Potencializando a criação de modelos de AI: paralelismo de dados e de tarefa com Ray e Databricks
Como a combinação do Ray com o Databricks Spark permitiu que a Pilot Company criasse modelos de previsão de forma mais rápida e eficiente.
- Aprenda como a combinação do paralelismo de dados do Spark com o paralelismo de tarefas do Ray acelera drasticamente o treinamento e o ajuste de machine learning (ML), reduzindo os custos de compute e os tempos de ciclo.
- Explore um caso real de previsão de ventas no varejo em que os modelos das lojas foram ajustados 8x mais rápido graças ao Ray no Databricks.\n
- Veja como a arquitetura lakehouse do Databricks, o Unity Catalog e o MLflow suportam pipelines escaláveis de ponta a ponta para equipes de AI de varejo e corporativas.
Infraestrutura ideal, impacto máximo: por que o paralelismo é importante para a AI no varejo
Previsões de ventas precisas melhoram a satisfação do cliente em todas as indústrias, incluindo os de viagens e varejo. A Pilot Company opera mais de 900 unidades, com operações comerciais que dependem de previsões rápidas e confiáveis para atender nossos clientes. Gargalos legados (como compute subutilizado e ciclos de modelo demorados) poderiam levar a previsões desatualizadas, o que pode impactar negativamente a experiência de nossos clientes.
A Pilot Company precisava de um pipeline de AI que possibilitasse previsões frequentes e granulares, sem aumentar os gastos com infraestrutura. Os métodos tradicionais de retreinamento manual ou em lote não conseguiam acompanhar o ritmo.
Para enfrentar esses desafios, a Pilot Company utilizou:
- Clusters Spark da Databricks (Runtime 16.4) para extrair, transformar, carregar (ETL), preparação e particionamento de big data
- Arquitetura Lakehouse para armazenamento unificado e governado e acesso simplificado
- Databricks Unity Catalog para compartilhamento de dados seguro entre equipes
- Managed MLflow para acompanhamento de experimentos e reprodutibilidade
A sobreposição do Ray para paralelismo de tarefas sobre o paralelismo de dados do Spark permite que a Pilot Company otimize a criação de modelos de ponta a ponta. Os modelos agora são retreinados assim que novos dados se tornam disponíveis, traduzindo a eficiência da infraestrutura em benefícios comerciais tangíveis.
Paralelismo em ação: da preparação de dados ao ajuste de modelos
A criação de um modelo de previsão de alta precisão para ventas no varejo envolve vários os passos:
- Coleta e preparação de dados: coleta e limpeza de dados de vendas de múltiplas fontes em grande escala.
- Engenharia de recurso: transformar e extrair novos preditores que melhoram o desempenho do modelo.
- Treinamento de modelos: ajuste de parâmetros e minimização das funções de perda para o melhor ajuste.
- Validação e ajuste de modelos: avaliação da precisão, ajuste de hiperparâmetros e seleção dos melhores modelos.
- Implantação e avaliação: verificações finais de eficácia antes da entrada em produção.
- O Spark se destaca em tarefas de big data (os passos 1 e 2) usando paralelismo de dados. Datasets massivos são divididos em partições, processados simultaneamente e gerenciados de forma eficiente em um cluster.
- Os passos 3-6 (treinamento, ajuste e avaliação) se beneficiam do paralelismo de tarefas. Aqui, o desafio é maximizar a utilização para processos de longa duração e intensivos em compute, e é aí que entra o Ray.
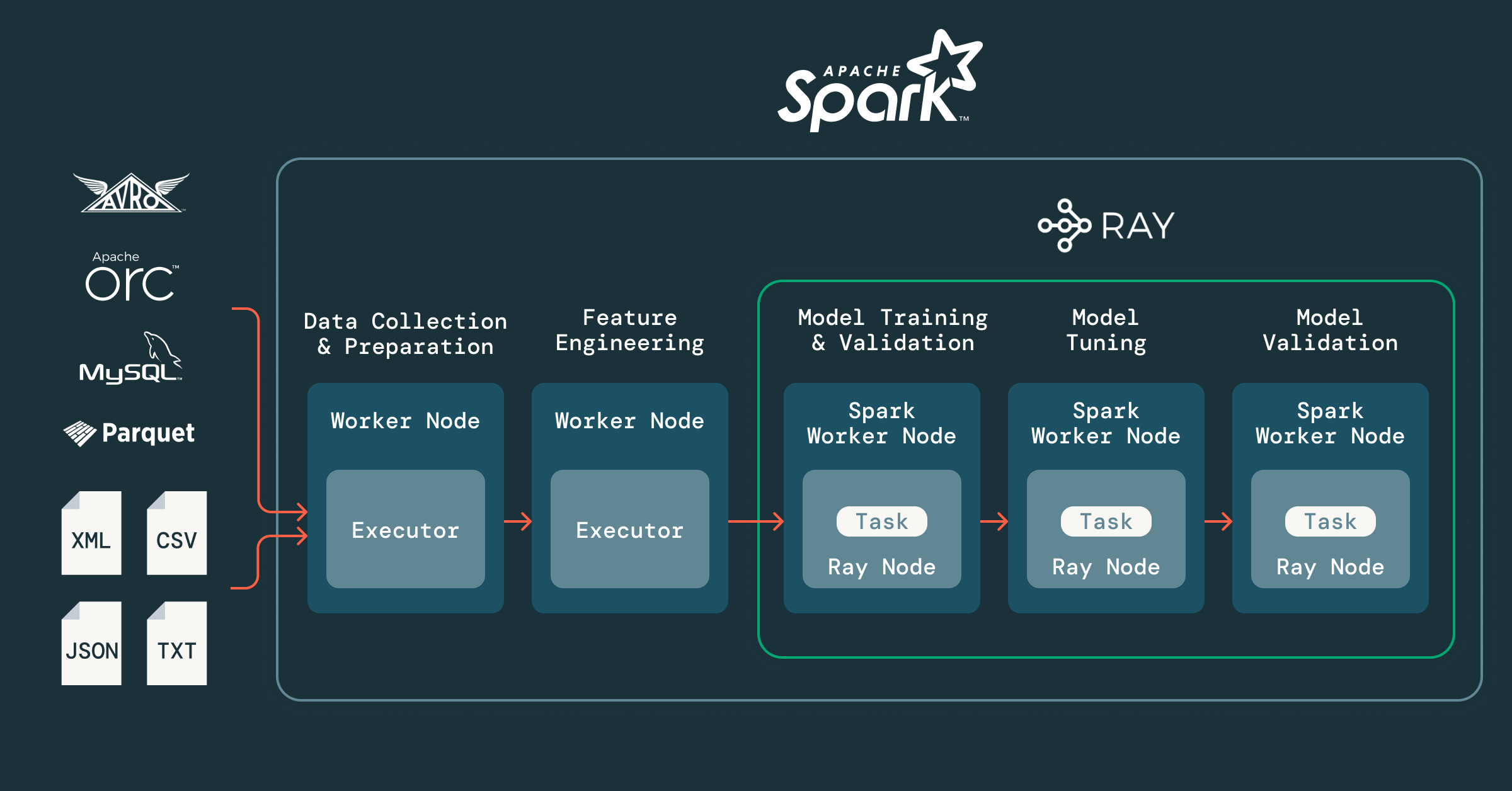
Paralelismo de dados com Spark
No Spark, os dados são divididos em partições. Cada executor processa-os em paralelo usando funções de ordem superior e lambda (p. ex., map, filter) em RDDs ou DataFrames. Isso permite um escalonamento contínuo para ETL, processos em lotes e engenharia de recurso, reduzindo drasticamente o tempo de preparação e transformações de dados.
Paralelismo de tarefas com Ray: sobre o Databricks
O Ray permite que milhares de Jobs de treinamento de modelos ou de ajuste de hiperparâmetros sejam executadas simultaneamente, atribuindo frações ideais de CPU ou GPU por tarefa — maximizando a utilização do cluster. Por exemplo, o Ray pode fazer o ajuste fino de mais de 1.400 modelos de séries temporais de uma só vez em um clusters de 52 núcleos, adequando a oferta de compute à demanda de job.
A integração com o Databricks permite a transferência em memória via Apache Arrow, fazendo a transição do ambiente de dados do Spark para tarefas de ML orientadas pelo Ray sem gargalos de I/O.
O paralelismo de tarefas é crucial no treinamento e ajuste de modelos, especialmente ao otimizar milhares de modelos individuais, como a previsão de demanda para cada item em cada loja de uma rede de varejo inteira. O Ray se destaca nessa camada, orquestrando cargas de trabalho para que cada tarefa de treinamento de modelo ou otimização de hiperparâmetros seja executada de forma independente e simultânea.
O que diferencia o Ray é sua eficiência de recurso: ele não apenas consegue gerenciar milhares de tarefas concorrentes, mas também aloca dinamicamente a quantidade certa de recurso de compute — atribuindo números específicos ou até mesmo frações de núcleos de CPU e GPU a cada tarefa com base na complexidade. Por exemplo, o Ray pode alocar frações tão pequenas quanto 0,25, 0,5 ou 1 núcleo de CPU inteiro (ou combinações como 1 CPU e 0,5 GPU) para diferentes jobs, maximizando a utilização geral do cluster.
Em nosso benchmark, esse paralelismo de granularidade fina nos permitiu ensinar e ajustar mais de 1.400 modelos de séries temporais simultaneamente em um clusters de 52 núcleos, resultando em uma redução do tempo total de processamento de quase 3 horas (usando apenas o Spark) para menos de 30 minutos com o Ray no Databricks. Isso não apenas significa que os engenheiros podem fazer mais e mais rápido, mas também garante que cada recurso de hardware disponível seja totalmente aproveitado para gerar valor de negócio.
Key benefício: a integração do Ray com o Databricks permite a transferência de dados em memória com o Apache Arrow, permitindo que as cargas de trabalho de ML alternem do ambiente de preparação de dados do Spark diretamente para os experimentos executados pelo Ray, sem a complexidade de E/S de arquivos.
Benchmark do mundo real: previsão de ventas no varejo
Cenário
- Objetivo: ajustar mais de 1.400 modelos individuais de previsão de séries temporais (um por local de loja-produto) para ventas de varejo.
- Tarefa: otimização de hiperparâmetros usando o Optuna com um espaço de busca rico e multidimensional.
Linha de base: Apenas Spark (Cluster 1)
- 6 worker nodes, oito núcleos cada, 61 GB de RAM.
- Os modelos são execução sequencialmente nos nós de worker; apenas seis podem ser processados por vez.
- Tempo total de execução: ~2 horas e 47 minutos.
- Utilização de CPU: apenas 20–25%.
Acelerado: Ray-on-Spark (Cluster 2)
- Mesmo stack de hardware, com um cluster Ray adicionado (4 CPUs por worker do Ray).
- 52 tarefas concorrentes gerenciadas pelo Ray (6x8+4).
- Tempo total de execução: apenas 28 minutos e 12 segundos — uma melhoria de quase 8x!
- Utilização de CPU: 90–95% (muito mais próximo do potencial máximo).
Impacto no negócio:
Essa abordagem paralelizada não apenas acelerou a previsão para nossas operações de varejo, mas também transformará a maneira como as equipes de cadeia de suprimentos, merchandising e marketing da Pilot Company usam percepções para apoiar nosso propósito de mostrar às pessoas que elas são importantes em todos os momentos. Ao reduzir o tempo necessário para o treinamento e ajuste de modelos de previsão de horas para minutos, os modelos podem ser retreinados com muito mais frequência. Essa maior frequência permite que as previsões reflitam tendências de ventas em tempo real, sazonalidade e mudanças nas preferências do consumidor, capturando a "realidade do momento" muito melhor do que abordagens mais lentas e baseadas em lotes.
Como resultado, o planejamento de estoque será mais preciso, permitindo que as lojas estoquem exatamente o que precisam. Para os gerentes de categoria, a velocidade para obter percepções acionáveis permitirá um alinhamento mais preciso entre as previsões de demanda e as decisões de compra.
Mais importante ainda, as equipes de marketing e merchandising terão a capacidade de responder rapidamente com campanhas promocionais data-driven, lançando ofertas nos momentos mais oportunos e mostrando às pessoas que elas são importantes em todos os momentos. Este ciclo de feedback fechado, no qual os modelos são continuamente aprimorados com base nos dados más recentes de cada loja, posiciona a empresa para permanecer ágil e obcecada pelo cliente em um ambiente de varejo em rápida mudança.
Análise técnica aprofundada: como funciona
- Spark particiona e prepara os dados de ventas, deixando os recursos prontos para o consumo do modelo.
- Ray orquestra e paraleliza o ajuste de hiperparâmetros e o treinamento de modelos. Cada worker do Ray lida com vários modelos — ou divide grandes datasets para treinamento distribuído quando necessário.
- Os dados transitam de forma transparente entre o Spark e o Ray graças à integração de memória baseada em Arrow do Databricks, que evita lentidão na gravação em disco e gargalos de armazenamento.
Um exemplo de código simples:
- Defina um espaço de busca no Optuna.
- Use a biblioteca tune do Ray para treinamento de modelos paralelo e distribuído e busca de hiperparâmetros.
- Logs e monitore a utilização para garantir que o hardware seja totalmente aproveitado para gerar valor para o negócio.
Quando usar Spark, Ray... ou ambos?
- Spark: Ideal para ETL, processamento massivo de dados, fluxos de trabalho de transmissão/lotes e engenharia de recursos.
- Ray: melhor para ajuste de hiperparâmetros, aprendizagem profunda, aprendizado por reforço e tarefas de compute de alto desempenho.
- Combinado: use Spark + Ray para pipelines de AI de ponta a ponta: preparação/engenharia de recursos com Spark, treinamento/ajuste/experimentação com Ray — tudo com o mínimo de atrito.
Transformando o treinamento de modelos: próximos passos
A combinação do paralelismo de dados com o Spark e do paralelismo de tarefa com o Ray — principalmente quando em execução em uma stack unificada do Databricks — permite que as equipes de AI/ML superem os gargalos legados. Os tempos de execução despencam, a utilização do compute dispara e as implantações corporativas se tornam muito mais econômicas.
Adicionar o Ray aos seus clusters do Databricks Spark pode reduzir o tempo de criação de modelos para tarefas de ML em grande escala, permitindo que as organizações prevejam, planejem e concorram com mais velocidade e precisão.
Redefina o que é possível com a Databricks Data Intelligence Platform. Saiba mais hoje.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.