How to Build Real-Time Fraud Detection using Spark Real-Time Mode and Lakebase
Modernizing Financial Ecosystems with Sub-Second Latency and Scalable Data Intelligence
by Sixuan He and Navneeth Nair
- Traditional fraud detection systems struggle with detection lag, relying on slow batch processing or complex, bolted-on streaming engines that fail to block threats in real-time.
- Spark Real-Time Mode and Lakebase enable data teams to easily build and automate an end-to-end fraud detection workflow: processing high-throughput data streams, executing low-latency ML models, and serving explainable fraud scores, all within a unified platform.
- Organizations can achieve sub-second intervention on fraudulent transactions, reducing operational complexity while protecting revenue and maintaining customer trust without the need for external infrastructure.
Card fraud operates in seconds. A stolen credit card number can fuel dozens of purchases in minutes, and once a transaction settles, recovering those funds becomes exponentially harder. According to the Nilson Report, financial institutions lose an estimated $33 billion annually to fraudulent card transactions, and that figure will only grow as digital transaction volume accelerates.
The challenge isn't detecting fraud. Most organizations already have capable fraud models and well-tuned rules. The challenge is detecting it fast enough to block a suspicious transaction before it clears, in the sub-second window between authorization and settlement, and doing that without bolting on a separate, specialized streaming engine that doubles your operational complexity.
In this blog, we introduce a new Solution Accelerator: an open source reference implementation you can clone and deploy directly into your Databricks environment. It demonstrates how to build a complete, end-to-end fraud detection system, from raw transaction ingestion and real-time ML scoring to a live monitoring dashboard built with Databricks Apps, entirely on the Databricks Platform. At its core are two technologies: Real-Time Mode (RTM) for Apache Spark Structured Streaming on Databricks that delivers sub-300ms stream processing, and Lakebase, a fully managed, serverless, Postgres database built into the Databricks Platform.
Speed vs. Simplicity: The Real-time Tradeoff for Fraud Detection
Fraud detection sits at the intersection of two conflicting demands.
On one side, there's speed. A fraudulent transaction must be identified and blocked within hundreds of milliseconds before it settles. Sophisticated fraud rings test stolen cards with rapid-fire micro-purchases, exploit geographic anomalies, and adapt their patterns faster than static rules can keep up.
On the other side, there's simplicity. Data teams want to build, train, and deploy fraud models on a single platform, with unified governance, shared data, and one set of tools. They don't want to maintain a separate streaming stack just for the "last mile" of real-time scoring.
Until now, teams have been forced to choose. Historically, meeting these ultra-low latency requirements meant introducing a specialized engine alongside Spark, such as Apache Flink. The result is a familiar pattern: two parallel systems, duplicate data, split governance, and engineering teams spending more time on managing pipelines instead of improving fraud models. With the introduction of RTM in Spark Structured Streaming, that tradeoff is no longer necessary.
RTM: Sub-Second Processing Without the Operational Overhead of Multiple Systems
RTM is an evolution of the Spark Structured Streaming engine that enables sub-second data processing for latency-sensitive operational applications such as feature engineering.
On the speed side, RTM processes events in milliseconds and is up to 92% faster than Apache Flink across stateless transformation, join-based enrichment, and aggregation workloads. Customers such as Coinbase are already using RTM to compute over 250 ML features, and have achieved sub-100ms P99 processing latencies.
On the simplicity side, RTM lives inside the Spark engine you already run, not next to it. Therefore, you will immediately benefit from:
- No logic drift. Your fraud scoring rules, feature engineering, and ML preprocessing exist once. The same code that runs in your offline training pipeline runs in your real-time scoring environment. This enables you to productionize features faster and with greater accuracy.
- One operational surface. Spark UI, cluster monitoring, jobs, alerting, etc. All the tooling you already use applies. There's no second on-call rotation for the streaming engine.
- Flexibility on cost vs. freshness. When sub-second freshness isn't worth the cost, switching back to a slower trigger is the same one-line code change in the other direction. No need to spend time manually tuning parallelism or orchestrating the shutdown and restart of computing resources.
As a result, the team no longer needs to choose; you get both the speed and the simplicity, and engineering hours go back to tuning fraud signals rather than managing infrastructure.
Example scenario: Blocking fraud in credit card transactions
To make this concrete, our Solution Accelerator implements a real-time fraud detection system for credit card transactions. Here's the scenario:
Transactions stream in from a messaging system (Kafka, Kinesis, etc.). Each transaction carries a card ID, amount, merchant category, geographic coordinates, and channel (online vs. point-of-sale). The system must evaluate every transaction against multiple fraud signals, assign a risk score, and route it to the appropriate outcome — approved, flagged for review, or blocked — all within sub-300ms.
The architecture mirrors what production fraud systems look like at major financial institutions, with stateful tracking, feature enrichment from Lakebase as an online serving layer, ML scoring, and a live Databricks Apps for fraud analyst monitoring. The difference is that it runs entirely on one platform.
How We Built It
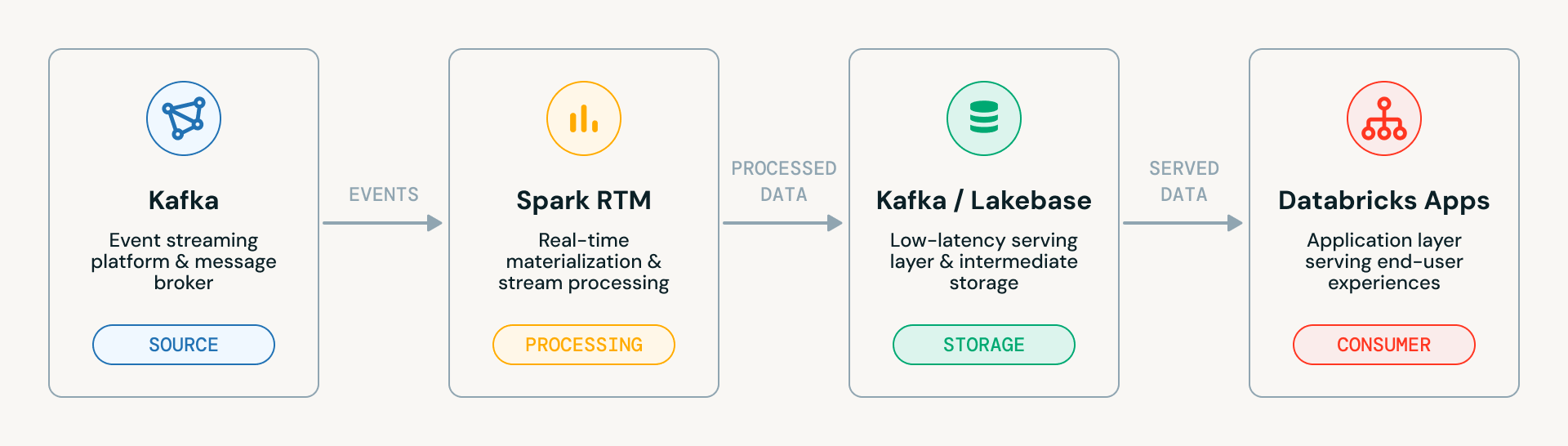
The accelerator goes through four progressive stages, each building on the last. Here's the high-level system architecture diagram. It shows the clean data flow across the four main components:
- Kafka (Source): The event streaming platform that ingests raw events
- Spark RTM: The real-time materialization engine that processes the streaming data
- Kafka / Lakebase: The intermediate layer where processed data lands, either back into Kafka or into Lakebase (Databricks’ low-latency serving layer)
- Databricks Apps: The application layer that serves the final data to end users
Check out the full end-to-end demo video below, or continue reading the step-by-step to learn exactly how we built it. Start with the Quick Start below (no external dependencies) and add complexity as you go.
Step 1: See Real-Time Mode in Action
For financial institutions evaluating real-time fraud infrastructure, rapid time-to-value is critical. The Quick Start notebook lets your team experience Real-Time Mode immediately, and validate core latency benchmarks and platform fit in under five minutes. before any production commitment No connecting to Kafka or configuring anything external is needed. It generates synthetic transactions using Spark's built-in rate source, applies fraud scoring logic, and displays results live in the notebook. This is your "hello world" for Real-Time Mode. Run it, see the latency numbers, and validate that your cluster is configured correctly.
Step 2: Build the Fraud Detection Pipeline
With Real-Time Mode validated, the next notebook builds a production-grade fraud detection pipeline that mirrors how leading FSIs operationalize real-time fraud decisioning. It processes transactions end-to-end, delivering the explainable scoring required by both fraud ops and compliance teams. Transactions flow from Kafka through five stages, each running continuously, each adding intelligence:
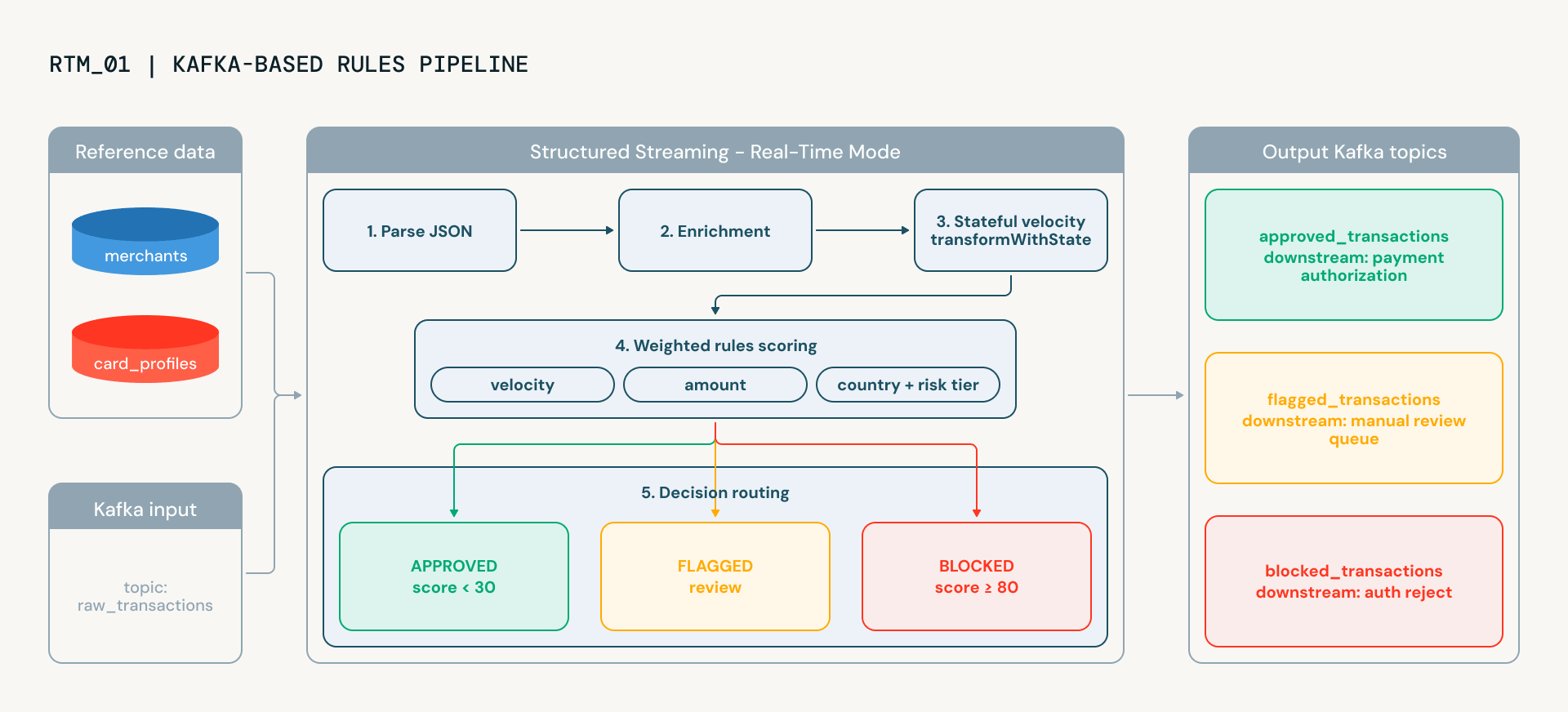
- Parsing takes raw JSON from Kafka and structures it into typed columns
- Velocity tracking is where things get interesting. Using transformWithState (Spark's powerful operator for building arbitrary or custom stateful transformations), the pipeline maintains per-card state across the stream: how many transactions has this card made in the last 60 seconds? A card that suddenly fires five transactions in a minute is exhibiting classic card-testing behavior. The state auto-expires via TTL, so there's no unbounded memory growth and no manual cleanup.
- Enrichment adds context from merchant risk profiles and cardholder data. Is this a high-risk merchant category (gift cards, jewelry)? Does the cardholder normally spend $50 or $5,000? These lookups use Python dictionaries rather than broadcast joins, avoiding the BroadcastExchange overhead that can add latency in streaming pipelines.
- Scoring combines five weighted fraud signals: velocity, geographic anomaly, amount deviation, merchant category risk, and country risk, into a single 0-100 score. Each signal is computed by a dedicated UDF, and the weights are configurable. The result is an explainable score: you can see exactly which signals contributed and by how much.
- Routing takes the final decision. Transactions are classified as approved, flagged for manual review, or automatically blocked, and written to the appropriate output Kafka topic.
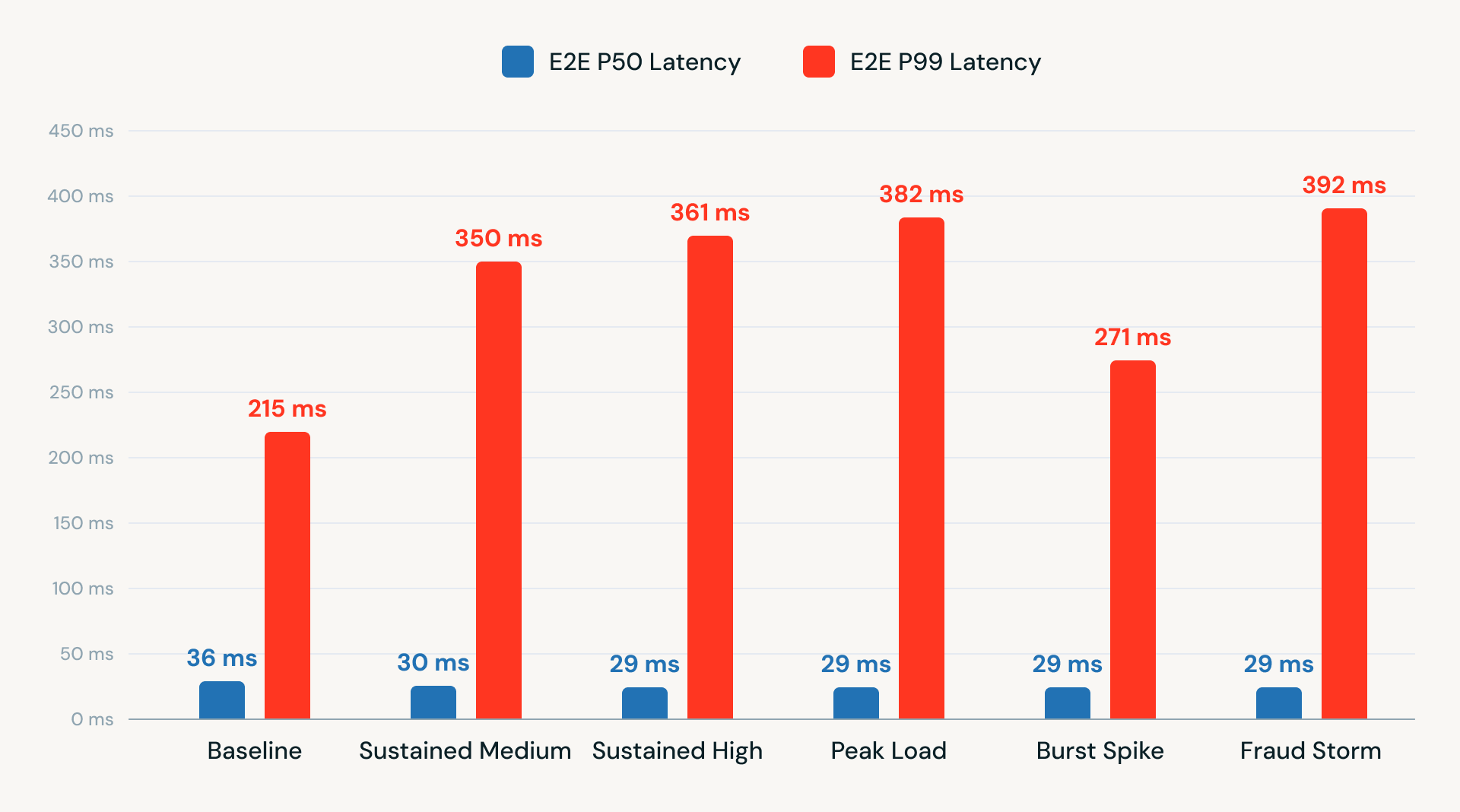
We also conducted end-to-end latency testing across varying TPS levels. The results showed consistent performance, with P50 latency under 40 ms and P99 latency ranging between 215-392 ms. These results demonstrate that a Kafka-in, Kafka-out architecture using RTM on the Databricks Platform can deliver low-latency, production-ready performance without relying on external APIs or additional infrastructure.
Step 3: Upgrade to Machine Learning
Static rules-based fraud detection creates audit-friendly but brittle systems. Thresholds are arbitrary: why are five transactions in 60 seconds "suspicious"? Why not four or six? And because there is no learning, the system never improves from past decisions.
The advanced notebook upgrades this logic to a governed machine learning model. This transition allows risk teams to reduce false positives, adapt to emerging fraud patterns, and demonstrate model lineage to regulators through MLflow's built-in experiment tracking and versioning. This introduces two new platform capabilities:
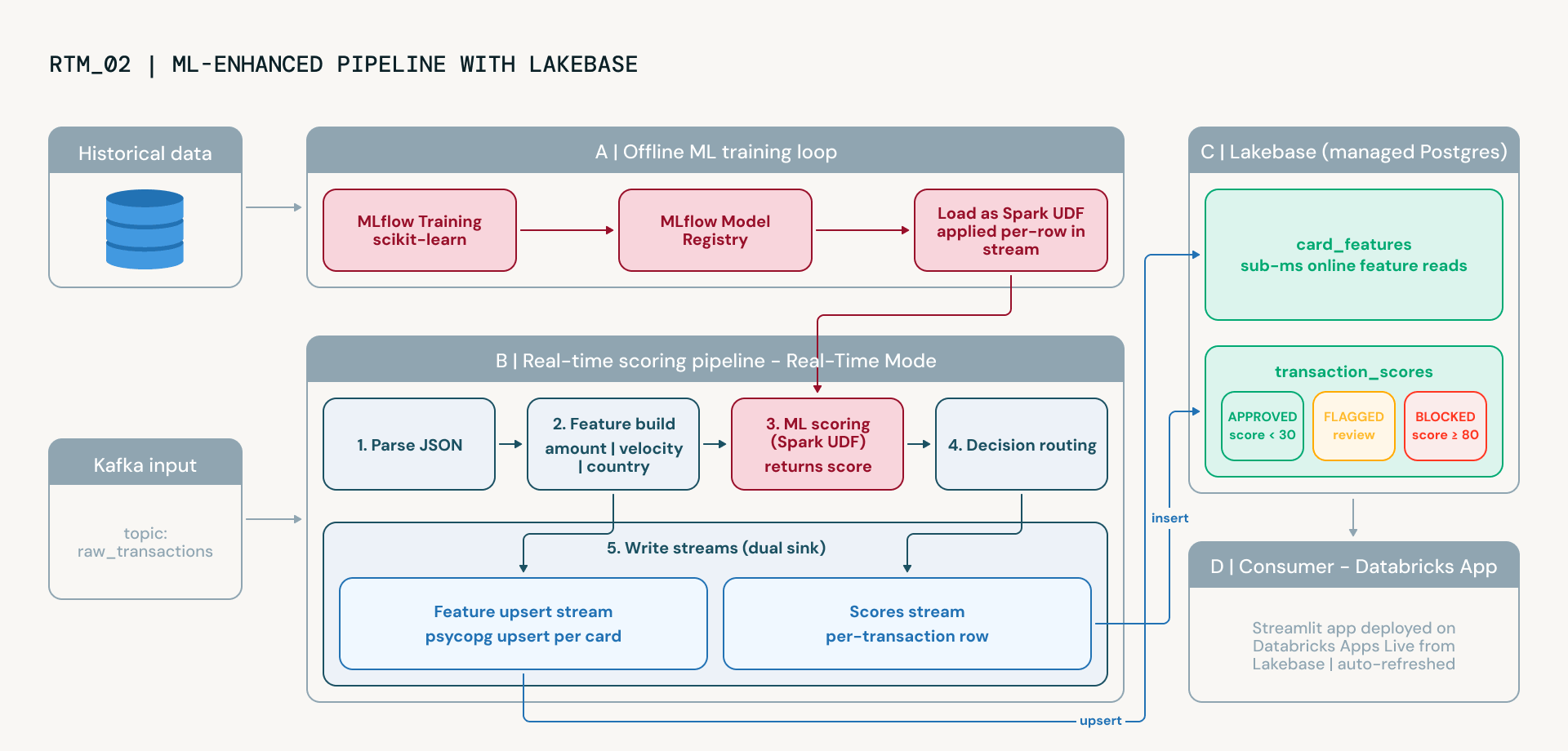
- Lakebase as an online serving layer. Lakebase is Databricks' managed PostgreSQL service. Using Spark Structured Streaming’s foreach sink with a custom LakebaseFeatureWriter, the pipeline continuously streams per-card features, velocity patterns, average transaction amounts, geographic spread, all directly into Lakebase tables with upsert semantics. Lakebase provides sub-millisecond reads, making it ideal for real-time feature serving without managing external infrastructure.
- MLflow for model training and serving. A RandomForest classifier is trained on historical labeled data using MLflow for experiment tracking and model versioning. The trained model is loaded as a Spark UDF and applied to every transaction in the streaming pipeline. Combined with live features from Lakebase, the model learns non-linear relationships between signals that static rules miss, and improves over time as new labeled data becomes available.
Step 4: Monitoring Everything in Real-Time
Operational visibility is a non-negotiable for fraud teams working under real-time regulatory reporting obligations. To make the system observable, the accelerator includes a Streamlit-based Databricks Apps that reads directly from Lakebase to provide a live fraud monitoring dashboard. This gives fraud analysts and risk manages a live, auditable view of every decision the system makes, without requiring engineering support to access it. Users can track total transactions scored, decision breakdowns (approved, flagged, blocked), recent fraud scores with card-level detail, and fraud probability distributions, all auto-refreshing every 10 seconds. This is the operational layer that makes the system usable in practice, not just technically functional.
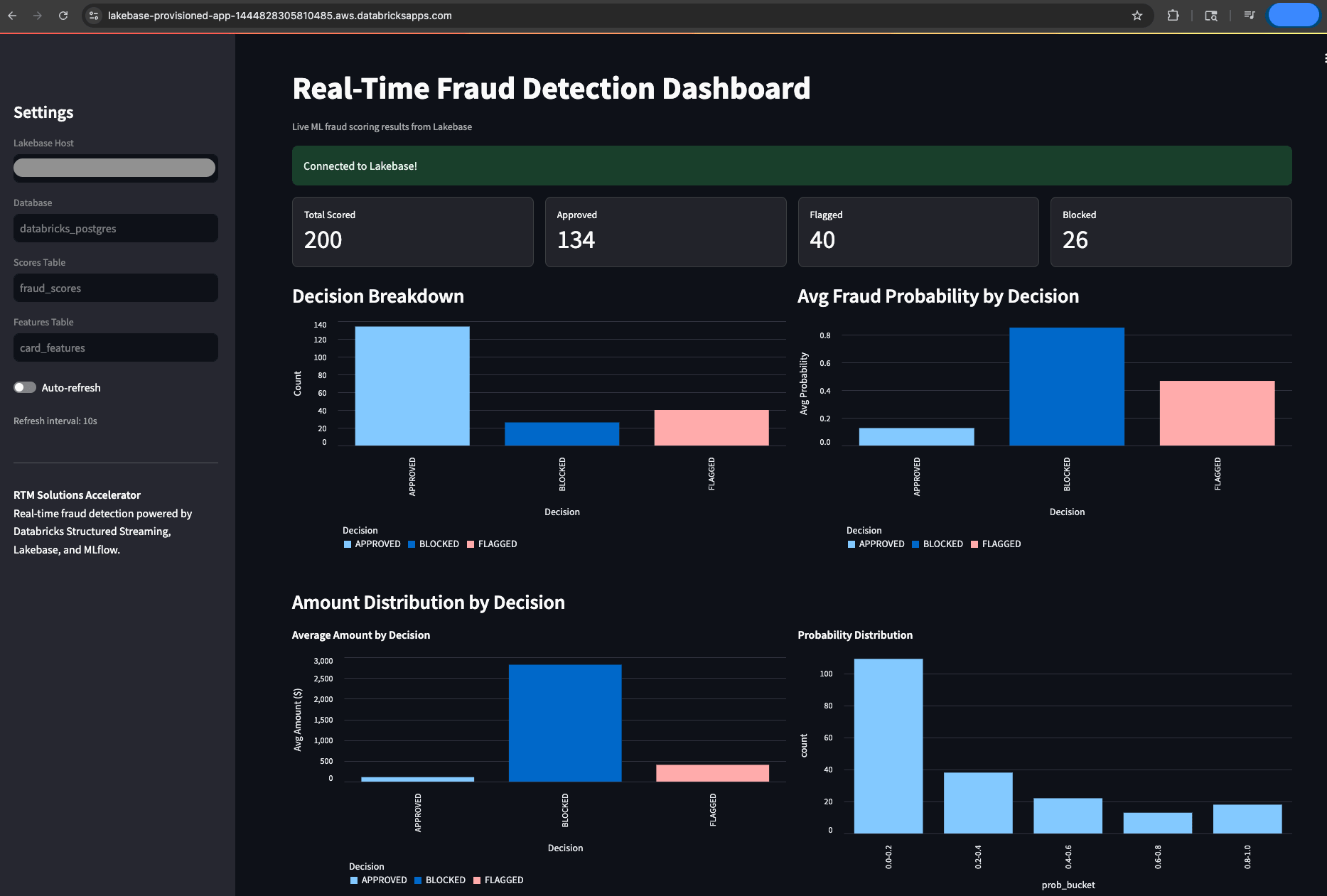
The key insight is that everything runs on one platform. The same Spark engine that powers your batch ETL and ML training now handles sub-300ms streaming. Unity Catalog now governs both your streaming tables and your training data. MLflow now tracks your fraud models, whether they're used in batch inference or real-time scoring. There's no integration gap, no governance split, and no second stack to maintain because everything is on the same platform.
Getting Started
This Solution Accelerator is designed to be progressively adaptable: start simple, and add complexity if needed.
- Quick Start: Clone the repo, open `notebooks/RTM_00_Quick_Start.py`, and run it on a cluster configured to run real-time mode. You'll see RTM processing synthetic transactions at sub-300ms latency — no Kafka, no external setup required.
- Full pipeline: Configure a Kafka secret scope with your broker addresses, then run `notebooks/RTM_01_Introduction_fraud_detection.py`. This gives you the complete parse-enrich-score-route pipeline reading from and writing to Kafka. When running, you'll see transactions flowing through all five stages and decisions landing in the approved, flagged, and blocked output topic. This gives you the complete parse-enrich-score-route pipeline reading from and writing to Kafka.
- ML-powered scoring: Create a Lakebase instance, then run `notebooks/RTM_02_Advanced_fraud_detection_ml.py`. This adds feature streaming to Lakebase, model training with MLflow, and ML-based scoring in the pipeline. When complete, MLflow will log the trained model and the pipeline will begin emitting ML-derived fraud scores in place of the rule-based weights.
- Live monitoring app: Deploy the Streamlit app from `apps/` as a Databricks Apps with a Lakebase resource binding. The app auto-connects and starts displaying live fraud scores.
The fastest path is with Databricks Asset Bundles — just clone, deploy, and run:
The bundle automatically provisions a correctly configured cluster and runs all notebooks in sequence.
Learn more about Real-Time Mode
Real-Time Mode is Generally Available on Databricks across AWS, Azure, and GCP. The fraud detection Solution Accelerator is open-source and ready to deploy.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.