Como transformar fluxos de trabalho de ativação de documentos com Genie e Agent Bricks
Transforme documentos em insights valiosos de negócios com Databricks
por Elena Tesser
-Fluxos manuais de extração de documentos em setores como mídia, comunicação e jogos atrasam as equipes, gerando perda de receita e aumentando o risco de conformidade.
-As empresas podem reunir AI/BI Genie, Agent Bricks e Unity Catalog para estabelecer um fluxo de trabalho rigoroso com múltiplos agentes que pode converter documentos importantes em marketing, jurídico, finanças, RH e muito mais em dados governados, pesquisáveis e acionáveis.
-Ao passar da extração para a orquestração de múltiplos agentes e a escrita de volta no sistema, as organizações podem fluir perfeitamente do processamento, leitura e ativação de seus documentos.
Há uma lacuna de inteligência documental nas empresas de hoje
As organizações operam com montanhas de documentos, desde contratos, acordos de emprego, acordos de talentos e NDAs, até ordens de inserção de publicidade e contratos de prestação de serviços e muito mais. Cada documento contém insights valiosos sobre receita potencial, risco e obrigação, no entanto, a forma como a maioria das organizações trabalha com eles não mudou muito em décadas.
No entanto, hoje, mesmo com as organizações integrando cada vez mais IA para ajudá-las a se moverem mais rápido, muitas equipes ainda dependem de humanos para ler PDFs, copiar campos em planilhas e reinserir dados em sistemas ERP, CRM e de planejamento. Tudo isso cria um risco significativo; fluxos de trabalho de processamento manual levam a atrasos e potencial perda de receita devido a erros humanos, enquanto a falta de governança significa que as equipes não podem auditar de forma confiável seus relatórios.
Ferramentas pontuais e arquiteturas legadas estão falhando
Os líderes entendem que a automação de IA pode ajudá-los a superar esses desafios. No entanto, muitos hesitam em integrar totalmente a IA em seus fluxos de trabalho, pois investimentos iniciais como motores de OCR, sistemas de gerenciamento do ciclo de vida de contratos e soluções pontuais específicas de domínio muitas vezes entregaram menos do que o esperado. Mesmo com as organizações experimentando GenAI, muitas equipes financeiras, jurídicas e de operações ainda relatam pouco valor realizado com investimentos em IA. A questão, no entanto, não é a automação de IA em si, mas as bases de dados fragmentadas e incompletas em que essas ferramentas iniciais se baseiam.
Sem uma base de dados unificada e bem governada, falta contexto setorial e organizacional, estão isoladas de sistemas empresariais chave, são construídas apenas para leitura, não para ativação. Pior ainda, quando você tenta construir um fluxo de trabalho de agente sobre isso, você obtém uma experiência que é desconexa, inconsistente e impossível de escalar.
Adotando uma abordagem de plataforma para ativação de documentos
O momento decisivo para a inteligência documental ocorre quando uma empresa evolui do gerenciamento de fluxos de trabalho com soluções de ferramentas pontuais para construí-los em uma base de dados unificada e governada. Essa mudança abre as portas para uma experiência multiagente verdadeiramente unificada e escalável que permite que usuários técnicos e não técnicos consultem seus dados de negócios estruturados e não estruturados e, em seguida, tomem ações apropriadas sobre esses dados.
Três recursos principais do Databricks tornam isso possível:
- AI/BI Genie: uma experiência de BI nativa de IA que permite aos usuários de negócios fazer perguntas em linguagem natural sobre tabelas Delta governadas, sem escrever SQL.
- Agent Bricks: blocos de construção reutilizáveis para agentes de produção de alta qualidade, incluindo extração de informações, assistentes de conhecimento e orquestração, que são construídos e otimizados em seus dados em vez de protótipos únicos.
- Unity Catalog: governança unificada, linhagem e controle de acesso granular sobre dados, agentes de IA e até mesmo servidores MCP, desde o documento de origem até a resposta do agente e a gravação no sistema.
O fluxo de trabalho de ativação de documentos multiagente
Sobre essa base, implementamos um fluxo de trabalho de ativação de documentos faseado que equipes técnicas e não técnicas podem adotar e replicar passo a passo.
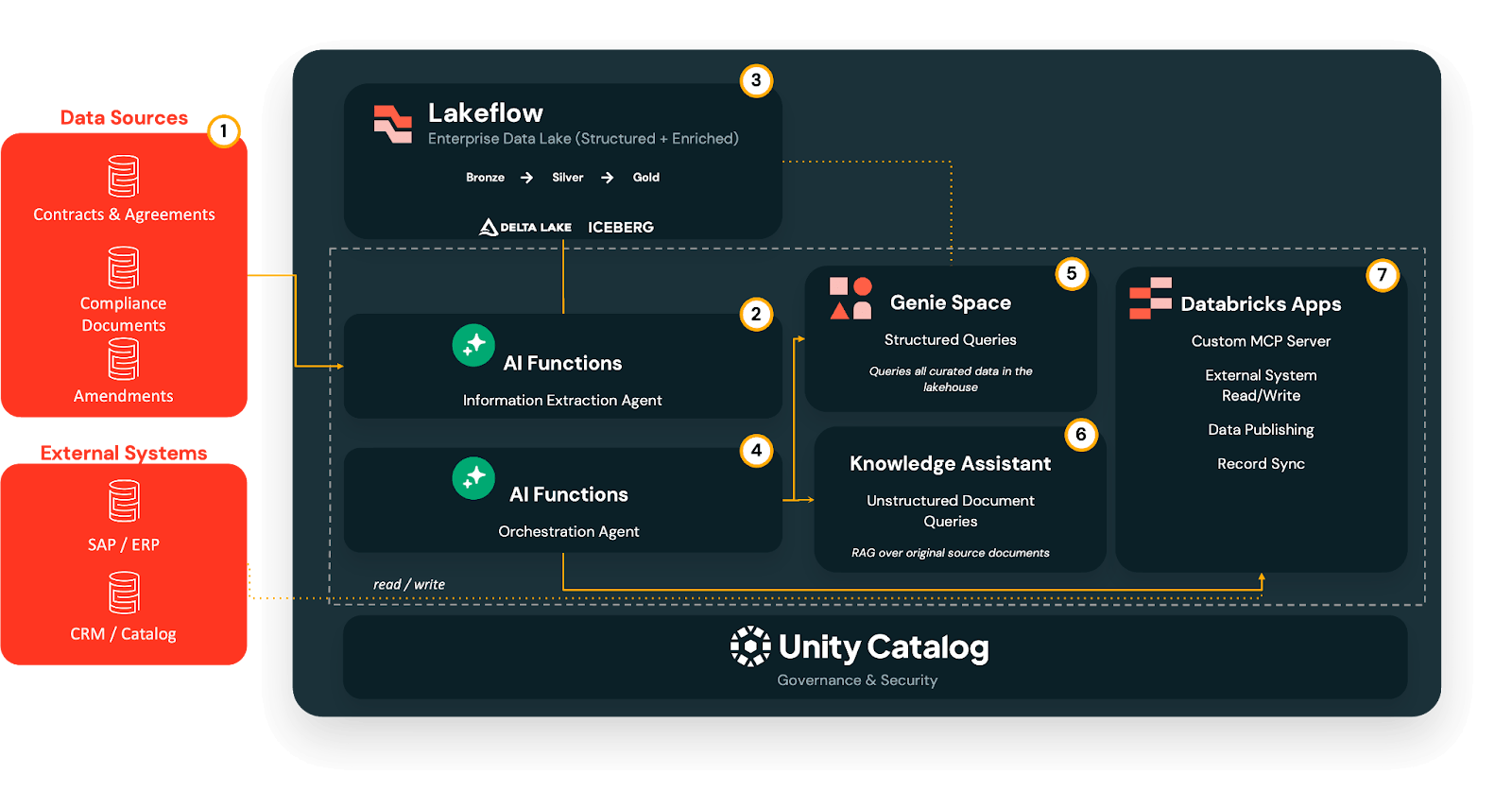
Fase 1 - Extrair: De PDFs para tabelas Delta governadas
Na Fase 1, o Agente de Extração de Informações usa extração baseada em LLM para converter documentos não estruturados (PDF, DOC/DOCX, PPT/PPTX, imagens) em campos estruturados, sem construir pipelines de OCR personalizados ou parsers únicos.
Os resultados brutos chegam a um pipeline Lakeflow medallion:
- Bronze: campos extraídos brutos como estão.
- Silver: valores limpos e padronizados, com IDs canônicos resolvidos e códigos normalizados.
- Gold: tabelas prontas para negócios otimizadas para consulta e análise.
Essa extração é executada no momento da ingestão, não no momento da consulta, para que tudo a jusante se baseie em uma base de dados consistente e governada.
Fase 2: Consultar - Análise self-service com Genie
Uma vez que os termos chave são estruturados em tabelas Delta, o AI/BI Genie fornece aos usuários de negócios uma interface self-service para fazer perguntas em inglês simples.
Aponte o Genie para as tabelas da camada gold, e os usuários podem fazer perguntas como “Quais contratos expiram no próximo trimestre na EMEA?” ou “Quais acordos de publicidade têm níveis de participação na receita que ativam acima de um determinado limite de gastos?” O Genie então traduz essas consultas em SQL, impõe as permissões do Unity Catalog e retorna resultados tabulares ou visuais, eliminando o gargalo do analista, mantendo o acesso aos dados governado.
Fase 3: Entender - Respostas em nível de cláusula com o Assistente de Conhecimento
Algumas perguntas não podem ser respondidas apenas com agregados. Equipes jurídicas, de direitos e de conformidade muitas vezes precisam saber exatamente o que uma cláusula específica diz.
Aqui, um Assistente de Conhecimento, um agente conversacional baseado em RAG, é executado diretamente sobre os documentos de origem originais armazenados nos Volumes do Unity Catalog.
Ele pode responder a perguntas como: ��“Quais são as restrições de sublicenciamento no acordo da Warner?” ou “Temos direitos SVOD para o Show X na França em 2027, e eles são exclusivos?” O assistente, então, retorna trechos em nível de cláusula com citações de volta aos PDFs originais, mantendo a rastreabilidade completa.
Fase 4: Orquestrar — uma porta de entrada com um supervisor multiagente
À medida que você adiciona mais agentes, você não quer que os usuários decidam qual ferramenta abrir para cada pergunta.
O Supervisor Multiagente atua como um único ponto de entrada conversacional que analisa cada consulta e a encaminha para o especialista certo:
- Perguntas estruturadas → Espaços Genie
- Perguntas em nível de cláusula → Assistente de Conhecimento
- Ações do sistema → Conectores baseados em MCP e fluxos downstream
Os usuários simplesmente fazem sua pergunta e o supervisor seleciona o caminho certo, combinando contexto não estruturado e estruturado quando necessário.
Fase 5: Agir — de insights a atualizações de sistema com MCP
Finalmente, os servidores MCP transformam o entendimento de documentos em ação, encapsulando APIs de sistemas externos (ERP, HRIS, CRM, plataformas de publicidade, sistemas de direitos, Slack) como ferramentas que o supervisor pode chamar.
Isso permite que você tome o melhor curso de ação com base nos dados extraídos e no contexto organizacional. Exemplos incluem::
- Enviar dados de direitos validados para o SAP e sincronizá-los com um catálogo de títulos ou CRM.
- Atualizar direitos e pacotes em sistemas de faturamento e atendimento ao cliente com base nos termos extraídos.
- Acionar fluxos de trabalho em ferramentas de ticketing ou gerenciamento de projetos quando prazos regulatórios ou obrigações de compensação forem detectados.
Por fim, como tudo isso é governado pelo Unity Catalog, cada campo permanece rastreável até o documento de onde veio, com linhagem e trilhas de auditoria entre agentes e gravação no sistema.
Casos de uso específicos da indústria em mídia, agências, ad tech e telecomunicações
Este fluxo de trabalho de ativação de documentos pode ser aplicado em uma ampla gama de indústrias e casos de uso. No entanto, pode ser especialmente impactante para indústrias como Telecomunicações e Mídia e Entretenimento, onde os clientes se baseiam em grandes quantidades de dados estruturados e não estruturados em rápida evolução dentro de seus documentos. Independentemente da necessidade de negócios ou persona, há uma aplicação para transformar documentos relevantes em insights limpos e governados e na próxima ação apropriada.
- Editoras e estúdios de mídia
- Acompanhar contratos de direitos e licenciamento, responder a perguntas como “Temos direitos de streaming para o Título X na Alemanha até 2027?” e sinalizar proativamente contratos que expiram nos próximos 90 dias.
- Extrair termos de participação na receita e distribuição em tabelas estruturadas e pipeline de números validados em sistemas ERP e de planejamento.

- Agências de mídia
- Extraia tabelas de preços, limites de AVB e gatilhos de faturamento de contratos de compra de mídia e concilie-os automaticamente com a entrega e os gastos.
- Estruture briefings de clientes e relatórios de pesquisa em dados reutilizáveis para sistemas de planejamento e análise de campanhas.
- Plataformas de AdTech
- Ative regulamentos de privacidade e documentos de políticas de anúncios para responder a “Quais regulamentos ativos exigem mecanismos de opt-out para direcionamento comportamental?” e aplique controles em motores de consentimento e políticas.
- Monitore licenças de dados e termos de API para evitar treinamento ou ativação de modelos não conformes.
- Provedores de telecomunicações
- Gerencie contratos de serviço e atacado, termos de acordos de roaming e interconexão, e locações de torres, com visibilidade clara de SLAs, escalonadores e janelas de renovação.
- Governe os direitos e pacotes de clientes de ponta a ponta, sincronizando direitos validados com sistemas de faturamento, CRM e suporte.
Em todos esses cenários, os clientes veem melhorias como fechamento de mês mais rápido, receita recuperada, redução de perdas e menor risco operacional, tudo isso enquanto reduzem o esforço manual para as equipes de finanças, jurídico, operações e marketing.
Próximos passos
Se suas equipes ainda dependem de fluxos de trabalho manuais de documentos e ferramentas desconectadas, agora é a hora de modernizar a inteligência de documentos em uma plataforma de dados e IA governada.
- Explore o Databricks para mídia e entretenimento e telecomunicações para ver como contratos, políticas e acordos se encaixam em sua estratégia de dados mais ampla.
- Converse com sua equipe de contas Databricks sobre uma prova de valor focada em ativação de documentos, começando com um caso de uso de alto impacto e uma única linha de negócios.
- Aprofunde-se em histórias de clientes como SEGA, First American e Vale para ver como as organizações já estão transformando documentos não estruturados em dados governados e acionáveis em escala.
Ao unificar extração, consulta, RAG, orquestração e gravação de sistema no Databricks, você pode ir além de simplesmente “ler documentos” para ativá-los, desbloqueando novas receitas, reduzindo riscos e liberando suas equipes para se concentrarem em trabalhos de maior valor.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.