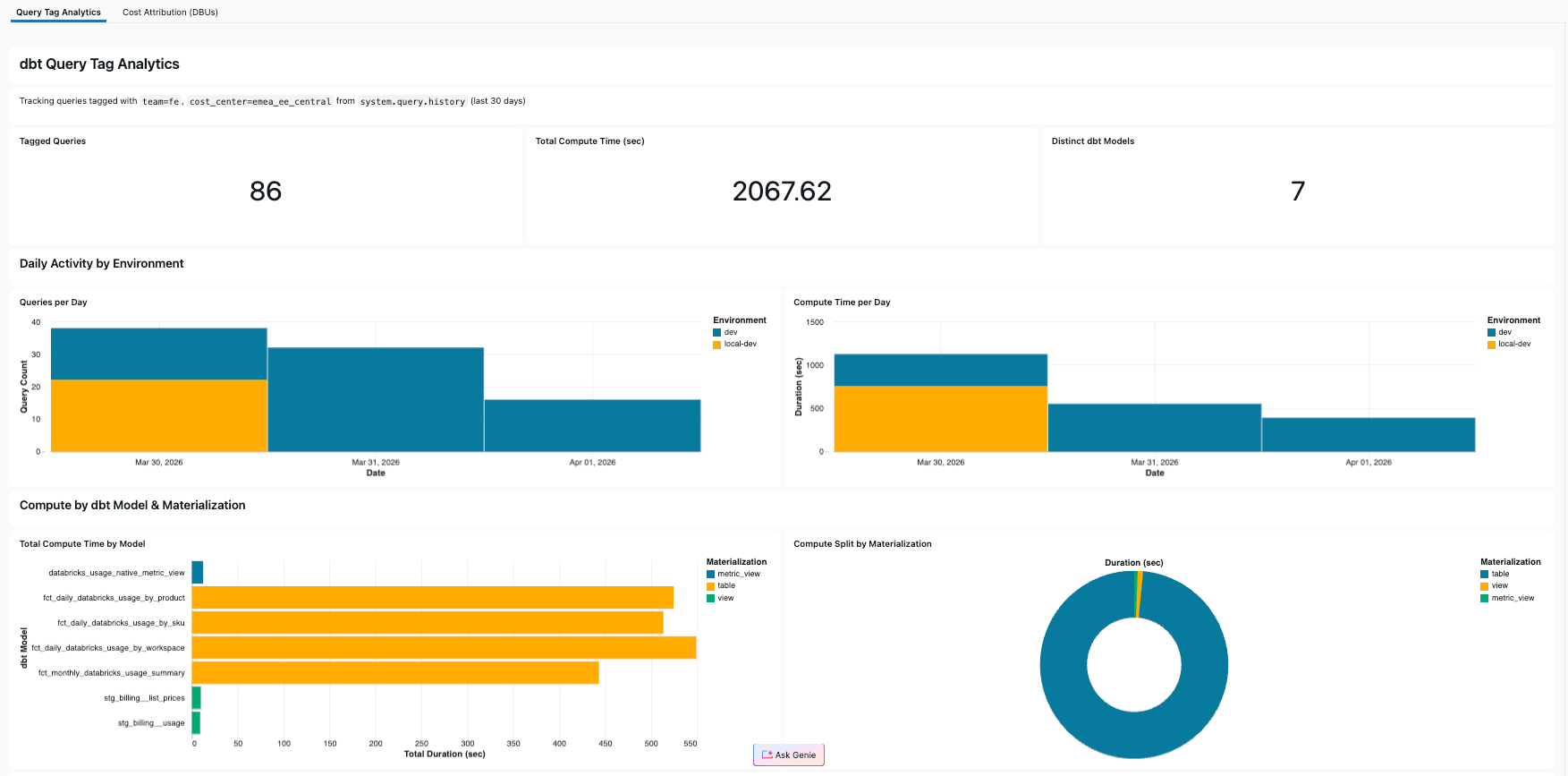
Criar esse dashboard você mesmo leva minutos com o Genie Code: basta solicitar o tempo de computação por modelo dbt a partir de system.query.history filtrado por suas query tags, e ele escreve o SQL e monta os recursos visuais. Se preferir ir direto para o resultado final, o dashboard também vem no projeto de referência e é implantado com um único databricks bundle deploy junto com o job dbt (consulte o repositório do GitHub para obter o guia detalhado).
Marcação de metric views
As metric views do Databricks (disponíveis com dbt-databricks 1.12+) são um novo tipo de materialização que define semânticas de negócios reutilizáveis na forma de dimensões e medidas diretamente no Unity Catalog (consulte a documentação completa). Elas podem conter Query Tags como qualquer outro modelo, usando o parâmetro de configuração query_tags:
Observe a distinção: query_tags são anexadas às consultas SQL que criam ou atualizam a metric view (rastreadas em system.query.history), enquanto databricks_tags são tags do Unity Catalog no próprio objeto (para governança e descoberta). O primeiro serve para rastreamento no nível da consulta, enquanto o segundo é no nível do objeto do Unity Catalog para a descoberta geral de dados.
Melhores práticas para marcação de projetos dbt
Neste artigo, abordamos o processo holístico para construir uma prática sólida de FinOps, onde as Query Tags são fundamentais para a atribuição de custos. Aqui está o que aprendemos ao construir o projeto de referência e conversar com usuários avançados do dbt:
- Use uma hierarquia de tags consistente. Defina tags para toda a organização no nível do perfil (team, cost_center, project_name, env) e reserve tags no nível do modelo para casos excepcionais. Isso mantém as tags previsíveis e evita a dispersão de configurações por modelo.
- Sempre marque o ambiente. Use valores de env diferentes para desenvolvimento local (local-dev) e jobs implantados (dev, staging, prod). Isso permite separar consultas de desenvolvimento ad-hoc de execuções de produção agendadas em suas análises. Em nosso projeto de referência, o perfil local define "env": "local-dev" enquanto o perfil implantado define "env": "dev".
- Use `project_name` para distinguir pipelines. Quando vários projetos dbt compartilham um warehouse, project_name permite atribuir custos por pipeline sem precisar dividir os warehouses. Combinado com o @@dbt_model_name injetado automaticamente, você obtém rastreabilidade total: projeto → modelo → materialização.
- Não exagere nas tags. As tags injetadas automaticamente já cobrem o nome do modelo, o tipo de materialização e as versões do adaptador. Raramente é necessário duplicar essas informações em tags personalizadas. Foque as tags personalizadas no contexto de negócios que o dbt não consegue inferir: propriedade da equipe, centro de custo, identidade do projeto.
- Marque as metric views explicitamente. Como as metric views são uma materialização mais recente, é útil marcá-las com uma chave feature (por exemplo, "feature": "metric_view") para que você possa filtrar facilmente as consultas de criação de metric views em sua análise de custos.
Experimente você mesmo
O projeto de referência completo está disponível no GitHub: github.com/databricks-solutions/dbt-query-tags
Para começar:
- Clone o repositório
- Crie um ambiente virtual Python 3.12 e instale as dependências: pip install dbt-databricks>=1.12.0a1
- Atualize profiles.yml com o host do seu workspace, o caminho HTTP do SQL warehouse, o catálogo e as query tags personalizadas
- Execute dbt deps && dbt run --profiles-dir . para executar o pipeline
- Consulte system.query.history para ver suas tags em ação
- Atualize dbt_profiles/profiles.yml e databricks.yml para apontar para a configuração correta.
- Implante com databricks bundle deploy para execuções agendadas e o dashboard de análise
Substitua pelos valores de sua própria equipe e centro de custo. O padrão funciona para qualquer projeto dbt no Databricks.
Clone o repositório hoje mesmo! Basta uma linha em seu perfil para desbloquear a visibilidade de atribuição de uso no nível do modelo em todo o seu warehouse.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.