Do monólito ao Lakebase ao LTAP: repensando o banco de dados a partir do armazenamento
por Reynold Xin
- Quase todos os bancos de dados tradicionais mantêm seu write-ahead log e arquivos de dados no disco de uma única máquina, o que é a causa raiz do risco de perda de dados, de réplicas de leitura caras, de clones de alta disponibilidade e de consultas analíticas que reduzem o desempenho das transações.
- O Lakebase torna a computação do Postgres stateless ao externalizar os arquivos de log e de dados em serviços de nuvem independentes (SafeKeeper e PageServer), liberando armazenamento ilimitado, computação elástica, gravações duráveis, HA mais simples e branching instantâneo, tudo sem latência adicional significativa.
- O LTAP vai além ao armazenar dados operacionais uma única vez em formatos colunares abertos que tanto o Postgres quanto os mecanismos de Lakehouse leem, de modo que as análises sejam executadas nos mesmos dados atualizados que as transações acabaram de gravar, sem pipeline de CDC, sem uma segunda cópia e sem lentidão na carga de trabalho transacional. Ao contrário do HTAP, que tenta unificar ambas as cargas de trabalho em um único mecanismo, o LTAP unifica na camada de armazenamento e mantém o melhor mecanismo para cada tarefa.
Quando comecei meu PhD na UC Berkeley há 16 anos, meu orientador me disse: "Bancos de dados OLTP são um problema resolvido. Eles funcionam. Foque em analytics." Estávamos no início da nossa capacidade de coletar muito mais dados, estruturados e não estruturados, e aplicar machine learning (que hoje chamamos de “AI”). Então, segui o conselho e me juntei aos meus cofundadores no projeto de pesquisa que se tornou o Apache Spark e, mais tarde, fundamos a Databricks.
Conforme construíamos a Databricks, começamos a usar vários bancos de dados existentes e percebemos que os bancos de dados OLTP estavam longe de ser um problema resolvido: eles eram desajeitados, difíceis de escalar e incrivelmente frágeis. Em certo momento, ficamos tão frustrados que nos perguntamos como seria um banco de dados OLTP se o projetássemos hoje. Essa pergunta nos levou ao Lakebase, nosso banco de dados Postgres serverless.
Este post faz uma análise profunda da arquitetura OLTP do Lakebase. Começamos pela camada de armazenamento de um banco de dados monolítico tradicional para ver de onde vêm os problemas e, em seguida, mostramos como o Lakebase reorganiza essas mesmas partes em serviços independentes e externalizados. Por fim, abordamos o LTAP, onde essa mesma arquitetura permite que transações e analytics sejam executados em uma única cópia dos dados, em tempo real, sem os atrasos e custos adicionais de CDC ou "espelhamento".
O banco de dados como um monólito
A grande maioria dos bancos de dados em execução no mundo hoje são monólitos. Isso inclui MySQL, Postgres e o Oracle clássico. O Lakebase é construído sobre o Postgres (que, por acaso, também nasceu em Berkeley), então usaremos o Postgres como o exemplo principal aqui, mas a maioria dos bancos de dados funciona de maneira semelhante: você provisiona uma máquina que executa o mecanismo de banco de dados e o armazenamento. Nesses sistemas de banco de dados, há duas coisas no disco que mais importam: o write ahead log (WAL) e os arquivos de dados.
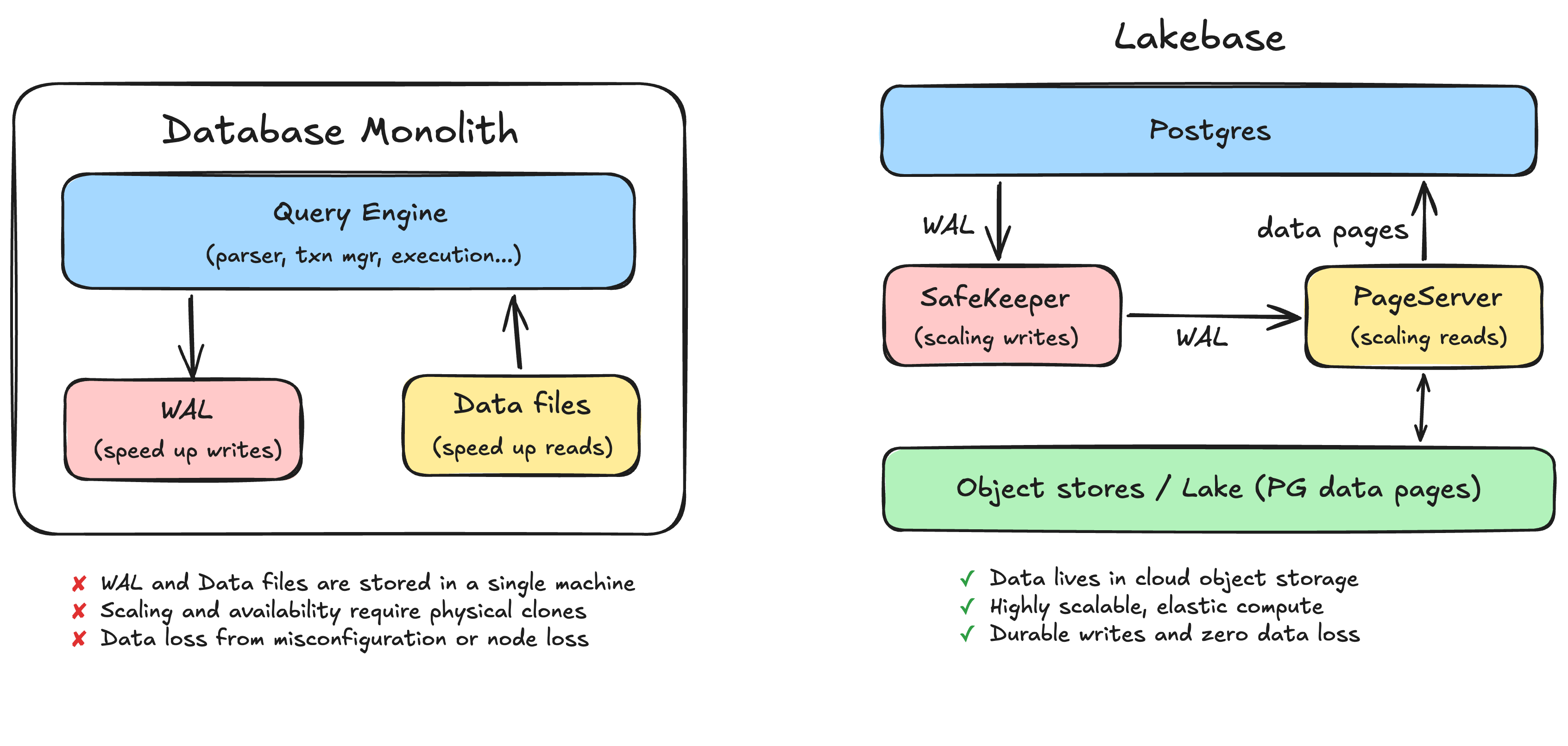
Quando você faz o commit de uma transação, o banco de dados não vai imediatamente reescrever os arquivos de dados. Isso seria lento, porque as linhas que você está alterando estão espalhadas pelo arquivo em locais que exigem I/O aleatório. Em vez disso, o banco de dados primeiro adiciona uma descrição da alteração ao WAL, que é um log sequencial no disco. Uma transação é considerada confirmada no momento em que essa entrada de log é gravada de forma durável. Só mais tarde, de forma assíncrona, o banco de dados volta e atualiza os arquivos de dados reais para refletir a alteração.
Uma maneira simples de pensar sobre isso: o WAL existe para tornar as gravações rápidas (e seguras), e os arquivos de dados existem para tornar as leituras rápidas. O log permite que você faça o commit de uma transação com uma única adição sequencial, em vez de várias operações de I/O aleatórias espalhadas. Os arquivos de dados permitem que você responda a uma consulta lendo o estado atual diretamente, em vez de reproduzir todo o histórico do banco de dados desde o início dos tempos. (Se você quiser entender todos os detalhes complexos desse design, leia o artigo do ARIES de 69 páginas. Fica o aviso de que este é um dos artigos mais complexos da ciência da computação.)
Como esse design se tornou a base de praticamente todos os bancos de dados existentes, a arquitetura monolítica também cria muitos desafios:
Perda de dados por configuração incorreta. Um commit é tão durável quanto o flush de disco por trás dele. Se o banco de dados, o sistema operacional ou a camada de armazenamento forem configurados de modo que uma gravação no WAL seja confirmada para o cliente antes de realmente ter sido gravada em uma mídia durável, então um commit pode desaparecer em uma queda de energia ou kernel panic. Essas configurações são sutis, fáceis de errar e a falha geralmente é silenciosa. O sistema operacional pode até decidir mentir para você sobre o flush!
Perda de dados por perda de nó. Mesmo com os flushes configurados corretamente, o WAL e os arquivos de dados residem em uma única máquina. Se o disco dessa máquina falhar, os dados nela contidos também serão perdidos. Observe que o armazenamento conectado à rede ou técnicas de redundância como RAID-1/RAID-10 podem melhorar a durabilidade, mas não resolvem fundamentalmente esse problema. Se a montagem do armazenamento falhar, o acesso aos seus dados também falhará.
Escalar leituras exige um clone físico. Quando uma única máquina não consegue mais atender ao seu tráfego, a resposta padrão é adicionar uma réplica de leitura. Mas uma réplica de leitura é uma cópia física completa de todo o banco de dados, que recebe o streaming do WAL a partir do nó primário e o reproduz. Provisionar uma réplica significa copiar todo o conjunto de dados e depois atualizar o log. Para um banco de dados grande, essa não é uma operação rápida e pode até derrubar o banco de dados.
A alta disponibilidade também exige um clone físico. Sobreviver à perda do nó primário significa executar pelo menos um nó standby adicional, que é, por si só, uma cópia física completa do banco de dados mantida em sincronia a partir do WAL. Você paga por pelo menos o dobro da infraestrutura, espera muito tempo para colocar um standby online e precisa configurar a replicação síncrona para evitar a perda de dados quando o primário cair. (Na prática, muitos recomendam 3 ou mais nós.)
O analytics compete com seu tráfego transacional. Uma consulta analítica pesada é executada nos mesmos recursos de hardware que sua carga de trabalho transacional sensível à latência. Uma grande consulta de relatório ou uma limpeza de GDPR pode degradar suas consultas OLTP principais. Você pode executar as consultas analíticas em uma réplica separada, mas acabará pagando pela réplica e ainda assim não obterá o desempenho ideal devido à natureza orientada a linhas do armazenamento OLTP (o analytics exige armazenamento orientado a colunas para alto desempenho).
Quase todos esses problemas remontam à mesma causa raiz da arquitetura monolítica: o WAL e os arquivos de dados são armazenados dentro de uma única máquina. A durabilidade está atrelada ao disco dessa máquina. A escalabilidade e a disponibilidade exigem a clonagem física dessa máquina. As cargas de trabalho interferem umas nas outras porque compartilham essa máquina.
Arquitetura do Lakebase
Se você fosse reprojetar um banco de dados OLTP hoje, começaria com os componentes da nuvem moderna: armazenamento de objetos em nuvem barato e altamente durável, combinado com computação elástica. Esse é o caminho que a equipe da Neon seguiu e a base do que se tornou o Lakebase.
A principal mudança é tornar as instâncias de computação do Postgres stateless. Fazemos isso externalizando o WAL e os arquivos de dados em discos locais para serviços criados sob medida e escaláveis de forma independente. A camada de computação se torna um mecanismo Postgres stateless que pode ser iniciado, interrompido e replicado livremente, pois não é mais proprietário dos dados.
Vejamos como esses dois serviços de armazenamento podem trabalhar juntos para resolver os desafios mencionados acima sem sacrificar o desempenho.
Escalando gravações: o WAL se torna SafeKeeper
Em um monólito, uma gravação torna-se durável ao fazer o flush no disco local. No Lakebase, o WAL é externalizado para um serviço de armazenamento distribuído chamado SafeKeeper. Em vez de depender do flush de disco para durabilidade, um commit torna-se durável ao replicar o registro de log em um quórum de nós SafeKeeper usando replicação de rede baseada em Paxos. Não há mais um disco cuja falha cause a perda de seus dados, e não há mais um flush mal configurado comprometendo silenciosamente sua garantia de durabilidade.
É natural perguntar neste ponto: mover os commits do WAL no disco local para o WAL no SafeKeeper aumenta a latência de gravação devido ao salto de rede adicional? A resposta é não. Para qualquer implantação séria do Postgres que se preocupe com durabilidade e disponibilidade, você teria que configurar a replicação síncrona, o que exige o salto de rede adicional, de modo que a externalização do WAL no SafeKeeper não gera sobrecarga adicional. Na verdade, devido à forma como o Postgres funciona internamente, a combinação de SafeKeeper e PageServer pode levar a um throughput de gravação 5 vezes maior e latência de leitura 2 vezes menor.
Escalando leituras: os arquivos de dados se tornam PageServer
Os arquivos de dados são movidos para outro serviço de armazenamento distribuído chamado PageServer. O WAL é transmitido via streaming do SafeKeeper para o PageServer, e o PageServer aplica essas alterações de forma assíncrona à sua versão dos dados, materializando páginas em um armazenamento de objetos em nuvem de baixo custo (o lake). Você pode pensar no PageServer como um cache write-through para o armazenamento de objetos subjacente.
Isso é semelhante à relação entre WAL e arquivos de dados do monólito, exceto que as duas partes agora residem em serviços separados e escaláveis de forma independente, conectados pela rede, em vez de ficarem no mesmo disco. Quando uma página é solicitada ao PageServer, e se o PageServer ainda não tiver a versão mais recente (lembre-se de que as alterações são gravadas primeiro no SafeKeeper antes de irem para o PageServer), o PageServer aplica os logs do SafeKeeper para reconstruir o estado mais recente.
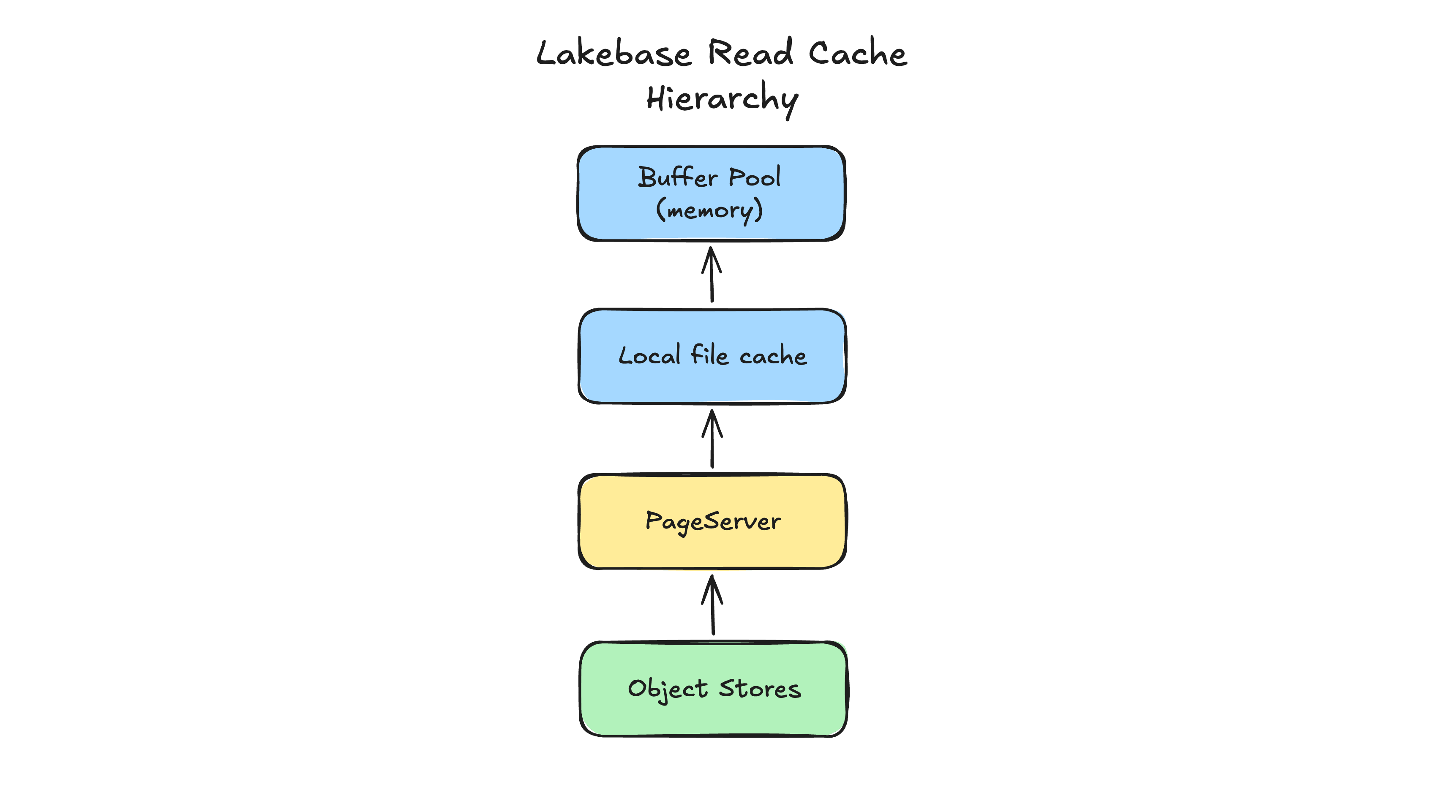
Uma pergunta semelhante: mover arquivos de dados de discos locais para o PageServer aumenta a latência de leitura devido ao salto de rede adicional? A resposta também é não, para todos os fins práticos. O sistema foi projetado para isolar e minimizar o impacto da latência por meio de um cache agressivo em várias camadas. Para buscar uma página, o Postgres primeiro consulta seu buffer pool, que fica na memória local do nó. Quando a página não está presente, ele consulta um cache de disco local. Ele só precisa ir ao PageServer se houver um cache miss. Como um nó de computação pode ser configurado com capacidades de memória local e disco idênticas às de uma configuração monolítica, sua taxa de acerto de cache local permanece inalterada. Para a grande maioria das operações, a latência de leitura é indistinguível de um monólito, mas você ganha o benefício de um armazenamento desacoplado e virtualmente infinito.
O que isso possibilita
Uma vez que o WAL reside no SafeKeeper e os arquivos de dados residem no PageServer, uma longa lista de recursos que eram difíceis ou impossíveis no monólito tornam-se consequências naturais da arquitetura. Os seguintes recursos já estão amplamente disponíveis como parte do produto Lakebase tanto no Databricks quanto no Neon:
Ainda é Postgres. Este é o Postgres real, portanto, o protocolo de conexão, SQL, drivers e extensões funcionam exatamente como são.
Armazenamento ilimitado. Os dados residem no armazenamento de objetos em nuvem, em vez de em um disco local provisionado. Você não precisa mais dimensionar uma máquina para um limite de capacidade. O armazenamento é, para fins práticos, infinito.
Computação elástica e serverless. Como a computação é stateless, ela pode ser dimensionada verticalmente de forma instantânea sob carga e reduzida até zero quando ociosa. Você deixa de pagar por uma máquina grande que fica ociosa esperando por tráfego.
Gravações duráveis e zero perda de dados. Um commit é durável assim que é replicado entre os nós do SafeKeeper via Paxos, e não quando um único disco local afirma ter feito o flush. A perda de qualquer nó individual não resulta em perda de dados confirmados.
Alta disponibilidade mais simples. No monólito, HA significava manter um segundo clone físico completo, pagar o dobro e ainda correr o risco de perda de dados na transição (cutover). Aqui, o estado durável já reside em uma camada de armazenamento replicada que é independente de qualquer instância de computação individual. Realizar o failover não significa mais promover uma cópia física separada do banco de dados e torcer para que o último segmento do log tenha sido transmitido.
Ramificação (branching), clonagem e recuperação instantâneas. Esta é a minha parte favorita. Para código, criar um branch é uma cópia totalmente isolada de toda a base de código gerada em menos de um segundo, e fazemos isso dezenas de vezes ao dia sem pensar duas vezes. Para um banco de dados monolítico, clonar significa copiar fisicamente todo o conjunto de dados, o que é lento, caro e arriscado para o sistema de produção. Quando os dados residem em uma camada de armazenamento externa e versionada, um branch ou um clone é uma operação de metadados, e não uma cópia física. Você pode criar um branch de um grande banco de dados de produção em segundos, executar um experimento ou uma migração arriscada nesse branch e depois descartá-lo. A recuperação para um ponto no tempo (PITR) funciona da mesma maneira. O banco de dados finalmente se move tão rápido quanto o seu código.
Separar a computação do armazenamento não é algo novo por si só. O post anterior discutiu as ferramentas de banco de dados em nuvem de segunda geração que já faziam isso. No entanto, o diferencial do Lakebase é que armazenamos dados operacionais em armazenamento de objetos comum em um formato aberto. Com isso, abrimos oportunidades para que outros engines os leiam diretamente, o que nos leva ao LTAP.
LTAP: uma única cópia para transações e análises
Tudo até agora foi para melhorar um único banco de dados operacional: torná-lo mais durável, mais elástico, mais barato de executar e mais rápido para criar ramificações. Mas, uma vez que os dados residem em uma camada de armazenamento externa, algo mais interessante se torna possível. Podemos parar de tratar o banco de dados transacional e o sistema analítico como dois mundos separados.
Voltemos ao PageServer por um momento. Ele já recebe o fluxo de alterações do WAL e materializa páginas de forma assíncrona no armazenamento de objetos. Essa etapa de materialização, o momento em que os dados chegam ao lake, revela-se exatamente o lugar certo para resolver um problema muito mais antigo...
Mesmo com um Lakebase, os dados no armazenamento de objetos ainda eram gravados no formato de página nativo do Postgres, organizados linha por linha. Esse formato é excelente para transações e ruim para análises, de modo que qualquer engine analítico que quisesse lê-lo precisava pagar um custo de conversão a cada leitura ou, mais comumente, depender de uma cópia separada dos dados mantida em sincronia por um pipeline. O pipeline pode ser frágil, e as duas cópias dos dados podem se tornar um pesadelo de governança com permissões divergentes.
Anunciamos recentemente o LTAP (Lake Transactional/Analytical Processing), que elimina o problema das duas cópias de dados. A ideia principal é unificar os dois mundos na camada de armazenamento, e não na camada de engine. Não tentamos construir um único engine que seja excelente tanto em transações quanto em análises. Mantemos a melhor ferramenta para cada tarefa: Postgres, com semântica ACID completa para transações, e os engines de Lakehouse para análises. O que muda são os dados abaixo deles. Em vez de duas cópias em dois formatos, há uma cópia durável, em formatos colunares abertos como Delta e Iceberg, armazenada como Parquet, que ambos os lados leem (e com vários níveis de caches para melhor desempenho).
Materialização em formato colunar
Nota: esta seção exige mais conhecimento interno do Postgres para ser compreendida do que as outras seções.
À medida que o PageServer materializa as páginas no armazenamento de objetos, ele transcodifica os dados do Postgres de um formato de linha para o layout colunar do Parquet conforme eles chegam ao lake. Preservamos a representação exata do Postgres de cada valor, até os bits, para que qualquer engine compatível com o Postgres possa reinterpretá-lo sem perder informações. Isso é diferente da abordagem baseada em CDC, pois o CDC envia um fluxo de eventos de alteração lógica para um esquema externo e deixa para trás a semântica física e transacional do Postgres; aqui, nós as mantemos. Com um engine hiperotimizado, a CPU sobressalente na camada do PageServer faz a transcodificação de linha para colunar como parte da materialização dos dados no armazenamento de objetos, de modo que não adiciona nenhuma carga à computação do Postgres que atende às suas transações. Para atender às leituras transacionais com eficiência, o PageServer ainda materializa páginas tradicionais baseadas em linhas em um cache local, mas este é estritamente um cache de desempenho. O armazenamento durável subjacente permanece unificado no lake, acessível por ambos os lados.
Preservar a semântica do Postgres em formato colunar resume-se a duas coisas: o sistema de tipos e o multiversionamento.
Sistema de tipos. A maioria dos tipos do Postgres é mapeada diretamente para tipos nativos do Parquet. O pequeno grupo de valores sem equivalente colunar sem perdas, por exemplo, NaN e ±Infinity, NUMERICs além do intervalo decimal, tipos exóticos ou de extensão, não são descartados ou coagidos. Eles são transportados junto com as colunas originais em um campo de estouro (overflow) estruturado dentro da mesma tabela, contendo o texto canônico do Postgres para esses valores. Esse campo é diretamente consultável por qualquer engine e suficiente para reconstruir exatamente os bytes originais do Postgres no caminho de volta.
Multiversionamento. No Postgres, cada versão de linha que alguma transação possa observar é retida, o que é exatamente o que torna possível o isolamento de snapshot e a recuperação de ponto no tempo (PITR). Em contraste, os formatos de tabela aberta expõem snapshots consistentes em toda a tabela sem nenhuma versão de linha intermediária. Obtemos os benefícios de ambas as abordagens separando a durabilidade da visibilidade. Cada linha materializada para colunar carrega seu endereço físico de heap (bloco e deslocamento), de modo que as páginas de heap permanecem totalmente reconstruíveis. A página de heap clássica do Postgres torna-se um cache que acelera as leituras pontuais, enquanto a fonte durável da verdade reside nos arquivos colunares no armazenamento de objetos. Os índices do Postgres não são transcodificados em colunas; eles são servidos e reconstruídos a partir dessa camada de cache dinâmico (hot cache). As versões intermediárias de linha são mantidas para preservar a semântica MVCC e o PITR do Postgres, mas não são visíveis para os leitores do Iceberg/Delta e acabam sendo coletadas pelo coletor de lixo (garbage-collected). O resultado líquido: os engines analíticos veem tabelas limpas e consistentes com snapshots, enquanto o sistema Postgres subjacente ainda vê um histórico de versões completo e navegável no tempo (time-travelable).
Também há um efeito colateral positivo. Os dados colunares são compactados muito melhor do que os dados em linhas, geralmente em mais de dez vezes. Portanto, a conversão para o armazenamento colunar reduz substancialmente o volume de dados que cruzam a rede entre a camada de cache e o armazenamento de objetos, a ponto de muitas vezes ser insignificante. O formato que torna a análise rápida também barateia o caminho de armazenamento. Nós inclusive aproveitamos isso para fazer gravação dupla (tanto no formato de linha quanto no formato colunar) em armazenamentos de objetos para verificação de dados durante a fase de transição de implementação do LTAP (já que queremos ser extremamente cuidadosos com alterações de armazenamento).
Lendo os dados mais recentes sem afetar o Postgres
Um grande desafio é a atualização dos dados. Se a análise lê de uma cópia no lake, como ela vê os dados que foram confirmados (committed) há um momento e ainda não foram materializados no armazenamento de objetos? Essa é a questão que inviabiliza a maioria dos projetos do tipo "basta apontar a análise para o lake", por isso vale a pena examinar como o LTAP responde a ela.
Quando uma consulta analítica começa (por exemplo, a partir do produto Lakehouse//RT que acabamos de anunciar), ela primeiro solicita ao Postgres o LSN atual, o número de sequência de log que marca a posição exata no WAL a partir da qual a leitura deve ser feita. Essa é uma busca de metadados de baixo custo. Com esse LSN, o mecanismo analítico lê a grande maioria dos dados, incluindo tudo o que já foi materializado até aquele momento, diretamente do armazenamento de objetos. A única coisa que resta é o pequeno conjunto de alterações muito recentes que ainda não foram materializadas no lake, as quais ele busca no PageServer e mescla por cima.
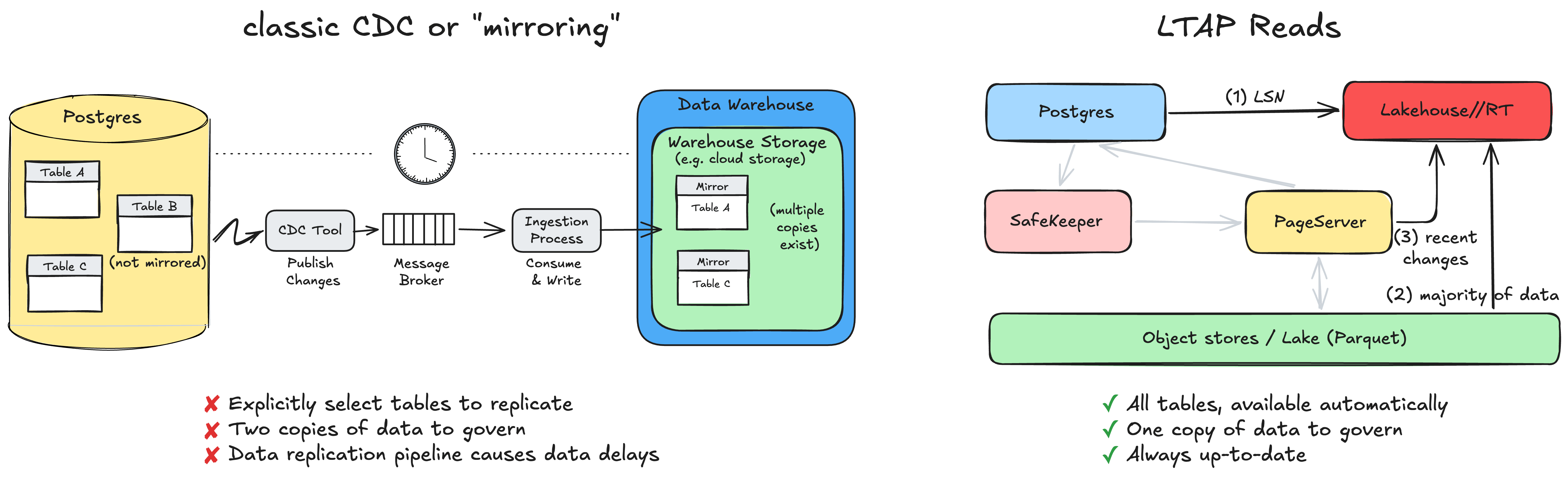
O resultado é uma leitura consistente e totalmente atualizada dos seus dados a partir daquele LSN. Quase todo o trabalho recai sobre o armazenamento de objetos, que é barato e escalável. E, fundamentalmente, o próprio Postgres não atende a nenhum tráfego de leitura analítica, exceto pelo retorno de um único número (LSN). Sua carga de trabalho transacional não desacelera porque alguém iniciou uma grande consulta analítica.
Há uma otimização prática que vale a pena mencionar aqui: para tabelas muito pequenas, aquelas que contêm poucas linhas, não nos preocupamos em convertê-las para o formato colunar e criar os metadados do Iceberg associados. O processamento extra custaria mais do que economizaria, e uma tabela tão pequena não tem efeito mensurável no desempenho analítico, independentemente de como esteja organizada. Essas tabelas ainda estão presentes e podem ser consultadas como parte da cópia única.
Todas as tabelas, automaticamente
Devido à importância desse problema, tem havido muita discussão no mercado sobre a integração de OLTP e análise. Uma abordagem clássica é o CDC, que replica efetivamente os dados do armazenamento OLTP para uma camada de armazenamento de análise separada. Você já deve ter ouvido falar de outros nomes para isso, como “espelhamento” (mirroring), “zero CDC” ou “zero ETL”.
No CDC ou “espelhamento”, como o pipeline de replicação de dados tem um custo, ele não pode ser aplicado a todas as tabelas. Você teria que selecionar explicitamente quais tabelas são importantes para você, e essa replicação normalmente ocorre com um atraso.
No LTAP, não há nada para ativar. Uma tabela existente já está, por definição, no lake e pronta para ser consultada. Não há lista de tabelas replicadas ou espelhadas, porque não há replicação. Existe uma única cópia governada dos dados em formatos abertos, sem nenhum pipeline de ETL para criar, monitorar ou consertar (seja por nossos clientes ou por nós). Os mecanismos transacionais e analíticos escalam de forma independente, cada um dimensionado para sua própria carga de trabalho. E como não há movimentação de dados nem uma segunda cópia, as duas visualizações nunca divergem: a análise sempre lê os mesmos dados que a aplicação acabou de gravar.
Para ver de outra forma como o LTAP funciona em conjunto, confira esta demonstração do Data and AI Summit.
E quanto ao HTAP?
Se você conhece a área, já deve ter percebido que o LTAP é um trocadilho intencional com o HTAP: processamento híbrido transacional/analítico. O HTAP tem sido o Santo Graal da engenharia de banco de dados, focando na criação de um único mecanismo capaz de lidar com cargas de trabalho transacionais e analíticas.
Na prática, não houve um único sistema de banco de dados HTAP amplamente adotado no mercado. Por que isso acontece? Na minha opinião, os sistemas HTAP sofrem de um ou mais dos seguintes problemas:
Conjunto de recursos incompleto. Projetar um novo mecanismo proprietário do zero para realizar uma única tarefa é um investimento de vários anos. Tentar criar um único mecanismo que possa fazer o trabalho de vários mecanismos multiplica o investimento necessário para alcançar o conjunto de recursos que os engenheiros consideram garantidos em um banco de dados maduro. Esses sistemas geralmente ficam atrás em aspectos que as pessoas supõem que sempre existam, desde a abrangência do suporte a SQL (por exemplo, suporte a chaves estrangeiras) até a maturidade do otimizador de consultas.
Sem ecossistema. O Postgres e o Spark estão, cada um, no centro de um ecossistema vasto: drivers, extensões, ferramentas e décadas de conhecimento operacional acumulado. Um mecanismo totalmente novo começa fora de tudo isso, e um mecanismo é tão útil quanto o ecossistema sobre o qual uma equipe pode realmente construir.
Sem isolamento de desempenho. Muitos sistemas HTAP executam transações e análises no mesmo hardware, de modo que as duas cargas de trabalho competem pela mesma CPU e memória. Essa é a mesma falha com a qual começamos no monólito, com uma consulta analítica deixando a carga de trabalho transacional sem recursos.
Todos os três problemas remontam à mesma decisão de unificar as duas cargas de trabalho em um único mecanismo. O Lakebase e o LTAP contornam esses desafios unificando na camada de armazenamento, enquanto usam mecanismos de computação diferentes para as diferentes cargas de trabalho, aproveitando seus conjuntos completos de recursos e suporte ao ecossistema, com total isolamento de desempenho.
Considerações finais
Quando apresentamos a arquitetura Lakebase pela primeira vez no ano passado, já sabíamos que ela liberaria armazenamento ilimitado, computação elástica, gravações duráveis, HA mais simples e ramificação instantânea, com base no que vimos com a plataforma Neon. Isso aconteceu de forma quase mecânica assim que o WAL passou a residir no SafeKeeper e os arquivos de dados no PageServer.
A ideia do LTAP surgiu mais tarde, depois que as equipes da Neon e da Databricks se uniram para resolver o problema de décadas de executar análises em dados transacionais mais recentes. À medida que ajustamos os detalhes do LTAP e o implementamos nos próximos meses, todas as suas tabelas do Lakebase estarão disponíveis para análise com o mesmo alto desempenho dos dados do Lakehouse.
O que mais me entusiasma é o que está por vir. Embora o LTAP seja um próximo passo natural, o mesmo design também abre muitas oportunidades de otimização para separar outras operações de manutenção pesadas das cargas de trabalho transacionais principais. Estamos apenas começando a explorar o que essa arquitetura torna possível e estamos ansiosos para compartilhar o que vem a seguir.
Agradecimento: Gostaria de agradecer à equipe do Lakebase por tornar real tudo o que discutimos neste blog, por revisar este texto e por me manter fiel aos detalhes técnicos.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.