Do Lakehouse à Mente Digital: Arquitetando um Ecossistema de AI Multiagente no Databricks Agent Bricks
Veja como a Edmunds reinventou seu data lakehouse em uma plataforma de AI multiagente inteligente com o Agent Bricks para ativação, automação e inovação contínua.
por Gregory Rokita
- A Edmunds construiu um ecossistema multiagente nativo de AI no Databricks Agent Bricks, passando do armazenamento passivo de dados para a automação inteligente em tempo real em todas as funções de compra de carros.
- Agentes especializados como o DataDave alcançam 95% de precisão em análises complexas, enquanto as ofertas de marketing melhoraram as taxas de conversão usando insights do lakehouse unificado.
- A arquitetura permite automação escalável, colaboração entre agentes e experiências proativas e personalizadas tanto para equipes internas quanto para compradores de carros.
Nas empresas de hoje, ter um data lakehouse amplo e unificado é fundamental para ativar dados. Com um lakehouse, as organizações podem transformar um repositório passivo em um mecanismo dinâmico e inteligente que antecipa necessidades, automatiza o conhecimento especializado e impulsiona decisões mais informadas. Na Edmunds, essa prioridade levou ao lançamento do Edmunds Mind, nossa iniciativa para construir um ecossistema de AI multiagente sofisticado diretamente na Databricks Data Intelligence Platform.
Essa evolução arquitetônica é impulsionada por um momento crucial na indústria automotiva. Três tendências principais convergiram:
- A ascensão dos grandes modelos de linguagem (LLMs) como poderosos mecanismos de raciocínio
- A escalabilidade e a governança de plataformas como a Databricks como uma base segura
- O surgimento de frameworks agênticos robustos para orquestrar a automação. Esses fatores viabilizam sistemas que pareceriam inimagináveis há apenas alguns anos
Essa transformação não se trata apenas de adicionar mais uma ferramenta de AI, mas também de redesenhar fundamentalmente nossa organização para operar de forma nativa em AI. Os princípios, componentes e estratégias por trás desse núcleo inteligente estão detalhados em nosso blueprint arquitetônico abaixo.
“A Databricks nos oferece uma base segura e governada para executar vários modelos, como GPT-4o, Claude e Llama, e trocar de provedor conforme nossas necessidades evoluem, tudo isso mantendo os custos sob controle. Essa flexibilidade nos permite automatizar a moderação de avaliações e melhorar a qualidade do conteúdo mais rapidamente, para que os compradores de carros recebam insights confiáveis quanto antes.”—Gregory Rokita, VP of Technology, Edmunds
Transformando uma empresa rica em dados em uma organização orientada por insights
Nossa visão é evoluir de uma empresa rica em dados para uma organização orientada por insights. Aproveitamos a AI para construir a experiência de compra de carros mais confiável, personalizada e preditiva do setor.
Isso é realizado por meio de quatro pilares estratégicos fundamentais:
- Ativar dados em escala: transição de dashboards estáticos para uma interação dinâmica e conversacional com os dados.
- Automatizar a especialização: codificar a lógica inestimável de nossos especialistas de domínio em agentes autônomos e reutilizáveis.
- Acelerar a inovação de produtos: fornecer às nossas equipes um conjunto de ferramentas de agentes inteligentes para criar recursos de última geração.
- Otimizar as operações internas: gerar ganhos significativos de eficiência automatizando fluxos de trabalho internos complexos.
No coração dessa visão está nossa vantagem competitiva mais significativa: o Edmunds Data Moat. Essa poderosa base de dados automotivos é liderada por nosso inventário de veículos usados líder do setor, o conjunto mais abrangente de avaliações de especialistas e inteligência de preços de ponta, complementado por extensas avaliações de consumidores e listagens de novos veículos. Todo esse ecossistema é unificado e gerenciado em nosso ambiente Databricks, criando um ativo único e poderoso. O Edmunds Mind é o mecanismo que construímos para desbloquear todo o seu potencial.
Por dentro do framework de agentes digitais
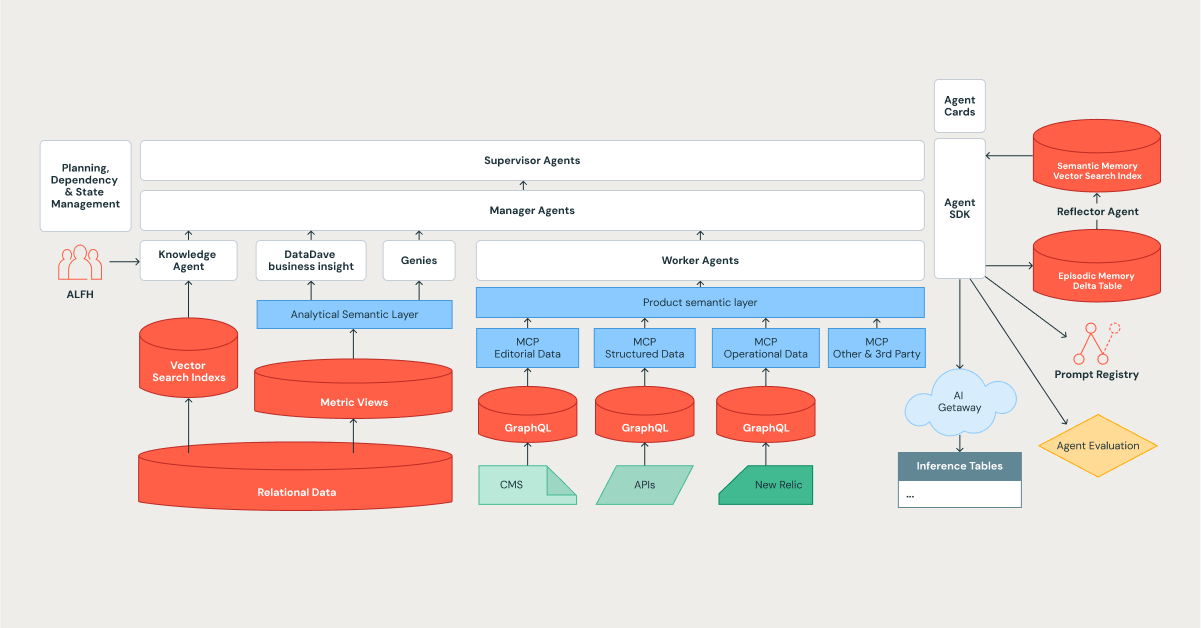
A arquitetura do Edmunds Mind é um sistema cognitivo hierárquico projetado para complexidade, aprendizado e escala, tendo a plataforma Databricks como sua base.
A hierarquia de agentes: uma organização de especialistas digitais
Projetamos nosso sistema para espelhar uma organização eficiente, usando uma estrutura em camadas onde as tarefas são decompostas e delegadas. Isso se alinha perfeitamente aos padrões de orquestrador em frameworks modernos, como o Databricks Agent Bricks.
- Agentes supervisores: os líderes estratégicos. Eles realizam planejamento de longo prazo, gerenciam dependências e orquestram tarefas complexas de várias etapas.
- Agentes gerentes: os líderes de equipe. Eles coordenam uma equipe de agentes especializados para atingir um objetivo específico e bem definido.
- Agentes executores e especializados: estes são os colaboradores individuais que fornecem conhecimento especializado. Eles são a força de trabalho do sistema e incluem uma lista crescente de especialistas, como o Knowledge Assistant, o DataDave e vários Genies.
A comunicação entre agentes é governada por um protocolo padronizado, garantindo que as delegações de tarefas e as transferências de dados sejam estruturadas, tipadas e auditáveis, o que é fundamental para manter a confiabilidade em escala.
A hierarquia também foi projetada para falhas controladas (graceful failure). Quando um agente gerente determina que sua equipe de especialistas não pode resolver uma tarefa, ele escala todo o contexto da tarefa de volta para o supervisor, incluindo as tentativas malsucedidas armazenadas em sua memória episódica. O supervisor pode então replanejar com uma estratégia diferente ou, crucialmente, sinalizar isso como um problema inédito que requer intervenção humana para desenvolver uma nova capacidade. Isso torna o sistema robusto e uma ferramenta de aprendizado que nos ajuda a identificar os limites de sua competência.
Análise profunda 1: fluxo de trabalho automatizado de enriquecimento de dados
Historicamente, resolver imprecisões nos dados dos veículos, como cores incorretas em uma página de detalhes do veículo (Vehicle Detail Page), era um processo trabalhoso que exigia coordenação manual entre várias equipes. Hoje, o ecossistema de AI Edmunds Mind automatiza e resolve esses desafios quase em tempo real. Essa eficiência operacional é alcançada por meio do nosso Model Serving centralizado, que consolida nossos diversos recursos de agentes de AI em um único ambiente coeso que faz o escalonamento automático com base na demanda. Essa arquitetura liberta nossas equipes da sobrecarga operacional, permitindo que se concentrem em entregar valor aos nossos usuários rapidamente.
O processo de resolução é executado por meio de um fluxo de trabalho multiagente governado. Quando um usuário ou um monitor automatizado sinaliza uma possível discrepância de dados, um agente supervisor faz a triagem imediata do evento. Ele avalia o problema, direciona-o para a equipe especializada apropriada e valida as permissões de tarefa por meio do Unity Catalog para uma governança de dados robusta. Um agente gerente dedicado então orquestra uma sequência de agentes executores especializados para realizar tarefas que variam de decodificação de VIN e recuperação de imagens a análise de cores baseada em AI e atualizações finais no banco de dados. Os curadores de dados humanos continuam sendo essenciais para a revisão crítica, mudando seu foco da intervenção manual para a etapa de aprovação de alto valor. Cada interação e decisão é registrada sistematicamente, construindo uma base abrangente para o aprendizado contínuo e a otimização futura dos processos.
Este exemplo ilustra como todo o ecossistema lida com uma tarefa real de qualidade e enriquecimento de dados de ponta a ponta.
- Gatilho do evento: uma reclamação de usuário ou um monitor automatizado sinaliza um possível problema de qualidade de dados (por exemplo, uma cor incorreta do veículo) em uma página de descrição do veículo.
- Triagem e orquestração: um agente supervisor ingere o evento, cria uma tarefa rastreável e avalia sua prioridade com base em regras de negócios predefinidas.
- Delegação ao gerente: o supervisor delega a tarefa ao agente gerente de dados do veículo após confirmar suas permissões para acessar e modificar dados de veículos no Unity Catalog.
- Execução coordenada de tarefas: o agente gerente orquestra uma sequência de agentes executores especializados para resolver o problema: um agente de decodificação de VIN, um agente de recuperação de imagens para extrair fotos de nossa biblioteca de mídia, um agente de análise de cores baseado em AI para determinar a cor correta a partir das imagens e um agente de correção de dados para atualizar o banco de dados de fabricação do veículo.
- Revisão com intervenção humana (Human-in-the-Loop): antes que a alteração entre em vigor, o agente gerente sinaliza a alteração automatizada e notifica um curador de dados humano por meio de uma integração com o Slack para validação final.
- Aprendizado e encerramento: assim que o curador aprova a tarefa, o supervisor a marca como concluída. Toda a interação — incluindo a aprovação humana final — é rastreada e registrada na memória de longo prazo para aprendizado e auditoria futuros.
Análise profunda 2: assistente de conhecimento: respostas em tempo real, voz de marca confiável
Onde antes os clientes navegavam por vários dashboards da Edmunds ou entravam em contato com o suporte da Edmunds para obter respostas, o assistente de conhecimento agora oferece respostas conversacionais instantâneas, aproveitando todo o espectro de dados da Edmunds. Esse agente RAG é ajustado ao tom de voz da marca Edmunds, reunindo insights de avaliações de especialistas e consumidores, especificações de veículos, mídia e preços em tempo real. Como resultado, os clientes experimentam interações mais rápidas e satisfatórias, e a equipe de suporte gasta menos tempo respondendo a solicitações básicas.
Os principais recursos incluem:
- Personificação da voz da marca: O agente é meticulosamente ajustado para se comunicar na voz viva, prestativa e confiável que os clientes da Edmunds conhecem há décadas.
- Síntese de dados em tempo real: Em uma única consulta, o Assistente pode recuperar, sintetizar e apresentar informações de nossas fontes de dados distintas em tempo real, incluindo avaliações de especialistas e consumidores, especificações de veículos, conteúdo de vídeo transcrito e os preços e incentivos mais recentes.
- Recursos avançados de RAG: Estamos trabalhando ativamente com a Databricks usando o AI Search para expandir os limites da nossa implementação de RAG. Focamos em aprimorar a priorização de novidade do conteúdo e a filtragem sofisticada de metadados para garantir que as informações mais relevantes e oportunas sejam sempre apresentadas primeiro.
Análise detalhada 3: Fluxo de trabalho "Gerar e criticar" do DataDave
O DataDave agora lida com análises complexas que antes dependiam de um trabalho manual demorado. Este agente orquestra um fluxo de trabalho rigoroso, com cada etapa criticada por um agente especialista, para entregar 95% de precisão nas consultas mais desafiadoras. O DataDave pode identificar oportunidades de forma proativa (como sinalizar concessionárias subatendidas para a equipe de vendas da Edmunds) sintetizando o tráfego do site e dados demográficos. Isso capacita a liderança da Edmunds a passar com confiança do relatório de “o que aconteceu” para a decisão de “o que devemos fazer a seguir”.
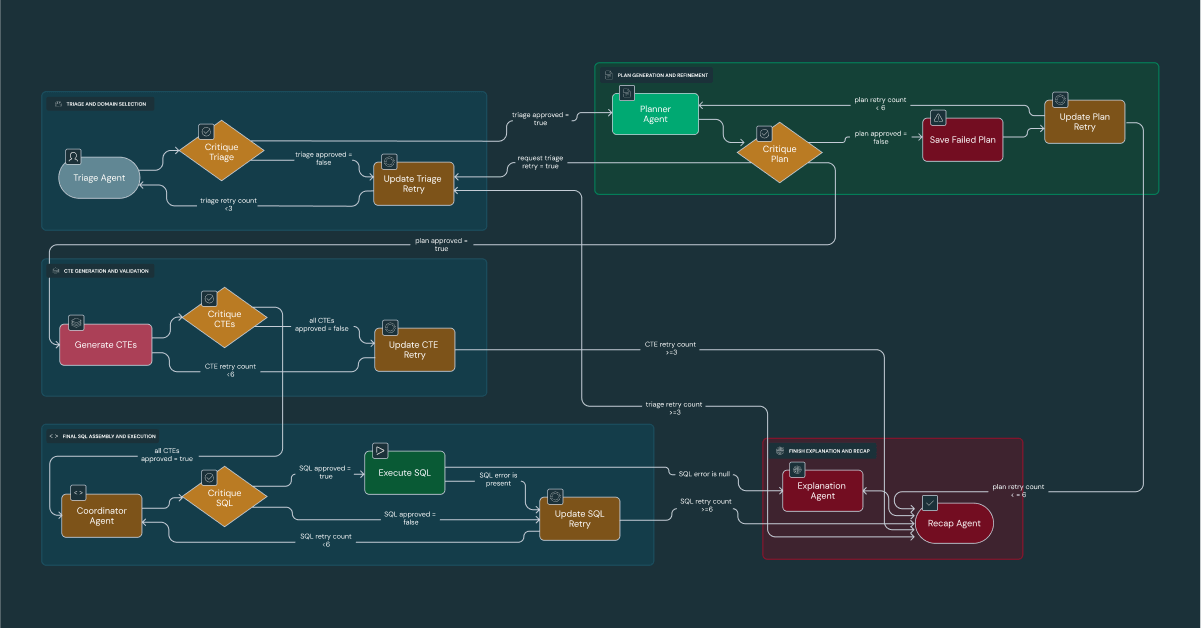
O fluxo de trabalho interno é um processo de cinco fases de Triagem, Planejamento, Geração de Código, Execução e Síntese, com um agente de Crítica dedicado validando a saída de cada fase. Além de simplesmente analisar métricas internas, o verdadeiro poder do DataDave está em sua capacidade de sintetizar nossos dados proprietários com conhecimento geral do mundo para gerar recomendações estratégicas. Por exemplo, ao correlacionar os dados de tráfego do site da Edmunds com dados geográficos e demográficos, o DataDave pode identificar concessionárias em áreas subatendidas e recomendá-las proativamente à nossa equipe de vendas como "oportunidades fáceis de alcançar".
Análise detalhada 4: Especialização em precificação
Na Edmunds, operamos com base em um princípio fundamental: o preço não é apenas um número; é uma conclusão que exige contexto e justificativa para ser confiável. Aproveitando nossa reputação de ter a precificação mais precisa do mercado dos EUA, nossa arquitetura de agentes foi projetada para oferecer essa confiança em escala.
Nossa experiência de evoluir um "Especialista em Precificação" monolítico para uma equipe coordenada de especialistas demonstra esse princípio. Essa equipe — orquestrada por um Agente Gerente e incluindo especialistas como um Agente de Valor Real de Mercado, um Agente de Depreciação e um Agente de Classificação de Ofertas — produz mais do que apenas um preço sugerido. O resultado final é um histórico de precificação abrangente e contextualizado que explica por que um veículo é avaliado de determinada maneira.
Isso transforma a função de nossos analistas de precificação, passando da agregação manual de dados para a supervisão e orientação estratégica. Ao aproveitar o Databricks Agent Bricks, nossos estatísticos de precificação podem configurar essas equipes hierárquicas de agentes com pouca codificação, aumentando drasticamente sua produtividade e reduzindo os custos de manutenção. Isso os capacita a focar no que realmente importa: o "porquê" por trás dos números.
O núcleo cognitivo: uma arquitetura para inteligência cumulativa
Nossa jornada em direção a um ecossistema de AI verdadeiramente inteligente começou com um desafio prático. Ao implantar agentes especialistas como o DataDave para análise de negócios, descobrimos que eles estavam revelando verdades comerciais críticas e urgentes que permaneciam isoladas em seu contexto operacional. Por exemplo, um agente pode detectar uma tendência de queda anômala em um canal de marketing importante, mas esse insight vital precisa ser comunicado de forma eficaz a outras entidades, tanto agentes quanto humanos, para acionar uma resposta coordenada. Isso destacou uma necessidade fundamental: um sistema de memória compartilhada que pudesse capturar esses aprendizados emergentes e torná-los acessíveis como entrada para todo o sistema de agentes. Visualizamos uma camada cognitiva onde esse conhecimento pudesse se acumular, crescer e ser aproveitado para tornar todo o nosso ecossistema progressivamente mais inteligente. Consequentemente, nossa linha de pensamento e design mais recente é a seguinte.
- Memória episódica ("O que aconteceu"): Um registro de alta fidelidade de cada ação e observação do agente, servindo como a verdade fundamental do sistema.
- Memória semântica ("O que foi aprendido"): Um índice vetorial contendo insights generalizados e estratégias bem-sucedidas sintetizadas a partir de eventos episódicos. Esta será a biblioteca de conhecimento acionável.
- Consolidação automatizada de memória: Um agente "Reflector" em segundo plano analisa periodicamente a memória episódica para identificar e consolidar os principais aprendizados na memória semântica.
- Acesso hierárquico à memória: Agentes de nível superior podem acessar as memórias de seus subordinados, permitindo que um Agente Gerente analise o desempenho da equipe e otimize estratégias futuras. Esse ciclo de feedback é central para a antifragilidade do nosso sistema; cada nova falha escalada pela hierarquia não é apenas um problema a ser resolvido, mas um sinal que treina todo o ecossistema, tornando-o progressivamente mais inteligente e resiliente.
Implementação: mem0 + Databricks
Nossa implementação será baseada no Databricks AI Search usando um Delta Sync Index, que é totalmente compatível com a interface mem0. Dado que o mem0 interage com bancos de dados vetoriais, inovaremos ao armazenar memórias episódicas e semânticas em um único back-end poderoso. Eventos brutos e não resumidos ("o que aconteceu") e aprendizados sintetizados ("o que foi aprendido") coexistirão como tipos de vetores distintos na mesma tabela Delta de origem, que então preenche de forma contínua e automática o índice do AI Search.
Essa arquitetura unificada cria um fluxo de trabalho eficiente. O agente Reflector pode consultar o índice em busca de entradas episódicas recentes, realizar sua síntese e gravar os novos vetores semânticos generalizados de volta na tabela Delta de origem. O Delta Sync Index então ingere automaticamente esses novos aprendizados, tornando-os disponíveis para consulta. Ao aproveitar a tabela Delta de origem como o único ponto de entrada, eliminamos a complexidade do pipeline de dados e obtemos a base escalável, serverless e de baixa latência necessária para um sistema de agentes verdadeiramente inteligente.
Exemplo de fluxo de trabalho com o Edmunds Pulse
- Registro: O agente 'DataDave' detecta uma anomalia de vendas e registra o evento em sua Memória Episódica por meio da API mem0. Essa ação grava uma nova entrada de vetor em nossa tabela Delta de origem.
- Síntese: O agente Reflector processa esse evento, gera um insight generalizado (por exemplo, "queda nas vendas do Produto X nos fins de semana") e o converte em um embedding vetorial.
- Indexação: O novo insight é gravado de volta na tabela Delta de origem, mas sinalizado como um aprendizado sintetizado. O Databricks AI Search sincroniza automaticamente essa nova entrada, indexando-a na memória semântica.
- Entrega: Por fim, um agente dedicado do Edmunds Pulse, que monitora constantemente a memória semântica em busca de inteligência de alta prioridade, entrega proativamente essa descoberta sintetizada a uma parte interessada humana. Traçando um paralelo com o lançamento do ChatGPT Pulse, que visa fornecer um assistente de AI mais ambiente e consciente, nosso Edmunds Pulse funcionará como o 'pulso' ao vivo dos negócios, garantindo que os insights críticos não sejam apenas armazenados, mas comunicados ativamente para impulsionar ações oportunas e inteligentes.
A camada de dados e conhecimento: uma base governada de verdade
Os agentes de AI dependem da qualidade de seus dados. A camada de dados da Edmunds foi desenvolvida especificamente para consistência, governança e flexibilidade, com o Unity Catalog servindo como a pedra angular para garantir que todas as informações permaneçam precisas e bem gerenciadas.
Análise detalhada 5: Acesso a dados GraphQL e padrões de interatividade
O framework Model Context Protocol (MCP) da Edmunds conecta com segurança agentes de AI ao contexto em tempo real de todas as principais fontes de dados, como especificações de veículos, avaliações, inventário e métricas operacionais de sistemas como o New Relic. Isso é alcançado por meio de um gateway de API GraphQL unificado, que abstrai a complexidade subjacente e oferece um esquema fortemente tipado e autodocumentado.
Em vez de agentes ou engenheiros lidarem com dados fragmentados, esquemas incompatíveis ou solução de problemas lenta, o sistema agora oferece suporte a três padrões principais de interatividade, cada um ajustado para um caso de uso diferente:
- Introspecção dinâmica de esquema: os agentes podem explorar dinamicamente consultas novas ou desconhecidas por meio da introspecção do próprio esquema GraphQL. Quando um cliente faz uma pergunta exclusiva — como se o valor de um carro é afetado por recalls de segurança recentes —, o agente pode descobrir novos tipos de dados na hora e criar consultas precisas para buscar as respostas relevantes. Essa flexibilidade permite que a organização se adapte rapidamente a novos requisitos de negócios sem a necessidade de alterações manuais de API.
- Ferramentas mapeadas granulares: cada ferramenta do agente é mapeada diretamente para uma consulta ou mutação GraphQL específica para operações de rotina. Por exemplo, atualizar a cor de um veículo é tão simples quanto extrair o VIN e a nova cor, com o agente lidando com a mutação. Essa abordagem aumenta a confiabilidade e reduz a intervenção manual, otimizando as tarefas diárias da equipe.
- Consultas persistentes: funções de alto tráfego e críticas para o desempenho, como painéis de inventário em tempo real, aproveitam consultas pré-registradas para obter o máximo de eficiência. O agente envia um hash leve e variáveis, e o sistema retorna os resultados instantaneamente com menor consumo de largura de banda e maior segurança.
A Edmunds melhorou drasticamente a velocidade, a flexibilidade e a confiabilidade das operações de dados em funções de produto e suporte, oferecendo aos agentes de AI acesso estruturado a todos os dados de negócios por meio de uma camada de API única e robusta. Tarefas que antes exigiam desenvolvimento personalizado ou depuração entre equipes agora são resolvidas em tempo real, permitindo que clientes e equipes internas se beneficiem de insights mais ricos e respostas mais ágeis.
Análise profunda 6: as camadas semântica e de conhecimento
Essa camada crucial serve como ponte entre os dados brutos e a compreensão do agente. Ela abstrai a complexidade dos armazenamentos de dados subjacentes e enriquece os dados com o contexto de negócios, garantindo que os agentes operem em uma visão consistente, governada e compreensível do universo da Edmunds.
- Unity Catalog: a espinha dorsal da governança: no núcleo do nosso ecossistema de dados, o Unity Catalog oferece governança centralizada, segurança e linhagem para todos os ativos de dados e AI. Ele garante que cada dado acessado por um agente esteja sujeito a controles de acesso refinados e que sua jornada seja totalmente auditável, formando a base inegociável para uma plataforma de AI segura e em conformidade.
- Camada semântica do produto: contexto de negócios em tempo real: essa camada fornece aos agentes uma visão orientada a objetos e em tempo real de nossas principais entidades de produtos (por exemplo, veículos, concessionárias, avaliações). Crucialmente, ela é originada diretamente dos mesmos esquemas GraphQL que alimentam o site da Edmunds. Isso garante consistência absoluta; quando um agente discute um "veículo", ele está fazendo referência ao mesmo modelo de dados e lógica de negócios que o consumidor vê no site, eliminando qualquer risco de desvio de dados entre nossos produtos externos e nossa AI interna.
- Camada semântica analítica: a única fonte da verdade para KPIs: essa camada fornece uma visão consistente e confiável de todas as métricas de desempenho de negócios. Ela é obtida diretamente de nossas Delta Metric Views selecionadas, que é a mesma fonte que alimenta todos os painéis executivos e operacionais. Esse alinhamento garante que, quando o DataDave ou outros agentes gerarem relatórios sobre KPIs de negócios (como tráfego de sessão, leads ou taxas de avaliação), eles usem definições e fontes de dados idênticas às de nossas ferramentas de business intelligence estabelecidas, garantindo uma única fonte da verdade em toda a organização.
- Databricks AI Search - O mecanismo para RAG: este componente é o mecanismo de recuperação de alto desempenho para nossos dados não estruturados e semiestruturados. Ao converter nosso vasto corpus de avaliações, artigos e conteúdo transcrito em embeddings vetoriais, permitimos que agentes como o Knowledge Assistant realizem buscas semânticas extremamente rápidas, recuperando o contexto mais relevante para responder às consultas dos usuários em um padrão de Geração Aumentada de Recuperação (RAG).
De centro de custo a mecanismo de valor: medindo o ROI de nossa AI
Uma arquitetura visionária só é tão boa quanto sua execução. Nossa abordagem se baseia em um roteiro em fases e em um compromisso profundo de tratar nosso ecossistema de AI como um mecanismo central de geração de valor. Alcançamos isso vinculando diretamente nossa estrutura técnica de observabilidade, governança e ética aos principais resultados de negócios. Nosso objetivo não é apenas criar uma AI poderosa; é quantificar seu impacto em nossos resultados financeiros.
Acelerando a velocidade dos negócios
Criamos um sistema holístico para medir os dois lados da equação do ROI. Do lado do retorno, nossa estrutura conecta o desempenho da AI diretamente aos KPIs de negócios. Por exemplo:
- Nosso agente DataDave fornece análises complexas e acionáveis em minutos, uma tarefa que antes levava horas para os analistas humanos da Edmunds concluírem. Isso acelera drasticamente a tomada de decisões orientada por dados.
- Nossos agentes de precificação respondem instantaneamente às consultas, eliminando horas de pesquisa manual e liberando nossas equipes para se concentrarem em trabalhos estratégicos e de alto valor.
Embora ainda estejamos quantificando o impacto preciso em métricas como taxas de conversão de campanha, essa estrutura fornece os dados em tempo real necessários para estabelecer essas correlações.
Otimização de custos
Praticamos uma governança econômica inteligente por meio do nosso AI Gateway. Agentes de alta responsabilidade, como o DataDave, são direcionados para nossos modelos mais poderosos para garantir a precisão, enquanto as tarefas de rotina são atribuídas automaticamente a modelos mais econômicos. Essa estratégia de camadas de modelos nos permite gerenciar com precisão nossos gastos com LLM e computação, garantindo que cada dólar investido esteja alinhado ao valor de negócios que ele gera.
“A Databricks nos permite executar o modelo certo para a tarefa certa, de forma segura e em escala. Essa flexibilidade potencializa nossos agentes e oferece experiências mais inteligentes de compra de carros.” —Greg Rokita, VP de Tecnologia, Edmunds
Capacitação organizacional: empoderando todos os funcionários
Para dar vida a essa visão, estamos promovendo uma cultura de inovação em toda a Edmunds. Nosso objetivo é apoiar um espectro completo de interação entre humanos e AI, desde tarefas totalmente autônomas até revisões com supervisão humana (human-in-the-loop) e solução de problemas totalmente colaborativa.
Para apoiar isso, fornecemos um Agent SDK robusto para engenheiros e defendemos um movimento de "Desenvolvedor Cidadão" por meio de nossa plataforma Agent Bricks. Essa iniciativa foi iniciada com nossa conferência de tecnologia interna "AI Agents @ Edmunds" e é alimentada por uma guilda ativa de agentes de LLM, garantindo que cada funcionário tenha as ferramentas e o suporte para contribuir com nosso futuro impulsionado por AI.
O caminho a seguir: da inteligência proativa à verdadeira autonomia
Nossa jornada para nos tornarmos uma organização verdadeiramente nativa de AI é uma maratona, não uma corrida de velocidade. A arquitetura "Edmunds Mind" serve como nosso modelo para essa jornada, e seu próximo passo evolutivo é desenvolver agentes proativos que não apenas respondam a perguntas, mas também antecipem as necessidades dos negócios. Vislumbramos um futuro em que nossos agentes identifiquem oportunidades de mercado a partir de fluxos de dados em tempo real e forneçam insights estratégicos às partes interessadas antes mesmo que elas perguntem.
Por fim, nosso roteiro leva a um sistema no qual os agentes podem se auto-otimizar — propondo novas ferramentas, refinando mecanismos de crítica e até sugerindo melhorias arquitetônicas. Isso marca a transição de um sistema que simplesmente operamos para um verdadeiro parceiro cognitivo, evoluindo nossos papéis de operadores para supervisores, especialistas em ética e estrategistas de uma nova força de trabalho inteligente.
Saiba mais sobre como a Edmunds está criando uma experiência de compra de carros impulsionada por AI com a ajuda da Databricks.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.