Como Criar Detecção de Fraudes em Tempo Real usando o Modo em Tempo Real do Spark e Lakebase
Modernizando Ecossistemas Financeiros com Latência de Sub-Segundo e Inteligência de Dados Escalável
por Sixuan He e Navneeth Nair
- Sistemas tradicionais de detecção de fraudes têm dificuldade com o atraso na detecção, dependendo de processamento em lote lento ou motores de streaming complexos e adicionados que falham em bloquear ameaças em tempo real.
- O Modo de Tempo Real do Spark e o Lakebase permitem que as equipes de dados criem e automatizem facilmente um fluxo de trabalho de detecção de fraudes de ponta a ponta: processando fluxos de dados de alta vazão, executando modelos de ML de baixa latência e fornecendo pontuações de fraude explicáveis, tudo dentro de uma plataforma unificada.
- As organizações podem alcançar intervenção em sub-segundo em transações fraudulentas, reduzindo a complexidade operacional enquanto protegem a receita e mantêm a confiança do cliente sem a necessidade de infraestrutura externa.
A fraude com cartões opera em segundos. Um número de cartão de crédito roubado pode alimentar dezenas de compras em minutos e, uma vez que uma transação é liquidada, recuperar esses fundos se torna exponencialmente mais difícil. De acordo com o Nilson Report, as instituições financeiras perdem cerca de US$ 33 bilhões anualmente para transações fraudulentas com cartões, e esse número só aumentará à medida que o volume de transações digitais acelera.
O desafio não é detectar a fraude. A maioria das organizações já possui modelos de fraude capazes e regras bem ajustadas. O desafio é detectá-la rápido o suficiente para bloquear uma transação suspeita antes que ela seja liquidada, na janela de sub-segundo entre a autorização e a liquidação, e fazer isso sem adicionar um motor de streaming separado e especializado que dobra sua complexidade operacional.
Neste blog, apresentamos um novo Acelerador de Soluções: uma implementação de referência de código aberto que você pode clonar e implantar diretamente em seu ambiente Databricks. Ele demonstra como construir um sistema completo de detecção de fraudes de ponta a ponta, desde a ingestão de transações brutas e pontuação de ML em tempo real até um painel de monitoramento ao vivo construído com Databricks Apps, inteiramente na Plataforma Databricks. Em seu núcleo estão duas tecnologias: Real-Time Mode (RTM) para Apache Spark Structured Streaming no Databricks, que oferece processamento de streaming de sub-300ms, e Lakebase, um banco de dados Postgres totalmente gerenciado e sem servidor, integrado à Plataforma Databricks.
Velocidade vs. Simplicidade: O Trade-off em Tempo Real para Detecção de Fraudes
A detecção de fraudes fica na intersecção de duas demandas conflitantes.
De um lado, há a velocidade. Uma transação fraudulenta deve ser identificada e bloqueada em centenas de milissegundos antes de ser liquidada. Anéis de fraude sofisticados testam cartões roubados com microcompras rápidas, exploram anomalias geográficas e adaptam seus padrões mais rápido do que regras estáticas podem acompanhar.
Do outro lado, há a simplicidade. As equipes de dados querem construir, treinar e implantar modelos de fraude em uma única plataforma, com governança unificada, dados compartilhados e um conjunto de ferramentas. Elas não querem manter uma pilha de streaming separada apenas para a "última milha" de pontuação em tempo real.
Até agora, as equipes foram forçadas a escolher. Historicamente, atender a esses requisitos de latência ultrabaixa significava introduzir um motor especializado ao lado do Spark, como o Apache Flink. O resultado é um padrão familiar: dois sistemas paralelos, dados duplicados, governança dividida e equipes de engenharia gastando mais tempo gerenciando pipelines em vez de melhorar os modelos de fraude. Com a introdução do RTM no Spark Structured Streaming, esse trade-off não é mais necessário.
RTM: Processamento de Sub-segundo Sem o Overhead Operacional de Múltiplos Sistemas
RTM é uma evolução do motor Spark Structured Streaming que permite o processamento de dados em sub-segundo para aplicações operacionais sensíveis à latência, como engenharia de features.
No lado da velocidade, o RTM processa eventos em milissegundos e é até 92% mais rápido que o Apache Flink em cargas de trabalho de transformação stateless, enriquecimento baseado em join e agregação. Clientes como a Coinbase já estão usando o RTM para computar mais de 250 features de ML e alcançaram latências de processamento P99 abaixo de 100ms.
No lado da simplicidade, o RTM vive dentro do motor Spark que você já executa, não ao lado dele. Portanto, você se beneficiará imediatamente de:
- Sem desvio de lógica. Suas regras de pontuação de fraude, engenharia de features e pré-processamento de ML existem uma vez. O mesmo código que roda em seu pipeline de treinamento offline roda em seu ambiente de pontuação em tempo real. Isso permite que você produza features mais rapidamente e com maior precisão.
- Uma superfície operacional. Spark UI, monitoramento de cluster, jobs, alertas, etc. Todas as ferramentas que você já usa se aplicam. Não há uma segunda rotação de plantão para o motor de streaming.
- Flexibilidade de custo vs. atualidade. Quando a atualidade de sub-segundo não vale o custo, voltar para um trigger mais lento é a mesma mudança de código de uma linha na outra direção. Não é necessário gastar tempo ajustando manualmente o paralelismo ou orquestrando o desligamento e reinício de recursos de computação.
Como resultado, a equipe não precisa mais escolher; você obtém tanto a velocidade quanto a simplicidade, e as horas de engenharia voltam para ajustar sinais de fraude em vez de gerenciar infraestrutura.
Exemplo de cenário: Bloqueando fraudes em transações de cartão de crédito
Para tornar isso concreto, nosso Acelerador de Soluções implementa um sistema de detecção de fraudes em tempo real para transações de cartão de crédito. Aqui está o cenário:
As transações chegam de um sistema de mensagens (Kafka, Kinesis, etc.). Cada transação carrega um ID de cartão, valor, categoria de comerciante, coordenadas geográficas e canal (online vs. ponto de venda). O sistema deve avaliar cada transação contra múltiplos sinais de fraude, atribuir uma pontuação de risco e roteá-la para o resultado apropriado — aprovado, marcado para revisão ou bloqueado — tudo dentro de sub-300ms.
A arquitetura espelha como são os sistemas de fraude em produção em grandes instituições financeiras, com rastreamento stateful, enriquecimento de features do Lakebase como uma camada de serviço online, pontuação de ML e um Databricks Apps ao vivo para monitoramento por analistas de fraude. A diferença é que ele roda inteiramente em uma plataforma.
Como Construímos
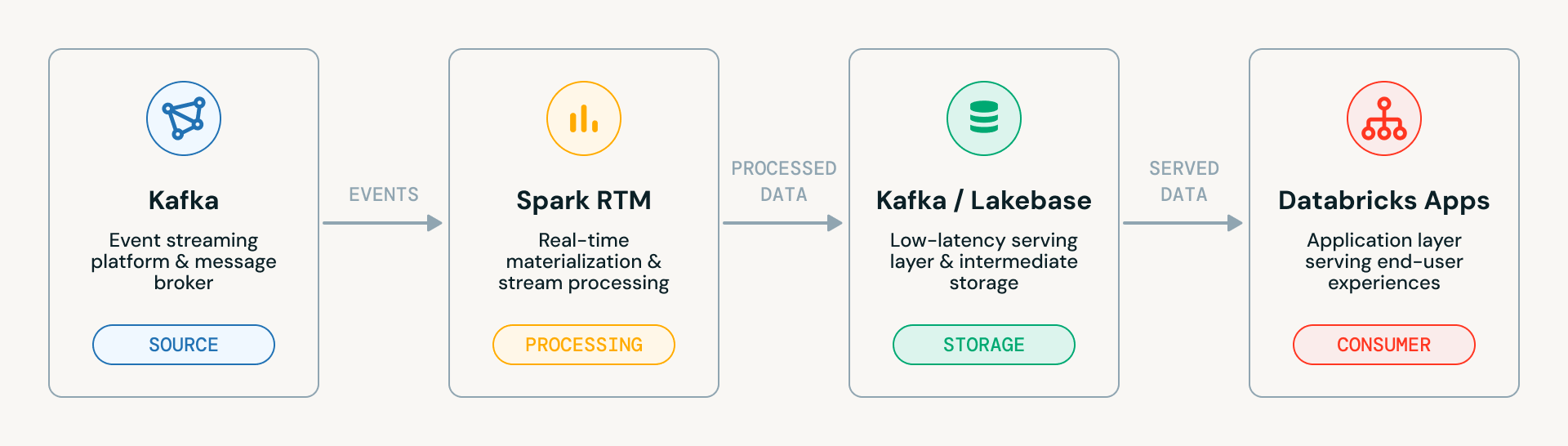
O acelerador passa por quatro estágios progressivos, cada um construindo sobre o anterior. Aqui está o diagrama de arquitetura de sistema de alto nível. Ele mostra o fluxo de dados limpo através dos quatro componentes principais:
- Kafka (Origem): A plataforma de streaming de eventos que ingere eventos brutos
- Spark RTM: O motor de materialização em tempo real que processa os dados de streaming
- Kafka / Lakebase: A camada intermediária onde os dados processados chegam, seja de volta ao Kafka ou ao Lakebase (camada de serviço de baixa latência do Databricks)
- Databricks Apps: A camada de aplicação que serve os dados finais aos usuários finais
Confira o vídeo completo da demonstração de ponta a ponta abaixo, ou continue lendo o passo a passo para aprender exatamente como construímos. Comece com o Quick Start abaixo (sem dependências externas) e adicione complexidade conforme avança.
Passo 1: Veja o Real-Time Mode em Ação
Para instituições financeiras que avaliam infraestrutura de fraude em tempo real, o rápido tempo de valor é crítico. O notebook Quick Start permite que sua equipe experimente o Real-Time Mode imediatamente e valide benchmarks de latência centrais e o ajuste da plataforma em menos de cinco minutos, antes de qualquer compromisso de produção. Não é necessário conectar ao Kafka ou configurar nada externo. Ele gera transações sintéticas usando a fonte de taxa integrada do Spark, aplica a lógica de pontuação de fraude e exibe os resultados ao vivo no notebook. Este é o seu "olá mundo" para o Real-Time Mode. Execute-o, veja os números de latência e valide se seu cluster está configurado corretamente.
Passo 2: Construa o Pipeline de Detecção de Fraudes
Com o Real-Time Mode validado, o próximo notebook constrói um pipeline de detecção de fraudes de nível de produção que espelha como as principais FSIs operacionalizam a tomada de decisão de fraude em tempo real. Ele processa transações de ponta a ponta, entregando a pontuação explicável exigida pelas equipes de operações de fraude e conformidade. As transações fluem do Kafka através de cinco estágios, cada um rodando continuamente, cada um adicionando inteligência:
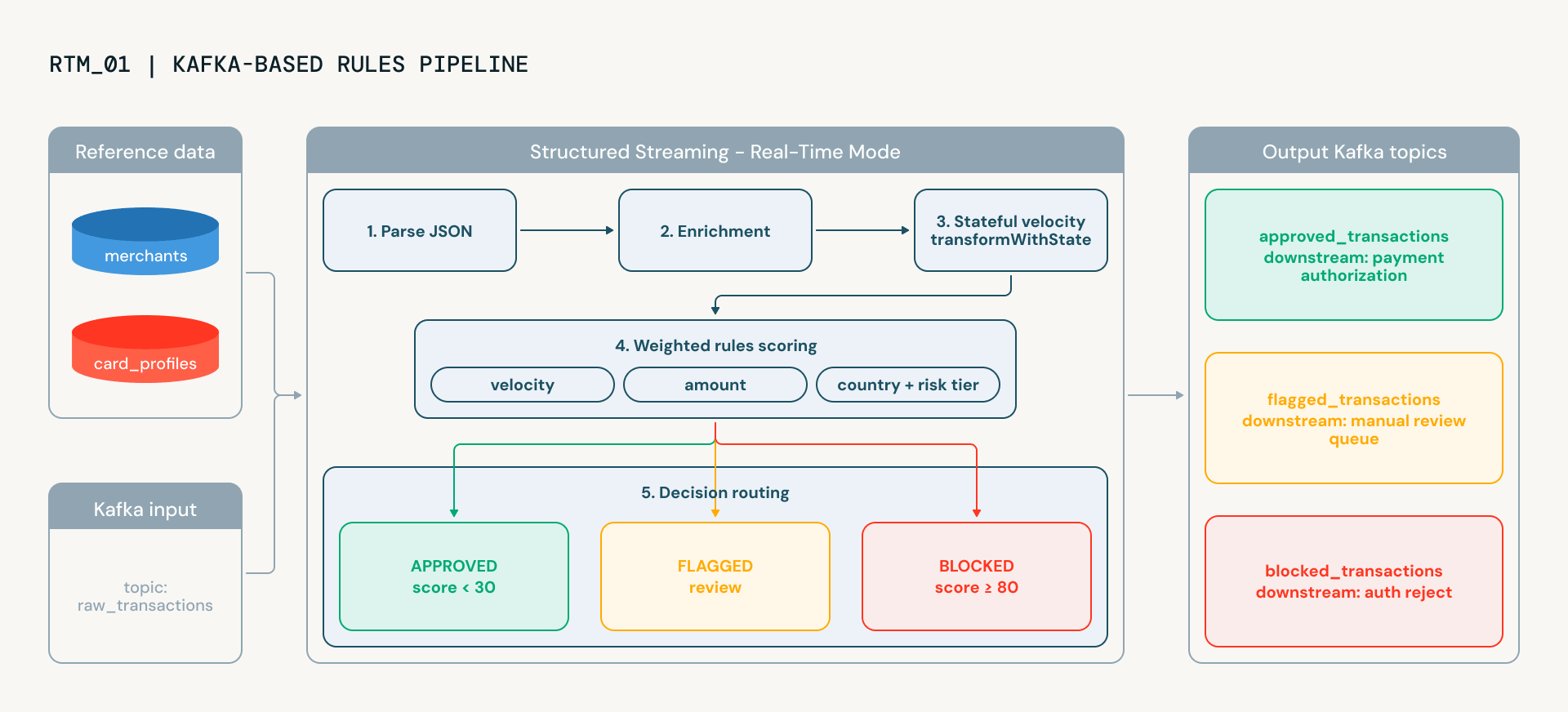
- Análise pega dados brutos JSON do Kafka e os estrutura em colunas tipadas
- Rastreamento de velocidade é onde as coisas ficam interessantes. Usando transformWithState (o poderoso operador do Spark para construir transformações arbitrárias ou personalizadas com estado), o pipeline mantém o estado por cartão em todo o stream: quantas transações este cartão fez nos últimos 60 segundos? Um cartão que dispara repentinamente cinco transações em um minuto está exibindo comportamento clássico de teste de cartão. O estado expira automaticamente via TTL, portanto, não há crescimento de memória ilimitado nem limpeza manual.
- Enriquecimento adiciona contexto de perfis de risco de comerciantes e dados de portadores de cartão. Esta é uma categoria de comerciante de alto risco (cartões-presente, joias)? O portador do cartão normalmente gasta US$ 50 ou US$ 5.000? Essas consultas usam dicionários Python em vez de broadcast joins, evitando a sobrecarga do BroadcastExchange que pode adicionar latência em pipelines de streaming.
- Pontuação combina cinco sinais de fraude ponderados: velocidade, anomalia geográfica, desvio de valor, risco da categoria do comerciante e risco do país, em uma única pontuação de 0 a 100. Cada sinal é computado por um UDF dedicado, e os pesos são configuráveis. O resultado é uma pontuação *explicável*: você pode ver exatamente quais sinais contribuíram e em que medida.
- Roteamento toma a decisão final. As transações são classificadas como aprovadas, sinalizadas para revisão manual ou bloqueadas automaticamente, e gravadas no tópico de saída Kafka apropriado.
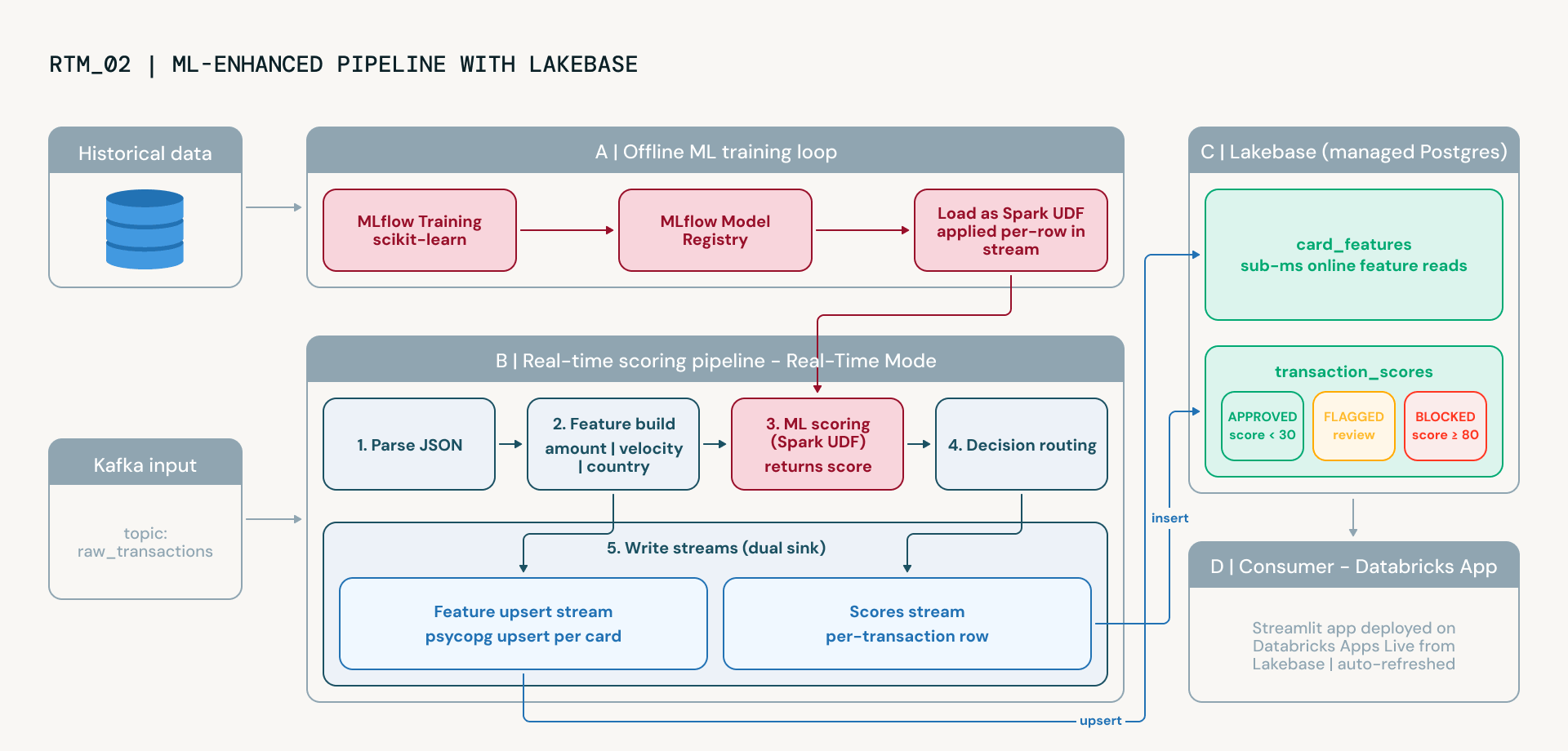
- Lakebase como camada de serviço online. Lakebase é o serviço PostgreSQL gerenciado da Databricks. Usando o sink foreach do Spark Structured Streaming com um LakebaseFeatureWriter personalizado, o pipeline transmite continuamente recursos por cartão, padrões de velocidade, valores médios de transação, dispersão geográfica, tudo diretamente em tabelas Lakebase com semântica de upsert. O Lakebase fornece leituras de sub-milissegundos, tornando-o ideal para o serviço de recursos em tempo real sem gerenciar infraestrutura externa.
- MLflow para treinamento e serviço de modelos. Um classificador RandomForest é treinado em dados históricos rotulados usando MLflow para rastreamento de experimentos e versionamento de modelos. O modelo treinado é carregado como um Spark UDF e aplicado a cada transação no pipeline de streaming. Combinado com recursos ao vivo do Lakebase, o modelo aprende relações não lineares entre sinais que as regras estáticas perdem e melhora ao longo do tempo à medida que novos dados rotulados se tornam disponíveis.
- Início Rápido: Clone o repositório, abra `notebooks/RTM_00_Quick_Start.py` e execute-o em um cluster configurado para executar o modo em tempo real. Você verá o RTM processando transações sintéticas com latência de sub-300ms — sem Kafka, sem configuração externa necessária.
- Pipeline completo: Configure um escopo de segredo Kafka com os endereços do seu broker, em seguida, execute `notebooks/RTM_01_Introduction_fraud_detection.py`. Isso fornece o pipeline completo de análise-enriquecimento-pontuação-roteamento lendo e gravando no Kafka. Ao executar, você verá transações fluindo por todas as cinco etapas e decisões chegando ao tópico de saída aprovado, sinalizado e bloqueado. Isso fornece o pipeline completo de análise-enriquecimento-pontuação-roteamento lendo e gravando no Kafka.
- Pontuação com IA: Crie uma instância Lakebase e, em seguida, execute `notebooks/RTM_02_Advanced_fraud_detection_ml.py`. Isso adiciona streaming de recursos ao Lakebase, treinamento de modelo com MLflow e pontuação baseada em IA no pipeline. Ao concluir, o MLflow registrará o modelo treinado e o pipeline começará a emitir pontuações de fraude derivadas de IA em vez dos pesos baseados em regras.
- Aplicativo de monitoramento ao vivo: Implante o aplicativo Streamlit de `apps/` como um Databricks Apps com uma vinculação de recurso Lakebase. O aplicativo se conecta automaticamente e começa a exibir pontuações de fraude ao vivo.
- Obtenha o Acelerador de Soluções no GitHub
- Documentação do Modo em Tempo Real
- Anúncio de Disponibilidade Geral do Modo em Tempo Real
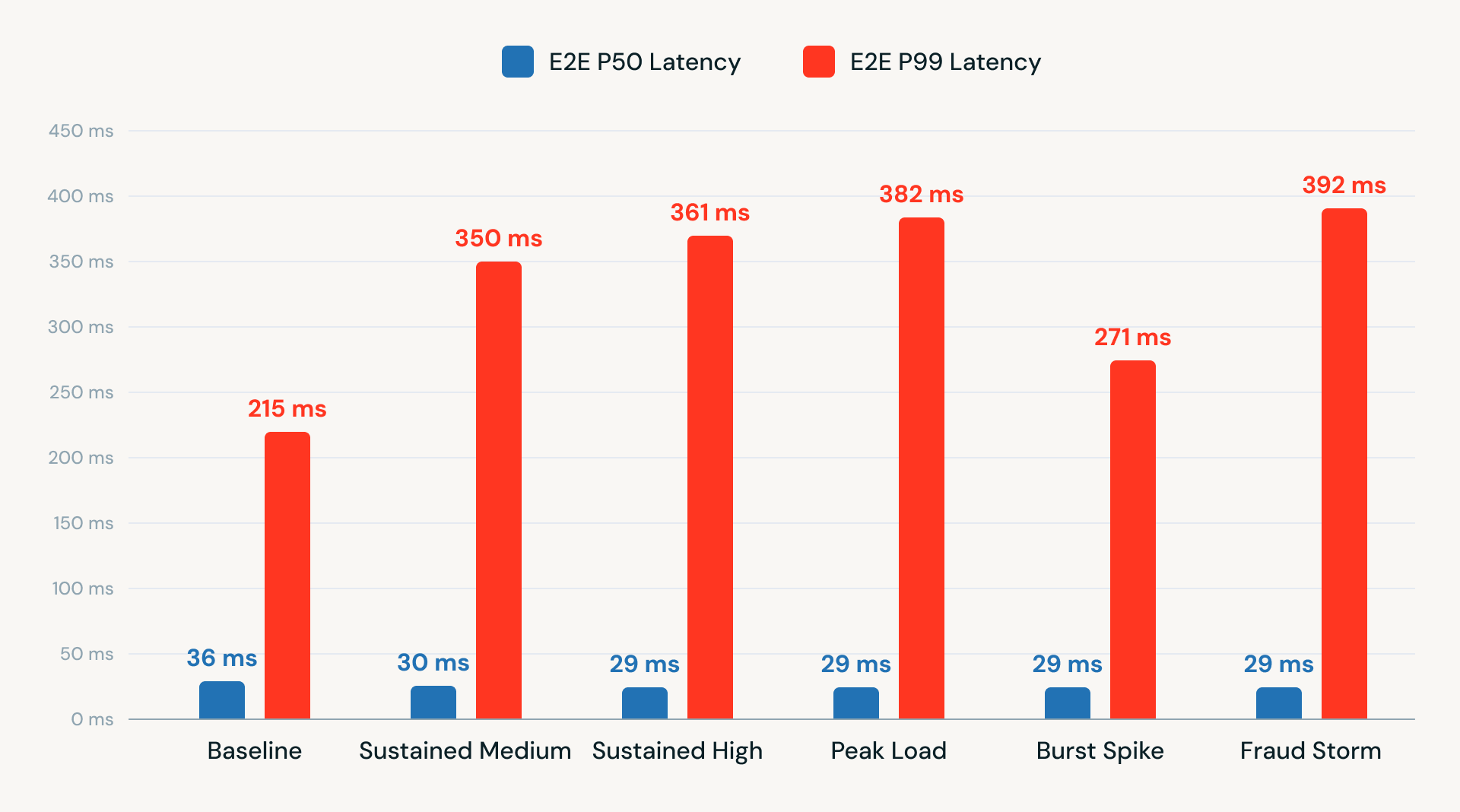
Também realizamos testes de latência de ponta a ponta em vários níveis de TPS. Os resultados mostraram desempenho consistente, com latência P50 abaixo de 40 ms e latência P99 variando entre 215-392 ms. Esses resultados demonstram que uma arquitetura Kafka-in, Kafka-out usando RTM na Databricks Platform pode oferecer desempenho de baixa latência e pronto para produção sem depender de APIs externas ou infraestrutura adicional.
Etapa 3: Atualizar para Machine Learning
A detecção de fraude baseada em regras estáticas cria sistemas auditáveis, mas frágeis. Os limites são arbitrários: por que cinco transações em 60 segundos são "suspeitas"? Por que não quatro ou seis? E como n�ão há aprendizado, o sistema nunca melhora a partir de decisões passadas.
O notebook avançado atualiza essa lógica para um modelo de machine learning governado. Essa transição permite que as equipes de risco reduzam falsos positivos, se adaptem a padrões de fraude emergentes e demonstrem linhagem de modelo aos reguladores por meio do rastreamento de experimentos e versionamento integrados do MLflow. Isso introduz dois novos recursos da plataforma:
Etapa 4: Monitorar Tudo em Tempo Real
A visibilidade operacional é inegociável para equipes de fraude que trabalham sob obrigações de relatórios regulatórios em tempo real. Para tornar o sistema observável, o acelerador inclui um Databricks Apps baseado em Streamlit que lê diretamente do Lakebase para fornecer um painel de monitoramento de fraude ao vivo. Isso oferece a analistas de fraude e gerentes de risco uma visão ao vivo e auditável de cada decisão que o sistema toma, sem exigir suporte de engenharia para acessá-la. Os usuários podem rastrear transações totais pontuadas, detalhamento de decisões (aprovadas, sinalizadas, bloqueadas), pontuações de fraude recentes com detalhes por cartão e distribuições de probabilidade de fraude, tudo atualizando automaticamente a cada 10 segundos. Esta é a camada operacional que torna o sistema utilizável na prática, não apenas tecnicamente funcional.
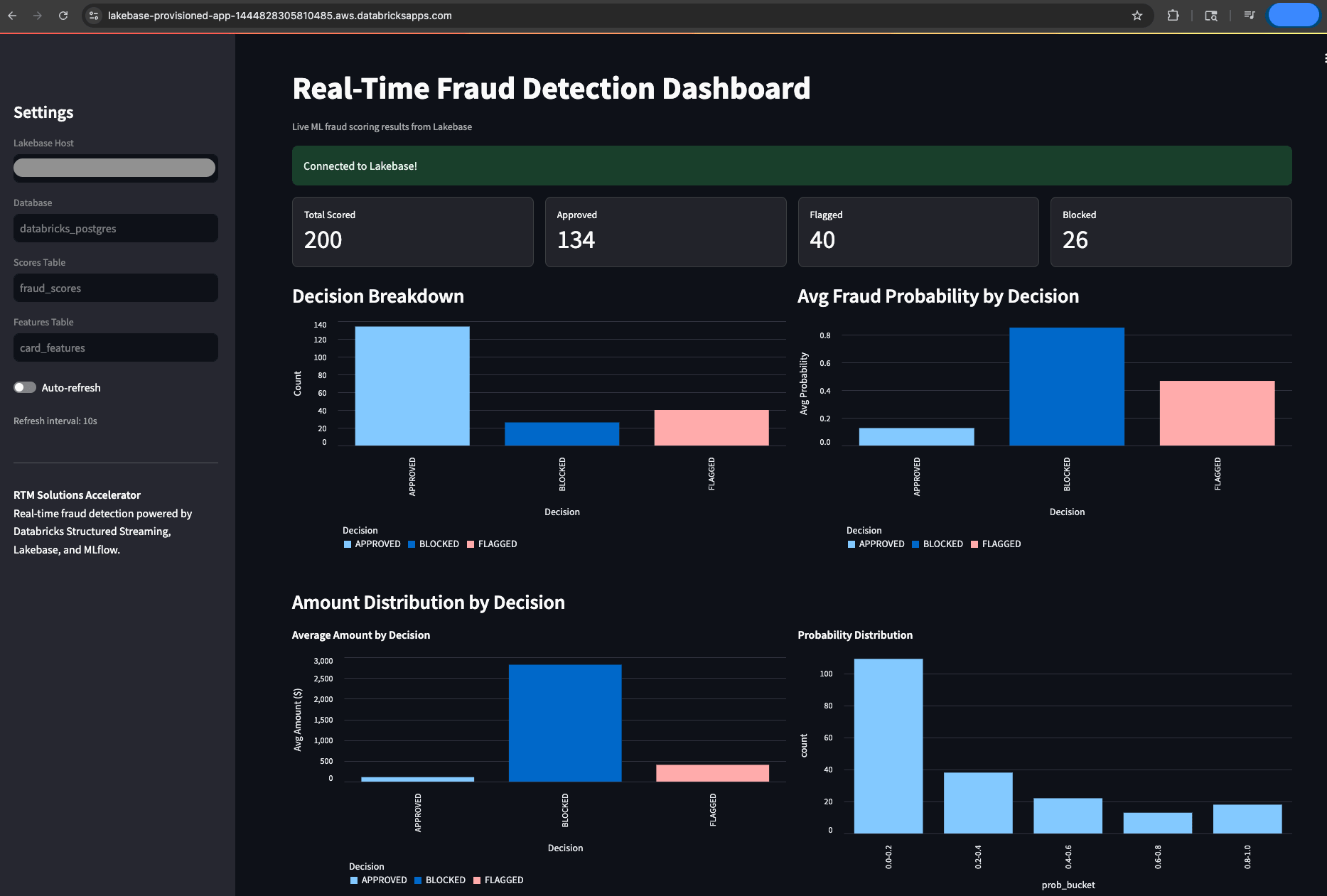
O principal insight é que tudo roda em uma única plataforma. O mesmo motor Spark que impulsiona seu ETL em lote e treinamento de ML agora lida com streaming de sub-300ms. O Unity Catalog agora governa tanto suas tabelas de streaming quanto seus dados de treinamento. O MLflow agora rastreia seus modelos de fraude, quer sejam usados em inferência em lote ou pontuação em tempo real. Não há lacuna de integração, divisão de governança ou segunda pilha para manter, porque tudo está na mesma plataforma.
Começando
Este Acelerador de Soluções foi projetado para ser progressivamente adaptável: comece de forma simples e adicione complexidade, se necessário.
O caminho mais rápido é com Databricks Asset Bundles — basta clonar, implantar e executar:
O bundle provisiona automaticamente um cluster configurado corretamente e executa todos os notebooks em sequência.
Saiba mais sobre o Modo em Tempo Real
O Modo em Tempo Real está em Disponibilidade Geral no Databricks em AWS, Azure e GCP. O acelerador de soluções de detecção de fraude é de código aberto e está pronto para implantação.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.