Aprendizado Supervisionado vs. Não Supervisionado: Entendendo as diferenças e capacidades de cada abordagem de ML
- Aprendizado supervisionado vs. não supervisionado servem a propósitos diferentes: o aprendizado supervisionado usa dados rotulados para fazer previsões e classificações precisas, enquanto o aprendizado não supervisionado encontra padrões ocultos em dados brutos e não rotulados, tornando cada um mais adequado para diferentes objetivos de negócios.
- ML moderno combina ambas as abordagens: técnicas como aprendizado semi-supervisionado e auto-supervisionado combinam os pontos fortes de cada paradigma.
- O verdadeiro desafio é construir sistemas: ML empresarial bem-sucedido depende da orquestração de ambas as abordagens em pipelines de dados confiáveis, governança robusta e avaliação contínua ao longo do ciclo de vida do modelo.
Sistemas de machine learning aprendem com dados para fazer previsões, classificar informações ou descobrir padrões que seriam difíceis para humanos identificarem manualmente.
O que é aprendizado supervisionado?
No aprendizado supervisionado, os modelos são treinados usando dados rotulados, onde cada entrada é pareada com uma saída conhecida. O modelo aprende comparando suas previsões com essas respostas corretas e reduzindo o erro iterativamente.
No cerne desse processo estão os modelos de machine learning que aprendem relacionamentos explícitos entre características e resultados. A presença de dados rotulados fornece orientação clara, tornando o aprendizado supervisionado adequado para problemas onde precisão, rastreabilidade e repetibilidade são essenciais.
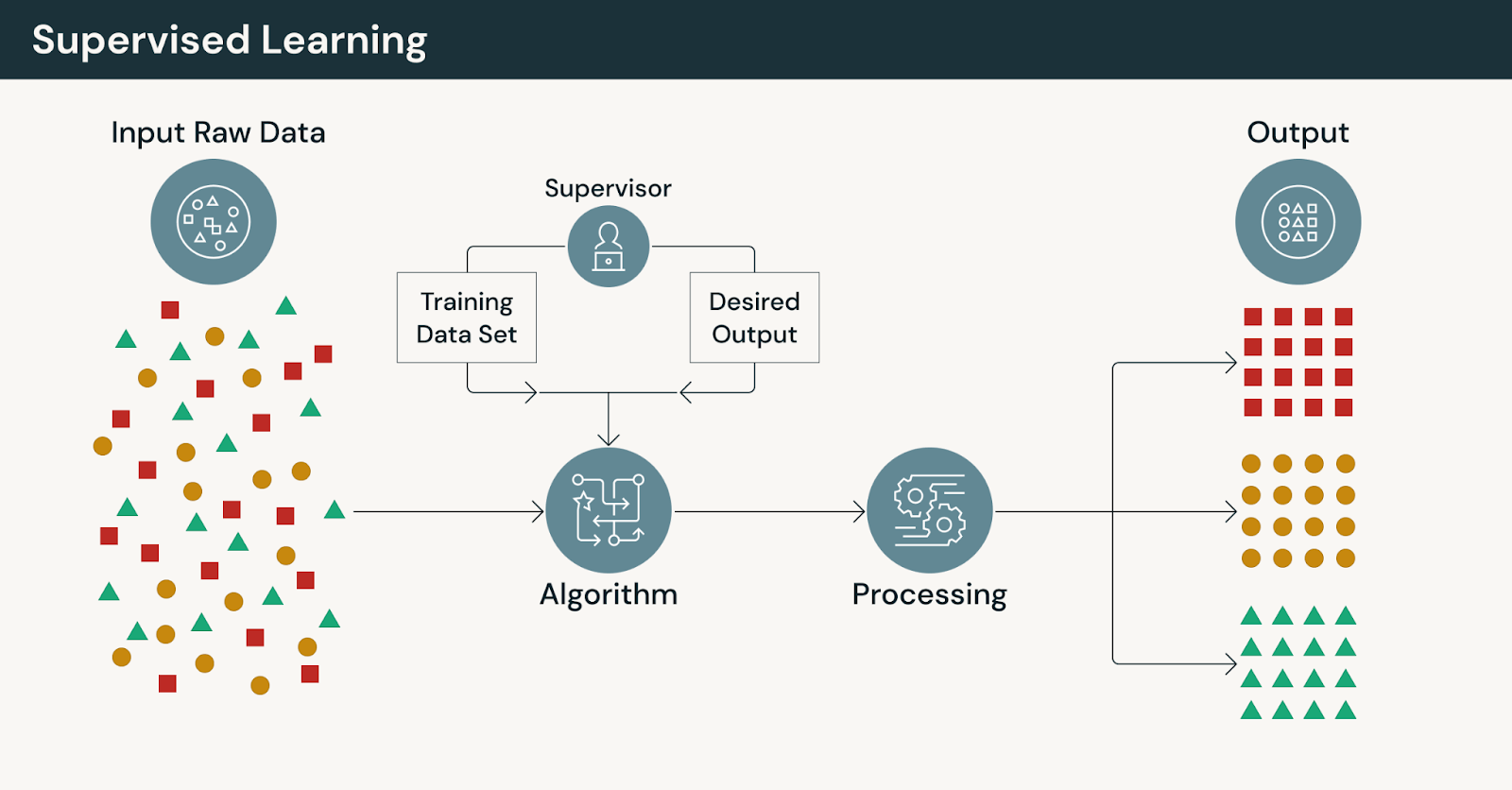
Como funciona o aprendizado supervisionado
Um fluxo de trabalho típico de aprendizado supervisionado inclui:
- Coleta de dados históricos de treinamento com resultados conhecidos
- Preparação e validação de conjuntos de dados de treinamento rotulados
- Engenharia de características que capturam sinais relevantes
- Treinamento e avaliação de modelos em relação à verdade fundamental (ground truth)
- Implantação de modelos e acompanhamento do desempenho ao longo do tempo
Esse fluxo de trabalho depende da disponibilidade e qualidade dos rótulos — uma limitação que muitas vezes se torna mais pronunciada à medida que o volume de dados cresce.
Tipos de aprendizado supervisionado
Problemas de aprendizado supervisionado geralmente se enquadram em duas categorias:
- Classificação: Atribuição de dados de entrada a classes predefinidas, como e-mail spam versus legítimo ou sentimento positivo versus negativo.
- Regressão: Previsão de valores contínuos, como previsões de demanda, precificação ou pontuações de risco. Empresas de transporte usam modelos de regressão para prever tempos de voo com base no desempenho histórico de rotas, padrões sazonais e fatores operacionais, ajudando a otimizar o agendamento e definir expectativas precisas para os clientes.
Em ambos os casos, o desempenho do modelo pode ser medido diretamente em relação aos resultados conhecidos, o que simplifica a avaliação e a responsabilidade.
Aplicações comuns de aprendizado supervisionado
O aprendizado supervisionado de máquina é comumente usado para:
- Filtragem de e-mail e moderação de conteúdo
- Análise de sentimento em feedback de clientes
- Previsão e análise preditiva
- Classificação de imagens e documentos
Muitas aplicações de processamento de linguagem natural dependem de ajuste fino supervisionado para adaptar modelos de propósito geral a tarefas, políticas ou vocabulários específicos de domínio.
Aprendizado supervisionado em diversas indústrias
As aplicações de aprendizado supervisionado abrangem praticamente todos os setores, com alguns casos de uso que se tornaram fundamentais para a infraestrutura digital moderna.
Segurança cibernética: Sistemas de detecção de spam analisam bilhões de e-mails diariamente, usando modelos supervisionados treinados em exemplos rotulados de mensagens legítimas e maliciosas. A detecção moderna de spam vai além da simples correspondência de palavras-chave, incorporando reputação do remetente, estrutura da mensagem, análise de anexos e padrões comportamentais.
Saúde e ciências da vida: O aprendizado supervisionado envolve o treinamento de modelos preditivos em dados biomédicos e genômicos rotulados para identificar padrões associados a variantes relacionadas a doenças e alvos terapêuticos. Ao aplicar esses modelos em uma plataforma de análise escalável, os pesquisadores podem quantificar relacionamentos entre características genéticas e resultados clínicos, permitindo uma previsão mais precisa de alvos de medicamentos e acelerando a descoberta baseada em hipóteses.
Serviços financeiros: O aprendizado supervisionado foi usado para treinar modelos de detecção de risco e fraude em dados históricos de transações rotulados, permitindo que o sistema distinga entre atividades legítimas e suspeitas. Ao aprender com resultados conhecidos — como casos de fraude confirmados ou comportamentos de clientes validados — os modelos melhoraram a precisão da detecção em tempo real, ao mesmo tempo em que reduziram falsos positivos. Implantados em uma plataforma de dados escalável, esses modelos supervisionados suportaram a tomada de decisão mais rápida e um gerenciamento de risco financeiro mais resiliente.
Varejo e bens de consumo: Usando dados históricos rotulados de vendas, preços e promoções, modelos preditivos foram treinados para prever a demanda e otimizar as decisões de estoque em escala. Ao aprender com resultados conhecidos — como movimentação anterior de produtos e padrões de demanda regionais — o sistema melhorou a precisão da previsão em milhares de locais. Isso permitiu um reabastecimento mais preciso, reduziu rupturas de estoque e um alinhamento mais estreito entre as operações da cadeia de suprimentos e a demanda do cliente.
Experiências do cliente: Modelos preditivos foram treinados em dados unificados e rotulados de interações e perfis de clientes para aprender padrões que ajudam a segmentar públicos e prever comportamentos de clientes. Esses modelos supervisionados permitiram insights de clientes mais precisos, apoiando estratégias de marketing direcionado e personalização. Isso resultou na entrega mais rápida de insights acionáveis que melhoram o engajamento e a experiência do cliente em todos os canais.
Mídia e entretenimento: Dados rotulados de jogabilidade, engajamento e comportamento foram usados para treinar modelos preditivos que identificam padrões na atividade do jogador e na interação com o conteúdo. Ao aprender com resultados conhecidos — como sinais de abandono (churn), comportamentos dentro do jogo e tendências da comunidade — o sistema permitiu previsões mais precisas e otimização de conteúdo mais rápida. Isso apoiou melhores experiências para os jogadores, decisões de operações ao vivo mais eficientes e desenvolvimento baseado em dados em um ecossistema global de jogos.
Cada aplicação compartilha um requisito comum: dados de treinamento rotulados confiáveis que representam com precisão o espaço do problema e monitoramento contínuo para detectar quando o desempenho do modelo se degrada.
O que é aprendizado não supervisionado?
Em vez de aprender com exemplos rotulados, o aprendizado não supervisionado de máquina analisa dados não rotulados para identificar padrões, estrutura ou relacionamentos sem alvos predefinidos.
Isso torna o aprendizado não supervisionado especialmente valioso no início de projetos de ML, quando as equipes ainda podem não saber quais perguntas fazer — ou quando rotular dados é impraticável ou proibitivo em termos de custo.
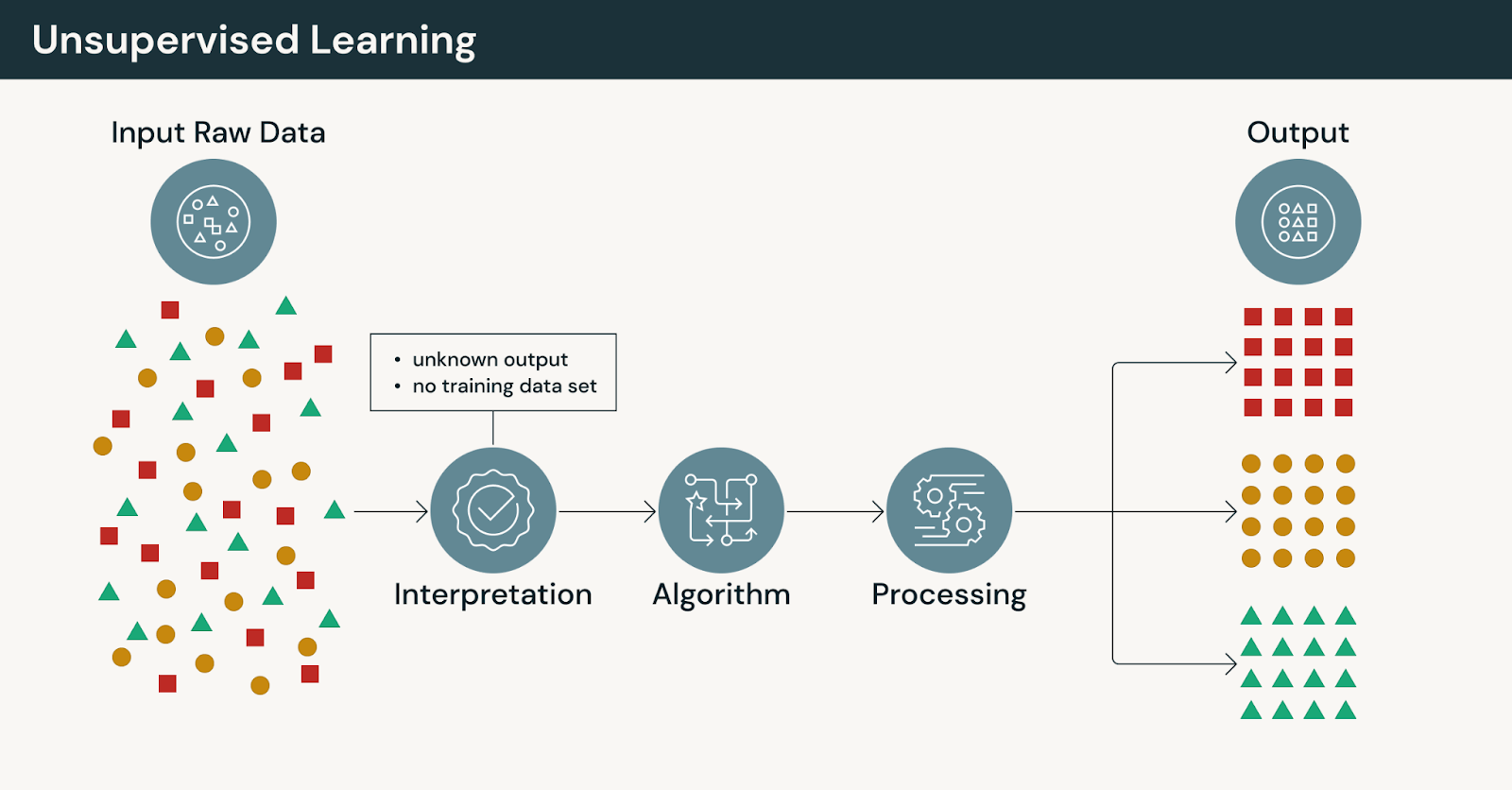
Como funciona o aprendizado não supervisionado
No aprendizado não supervisionado:
- Modelos operam sem rótulos explícitos fornecidos por humanos
- Algoritmos agrupam, comprimem ou organizam dados com base na similaridade
- Saídas requerem interpretação e validação por especialistas do domínio
Como não há respostas corretas, o aprendizado não supervisionado enfatiza a exploração em vez da previsão.
Tipos de aprendizado não supervisionado
Técnicas comuns de aprendizado não supervisionado incluem:
- Agrupamento (Clustering): Agrupamento de pontos de dados semelhantes para revelar estrutura
- Redução de dimensionalidade: Simplificação de conjuntos de dados complexos para análise
- Aprendizado de regras de associação: Identificação de relacionamentos entre variáveis
Muitos desses métodos dependem de algoritmos de agrupamento para expor padrões que não foram definidos explicitamente com antecedência.
Aplicações comuns de aprendizado não supervisionado
O aprendizado não supervisionado de máquina é amplamente utilizado para:
- Estratégias de segmentação de clientes em marketing e personalização, usando agrupamento para agrupar pontos de dados semelhantes por comportamento, preferências e valor, em vez de categorias predeterminadas
- Sistemas de detecção de anomalias para prevenção de fraudes e monitoramento operacional
- Análise exploratória de dados e descoberta de padrões comportamentais
- Busca e agrupamento de similaridade em larga escala
- Análise de cesta de mercado e sistemas de recomendação de produtos, onde algoritmos como o algoritmo Apriori descobrem padrões de compra e associações de produtos sem serem informados quais itens devem estar relacionados
À medida que as organizações acumulam mais dados brutos, o aprendizado não supervisionado oferece uma maneira de extrair valor sem esperar por esforços exaustivos de rotulagem.
Principais diferenças entre aprendizado supervisionado e não supervisionado
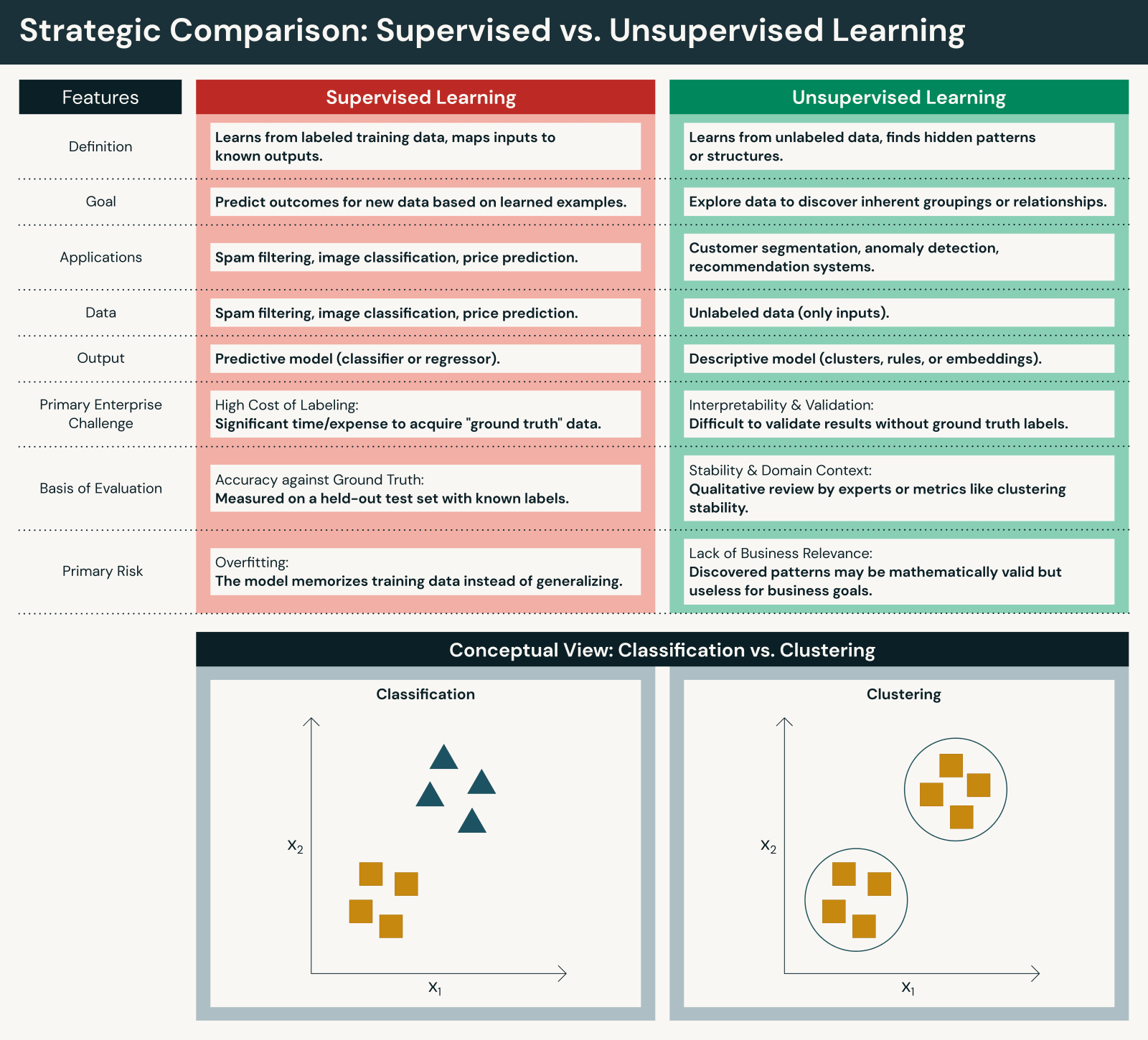
Embora ambas as abordagens sejam fundamentais, elas diferem em aspectos importantes:
Dados e esforço humano
- O aprendizado supervisionado requer conjuntos de dados rotulados, frequentemente criados por meio de anotação manual ou revisão de especialistas. Embora o aprendizado supervisionado de máquina exija intervenção humana significativa para rotulagem, essa intervenção garante que a precisão esteja alinhada com os objetivos de negócios.
- O aprendizado não supervisionado opera diretamente em dados brutos, reduzindo a preparação inicial, mas aumentando o esforço de interpretação. O aprendizado não supervisionado de máquina reduz a intervenção humana durante o treinamento, mas requer intervenção humana para interpretar os resultados.
Objetivos
- O aprendizado supervisionado foca em previsão e classificação contra resultados conhecidos para prever resultados com precisão.
- O aprendizado não supervisionado foca em descoberta e geração de insights para desvendar padrões nos dados.
Avaliação e transparência
- Modelos supervisionados podem ser avaliados usando métricas claras de desempenho contra respostas corretas (acurácia, precisão, recall, F1, RMSE, etc.).
- Modelos de aprendizado não supervisionado requerem avaliação indireta e contexto de domínio para avaliar a utilidade (scores de silhueta, método do cotovelo, validação por especialista de domínio, etc.).
Escalabilidade
- O aprendizado supervisionado geralmente escala mais lentamente devido a restrições de rotulagem.
- O aprendizado não supervisionado escala naturalmente com o volume de dados, mas pode produzir resultados mais ruidosos.
Em ambientes corporativos, essas diferenças-chave levam as equipes a abordagens híbridas em vez de escolhas exclusivas.
O manual de IA agêntica para empresas

Aprendizado semi-supervisionado e auto-supervisionado
Sistemas modernos de ML misturam cada vez mais paradigmas:
Aprendizado semi-supervisionado combina um pequeno conjunto de dados rotulados com um conjunto muito maior de dados não rotulados, reduzindo custos de rotulagem e mantendo a precisão preditiva.
Aprendizado auto-supervisionado vai além, permitindo que os modelos gerem seus próprios sinais de treinamento a partir de dados brutos. Essa abordagem sustenta muitos modelos de fundação modernos e transformou o aprendizado supervisionado em uma função de refinamento, em vez de um ponto de partida.
Essas técnicas permitem que as organizações:
- Aproveitem ativos de dados existentes em escala
- Adaptem-se mais rapidamente a novas distribuições de dados
- Reduzam a dependência de rotulagem manual
Vale notar que aprendizado supervisionado e não supervisionado não representam o cenário completo de machine learning. O aprendizado por reforço é um terceiro paradigma principal no qual agentes aprendem comportamentos ótimos por meio de interações de tentativa e erro com ambientes, recebendo recompensas ou penalidades por suas ações. Embora o aprendizado por reforço esteja fora do espectro supervisionado vs. não supervisionado, sistemas modernos combinam cada vez mais todas as três abordagens, dependendo dos requisitos da tarefa.
Quando usar aprendizado supervisionado vs. não supervisionado
Na prática, a escolha certa depende dos dados, objetivos e restrições operacionais.
Avalie seus dados
- Você tem rótulos confiáveis hoje?
- Você consegue manter a qualidade da rotulagem à medida que os dados aumentam?
- Com que frequência seus dados mudam?
Defina seu objetivo
- Prever resultados? O aprendizado supervisionado se encaixa.
- Explorar estrutura desconhecida? O aprendizado não supervisionado é frequentemente o ponto de entrada certo.
Planeje para o ciclo de vida completo
Independentemente da abordagem, sistemas bem-sucedidos dependem de pipelines de engenharia de dados confiáveis que movem dados da ingestão ao treinamento e à produção de forma consistente.
Muitas equipes começam com exploração não supervisionada e, em seguida, introduzem aprendizado supervisionado assim que os alvos e as métricas são bem definidos.
Por que a governança unificada de dados e IA é crítica para uma estratégia de ML empresarial
À medida que os sistemas de ML escalam, as empresas precisam gerenciar acesso, linhagem, conformidade e responsabilidade.
É aqui que a governança de dados unificada se torna crítica. Governar dados e modelos de forma consistente em todos os fluxos de trabalho garante que os insights sejam confiáveis e que os sistemas permaneçam auditáveis à medida que evoluem.
Abordando perguntas comuns
A regressão linear é supervisionada ou não supervisionada?
A regressão linear é aprendizado supervisionado porque requer valores de saída rotulados.
Qual é a principal diferença entre aprendizado supervisionado e não supervisionado?
O aprendizado supervisionado prevê resultados conhecidos usando dados rotulados. O aprendizado não supervisionado descobre padrões em dados não rotulados.
O que você precisa saber daqui para frente
Várias tendências estão remodelando o ML empresarial:
- O aprendizado auto-supervisionado domina o treinamento de modelos de fundação.
- O aprendizado supervisionado serve cada vez mais como uma camada de precisão.
- Clustering e embeddings estão se tornando capacidades empresariais centrais.
- Avaliação e governança estão crescendo em importância à medida que o uso de dados não rotulados se expande.
Essas mudanças reforçam a necessidade de pensar em sistemas, não em silos.
Desafios e limitações
Tanto o aprendizado supervisionado quanto o não supervisionado desempenham papéis essenciais no ML empresarial, mas cada um vem com compensações que as equipes devem planejar antecipadamente.
Desafios do aprendizado supervisionado
Os requisitos de dados são frequentemente a maior restrição. Criar conjuntos de dados rotulados pode ser demorado e caro, especialmente quando a rotulagem requer conhecimento de domínio. Em muitos casos, a precisão do modelo está diretamente ligada à qualidade dos rótulos, tornando anotações inconsistentes ou tendenciosas um risco sério.
Modelos supervisionados também enfrentam riscos de overfitting. Quando os modelos aprendem os dados de treinamento muito de perto, eles podem ter um bom desempenho na avaliação, mas falhar em generalizar para novos dados ou dados não vistos. Mitigações comuns incluem validação cruzada, técnicas de regularização e expansão de conjuntos de dados de treinamento para refletir melhor a variabilidade do mundo real.
Preocupações com escalabilidade surgem à medida que os volumes de dados crescem. A rotulagem com intervenção humana não escala linearmente, e processos manuais podem se tornar gargalos para projetos grandes ou de rápida movimentação. Sem planejamento cuidadoso, fluxos de trabalho supervisionados podem ter dificuldade em acompanhar as demandas de negócios.
Desafios do aprendizado não supervisionado
O aprendizado não supervisionado introduz um conjunto diferente de problemas, começando pela dificuldade de interpretação. Clusters ou padrões podem não ter um significado óbvio sem contexto de domínio, e a estrutura descoberta nem sempre se alinha com os objetivos de negócios. Extrair valor geralmente requer colaboração próxima entre cientistas de dados e especialistas no assunto.
A complexidade da validação é outro desafio. Sem rótulos de verdade fundamental, pode ser difícil avaliar objetivamente a qualidade do modelo. As equipes geralmente confiam em métricas substitutas, alinhamento de negócios ou avaliação comparativa entre vários algoritmos para construir confiança nos resultados.
Finalmente, a seleção de algoritmos requer experimentação. Os resultados podem variar significativamente com base nas escolhas de parâmetros, medidas de distância ou etapas de pré-processamento, tornando a iteração inevitável.
Melhores práticas de machine learning
Em ambas as abordagens, várias práticas melhoram consistentemente os resultados:
- Garanta dados de entrada de alta qualidade, incluindo o manuseio adequado de valores ausentes e outliers
- Comece com uma definição clara do problema antes de selecionar uma abordagem
- Implemente verificações de qualidade de dados e processos de validação precocemente
- Use métricas de avaliação apropriadas para cada paradigma
- Comece com análise exploratória de dados antes de se comprometer com fluxos de trabalho de produção
Soluções confiáveis de engenharia de dados fornecem a base para aplicar essas práticas de forma consistente, ajudando as equipes a passar da experimentação para a produção com maior confiança.
O que você precisa saber em 2026
Várias mudanças já estão remodelando a prática de ML empresarial.
1. Pré-treinamento auto-supervisionado agora sustenta a maioria dos modelos de fundação modernos
A maioria dos modelos de ponta — incluindo modelos de linguagem grandes, sistemas de visão computacional e arquiteturas multimodais — agora são treinados principalmente usando aprendizado auto-supervisionado. Em vez de depender de conjuntos de dados rotulados por humanos, esses modelos geram seus próprios sinais de treinamento a partir de dados brutos, como prever o próximo token em uma sequência ou reconstruir partes mascaradas de uma entrada.
Essa mudança reflete uma realidade prática: as empresas possuem vastas quantidades de dados não rotulados, mas a rotulagem em escala é cara e lenta. O aprendizado auto-supervisionado permite que as organizações extraiam valor de ativos de dados existentes enquanto constroem representações que podem ser adaptadas posteriormente a tarefas específicas.
2. O ajuste fino supervisionado mudou para uma função de refinamento
O aprendizado supervisionado não desapareceu — mas seu papel mudou. Em vez de servir como o principal mecanismo de treinamento, o ajuste fino supervisionado é cada vez mais usado para refinar, alinhar e validar modelos para objetivos de negócios bem definidos.
Essa abordagem permite que as equipes concentrem os esforços de rotulagem onde a precisão é mais importante, como requisitos regulatórios, restrições de segurança ou precisão específica do domínio, evitando rotulagem desnecessária no início do pipeline.
3. Embeddings são agora capacidades empresariais centrais
Embeddings se tornaram infraestrutura empresarial central. Modelos de fundação geram cada vez mais embeddings vetoriais que capturam o significado semântico em texto, imagens, áudio e dados estruturados. Esses embeddings alimentam busca por similaridade, recuperação, personalização, detecção de anomalias e sistemas de recomendação em escala.
Clustering e outros métodos baseados em similaridade são importantes — mas são aplicações downstream de embeddings, em vez de paradigmas pares. A mudança estratégica não é em direção ao clustering em si, mas em direção a arquiteturas centradas em embeddings que permitem busca, recuperação e raciocínio unificados em dados empresariais.
À medida que as organizações operacionalizam a IA, os embeddings se tornam o tecido conectivo entre o pré-treinamento auto-supervisionado, o ajuste fino supervisionado e as aplicações downstream. Eles fornecem uma camada representacional comum que suporta fluxos de trabalho de exploração e precisão dentro de plataformas de dados modernas e unificadas.
Construa sistemas, não lados
Aprendizado supervisionado e não supervisionado resolvem problemas diferentes — e sistemas modernos de ML precisam de ambos. O aprendizado de máquina supervisionado se destaca quando você tem dados rotulados e precisa de previsões ou classificações precisas e responsáveis. O aprendizado de máquina não supervisionado prospera quando o objetivo é a descoberta, ajudando equipes a desvendar padrões e insights em dados brutos sem saídas predefinidas. Quando os dados rotulados são limitados, as abordagens de aprendizado semi supervisionado preenchem a lacuna combinando ambos os paradigmas.
O verdadeiro desafio não é escolher entre aprendizado supervisionado vs não supervisionado, mas construir sistemas que possam combinar abordagens, evoluir ao longo do tempo e operar de forma confiável em produção. Equipes eficazes começam avaliando a disponibilidade de seus dados, esclarecendo se o objetivo principal é previsão ou exploração, e avaliando os recursos necessários para suportar cada abordagem.
Estratégias de aprendizado de máquina raramente são estáticas. A exploração não supervisionada geralmente informa o desenvolvimento posterior de modelos supervisionados, enquanto o ajuste fino supervisionado traz precisão e validação para sistemas construídos sobre representações mais amplas. Com o tempo, os insights devem fluir para business intelligence e analytics onde podem informar decisões e impulsionar resultados.
Para se aprofundar, explore estes recursos:
- Um Guia Compacto para Ajuste Fino e Pré-treinamento de LLMs — Aprenda técnicas para ajustar fino e pré-treinar seu LLM
Obtenha o guia - O Grande Livro da IA Generativa — Melhores práticas para construir aplicações GenAI de qualidade de produção
Baixe - O Grande Livro de Casos de Uso de Machine Learning — Obtenha tudo o que você precisa para colocar o aprendizado de máquina em prática
Leia agora
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.