Dívida Técnica Oculta dos Sistemas de GenAI
Os custos ocultos da IA generativa: gerenciando a proliferação de ferramentas, pipelines opacos e avaliações subjetivas
por Jeanne Choo e Conor Murphy
- Desenvolvedores que trabalham com ML clássico e IA generativa alocam seu tempo de maneiras muito diferentes
- A IA generativa introduz novas formas de dívida técnica que precisam ser quitadas
- Novas práticas de desenvolvimento precisam ser introduzidas para lidar com essas novas formas de dívida técnica
Introdução
Se compararmos amplamente os fluxos de trabalho de machine learning clássico e de IA generativa, descobriremos que os passos gerais do fluxo de trabalho permanecem semelhantes entre os dois. Ambos exigem coleta de dados, engenharia de recursos, otimização de modelo, implantação, avaliação etc., mas os detalhes de execução e as alocações de tempo são fundamentalmente diferentes. Mais importante, a AI generativa introduz fontes únicas de dívida técnica que podem se acumular rapidamente se não forem gerenciadas adequadamente, incluindo:
- Proliferação de ferramentas - dificuldade em gerenciar e selecionar entre as ferramentas de agente em expansão
- Prompt stuffing - prompts excessivamente complexos que se tornam insustentáveis
- Pipelines opacos: a falta de rastreamento adequado dificulta a depuração.
- Sistemas de feedback inadequados - falha em capturar e utilizar o feedback humano de forma eficaz
- Engajamento insuficiente das partes interessadas - não manter comunicação regular com os usuários finais
Neste blog, abordaremos cada forma de dívida técnica por sua vez. Em última análise, as equipes em transição do ML clássico para a AI generativa precisam estar cientes dessas novas fontes de débito e ajustar suas práticas de desenvolvimento de acordo, dedicando mais tempo à avaliação, ao gerenciamento de stakeholders, ao monitoramento subjetivo da qualidade e à instrumentação, em vez da limpeza de dados e da engenharia de recursos que dominavam os projetos de ML clássico.
Qual a diferença entre os fluxos de trabalho de Machine Learning (ML) clássico e de Inteligência Artificial (AI) generativa?
Para entender onde o campo está agora, é útil comparar como nossos fluxos de trabalho para IA generativa se comparam com o que usamos para problemas de machine learning clássico. A seguir, uma visão geral de alto nível. Como essa comparação revela, as etapas amplas do fluxo de trabalho permanecem as mesmas, mas há diferenças nos detalhes de execução que levam a diferentes etapas recebendo mais ênfase. Como veremos, a IA generativa também introduz novas formas de dívida técnica, que têm implicações em como mantemos nossos sistemas em produção.
| Passo do fluxo de trabalho | ML clássico | IA generativa |
|---|---|---|
| Coleta de dados | Os dados coletados representam eventos do mundo real, como vendas no varejo ou falhas de equipamentos. Formatos estruturados, como CSV e JSON, são frequentemente usados. | Os dados coletados representam o conhecimento contextual que ajuda um modelo de linguagem a fornecer respostas relevantes. Tanto dados estruturados (geralmente em tabelas em tempo real) quanto dados não estruturados (imagens, vídeos, arquivos de texto) podem ser usados. |
| Engenharia de recursos/ Transformação de dados | As etapas de transformação de dados envolvem a criação de novos recursos para refletir melhor o espaço do problema (por exemplo, criando recursos de dia da semana e fim de semana a partir de dados de timestamp) ou a realização de transformações estatísticas para que os modelos se ajustem melhor aos dados (por exemplo, padronizando variáveis contínuas para agrupamento k-means e fazendo uma transformação logarítmica de dados assimétricos para que sigam uma distribuição normal). | Para dados não estruturados, a transformação envolve a segmentação, a criação de representações de embedding e (possivelmente) a adição de metadados, como cabeçalhos e tags, aos segmentos. Para dados estruturados, pode ser necessário desnormalizar tabelas para que os modelos de linguagem grandes (LLMs) não precisem considerar os joins de tabelas. Adicionar descrições de metadados de tabelas e colunas também é importante. |
| Design do pipeline do modelo | Geralmente abordado por um pipeline básico com três passos:
| Geralmente envolve um passo de reescrita de query, alguma forma de recuperação de informação, possivelmente chamada de ferramenta e verificações de segurança no final. Os pipelines são muito mais complexos, envolvem infraestrutura mais complexa, como bancos de dados e integrações de API, e às vezes são tratados com estruturas semelhantes a grafos. |
| Otimização de modelo | A otimização do modelo envolve o ajuste de hiperparâmetros usando métodos como validação cruzada, busca em grade (grid search) e busca aleatória (random search). | Embora alguns hiperparâmetros, como temperature, top-k e top-p, possam ser alterados, a maior parte do esforço é gasta no ajuste de prompts para orientar o comportamento do modelo. Como uma cadeia de LLM pode envolver muitos passos, um engenheiro de IA também pode experimentar dividir uma operação complexa em componentes menores. |
| Implantação | Os modelos são muito menores do que os modelos de fundação, como os LLMs. Aplicações de ML inteiras podem ser hospedadas em uma CPU sem a necessidade de GPUs. O versionamento, o monitoramento e a linhagem de modelos são considerações importantes. As previsões do modelo raramente exigem cadeias ou gráficos complexos, então os rastros geralmente não são usados. | Como os modelos de base são muito grandes, eles podem ser hospedados em uma GPU central e expostos como uma API para vários aplicativos de IA voltados para o usuário. Esses aplicativos atuam como “wrappers” em torno da API do modelo de base e são hospedados em CPUs menores. Gerenciamento de versões de aplicativos, monitoramento e linhagem são considerações importantes. Além disso, como as cadeias e os grafos de LLM podem ser complexos, é necessário um rastreamento adequado para identificar gargalos de query e bugs. |
| Avaliação | Para o desempenho do modelo, os cientistas de dados podem usar métricas quantitativas definidas, como a pontuação F1 para classificação ou a raiz do erro quadrático médio para regressão. | A correção da saída de um LLM depende de julgamentos subjetivos, por exemplo, da qualidade de um resumo ou tradução. Portanto, a qualidade da resposta geralmente é julgada com diretrizes, e não com métricas quantitativas. |
Como os desenvolvedores de Machine Learning estão alocando seu tempo de forma diferente em projetos de GenAI?
Por experiência própria, equilibrando um projeto de previsão de preços com um projeto de construção de um agente de chamada de ferramentas, descobrimos que existem algumas diferenças importantes nos passos de desenvolvimento e implantação do modelo.
Ciclo de desenvolvimento do modelo
O ciclo de desenvolvimento interno normalmente se refere ao processo iterativo pelo qual os desenvolvedores de machine learning passam ao construir e refinar seus pipelines de modelo. Geralmente ocorre antes dos testes de produção e da implantação do modelo.
Veja como os profissionais de ML clássico e GenAI gastam seu tempo de forma diferente neste passo:
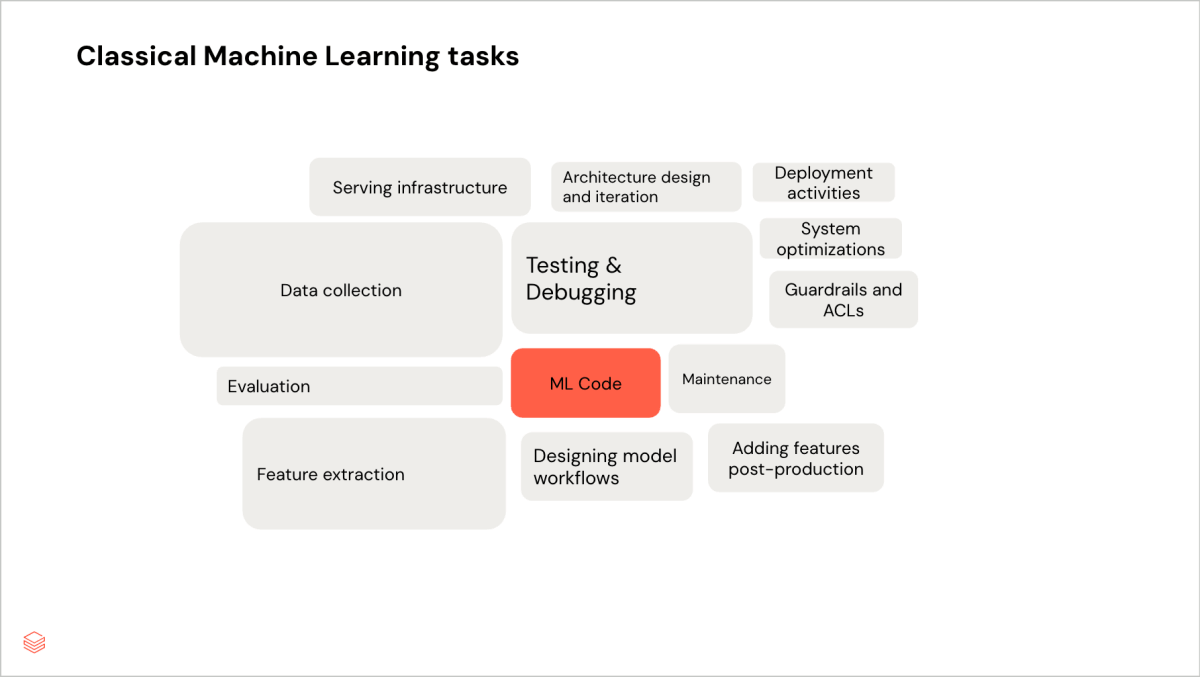
Ladrões de tempo no desenvolvimento de modelos de ML clássico
- Coleta de dados e refinamento de recursos: em um projeto de machine learning clássico, a maior parte do tempo é gasta no refinamento iterativo dos recursos e dos dados de entrada. Uma ferramenta para gerenciar e compartilhar recursos, como o Databricks Feature Store, é usada quando há muitas equipes envolvidas ou muitos recursos para gerenciar manualmente com facilidade.
Em contraste, a avaliação é direta: você executa seu modelo e vê se houve uma melhoria em suas métricas quantitativas, antes de voltar a considerar como uma melhor coleta de dados e melhores recursos podem aprimorar o modelo. Por exemplo, no caso do nosso modelo de previsão de preços, nossa equipe observou que a maioria das previsões incorretas resultava da falha em levar em conta os outliers dos dados. Tivemos então que considerar como incluir recursos que representassem esses outliers, permitindo que o modelo identificasse esses padrões.
Gargalos de tempo no desenvolvimento de modelos e pipelines de AI generativa
- Avaliação: em um projeto de IA generativa, a alocação de tempo relativa entre a coleta, a transformação e a avaliação de dados é invertida. A coleta de dados normalmente envolve reunir contexto suficiente para o modelo, que pode estar na forma de documentos ou manuais de base de conhecimento não estruturados. Esses dados não exigem limpeza extensiva. Mas a avaliação é muito mais subjetiva e complexa e, consequentemente, mais demorada. Você não está apenas iterando no pipeline do modelo, mas também precisa iterar em seu conjunto de avaliação. E mais tempo é gasto considerando casos extremos do que com o ML clássico.
Por exemplo, um conjunto inicial de 10 perguntas de avaliação pode não cobrir todo o espectro de perguntas que um usuário pode fazer a um bot de suporte. Nesse caso, você precisará coletar mais avaliações, ou os avaliadores de LLM que você configurou podem ser muito rigorosos, de modo que você precise reformular seus prompts para impedir que respostas relevantes sejam reprovadas nos testes. Os Evaluation Datasets do MLflow são úteis para versionar, desenvolver e auditar um “conjunto de ouro” de exemplos que devem sempre funcionar corretamente. - Gerenciamento das partes interessadas: Além disso, como a qualidade da resposta depende da entrada do usuário final, os engenheiros passam muito mais tempo em reuniões com usuários finais de negócios e gerentes de produto para coletar e priorizar requisitos, bem como iterar com base no feedback do usuário. Historicamente, o ML clássico muitas vezes não era amplamente voltado para o usuário final (por exemplo, previsões de séries temporais) ou era menos exposto a usuários não técnicos, então as demandas de gerenciamento de produto da AI generativa são muito maiores. A coleta de feedback sobre a qualidade da resposta pode ser feita por meio de uma interface de usuário simples hospedada no Databricks Apps que chama a API de Feedback do MLflow. O feedback pode então ser adicionado a um Rastreamento do MLflow e a um dataset de Avaliação do MLflow, criando um ciclo virtuoso entre o feedback e a melhoria do modelo.
Os diagramas a seguir comparam as alocações de tempo do ML clássico e da AI generativa para o ciclo de desenvolvimento do modelo.

Ciclo de implantação de modelos
Diferentemente do loop de desenvolvimento do modelo, o loop de implantação do modelo não se concentra na otimização do desempenho do modelo. Em vez disso, os engenheiros se concentram em testes sistemáticos, implantação e monitoramento em ambientes de produção.
Aqui, os desenvolvedores podem mover as configurações para arquivos YAML para facilitar as atualizações do projeto. Eles também podem refatorar pipelines de processamento de dados estáticos para serem executados em transmissão, usando um framework mais robusto como o PySpark em vez do Pandas. Finalmente, eles precisam considerar como configurar processos de teste, monitoramento e feedback para manter a qualidade do modelo.
Neste ponto, a automa�ção é essencial, e a integração e entrega contínuas são um requisito não negociável. Para gerenciar CI/CD para projetos de dados e AI no Databricks, os Databricks Asset Bundles geralmente são a ferramenta de escolha. Eles possibilitam descrever recursos do Databricks (como jobs e pipelines) como arquivos de origem e fornecem uma maneira de incluir metadados junto com os arquivos de origem do seu projeto.
Assim como na etapa de desenvolvimento do modelo, as atividades que consomem mais tempo em projetos de IA generativa em comparação com projetos de ML clássico nesta fase não são as mesmas.
Gargalos de tempo na implantação de modelos de ML clássico
- Refatoração: em um projeto clássico de machine learning, o código de um notebook pode ser bastante desorganizado. Diferentes combinações de dataset, recursos e modelos são continuamente testadas, descartadas e recombinadas. Como resultado, pode ser necessário um esforço significativo para refatorar o código do notebook para torná-lo mais robusto. Ter uma estrutura de pastas de repository de código definida (como o padrão Databricks ativo Bundles MLOps Stacks) pode fornecer a estrutura necessária para este processo de refatoração.
Alguns exemplos de atividades de refatoração incluem:- Abstraindo o código auxiliar em funções
- Criando bibliotecas auxiliares para que as funções de utilidades possam ser importadas e reutilizadas várias vezes
- Removendo configurações de notebooks para arquivos YAML
- Criar implementações de código mais eficientes que rodem de forma mais rápida e eficiente (por exemplo, removendo laços
foraninhados)
- Monitoramento de qualidade: o monitoramento de qualidade é outro consumidor de tempo porque os erros de dados podem assumir muitas formas e ser difíceis de detectar. Em particular, como Shreya Shankar et al. observam em seu artigo “Operationalizing Machine Learning: An Interview Study” , “Erros soft, como alguns recursos com valores nulos em um ponto de dados, são menos perniciosos e ainda podem gerar previsões razoáveis, tornando-os difíceis de capturar e quantificar.” Além disso, diferentes tipos de erros exigem respostas diferentes, e determinar a resposta apropriada nem sempre é fácil.
Um desafio adicional é que diferentes tipos de drift do modelo (como drift de recurso, drift de dados e drift de rótulos) precisam ser medidos em diferentes granularidades de tempo (diária, semanal, mensal), o que aumenta a complexidade. Para facilitar o processo, os desenvolvedores podem usar o Databricks Data Quality monitoramento para rastrear métricas de qualidade do modelo, a qualidade dos dados de entrada e o possível drift das entradas e previsões do modelo em uma estrutura holística.
Consumidores de tempo na implantação de modelos de IA generativa
- Monitoramento da qualidade: com a IA generativa, o monitoramento também consome uma quantidade substancial de tempo, mas por motivos diferentes:
- Requisitos em tempo real: projetos de machine learning clássico para tarefas como previsão de churn, previsão de preços ou readmissão de pacientes podem servir previsões em modo de lote (batch), executando talvez uma vez por dia, uma vez por semana ou uma vez por mês. No entanto, muitos projetos de IA generativa são aplicações em tempo real, como agentes de suporte virtual, agentes de transcrição ao vivo ou agentes de programação. Consequentemente, as ferramentas de monitoramento em tempo real precisam ser configuradas, o que significa monitoramento de endpoint em tempo real, pipelines de análise de inferência em tempo real e alertas em tempo real.
A configuração de gateways de API (como o Databricks AI Gateway) para realizar verificações de guardrail na API do LLM pode dar suporte aos requisitos de segurança e privacidade de dados. Esta é uma abordagem diferente do monitoramento de modelos tradicional, que é feito como um processo offline. - Avaliações subjetivas: como mencionado anteriormente, as avaliações para aplicações de IA generativa são subjetivas. Os engenheiros de implantação de modelos precisam considerar como operacionalizar a coleta de feedback subjetivo em seus pipelines de inferência. Isso pode assumir a forma de avaliações por juízes de LLM executadas nas respostas do modelo, ou selecionar um subconjunto de respostas do modelo para apresentar a um especialista no domínio para avaliação. Provedores de modelos proprietários otimizam seus modelos ao longo do tempo, então seus "modelos" são, na verdade, serviços propensos a regressões, e os critérios de avaliação precisam levar em conta o fato de que os pesos do modelo não são congelados como nos modelos autotreinados.
A capacidade de fornecer feedback de formato livre e classificações subjetivas ganha destaque. Frameworks como Databricks Apps e a API de Feedback do MLflow permitem interfaces de usuário mais simples que podem capturar esse feedback e vinculá-lo a chamadas específicas de LLM.
- Requisitos em tempo real: projetos de machine learning clássico para tarefas como previsão de churn, previsão de preços ou readmissão de pacientes podem servir previsões em modo de lote (batch), executando talvez uma vez por dia, uma vez por semana ou uma vez por mês. No entanto, muitos projetos de IA generativa são aplicações em tempo real, como agentes de suporte virtual, agentes de transcrição ao vivo ou agentes de programação. Consequentemente, as ferramentas de monitoramento em tempo real precisam ser configuradas, o que significa monitoramento de endpoint em tempo real, pipelines de análise de inferência em tempo real e alertas em tempo real.
- Testes: os testes costumam ser mais demorados em aplicações de IA generativa, por alguns motivos:
- Desafios não resolvidos: as próprias aplicações de IA generativa estão cada vez mais complexas, mas os frameworks de avaliação e teste ainda não acompanharam esse ritmo. Alguns cenários que tornam os testes desafiadores incluem:
- Longas conversas de múltiplos turnos
- Saída SQL que pode ou não capturar detalhes importantes sobre o contexto organizacional de uma empresa
- Garantindo o uso das ferramentas corretas em uma cadeia
- Avaliando múltiplos agentes em uma aplicação
O primeiro o passo para lidar com essa complexidade é geralmente capturar com a maior precisão possível um rastreamento da saída do agente (uma história de execução de chamadas de ferramentas, raciocínio e resposta final). Uma combinação de captura automática de rastreamento e instrumentação manual pode fornecer a flexibilidade necessária para cobrir toda a gama de interações do agente. Por exemplo, o decoradortracedo MLflow Traces pode ser usado em qualquer função para capturar suas entradas e saídas. Ao mesmo tempo, spans personalizados do MLflow Traces podem ser criados em blocos de código específicos para registrar operações mais granulares. Somente após usar a instrumentação para agregar uma fonte confiável de verdade a partir das saídas do agente é que os desenvolvedores podem começar a identificar modos de falha e projetar testes de acordo.
- Incorporando feedback humano: É crucial incorporar essa entrada ao avaliar a qualidade. Mas algumas atividades consomem muito tempo. Por exemplo:
- Projetando rubricas para que os anotadores tenham diretrizes a seguir
- Projetando diferentes métricas e juízes para diferentes cenários (por exemplo, uma saída é segura versus uma saída é útil)
Discussões e workshops presenciais são geralmente necessários para criar uma rubrica compartilhada de como se espera que um agente responda. Somente depois que os anotadores humanos estiverem alinhados, suas avaliações poderão ser integradas de forma confiável em juízes baseados em LLM, usando funções como a APImake_judgedo MLflow ou oSIMBAAlignmentOptimizer.
- Desafios não resolvidos: as próprias aplicações de IA generativa estão cada vez mais complexas, mas os frameworks de avaliação e teste ainda não acompanharam esse ritmo. Alguns cenários que tornam os testes desafiadores incluem:
Dívida técnica de IA
A dívida técnica se acumula quando os desenvolvedores implementam uma solução rápida e de baixa qualidade em detrimento da manutenibilidade a longo prazo.
Dívida técnica de ML clássico
Dan Sculley et al. forneceram um ótimo resumo dos tipos de dívida técnica que esses sistemas podem acumular. Em seu artigo “Machine Learning: The High-Interest Credit Card of Technical Debt,” eles dividem isso em três grandes áreas:
- Dívida de dados Dependências de dados mal documentadas, não contabilizadas ou que mudam silenciosamente
- Dívida no nível do sistema Código de cola extensivo, “selvas” de pipelines e caminhos "mortos" codificados
- Mudanças externas Modificação de limites (como o limite de precisão-revocação) ou remoção de correlações anteriormente importantes
A AI generativa introduz novas formas de débito técnico, muitas das quais podem não ser óbvias. Esta seção explora as fontes dessa dívida técnica oculta.
Proliferação de ferramentas
As ferramentas são uma forma poderosa de expandir as capacidades de um LLM. No entanto, à medida que o número de ferramentas utilizadas aumenta, elas podem se tornar difíceis de gerenciar.
A proliferação de ferramentas não apresenta apenas um problema de descoberta e reutilização; também pode afetar negativamente a qualidade de um sistema de IA generativa. Quando as ferramentas proliferam, surgem dois pontos-chave de falha:
- Seleção de ferramenta: O LLM precisa ser capaz de selecionar corretamente a ferramenta certa para chamar a partir de uma ampla variedade de ferramentas. Se as ferramentas fazem coisas aproximadamente semelhantes, como chamar APIs de dados para estatísticas de vendas semanais versus mensais, garantir que a ferramenta certa seja chamada se torna difícil. Os LLMs começarão a cometer erros.
- Parâmetros da ferramenta: mesmo depois de selecionar com sucesso a ferramenta certa a ser chamada, um LLM ainda precisa ser capaz de analisar a pergunta de um usuário no conjunto correto de parâmetros para passar para a ferramenta. Este é outro ponto de falha a ser considerado, e torna-se particularmente difícil quando várias ferramentas têm estruturas de parâmetros semelhantes.
A solução mais limpa para a proliferação de ferramentas é ser estratégico e minimalista com as ferramentas que uma equipe usa.
No entanto, a estratégia de governança correta pode ajudar a tornar o gerenciamento de múltiplas ferramentas e o acesso escaláveis à medida que mais e mais equipes integram a GenAI em seus projetos e sistemas. Os produtos da Databricks, Unity Catalog e AI Gateway, são criados para esse tipo de escala.
Prompt stuffing
Embora os modelos de ponta possam lidar com páginas de instruções, prompts excessivamente complexos podem introduzir problemas como instruções contraditórias ou informações desatualizadas. Isso é especialmente verdade quando os prompts não são editados, mas apenas recebem acréscimos ao longo do tempo por diferentes especialistas de domínio ou desenvolvedores.
À medida que surgem diferentes modos de falha ou novas consultas são adicionadas ao escopo, é tentador continuar adicionando mais e mais instruções a um prompt de LLM. Por exemplo, um prompt pode começar fornecendo instruções para lidar com perguntas relacionadas a finanças e, em seguida, se estender para perguntas relacionadas a produto, engenharia e recursos humanos.
Assim como uma “classe deus” na engenharia de software não é uma boa ideia e deve ser dividida, megaprompts devem ser separados em prompts menores. Na verdade, a Anthropic menciona isso em seu guia de engenharia de prompts e, como regra geral, ter vários prompts menores em vez de um longo e complexo ajuda na clareza, precisão e solução de problemas.
Frameworks podem ajudar a manter os prompts gerenciáveis, acompanhando versões de prompt e aplicando as entradas e saídas esperadas. Um exemplo de ferramenta de versionamento de prompt é o Registro de Prompts do MLflow, enquanto otimizadores de prompt como o DSPy podem ser executados no Databricks para decompor um prompt em módulos autocontidos que podem ser otimizados individualmente ou como um todo.
Pipelines opacos
Há uma razão pela qual o acompanhamento tem recebido atenção ultimamente, com a maioria das bibliotecas de LLM e ferramentas de acompanhamento oferecendo a capacidade de rastrear as entradas e saídas de uma cadeia de LLM. Quando uma resposta retorna um erro — o temido "Sinto muito, não posso responder à sua pergunta" —, examinar as entradas e saídas das chamadas intermediárias do LLM é crucial para identificar a causa raiz.
Uma vez, trabalhei em um aplicativo em que presumi inicialmente que a geração de SQL seria o passo mais problemático do fluxo de trabalho. No entanto, a inspeção dos meus rastreamentos contou uma história diferente: a maior fonte de erros era, na verdade, um passo de reescrita de query em que atualizávamos as entidades na pergunta do usuário para entidades que correspondiam aos valores do nosso banco de dados. O LLM reescrevia queries que não precisavam ser reescritas ou começava a encher a query original com todo tipo de informação extra. Isso regularmente atrapalhava o processo subsequente de geração de SQL. O rastreamento ajudou a identificar rapidamente o problema.
Rastrear as chamadas de LLM corretas pode levar tempo. Não basta implementar o rastreamento pronto para uso. Instrumentar adequadamente um aplicativo com observabilidade, usando um framework como o MLflow Traces, é um primeiro passo para tornar as interações do agente mais transparentes.
Sistemas inadequados para capturar e utilizar o feedback humano
Os LLMs são notáveis porque você pode passar a eles alguns prompts simples, encadear os resultados e obter algo que parece entender nuances e instruções muito bem. Mas ir longe demais nesse caminho sem basear as respostas no feedback do usuário pode acumular rapidamente a dívida de qualidade. É aqui que criar um “volante de dados” o mais rápido possível pode ajudar, o que consiste em três os passos:
- Decidir sobre as métricas de sucesso
- Automatizar como você mede essas métricas, talvez por meio de uma UI que os usuários possam usar para dar feedback sobre o que está funcionando
- Ajustar iterativamente prompts ou pipelines para melhorar as métricas
Fui lembrado da importância do feedback humano ao desenvolver um aplicativo de texto para SQL para queryar estatísticas esportivas. O especialista no domínio conseguiu explicar como um fã de esportes gostaria de interagir com os dados, esclarecendo com o que eles se importariam e fornecendo outras percepções que eu, como alguém que raramente assiste a esportes, nunca teria conseguido pensar. Sem a contribuição deles, o aplicativo que criei provavelmente não teria atendido às necessidades dos usuários.
Embora capturar o feedback humano seja inestimável, geralmente é um processo extremamente demorado. Primeiro, é preciso programar um horário com especialistas do domínio, depois criar rubricas para reconciliar as diferenças entre os especialistas e, em seguida, avaliar o feedback para melhorias. Se a UI de feedback estiver hospedada em um ambiente ao qual os usuários de negócios não têm acesso, o alinhamento com os administradores de TI para fornecer o nível de acesso correto pode parecer um processo interminável.
Construir sem verificações regulares com as partes interessadas
Consultar regularmente os usuários finais, patrocinadores de negócios e equipes adjacentes para ver se você está construindo a coisa certa é o mínimo em todos os tipos de projetos. No entanto, em projetos de IA generativa, a comunicação com as partes interessadas é mais crucial do que nunca.
Por que a comunicação frequente e de alto contato é importante:
- Propriedade e controle: reuniões regulares ajudam as partes interessadas a sentir que têm uma maneira de influenciar a qualidade final de uma aplicação. Em vez de serem críticos, eles podem se tornar colaboradores. Claro, nem todo feedback tem o mesmo valor. Algumas partes interessadas inevitavelmente começarão a solicitar coisas que são prematuras para implementar em um MVP ou que estão fora do que os LLMs podem lidar atualmente. É importante negociar e educar a todos sobre o que pode e o que não pode ser alcançado. Caso contrário, outro risco pode surgir: muitas solicitações de recursos sem nenhum freio.
- Não sabemos o que não sabemos: a IA generativa é tão nova que a maioria das pessoas, tanto técnicas quanto não técnicas, não sabe com o que um LLM pode e não pode lidar adequadamente. Desenvolver um aplicativo de LLM é uma jornada de aprendizado para todos os envolvidos, e pontos de contato regulares são uma forma de manter todos informados.
Existem muitas outras formas de dívida técnica que podem precisar ser abordadas em projetos de IA generativa, incluindo a aplicação de controles de acesso a dados adequados, a implementação de proteções para gerenciar a segurança e prevenir injeções de prompt, evitar que os custos saiam do controle e muito mais. Incluí apenas as que me pareceram mais importantes aqui e que poderiam ser facilmente esquecidas.
Conclusão
O ML clássico e a IA generativa são sabores diferentes do mesmo domínio técnico. Embora seja importante estar ciente das diferenças entre eles e considerar o impacto dessas diferenças em como construímos e mantemos nossas soluções, certas verdades permanecem constantes: a comunicação ainda preenche lacunas, o monitoramento ainda previne catástrofes e sistemas limpos e de fácil manutenção ainda superam os caóticos a longo prazo.
Quer avaliar a maturidade em IA da sua organização? Leia nosso guia: Desbloqueie o valor da IA: o guia empresarial para a prontidão em IA.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.