Inferência de LLM Confiável em Escala
Lições da construção de infraestrutura de inferência de LLM confiável
por Ying Chen, Wendy Hu, Ankit Mathur, Mike Eastham, Pei-Lun Liao, Wai Wu e Arjun DCunha
- O serviço de LLM multilocatário exige raciocínio sobre a capacidade entre cargas de trabalho. "Unidades de modelo" fornecem uma abstração semelhante a VM que possibilita alocar, rotear e dimensionar recursos de GPU por cliente.
- O balanceamento de carga e o dimensionamento automático com reconhecimento de custo, baseados em unidades de modelo, economizaram mais de 80% nos custos de GPU em comparação com o provisionamento estático, mantendo as metas de latência.
- Mecanismos de confiabilidade de tempo de execução, como verificações de integridade de caixa preta, detectam e recuperam falhas silenciosas automaticamente, enquanto a otimização de gargalos multimodais desbloqueou ganhos de taxa de transferência 3x.
Na Databricks, criamos uma plataforma de inferência única que atende a todos os modelos de ponta, desde modelos de código aberto como Kimi e Qwen até modelos proprietários como OpenAI, Gemini e Claude. Potencializamos a inferência para algumas das maiores aplicações agentivas do mundo, incluindo Superhuman, Yipit Data, Fox Sports e outras. Hoje, atendemos mais de 120 trilhões de tokens por mês.
O que torna o serviço de LLM difícil em escala é a confiabilidade. Com os agentes se tornando a interface para como trabalhamos e vivemos, a demanda por inferência está crescendo exponencialmente. Vemos curvas de demanda extremamente voláteis que atingem o pico durante o horário de trabalho.
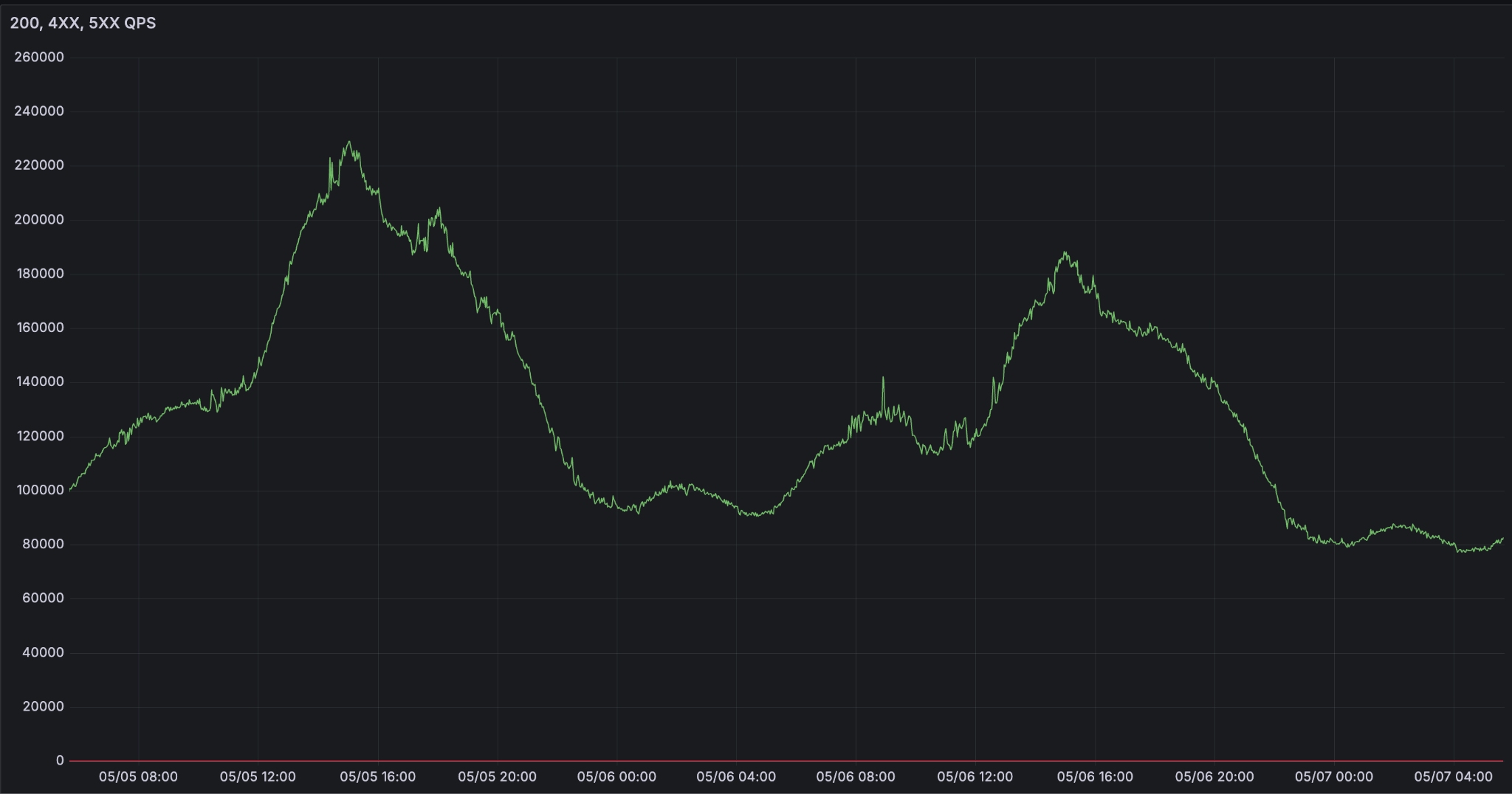
Desafios de executar inferência de LLM em escala
O que significa ser uma plataforma de inferência confiável? O contrato parece simples. Disponibilidade é se a solicitação pode ser processada. Mas, na prática, diferentes casos de uso têm requisitos de latência significativamente diferentes, e isso afeta a disponibilidade. Os agentes mais avançados não podem se dar ao luxo de ter a degradação do tempo de p95 para o primeiro token (TTFT) e tokens de saída por segundo (OPTS).
Em um sistema multilocatário para serviço de LLM, alcançar confiabilidade e latência é desafiador.
Confiabilidade
O desempenho de ponta requer as GPUs mais recentes com interconexão de alta largura de banda para transferência de cache KV. Essas configurações de computação são fundamentalmente menos confiáveis do que os sistemas clássicos de CPU e são caras. Dado que a comunicação de todos para todos é necessária, a inatividade de um único nó requer reconfiguração para vários outros nós em configurações de preenchimento/decodificação desagregadas. A rede de maior largura de banda requer conectividade single-spine em um único rack físico (por exemplo, sistemas NVL72). Isso significa que falhas em sistemas específicos dentro de um único rack de data center podem criar uma interrupção de amplo raio de impacto. Truques padrão em sistemas distribuídos, como multi-AZ ou o aproveitamento de tipos de instância de backup, significam manter GPUs de backup caras ociosas, uma opção proibitivamente cara. O provisionamento excessivo é outro truque clássico, mas como o suprimento de computação é tão restrito, é extremamente caro e impraticável. Assim, os sistemas devem permanecer operacionais sob forte pressão.
A velocidade de entrega também precisa permanecer alta sob essas restrições - nossa demanda de inferência cresceu várias ordens de magnitude ano a ano, e alimentar esse crescimento enquanto entregamos recursos inovadores foi desafiador. Recursos como imagens, vídeos e classificação de segurança exigem sistemas de pré-processamento diferentes, que devem escalar independentemente.
Finalmente, alcançar o melhor desempenho da categoria e suportar novas arquiteturas de modelos requer otimizações que abrangem desde kernels personalizados até motores de inferência proprietários. À medida que as arquiteturas mudam sutilmente, novos softwares de baixo nível são frequentemente introduzidos e podem falhar de maneiras opacas em escala, surgindo em cenários de depuração difíceis, que variam de travamentos de servidor a falhas de GPU.
Latência
Manter a latência sob controle com padrões de carga diversos é desafiador. Isso ocorre porque o custo para atender a uma solicitação é altamente variável e difícil de estimar a priori. Mesmo servidores saudáveis sob carga mais pesada processam todas as solicitações mais lentamente, expondo uma troca entre taxa de transferência (e, portanto, eficiência de custo) e a latência mais rápida que os produtos precisam para lidar. Isso também pode se manifestar como um problema de confiabilidade, pois os servidores podem entrar inesperadamente em estados não saudáveis muito rapidamente com base na mistura de solicitações atribuídas a eles.
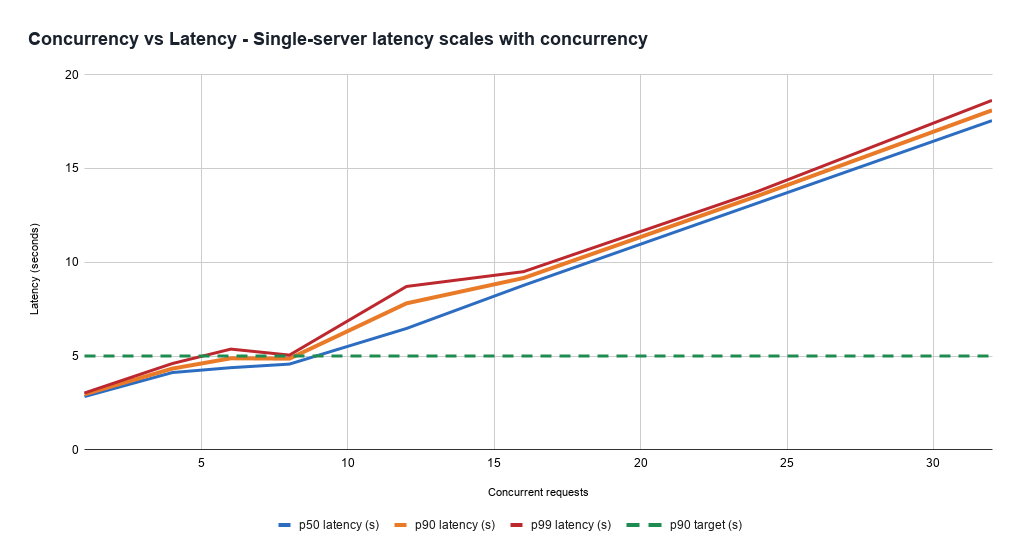
Além disso, a latência é dominada pela geração de tokens de saída, mas a estimativa inicial do custo é difícil, pois é complicado prever quanto tempo o modelo falará. Assim, o serviço de baixa latência requer gerenciamento complexo de capacidade, balanceamento de carga e sistemas de priorização de solicitações.
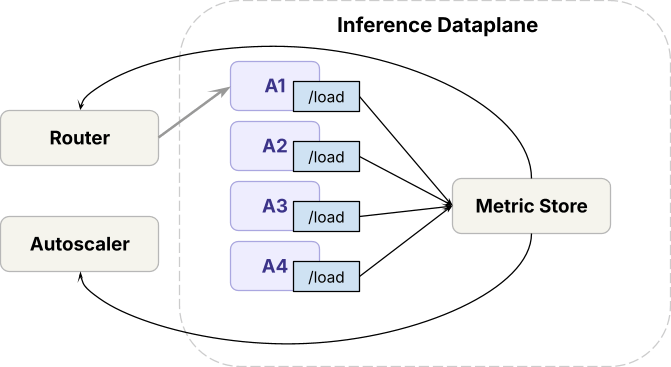
Arquitetura geral
Antes de mergulharmos nos detalhes de como abordar esses problemas, vamos percorrer uma visão geral de alto nível de nossa infraestrutura de serviço.
No plano de dados,
- O runtime de inferência (motores de código aberto e proprietários internos) é implantado em GPUs de ponta
- Para lidar com o tráfego entre implantações de modelos, o plano de dados executa um roteador, que chamamos de Axon, que balanceia a carga entre réplicas do mesmo modelo, e um autoscaler que ajusta as contagens de réplicas.
No plano de controle,
- As solicitações passam por limitação de taxa antes de chegar ao plano de dados.
- Com base nas métricas de solicitação, o algoritmo de gerenciamento de capacidade determina quanta capacidade de GPU cada carga de trabalho recebe, o que o autoscaler então impõe.
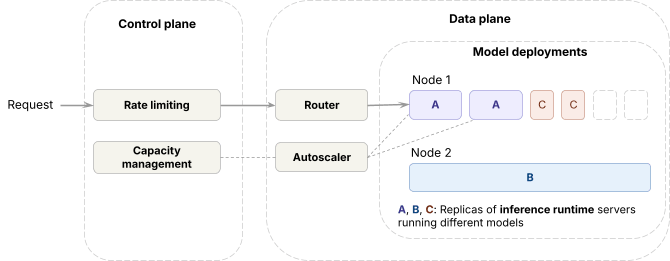
Obtendo controle da capacidade
Precisamos ser capazes de raciocinar aproximadamente sobre a capacidade - quanta temos, quanto vendemos e quanto os clientes estão usando. Para fazer isso, introduzimos uma abstração chamada "unidades de modelo". Se projetarmos que uma réplica pode processar um número fixo de unidades de modelo por minuto (por exemplo, 100), podemos fazer as seguintes suposições:
- Solicitações com entrada ou saída longa consomem mais unidades de modelo, pois menos podem ser concluídas na mesma janela de tempo.
- Prefill e decode têm características de taxa de transferência diferentes, portanto, solicitações com saída longa custam mais do que aquelas com entrada longa.
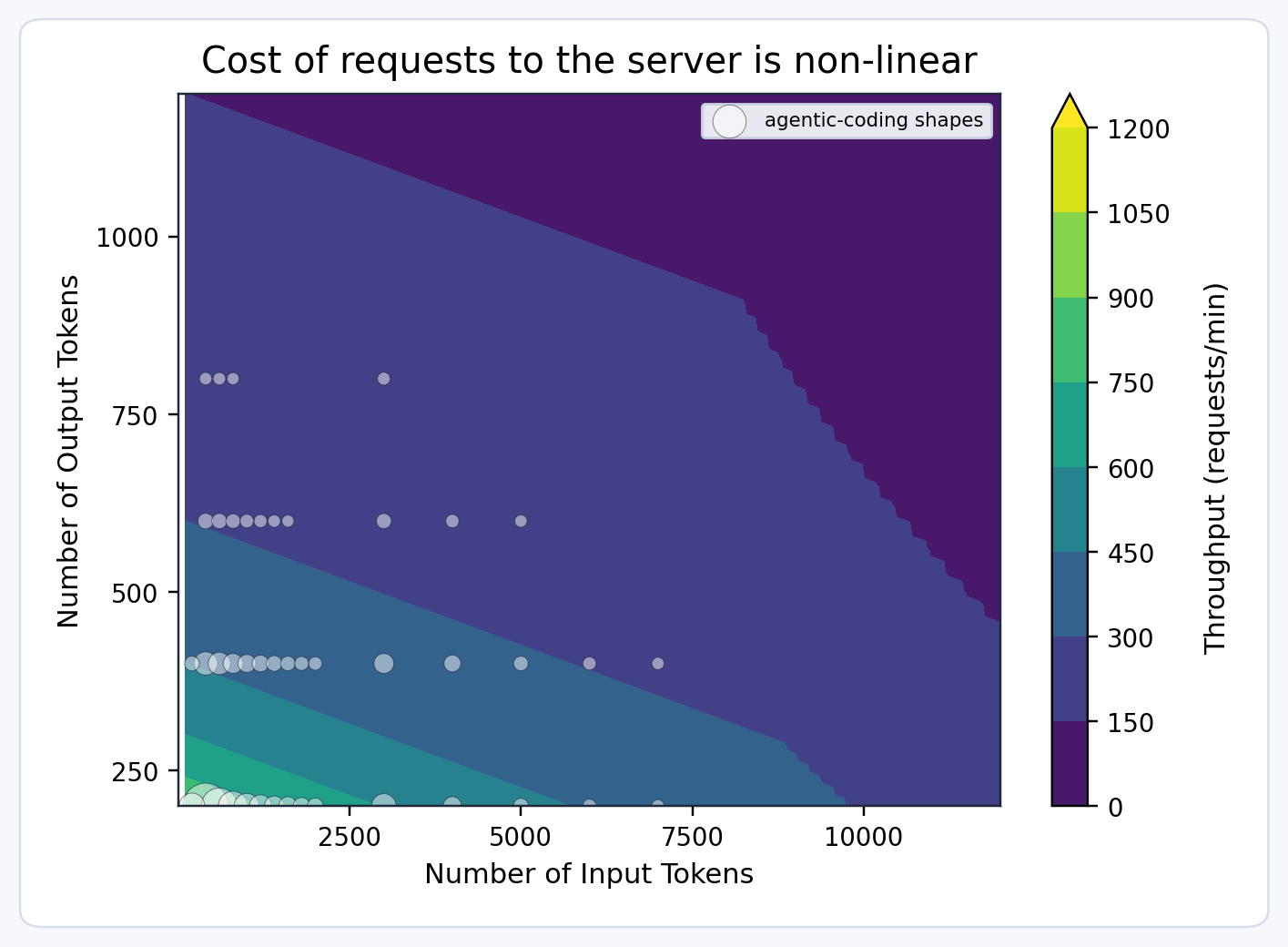
Portanto, modelamos o custo da solicitação usando uma função multidimensional como:
Os coeficientes α, β, γ são determinados por benchmarking automatizado para cada modelo em cada tipo de hardware. As unidades de modelo podem ser ajustadas ainda mais para otimizações como cache de prefixo, e elas devem levar em conta recursos como multimodalidade.
Tais estimativas são estruturalmente imperfeitas, mas servem como uma maneira de quebrarmos um sistema multilocatário em algo mais gerenciável que se assemelha a VMs na nuvem. As VMs têm a propriedade desejável de oferecer desempenho previsível que pode ser alocado a clientes específicos. Para cargas de trabalho agentivas de produção, é importante oferecer garantias em torno de baixa latência e capacidade, e sem tais sistemas de alocação, o melhor que podemos fazer é oferecer capacidade "melhor esforço" que pode ser recuperada se muitos clientes usarem o sistema.
Balanceamento de carga e escalonamento automático baseado em custo
Como as solicitações têm um impacto altamente variável nos servidores, é importante tomar decisões de roteamento quase ótimas. Em geral, o balanceamento de carga tende a se basear em abordagens estatísticas como P2C (poder de duas escolhas), que estimam a carga com base no tamanho da fila e utilizam amostragem para reduzir os sobrecargas de memória e latência de entender todos os destinos possíveis. No entanto, as latências de LLM tendem a ser altas, as contagens de servidores são menores do que os sistemas de CPU escalados, e o custo de roteamento incorreto é severo. Portanto, o serviço de LLM exige uma abordagem diferente.
Hoje, usamos Dicer, o auto-shard do Databricks, para rotear dinamicamente cargas de trabalho entre servidores. Sem roteamento ciente da carga, solicitações de contexto longo fazem com que servidores individuais se tornem hotspots enquanto outros ficam subutilizados. Integramos unidades de modelo com o Dicer para que as decisões de roteamento sejam baseadas na carga do servidor em unidades de modelo em vez de heurísticas tradicionais baseadas em solicitação. O Dicer também fornece sessões com estado, tornando o roteamento de solicitação fixo. As solicitações de uma carga de trabalho vão apenas para um subconjunto de servidores, o que melhora as taxas de acerto de cache (crucial para cargas de trabalho sensíveis à latência, como agentes de codificação) e limita o raio de impacto.
Podemos também ajustar as métricas de carga e até usar sistemas de roteamento mais otimizados no futuro com base em métricas de custo de maior fidelidade, à medida que aprendemos mais.
Um problema semelhante existe no autoscaling. As contagens de requisições pendentes sozinhas não refletem a carga real. Um pico em requisições de contexto longo parece idêntico a um pico em requisições curtas, e as métricas de CPU e memória são igualmente não correlacionadas com a utilização real da GPU.
Usando unidades de modelo, nosso autoscaler pode decidir se deve aumentar ou diminuir a escala com base na razão de utilização de unidades de modelo. Quando o mecanismo de inferência está operando perto de uma certa porcentagem de suas unidades de modelo máximas (determinado pelo tipo de hardware e formato da carga de trabalho), ele está se aproximando da taxa de transferência máxima, o que aciona o aumento de escala. O inverso aciona a diminuição de escala. Em vez de ajustar manualmente as regras de auto-scaling para cada modelo, essa abordagem permite uma infraestrutura de dimensionamento agnóstica ao modelo.
Construir autoscaling sobre padrões de inferência de LLM nos salvou de sempre dimensionar para o número máximo de réplicas. Para modelos com tráfego intermitente, o autoscaling manteve as contagens de réplicas próximas à demanda real, resultando em mais de 80% de economia de GPU em comparação com o provisionamento estático no pico.
Confiabilidade em Tempo de Execução
Roteamento e dimensionamento inteligentes forneceram uma ótima base, mas não evitam falhas no nível do mecanismo. Não importa qual mecanismo de inferência implantamos (nosso mecanismo interno ou opções populares de código aberto), casos extremos e contenção de recursos surgem em escala de produção. Precisamos de mecanismos para detectar e recuperar de falhas automaticamente.
Detectando e recuperando de falhas silenciosas
Um modo de falha que encontramos são travamentos silenciosos. Requisições envolvendo casos extremos (saída estruturada, entradas multimodais) podem acionar erros não tratados na arquitetura multiprocesso dos mecanismos de inferência, fazendo com que os servidores parem de responder sem apresentar erros.
Detectamos isso com verificações de integridade black-box periódicas: requisições mínimas de ponta a ponta enviadas quando nenhuma requisição real foi concluída recentemente. Se uma verificação de integridade falhar, a sonda de vivacidade do Kubernetes reinicia o servidor. Isso funciona em todos os mecanismos, independentemente da implementação interna.
No entanto, sob carga alta, as próprias verificações de integridade podem expirar, fazendo com que a sonda de vivacidade mate servidores que estão realmente íntegros. Isso arrisca falhas em cascata. Para resolver isso, atribuímos às requisições de verificação de integridade a prioridade de agendamento mais alta, garantindo que elas sejam concluídas mesmo sob carga pesada. Com verificações de integridade priorizadas, o ciclo completo de detecção de um travamento, eliminação do servidor não íntegro e recuperação leva menos de 5 minutos. As falhas falsas da sonda de vivacidade caíram de várias por semana para zero.
Lidando com carga inesperada de requisições multimodais
Quando grandes lotes de requisições multimodais chegavam, vimos picos nas taxas de erro e timeouts de uma fonte completamente diferente.
As investigações revelaram que as requisições nem sequer chegavam aos processos principais do mecanismo de inferência. Servir requisições de imagem é mais caro em termos de recursos do que requisições apenas de texto, não apenas pelo codificador de visão adicional rodando em GPUs, mas também pelo processamento de imagem intensivo em CPU. Para certos modelos, o processamento de imagem era extremamente lento, bloqueando o loop de eventos completamente.
Mover operações de bloqueio para threads e processos separados não resolveu o problema; as requisições ainda se acumulavam sob alta carga de imagem. Então, analisamos os processos Python e fizemos várias descobertas:
- Entre todas as operações de CPU para imagens, o processamento de imagem (redimensionamento e normalização) é 10 vezes mais lento do que outras operações como a decodificação base64.
- Alguns modelos Hugging Face usam por padrão o processador de imagem baseado em PIL, enquanto outros usam o processador baseado em Torchvision mais rápido.
- Em ambientes conteinerizados, OMP_NUM_THREADS (que controla o número de threads OpenMP usadas pelo Torch para operações de CPU) é definido por padrão para o número de vCPUs na máquina host. Em configurações multilocatárias, este é um padrão ruim: um host pode ter 192 vCPUs, mas um contêiner tem acesso apenas a 12. O resultado são muito mais threads em execução do que núcleos disponíveis. Isso leva o uso da CPU além do limite do contêiner e aciona o throttling.
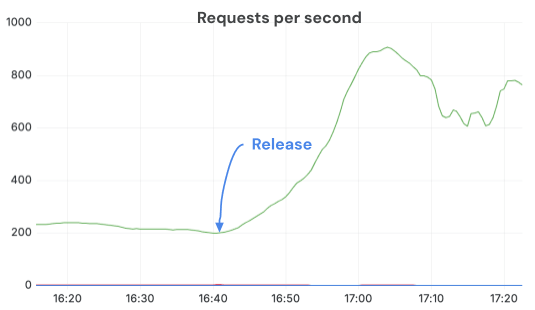
Ao mudar para processadores de imagem baseados em Torchvision e configurar corretamente OMP_NUM_THREADS, sustentamos QPS muito mais altos e aproveitamos totalmente as GPUs. Após o envio da correção, as requisições concluídas por segundo saltaram mais de 3x com as mesmas réplicas e carga. O throttling da CPU desapareceu e os servidores operaram em um estado muito mais saudável.
Conclusão
Servir LLMs de forma confiável em escala requer trabalho em todas as camadas da pilha de inferência. Cobrimos a infraestrutura de autoscaling e balanceamento de carga projetada em torno de cargas de trabalho de LLM, e mecanismos de tempo de execução que permanecem estáveis, independentemente do mecanismo ou da carga de trabalho. Há muito mais na história: início rápido de contêineres, rollouts seguros em frotas de GPU, gerenciamento de capacidade de GPU entre nuvens e regiões. Se esses são os tipos de problemas em que você quer trabalhar, estamos contratando!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.