Simplifying Healthcare Data and Claims Management: Introducing Databricks X12 EDI Ember
Get started with claims ingestion in Databricks with this new solution accelerator
by Raven Mukherjee, Manisha Bafna and Aaron Zavora
- Understand more about the challenges processing healthcare data including claims
- Learn how the Databricks X12 EDI Ember solution accelerator significantly streamlines the complex task of parsing healthcare EDI transactions
- Get started with the solution accelerator today
EDI and its role in the Healthcare Ecosystem
Electronic Data Interchange (EDI) is a semi-structured data exchange method allowing healthcare organizations like Payers, Providers, etc., to seamlessly share vital transactional information electronically. Its standardized approach ensures accuracy and consistency across healthcare operations. EDI transactions used for various healthcare operations include:
- Claims submissions, Remittance, and Benefit enrollment (837, 835, 834)
- Eligibility verifications (270, 271)
- Electronic funds transfers (EFTs)
With the global healthcare EDI market expected to surpass $7 billion by 2029, driven by increasing claims submissions, the adoption of APIs, and regulatory mandates, efficient EDI workflows are more essential than ever for scaling claims submissions, meeting regulatory demands, and powering real-time healthcare collaboration. Healthcare organizations leverage EDI to conduct core operational financial functions for services and payments. Additionally, claims, remittance, and enrollment information power many downstream analytical programs such as payment integrity workstreams, Value Based Care (VBC), and narrow network arrangements, and quality measures like Healthcare Effectiveness Data and Information Set (HEDIS) and Medicare Star ratings. Importantly, as more providers engage in VBCs, they have a greater need to seamlessly ingest and analyze EDIs.
Despite ongoing technological advancements, key challenges remain in how healthcare organizations interact with EDI data. First, the exchange and adjudication process—from claims submission to payment—remains lengthy and fragmented. Second, semi-structured EDI information is often difficult to access due to its format, complexity, and limited tooling to transform it into analytics-ready data. Lastly, much of the EDI data is consumed only downstream of proprietary adjudication systems, which offer limited transparency and restrict organizations from gaining timely, actionable insights into financial and clinical performance.
Challenges with EDI Processing
Handling EDI formats is inherently challenging due to:
- Complex and disparate data sources require the development of custom parsers
- High maintenance costs of custom scripts and legacy systems
- Error-prone manual processes cause data inaccuracies
- Difficulties scaling traditional solutions with increasing data volume
The implementation of an effective X12 parser is crucial for streamlining operations, enhancing data security and integrity, simplifying integration processes, and providing greater flexibility and scalability. Investing in this technology can reduce costs significantly and improve overall efficiency within the system. Healthcare organizations require a robust, efficient parser that directly addresses these challenges to:
- Reduce processing times significantly
- Enhance accuracy in data transformation
- Provide scalable performance for large transaction volumes
Solution: Databricks’ X12 EDI Ember
Databricks has developed an open source code repository, x12-edi-parser, also called EDI Ember, to accelerate value and time to insight by parsing your EDI data using Spark workflows. We have worked with our partner, CitiusTech, who has contributed to the repo functionality and can help enterprises scale EDI and/or claims-based functions such as:
- Transaction-type discovery: Automatically detect and classify functional groups as Institutional Claims (837I), Professional Claims (837P), or other X12 transaction sets
- Rich claim-segment extraction: Pull out financial and clinical data—claim amounts, procedure codes, service lines, revenue codes, diagnoses, and more
- Hierarchical loop recognition: To preserve EDI’s nested loops, identify which loop each claim belongs to, extract billing provider, subscriber, dependents, and capture the sender/receiver interchange partners
- JSON conversion and downstream readiness: Flatten and normalize all segments into clean, schema-on-read JSON objects, ready for analytics, data lakes, or downstream systems
Key Benefits
- Faster time to value: no more wrestling with third-party parsers or brittle custom scripts
- End-to-end governance: track lineage of claim tables with Unity Catalog, enforce quality checks, and add monitoring capabilities
- Scalable at petabyte scale: leverage Spark’s distributed engine to parse millions of claim transactions in minutes
EDI Ember uses functional orchestration to deconstruct EDI transmissions into structured, manageable layers. The EDI object parses the raw interchange and organizes segments into Functional Group objects, which in turn are split into Transaction objects representing individual healthcare claims.
In addition to these foundational components, specialized classes such as HealthcareManager orchestrate parsing logic for healthcare-specific standards (like 837 claims), while the MedicalClaim class further flattens and interprets key claim data such as service lines, diagnoses, and payer information.
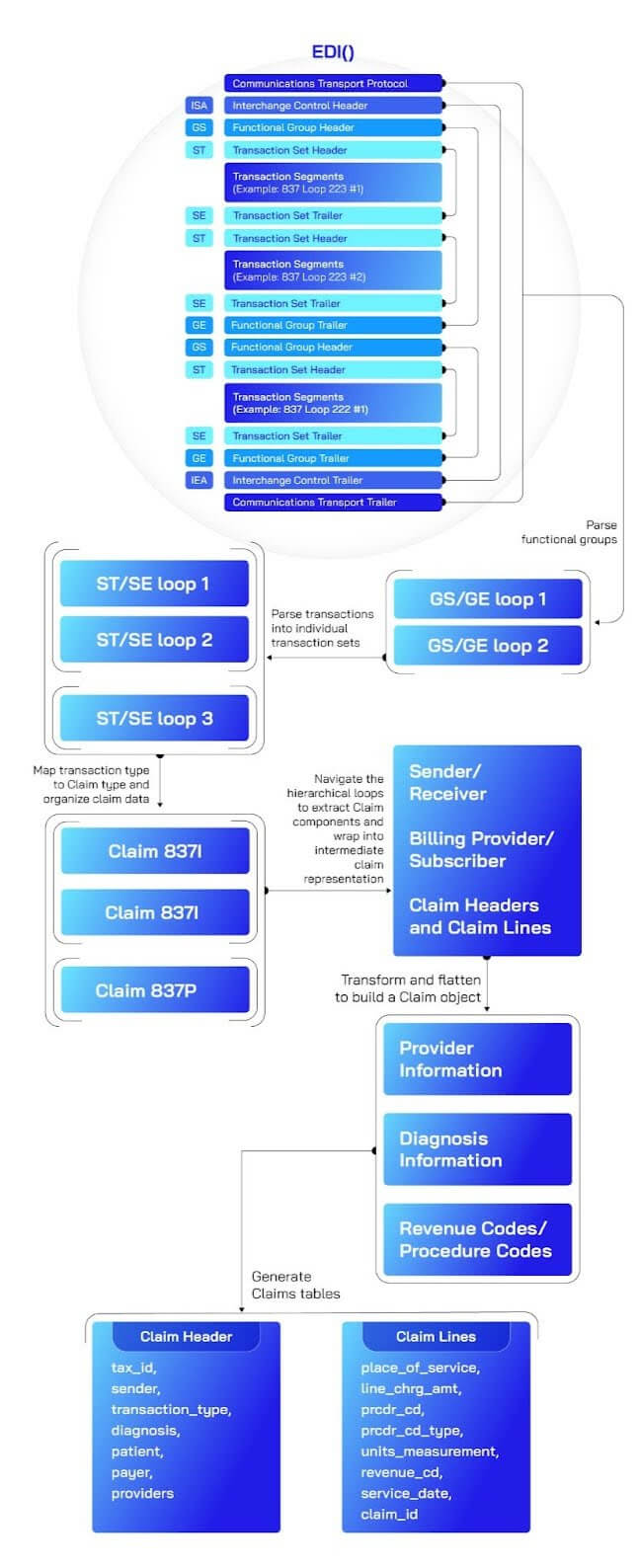
The modular architecture makes the parser highly extensible: adding support for new transaction types (e.g., 835 remittances, 834 enrollments) simply requires introducing new handler classes without rewriting the core parsing engine. As healthcare EDI standards continue to evolve, this design ensures organizations can flexibly extend functionality, modularize parsing workflows, and scale analytics-driven healthcare solutions efficiently.
Building Claims Tables
The steps to install and run the parser are in the repo’s README. Upon running those steps, we can build a claims Spark DataFrame from which we specifically build two Spark tables — claim_header and claim_lines.
- The
claim_headertable captures high-level and loop-level data from the EDI claim envelopes, such as claim IDs, provider details, patient demographics, diagnosis codes, payer identifiers, and claim amounts. - The
claim_linestable is generated by exploding the service-line array from each claim. This detailed table contains granular information on individual procedures, line charges, revenue codes, diagnosis pointers, and service dates.
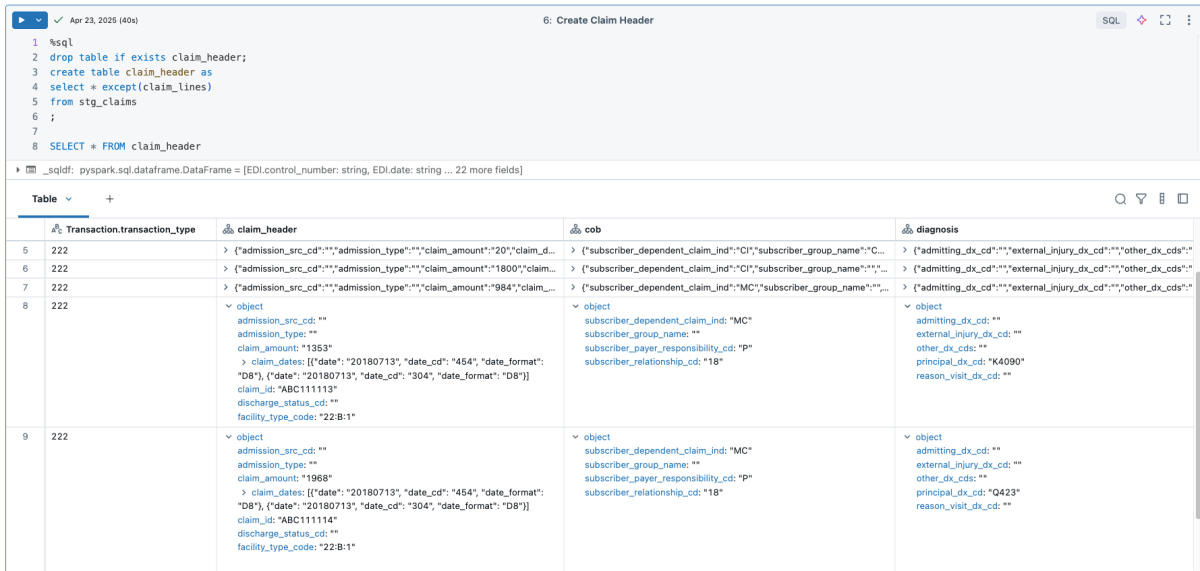
An 837 claim_header example (one row per claim):
Querying the data reveals the information about the transaction type, claim header metadata, and coordination of benefits:
And their corresponding 837 claim_lines rows (multiple rows per claim, one per service line) would be as follows:
That corresponds to this sample table in the environment:

By structuring data into these two tables, healthcare organizations gain clear visibility into both aggregated claim-level metrics and detailed service-line data, enabling comprehensive claims analytics and reporting.
The Databricks X12 EDI Ember (with a sample Databricks notebook) significantly streamlines the complex task of parsing healthcare EDI transactions. By simplifying data extraction, transformation, and management, this approach empowers healthcare organizations to unlock deeper analytical insights, improve claims processing accuracy, and enhance operational efficiency.
The repository is designed as a framework that can easily scale to other transaction types. If you are looking to process additional file types, please create a GitHub issue and contribute to the repo by reaching out to us!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.