Navegando na Migração de Oracle para Databricks: Dicas para uma Transição Suave
Estratégias, Ferramentas e Melhores Práticas para Transição para a Arquitetura Lakehouse
por Laurent Léturgez
- Entenda como a arquitetura Lakehouse se compara ao modelo tradicional de armazém de dados relacional do Oracle.
- Descubra como inventariar objetos de banco de dados e traduzir esquemas específicos do Oracle para formatos suportados pelo Databricks.
- Execute etapas pós-migração para validar a integridade dos dados, execute sistemas paralelos para testes de negócios e otimize o desempenho.
À medida que mais organizações adotam arquiteturas lakehouse, migrar de armazéns de dados legados como Oracle para plataformas modernas como Databricks tornou-se uma prioridade comum. Os benefícios - melhor escalabilidade, desempenho e eficiência de custos - são claros, mas o caminho para chegar lá nem sempre é direto.
Neste post, compartilharei estratégias práticas para navegar na migração de Oracle para Databricks, incluindo dicas para evitar armadilhas comuns e preparar seu projeto para um sucesso a longo prazo.
Entendendo as principais diferenças
Antes de discutir estratégias de migração, é importante entender as principais diferenças entre Oracle e Databricks - não apenas em tecnologia, mas também em diferenças arquitetônicas.
O modelo relacional da Oracle vs. a arquitetura lakehouse da Databricks
Os data warehouses da Oracle seguem um modelo relacional tradicional otimizado para cargas de trabalho estruturadas e transacionais. Databricks é uma solução perfeita para hospedar cargas de trabalho de data warehouse, independentemente do modelo de dados usado, semelhante a outros sistemas de gerenciamento de banco de dados como a Oracle. Em contraste, a Databricks é construída em uma arquitetura lakehouse, que combina a flexibilidade dos data lakes com o desempenho e a confiabilidade dos data warehouses.
Essa mudança altera como os dados são armazenados, processados e acessados, mas também desbloqueia novas possibilidades. Com o Databricks, as organizações podem:
- Apoie casos de uso modernos como aprendizado de máquina (ML), IA tradicional e IA generativa
- Aproveite a separação de armazenamento e computação, permitindo que várias equipes criem armazéns independentes enquanto acessam os mesmos dados subjacentes
- Quebrar silos de dados e reduzir a necessidade de pipelines ETL redundantes
Diferenças de dialetos SQL e processamento
Ambas as plataformas suportam SQL, mas existem diferenças na sintaxe, funções integradas e como as consultas são otimizadas. Essas variações precisam ser abordadas durante a migração para garantir compatibilidade e desempenho.
Processamento de dados e escalabilidade
O Oracle usa uma arquitetura baseada em linhas, escalonada verticalmente (com escalonamento horizontal limitado via Real Application Clusters). Databricks, por outro lado, usa o modelo distribuído do Apache Spark™, que suporta escalonamento horizontal e vertical em grandes conjuntos de dados.
O Databricks também trabalha nativamente com Delta Lake e Apache Iceberg, formatos de armazenamento em colunas otimizados para análises de alto desempenho em grande escala. Esses formatos suportam recursos como transações ACID, evolução de esquema e viagem no tempo, que são críticos para a construção de pipelines resilientes e escaláveis.
Etapas pré-migração (comuns a todas as migrações de armazém de dados)
Independentemente do seu sistema de origem, uma migração bem-sucedida começa com algumas etapas críticas:
- Inventário do seu ambiente: Comece catalogando todos os objetos de banco de dados, dependências, padrões de uso e fluxos de trabalho de ETL ou integração de dados. Isso fornece a base para entender o escopo e a complexidade.
- Análise dos padrões de fluxo de trabalho: Identifique como os dados fluem pelo seu sistema atual. Isso inclui cargas de trabalho em lote vs. streaming, dependências de carga de trabalho e qualquer lógica específica da plataforma que possa exigir redesign.
- Priorize e faça a migração em fases: Evite uma abordagem de "grande explosão". Em vez disso, divida sua migração em fases gerenciáveis com base em risco, impacto nos negócios e prontidão. Colabore com equipes da Databricks e parceiros de integração certificados para construir um plano realista e de baixo risco que esteja alinhado com seus objetivos e cronogramas.
Estratégias de migração de dados
Uma migração de dados bem-sucedida requer uma abordagem cuidadosa que aborde tanto as diferenças técnicas entre as plataformas quanto as características únicas dos seus ativos de dados. As seguintes estratégias ajudarão você a planejar e executar um processo de migração eficiente, maximizando os benefícios da arquitetura do Databricks.
Tradução e otimização de esquema
Evite copiar esquemas do Oracle diretamente sem repensar seu design para o Databricks. Por exemplo, o tipo de dados NUMBER do Oracle suporta maior precisão do que o permitido pelo Databricks (precisão máxima e escala de 38). Nesses casos, pode ser mais apropriado usar tipos DOUBLE em vez de tentar manter correspondências exatas.
Traduzir esquemas de forma cuidadosa garante compatibilidade e evita problemas de desempenho ou precisão de dados no futuro.
Para mais detalhes, confira o Guia de Migração de Oracle para Databricks.
Abordagens de extração e carregamento de dados
As migrações do Oracle geralmente envolvem a movimentação de dados de bancos de dados locais para o Databricks, onde a largura de banda e o tempo de extração podem se tornar gargalos. Sua estratégia de extração deve estar alinhada com o volume de dados, a frequência de atualização e a tolerância para tempo de inatividade.
Opções comuns incluem:
- Conexões JDBC – úteis para conjuntos de dados menores ou transferências de baixo volume
- Federação Lakehouse – para replicar data marts diretamente para Databricks
- Azure Data Factory ou AWS Database Migration Services – para movimentação de dados orquestrada em grande escala
- Ferramentas de exportação nativas do Oracle:
- DBMS_CLOUD.EXPORT_DATA (disponível no Oracle Cloud)
- Descarregamento do SQL Developer (para uso local ou on-premises)
- Configuração manual de DBMS_CLOUD em implantações Oracle 19.9+ locais
- Opções de transferência em massa - como AWS Snowball ou Microsoft Data Box, para mover grandes tabelas históricas para a nuvem
A escolha da ferramenta certa depende do tamanho dos seus dados, limites de conectividade e necessidades de recuperação.
Otimize para desempenho
Os dados migrados geralmente precisam ser remodelados para ter um bom desempenho no Databricks'. Isso começa com a reavaliação de como os dados são particionados.
Se o seu armazém de dados Oracle usava partições estáticas ou desbalanceadas, essas estratégias podem não se traduzir bem. Analise seus padrões de consulta e reestruture as partições de acordo. O Databricks oferece várias técnicas para melhorar o desempenho:
- Agrupamento Líquido Automático para otimização contínua sem ajuste manual
- Z-Ordering para agrupamento em colunas frequentemente filtradas
- Agrupamento Líquido para organizar dinamicamente os dados
Além disso:
- Comprima arquivos pequenos para reduzir sobrecarga
- Separe dados quentes e frios para otimizar custo e eficiência de armazenamento
- Evite a super-partição, que pode retardar as varreduras e aumentar a sobrecarga de metadados
Por exemplo, a partição baseada em datas de transação que resulta em distribuição de dados desigual pode ser reequilibrada usando o Agrupamento Líquido Automático, melhorando o desempenho para consultas baseadas em tempo.
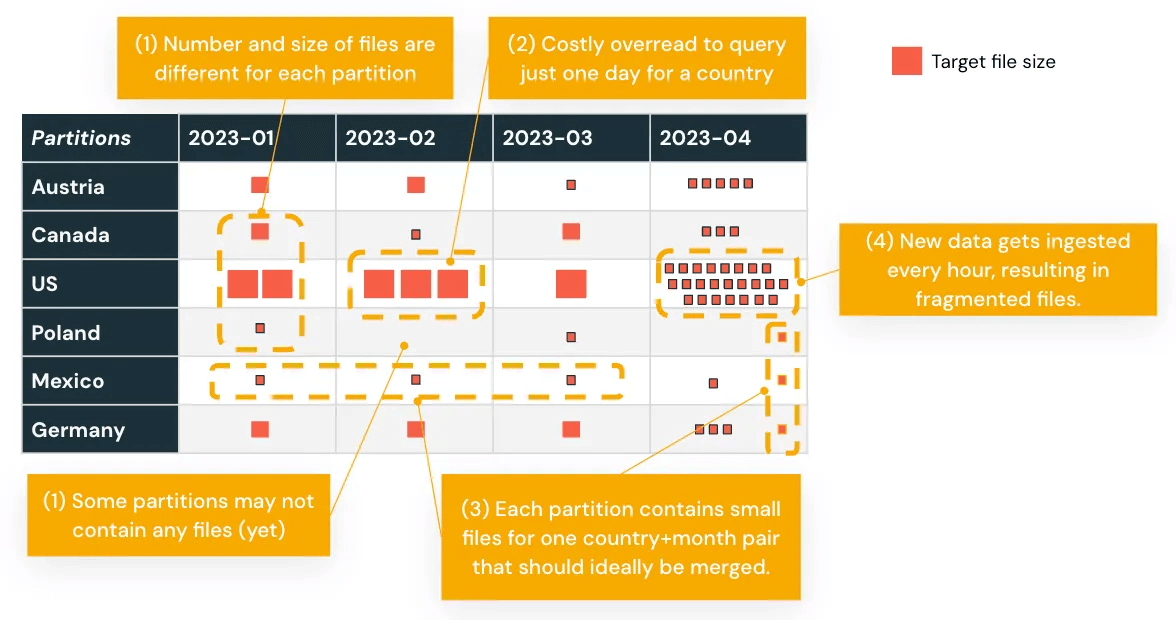
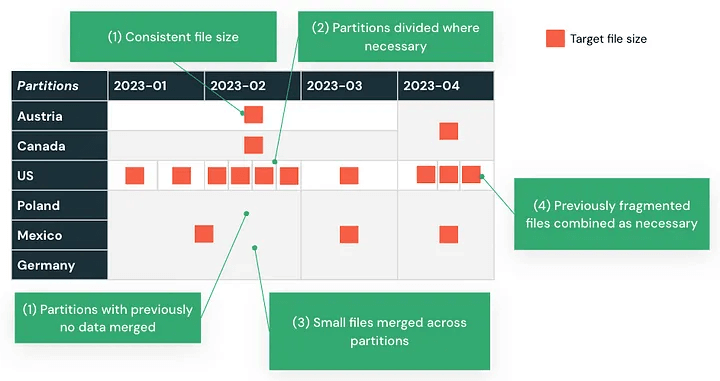
Projetar com o modelo de processamento do Databricks em mente garante que suas cargas de trabalho escalem de forma eficiente e permaneçam gerenciáveis após a migração.
Migração de código e lógica
Embora a migração de dados forme a base da sua transição, mover a lógica do seu aplicativo e o código SQL representa um dos aspectos mais complexos da migração de Oracle para Databricks. Este processo envolve a tradução de sintaxe e a adaptação a diferentes paradigmas de programação e técnicas de otimização que se alinham com o modelo de processamento distribuído do Databricks.
Estratégias de tradução SQL
Converta SQL Oracle para SQL Databricks usando uma abordagem estruturada. Ferramentas automatizadas como BladeBridge (agora parte do Databricks) podem analisar a complexidade do código e realizar tradução em massa. Dependendo do código, as taxas de conversão típicas são de cerca de 75% ou mais.
Essas ferramentas ajudam a reduzir o esforço manual e identificar áreas que requerem retrabalho ou mudanças arquitetônicas após a migração.
Migração de procedimentos armazenados
Evite tentar encontrar substituições exatas um-para-um para as construções PL/SQL do Oracle. Pacotes como DBMS_X, UTL_X e CTX_X não existem no Databricks e exigirão a reescrita da lógica para se adequar à plataforma.
Para construções comuns como:
- Cursores
- Tratamento de exceções
- Laços e declarações de controle de fluxo
O Databricks agora oferece Scripting SQL, que suporta SQL procedural em notebooks. Alternativamente, considere converter esses fluxos de trabalho para Python ou Scala dentro de Fluxos de trabalho do Databricks ou Pipelines DLT, que oferecem maior flexibilidade e integração com processamento distribuído.
BladeBridge pode ajudar a traduzir essa lógica para SQL Databricks ou notebooks PySpark como parte da migração.
Transformação de fluxo de trabalho ETL
Databricks oferece várias abordagens para construir processos de ETL que simplificam o ETL Oracle legado:
- Notebooks Databricks com parâmetros - para tarefas ETL simples e modulares
- DLT - para definir pipelines de forma declarativa com suporte para processamento em lote e streaming, processamento incremental e verificações de qualidade de dados integradas
- Fluxos de trabalho Databricks - para agendamento e orquestração dentro da plataforma
Essas opções dão às equipes flexibilidade na refatoração e operação do ETL pós-migração, alinhando-se com os padrões modernos de engenharia de dados.
Pós-migração: validação, otimização e adoção
Valide com testes técnicos e de negócios
Após um caso de uso ter sido migrado, é crucial validar que tudo funciona conforme o esperado, tanto tecnicamente quanto funcionalmente.
- Validação técnica deve incluir:
- Contagem de linhas e reconciliação de agregados entre sistemas
- Verificações de completude e qualidade dos dados
- Comparação de resultados de consultas entre plataformas de origem e destino
- Validação de negócios envolve a execução de ambos os sistemas em paralelo e a confirmação dos stakeholders de que as saídas correspondem às expectativas antes da transição.
Otimizar para custo e desempenho
Após a validação, avalie e ajuste o ambiente com base nas cargas de trabalho reais. As áreas de foco incluem:
- Estratégias de particionamento e agrupamento (por exemplo, Z-Ordering, Liquid Clustering)
- Otimização do tamanho e formato do arquivo
- Configuração de recursos e políticas de escalabilidade. Esses ajustes ajudam a alinhar a infraestrutura com os objetivos de desempenho e as metas de custo.
Transferência de conhecimento e prontidão organizacional
Uma migração bem-sucedida não termina com a implementação técnica. Garantir que as equipes possam usar a nova plataforma efetivamente é tão importante.
- Planeje treinamento prático e documentação
- Permita que as equipes adotem novos fluxos de trabalho, incluindo desenvolvimento colaborativo, lógica baseada em notebook e pipelines declarativos
- Atribuir propriedade para qualidade de dados, governança e monitoramento de desempenho no novo sistema
A migração é mais do que uma mudança técnica
Migrar do Oracle para o Databricks não é apenas uma troca de plataforma - é uma mudança na forma como os dados são gerenciados, processados e consumidos.
Um planejamento cuidadoso, execução faseada e coordenação próxima entre as equipes técnicas e os stakeholders do negócio são essenciais para reduzir o risco e garantir uma transição suave.
Igualmente importante é preparar sua organização para trabalhar de maneira diferente: adotando novas ferramentas, novos processos e uma nova mentalidade em torno de análises ou IA. Com um foco equilibrado tanto na implementação quanto na adoção, sua equipe pode desbloquear todo o valor de uma arquitetura moderna de lakehouse.
O que fazer a seguir
A migração raramente é simples. Compromissos, atrasos e desafios inesperados fazem parte do processo, especialmente ao alinhar pessoas, processos e tecnologia.
É por isso que é importante trabalhar com equipes que já fizeram isso antes. Databricks Professional Nossos serviços e nossos parceiros de migração certificados trazem vasta experiência na entrega de migrações de alta qualidade no prazo e em escala. Entre em contato conosco para iniciar sua avaliação de migração.
Procurando mais orientações? Baixe o completo Guia de Migração de Oracle para Databricks para etapas práticas, insights de ferramentas e modelos de planejamento para ajudá-lo a mover com confiança.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.