Navigating the Oracle to Databricks Migration: Tips for a Seamless Transition
Strategies, Tools, and Best Practices for Transitioning to the Lakehouse Architecture
- Understand how Lakehouse architecture compares to Oracle’s traditional relational data warehouse model.
- Discover how to inventory database objects and translate Oracle-specific schemas to Databricks-supported formats.
- Execute post-migration steps to validate data integrity, run parallel systems for business testing, and optimize performance.
As more organizations adopt lakehouse architectures, migrating from legacy data warehouses like Oracle to modern platforms like Databricks has become a common priority. The benefits—better scalability, performance, and cost efficiency—are clear, but the path to get there isn’t always straightforward.
In this post, I’ll share practical strategies for navigating the migration from Oracle to Databricks, including tips for avoiding common pitfalls and setting your project up for long-term success.
Understanding the key differences
Before discussing migration strategies, it’s important to understand the core differences between Oracle and Databricks—not just in technology but also in architectural differences.
Oracle's relational model vs. Databricks’ lakehouse architecture
Oracle data warehouses follow a traditional relational model optimized for structured, transactional workloads. Databricks is a perfect solution for hosting data warehouse workloads, regardless of the data model used, similar to other database management systems like Oracle. In contrast, Databricks is built on a lakehouse architecture, which merges the flexibility of data lakes with the performance and reliability of data warehouses.
This shift changes how data is stored, processed, and accessed—but also unlocks entirely new possibilities. With Databricks, organizations can:
- Support modern use cases like machine learning (ML), traditional AI, and generative AI
- Leverage the separation of storage and compute, enabling multiple teams to spin up independent warehouses while accessing the same underlying data
- Break down data silos and reduce the need for redundant ETL pipelines
SQL dialects and processing differences
Both platforms support SQL, but there are differences in syntax, built-in functions, and how queries are optimized. These variations need to be addressed during the migration to ensure compatibility and performance.
Data processing and scaling
Oracle uses a row-based, vertically scaled architecture (with limited horizontal scaling via Real Application Clusters). Databricks, on the other hand, uses Apache Spark™’s distributed model, which supports both horizontal and vertical scaling across large datasets.
Databricks also works natively with Delta Lake and Apache Iceberg, columnar storage formats optimized for high-performance, large-scale analytics. These formats support features like ACID transactions, schema evolution, and time travel, which are critical for building resilient and scalable pipelines.
Pre-migration steps (common to all data warehouse migrations)
Regardless of your source system, a successful migration starts with a few critical steps:
- Inventory your environment: Begin by cataloging all database objects, dependencies, usage patterns, and ETL or data integration workflows. This provides the foundation for understanding scope and complexity.
- Analyze workflow patterns: Identify how data flows through your current system. This includes batch vs. streaming workloads, workload dependencies, and any platform-specific logic that may require redesign.
- Prioritize and phase your migration: Avoid a “big bang” approach. Instead, break your migration into manageable phases based on risk, business impact, and readiness. Collaborate with Databricks teams and certified integration partners to build a realistic, low-risk plan that aligns with your goals and timelines.
Data migration strategies
Successful data migration requires a thoughtful approach that addresses both the technical differences between platforms and the unique characteristics of your data assets. The following strategies will help you plan and execute an efficient migration process while maximizing the benefits of Databricks’ architecture.
Schema translation and optimization
Avoid copying Oracle schemas directly without rethinking their design for Databricks. For example, Oracle’s NUMBER data type supports greater precision than what Databricks allows (maximum precision and scale of 38). In such cases, it may be more appropriate to use DOUBLE types instead of trying to retain exact matches.
Translating schemas thoughtfully ensures compatibility and avoids performance or data accuracy issues down the line.
For more details, check out the Oracle to Databricks Migration Guide.
Data extraction and loading approaches
Oracle migrations often involve moving data from on-premises databases to Databricks, where bandwidth and extraction time can become bottlenecks. Your extraction strategy should align with data volume, update frequency, and tolerance for downtime.
Common options include:
- JDBC connections – useful for smaller datasets or low-volume transfers
- Lakehouse Federation – for replicating data marts directly to Databricks
- Azure Data Factory or AWS Database Migration Services – for orchestrated data movement at scale
- Oracle-native export tools:
- DBMS_CLOUD.EXPORT_DATA (available on Oracle Cloud)
- SQL Developer unload (for on-premises or local usage)
- Manual setup of DBMS_CLOUD on Oracle 19.9+ on premises deployments
- Bulk transfer options – such as AWS Snowball or Microsoft Data Box, to move large historical tables into the cloud
Choosing the right tool depends on your data size, connectivity limits, and recovery needs.
Optimize for performance
Migrated data often needs to be reshaped to perform well in Databricks'. This starts with rethinking how data is partitioned.
If your Oracle data warehouse used static or unbalanced partitions, those strategies may not translate well. Analyze your query patterns and restructure partitions accordingly. Databricks offers several techniques to improve performance:
- Automatic Liquid Clustering for ongoing optimization without manual tuning
- Z-Ordering for clustering on frequently filtered columns
- Liquid Clustering to dynamically organize data
Additionally:
- Compress small files to reduce overhead
- Separate hot and cold data to optimize cost and storage efficiency
- Avoid over-partitioning, which can slow down scans and increase metadata overhead
For example, partitioning based on transaction dates that results in uneven data distribution can be rebalanced using Automatic Liquid Clustering, improving performance for time-based queries.
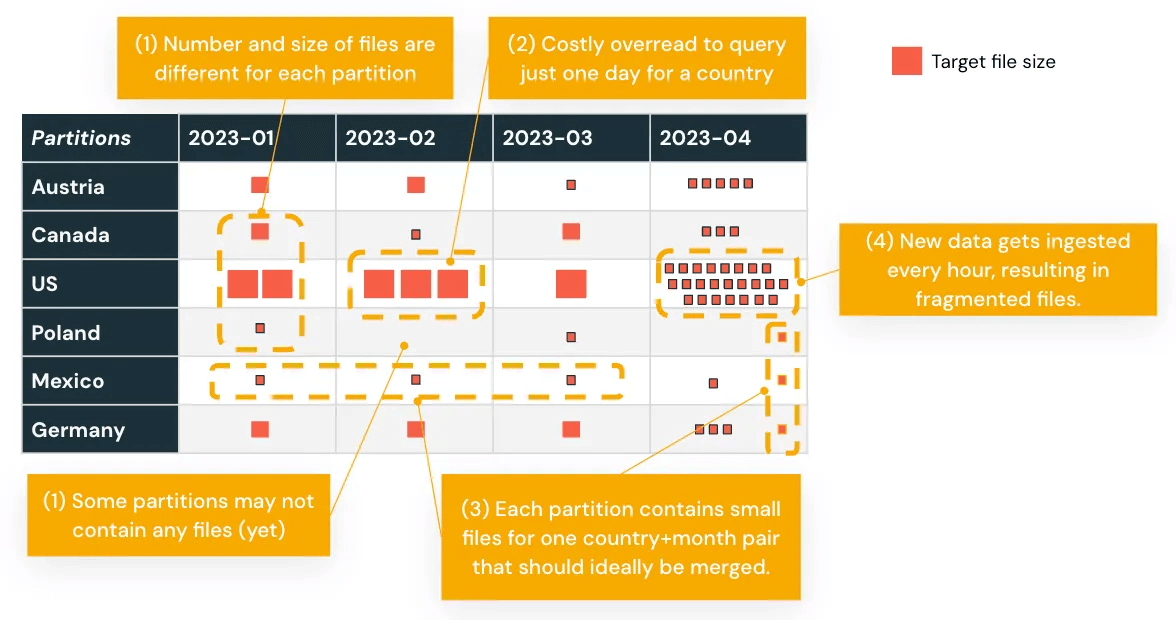
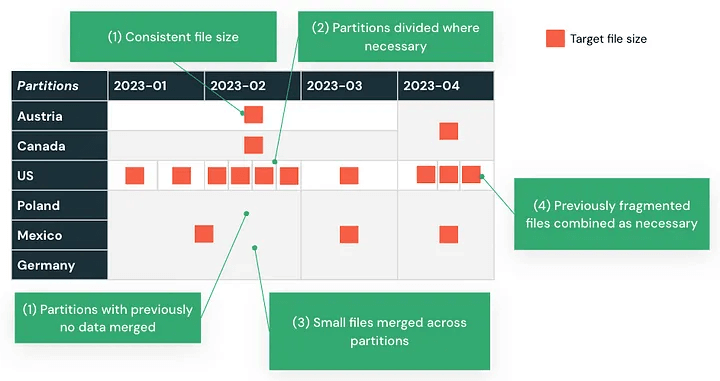
Designing with Databricks' processing model in mind ensures that your workloads scale efficiently and remain maintainable post-migration.
Code and logic migration
While data migration forms the foundation of your transition, moving your application logic and SQL code represents one of the most complex aspects of the Oracle to Databricks migration. This process involves translating syntax and adapting to different programming paradigms and optimization techniques that align with Databricks’ distributed processing model.
SQL translation strategies
Convert Oracle SQL to Databricks SQL using a structured approach. Automated tools like BladeBridge (now part of Databricks) can analyze code complexity and perform bulk translation. Depending on the codebase, typical conversion rates are around 75% or higher.
These tools help reduce manual effort and identify areas that require rework or architectural changes post-migration.
Stored procedures migration
Avoid trying to find exact one-to-one replacements for Oracle PL/SQL constructs. Packages like DBMS_X, UTL_X, and CTX_X don’t exist in Databricks and will require rewriting the logic to fit the platform.
For common constructs such as:
- Cursors
- Exception handling
- Loops and control flow statements
Databricks now offers SQL Scripting, which supports procedural SQL in notebooks. Alternatively, consider converting these workflows to Python or Scala within Databricks Workflows or DLT pipelines, which offer greater flexibility and integration with distributed processing.
BladeBridge can assist in translating this logic into Databricks SQL or PySpark notebooks as part of the migration.
ETL workflow transformation
Databricks offers several approaches for building ETL processes that simplify legacy Oracle ETL:
- Databricks Notebooks with parameters – for simple, modular ETL tasks
- DLT – to define pipelines declaratively with support for batch and streaming, incremental processing, and built-in data quality checks
- Databricks Workflows – for scheduling and orchestration within the platform
These options give teams flexibility in refactoring and operating post-migration ETL while aligning with modern data engineering patterns.
Post-migration: validation, optimization, and adoption
Validate with technical and business tests
After a use case has been migrated, it’s critical to validate that everything works as expected, both technically and functionally.
- Technical validation should include:
- Row count and aggregate reconciliation between systems
- Data completeness and quality checks
- Query result comparisons across source and target platforms
- Business validation involves running both systems in parallel and having stakeholders confirm that outputs match expectations before cutover.
Optimize for cost and performance
After validation, evaluate and fine-tune the environment based on actual workloads. Focus areas include:
- Partitioning and clustering strategies (e.g., Z-Ordering, Liquid Clustering)
- File size and format optimization
- Resource configuration and scaling policies. These adjustments help align infrastructure with performance goals and cost targets.
Knowledge transfer and organizational readiness
A successful migration doesn’t end with technical implementation. Ensuring that teams can use the new platform effectively is just as important.
- Plan for hands-on training and documentation
- Enable teams to adopt new workflows, including collaborative development, notebook-based logic, and declarative pipelines
- Assign ownership for data quality, governance, and performance monitoring in the new system
Migration is more than a technical shift
Migrating from Oracle to Databricks is not just a platform switch—it’s a shift in how data is managed, processed, and consumed.
Thorough planning, phased execution, and close coordination between technical teams and business stakeholders are essential to reduce risk and ensure a smooth transition.
Equally important is preparing your organization to work differently: adopting new tooling, new processes, and a new mindset around analytics or AI. With a balanced focus on both implementation and adoption, your team can unlock the full value of a modern lakehouse architecture.
Practical tips from Deloitte
Deloitte shared some practical tips in migrating from a legacy data warehouse to Databricks in this webinar. Check it out to hear how the migration worked at a global automotive finance company! Highlights include:
- implementing and modernizing the cloud analytics platform with cyber and PII privacy controls
- leveraging Databricks Unity Catalog metadata-driven framework to configure the ELT pipelines to store the data in the lakehouse
- integrating Databricks Workflows with ServiceNow for easy monitoring and failure handling
What to do next
Migration is rarely straightforward. Tradeoffs, delays, and unexpected challenges are part of the process, especially when aligning people, processes, and technology.
That’s why it’s important to work with teams that’ve done this before. Databricks Professional Services and our certified migration partners bring deep experience in delivering high-quality migrations on time and at scale. Contact us to start your migration assessment.
Looking for more guidance? Download the full Oracle to Databricks Migration Guide for practical steps, tooling insights, and planning templates to help you move with confidence.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.