Simplificando a Gestão de Dados e Reivindicações de Saúde: Apresentando Databricks X12 EDI Ember
Comece com a ingestão de reclamações no Databricks com este novo acelerador de soluções
- Entenda mais sobre os desafios do processamento de dados de saúde, incluindo reivindicações
- Saiba como o acelerador de soluções Databricks X12 EDI Ember simplifica significativamente a tarefa complexa de analisar transações de EDI em saúde
- Comece com o acelerador de soluções hoje
EDI e seu papel no Ecossistema de Saúde
A Troca Eletrônica de Dados (EDI) é um método de troca de dados semi-estruturado que permite a organizações de saúde como Pagadores, Provedores, etc., compartilhar informações transacionais vitais eletronicamente. Sua abordagem padronizada garante precisão e consistência em todas as operações de saúde. As transações EDI usadas para várias operações de saúde incluem:
- Submissões de reivindicações, Remessa e Inscrição de benefícios (837, 835, 834)
- Verificações de elegibilidade (270, 271)
- Transferências eletrônicas de fundos (EFTs)
Com o mercado global de EDI em saúde previsto para ultrapassar $7 bilhões até 2029, impulsionado pelo aumento das submissões de reivindicações, adoção de APIs e mandatos regulatórios, fluxos de trabalho EDI eficientes são mais essenciais do que nunca para escalar as submissões de reivindicações, atender às demandas regulatórias e potencializar a colaboração em tempo real na saúde. As organizações de saúde utilizam o EDI para realizar funções financeiras operacionais essenciais para serviços e pagamentos. Além disso, reivindicações, remessas e informações de inscrição alimentam muitos programas analíticos downstream, como fluxos de trabalho de integridade de pagamento, Cuidado Baseado em Valor (VBC), e arranjos de rede estreita, e medidas de qualidade como Conjunto de Dados e Informações de Efetividade em Saúde (HEDIS) e classificações de estrelas do Medicare. Importante, à medida que mais provedores se envolvem em VBCs, eles têm uma maior necessidade de ingerir e analisar EDIs de maneira contínua.
Apesar dos avanços tecnológicos contínuos, desafios-chave permanecem em como as organizações de saúde interagem com os dados EDI. Primeiro, o processo de troca e adjudicação - da submissão de reivindicações ao pagamento - permanece longo e fragmentado. Em segundo lugar, as informações EDI semi-estruturadas são frequentemente difíceis de acessar devido ao seu formato, complexidade e ferramentas limitadas para transformá-las em dados prontos para análise. Por último, grande parte dos dados EDI é consumida apenas a jusante dos sistemas proprietários de adjudicação, que oferecem transparência limitada e restringem as organizações de obter insights oportunos e acionáveis sobre o desempenho financeiro e clínico.
Desafios com o Processamento EDI
Lidar com formatos EDI é inerentemente desafiador devido a:
- Fontes de dados complexas e díspares exigem o desenvolvimento de analisadores personalizados
- Altos custos de manutenção de scripts personalizados e sistemas legados
- Processos manuais propensos a erros causam imprecisões nos dados
- Dificuldades em escalar soluções tradicionais com o aumento do volume de dados
A implementação de um parser X12 eficaz é crucial para agilizar as operações, melhorar a segurança e integridade dos dados, simplificar os processos de integração e proporcionar maior flexibilidade e escalabilidade. Investir nesta tecnologia pode reduzir significativamente os custos e melhorar a eficiência geral do sistema. As organizações de saúde requerem um parser robusto e eficiente que aborde diretamente esses desafios para:
- Reduzir significativamente os tempos de processamento
- Melhore a precisão na transformação de dados
- Fornecer desempenho escalável para grandes volumes de transações
Solução: Databricks’ X12 EDI Ember
Databricks desenvolveu um repositório de código aberto, x12-edi-parser, também chamado EDI Ember, para acelerar o valor e o tempo de insight ao analisar seus dados EDI usando fluxos de trabalho Spark. Trabalhamos com nosso parceiro, CitiusTech, que contribuiu para a funcionalidade do repositório e pode ajudar as empresas a escalar funções baseadas em EDI e/ou reivindicações, como:
- Descoberta do tipo de transação: Detectar e classificar automaticamente grupos funcionais como Reivindicações Institucionais (837I), Reivindicações Profissionais (837P), ou outros conjuntos de transações X12
- Extração rica de segmentos de reivindicações: Extraia dados financeiros e clínicos - valores de reivindicações, códigos de procedimentos, linhas de serviço, códigos de receita, diagnósticos e mais
- Reconhecimento de loop hierárquico: Para preservar os loops aninhados do EDI, identifique a qual loop cada reivindicação pertence, extraia o provedor de faturamento, assinante, dependentes e capture os parceiros de intercâmbio do remetente/receptor
- Conversão JSON e preparação para downstream: Aplaine e normalize todos os segmentos em objetos JSON limpos, prontos para análise, data lakes ou sistemas downstream.
Principais benefícios
- Menor tempo para valor: não há mais luta com parsers de terceiros ou scripts personalizados frágeis
- Governança de ponta a ponta: rastrear a linhagem das tabelas de reivindicações com o Catálogo Unity, aplicar verificações de qualidade e adicionar capacidades de monitoramento
- Escalar em escala de petabytes: aproveite o motor distribuído do Spark para analisar milhões de transações de reivindicações em minutos
EDI Ember usa orquestração funcional para desmontar transmissões EDI em camadas estruturadas e gerenciáveis. O objeto EDI analisa a troca bruta e organiza segmentos em objetos de Grupo Funcional, que por sua vez são divididos em objetos de Transação representando reivindicações individuais de saúde.
Além desses componentes fundamentais, classes especializadas como HealthcareManager orquestram a lógica de análise para padrões específicos de saúde (como reivindicações 837), enquanto a classe MedicalClaim aprofunda e interpreta dados chave de reivindicação como linhas de serviço, diagnósticos e informações do pagador.
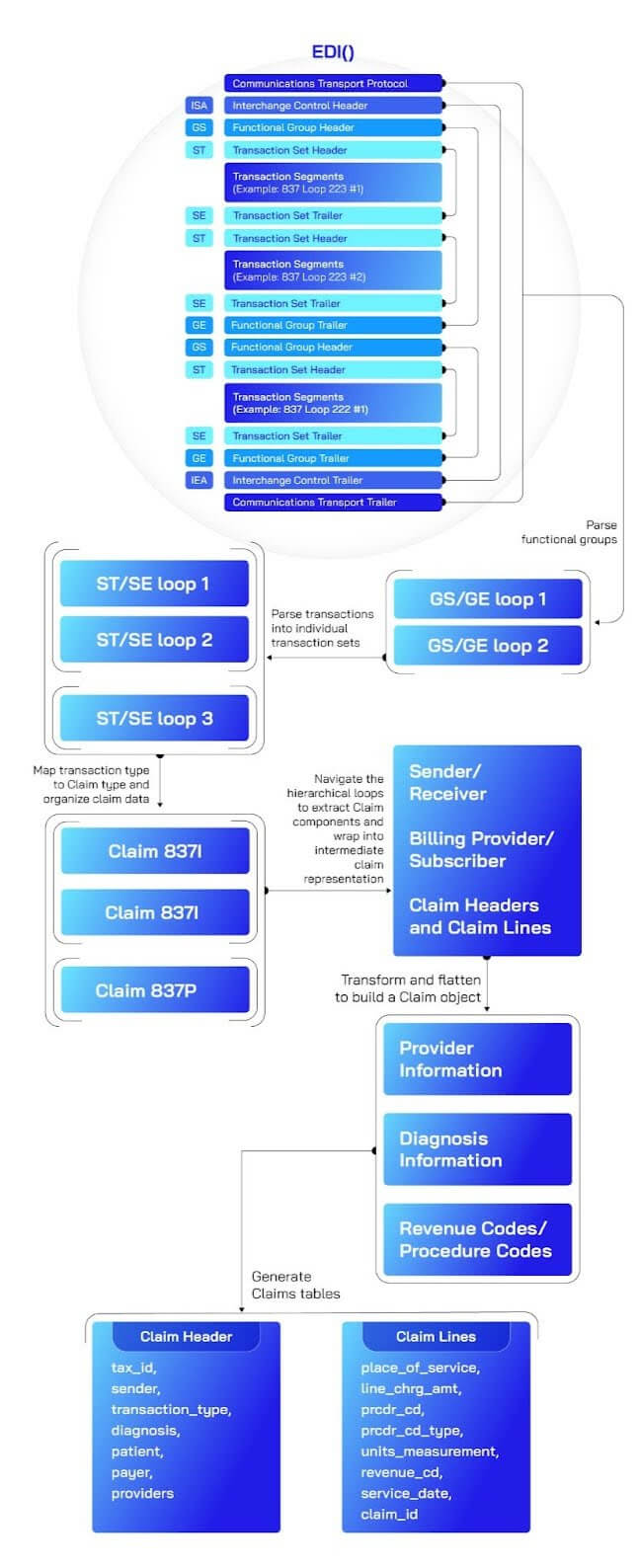
A arquitetura modular torna o parser altamente extensível: adicionar suporte para novos tipos de transação (por exemplo, remessas 835, inscrições 834) simplesmente requer a introdução de novas classes de manipulador sem reescrever o motor de análise central. À medida que os padrões EDI de saúde continuam a evoluir, este design garante que as organizações possam estender flexivelmente a funcionalidade, modularizar fluxos de trabalho de análise e escalar soluções de saúde orientadas por análise de forma eficiente.
Construindo Tabelas de Reivindicações
As etapas para instalar e executar o parser estão no README do repositório. Ao executar essas etapas, podemos construir um DataFrame Spark claims a partir do qual construímos especificamente duas tabelas Spark — claim_header e claim_lines.
- A tabela
claim_headercaptura dados de alto nível e de loop dos envelopes de reivindicações EDI, como IDs de reivindicações, detalhes do provedor, demografia do paciente, códigos de diagnóstico, identificadores de pagador e valores de reivindicações. - A tabela
claim_linesé gerada pela explosão do array de linha de serviço de cada reivindicação. Esta tabela detalhada contém informações granulares sobre procedimentos individuais, cobranças de linha, códigos de receita, ponteiros de diagnóstico e datas de serviço.
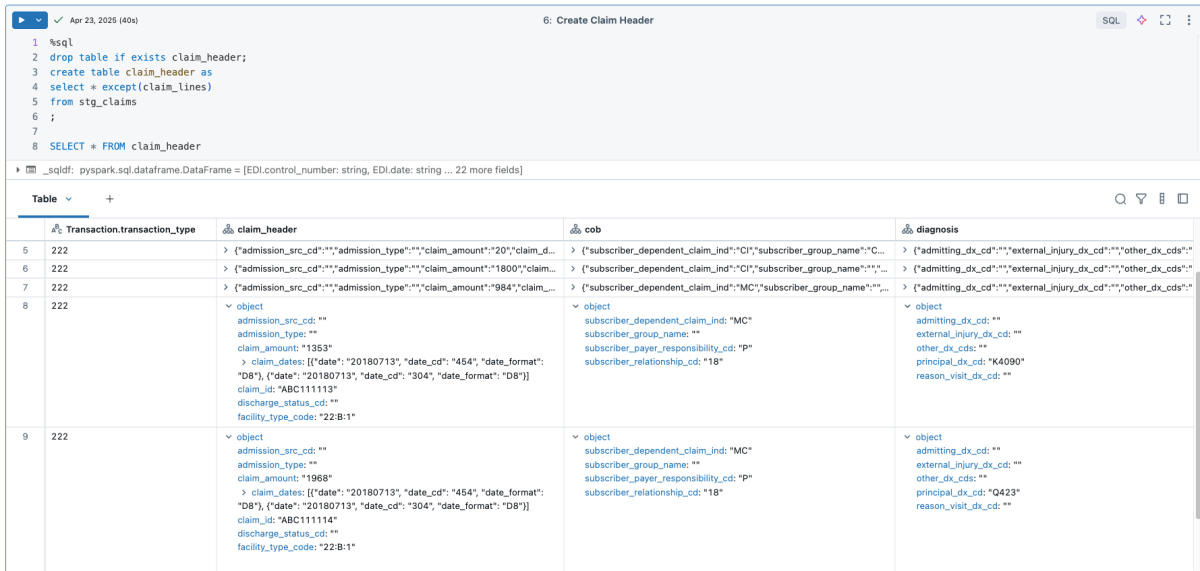
Um exemplo de claim_header 837 (uma linha por reivindicação):
A consulta aos dados revela informações sobre o tipo de transação, metadados do cabeçalho da reivindicação e coordenação de benefícios:
E suas correspondentes linhas 837 claim_lines (várias linhas por reivindicação, uma por linha de serviço) seriam as seguintes:
Isso corresponde a esta tabela de amostra no ambiente:

Ao estruturar os dados nessas duas tabelas, as organizações de saúde obtêm uma visibilidade clara tanto das métricas agregadas de nível de reclamação quanto dos dados detalhados da linha de serviço, permitindo análises e relatórios de reclamações abrangentes.
O Databricks X12 EDI Ember (com um notebook Databricks de amostra) simplifica significativamente a tarefa complexa de analisar transações EDI de saúde. Ao simplificar a extração, transformação e gestão de dados, esta abordagem capacita as organizações de saúde a desbloquear insights analíticos mais profundos, melhorar a precisão do processamento de reivindicações e melhorar a eficiência operacional.
O repositório é projetado como uma estrutura que pode facilmente escalar para outros tipos de transações. Se você está procurando processar tipos de arquivos adicionais, por favor, crie uma questão no GitHub e contribua para o repositório entrando em contato conosco!
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.